Cloudera ने हाल ही में CDH 6.2 लॉन्च किया है जिसमें Apache HBase में दो नई प्रमुख विशेषताएं शामिल हैं:
- सीरियल प्रतिकृति
- बकेट कैश अब इंटेल की ऑप्टेन मेमोरी का समर्थन करता है
सीरियल प्रतिकृति
HBase में एक परिष्कृत अतुल्यकालिक प्रतिकृति तंत्र है जो आज जटिल टोपोलॉजी का समर्थन करता है जिसमें वैश्विक राउंड-रॉबिन, टू वे, स्पैन-इन और स्पैन-आउट टोपोलॉजी शामिल हैं।
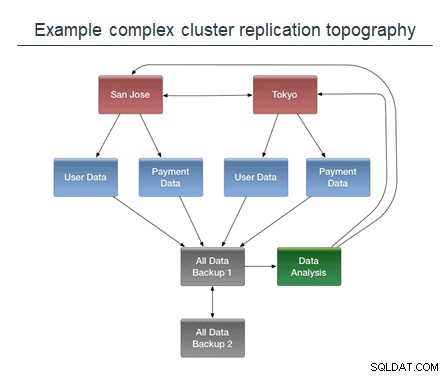
यह प्रतिकृति क्षमता, आज तक, अंतिम स्थिरता प्रदान करती है - जिसका अर्थ है कि जिस क्रम में अद्यतनों को दोहराया जाता है वह आवश्यक रूप से उसी क्रम में नहीं होता है जिसमें वे डेटाबेस पर लागू होते थे। जबकि यह कई ग्राहकों के लिए काम करता है, कई उपयोग मामलों के लिए प्रतिकृति समापन बिंदु पर अद्यतनों का क्रम महत्वपूर्ण था।

सीरियल प्रतिकृति सुविधा प्रतिकृति के लिए समयरेखा स्थिरता प्रदान करती है। दूसरे शब्दों में, अद्यतनों के क्रम को गंतव्य क्लस्टर में प्रतिकृति के माध्यम से संरक्षित किया जाता है। इस स्थिरता के लिए थोड़ी सी लागत है और कुछ मामलों में, उपयोगकर्ता पा सकते हैं कि प्रतिकृति डिफ़ॉल्ट प्रतिकृति दृष्टिकोण की तुलना में थोड़ी धीमी है।
इस विकल्प का विन्यास काफी सरल है (सीरियल ध्वज को सत्य पर सेट करें) और प्रतिकृति सेटअप के समय या उसके बाद किसी भी समय तालिका स्तर, नामस्थान स्तर पर या किसी ऐसे सहकर्मी के लिए लागू किया जा सकता है जो HBase में सभी तालिकाओं को दोहराता है।
HBase बकेट कैश
HBase का बकेट कैश एक 2-लेयर कैश है जिसे विभिन्न प्रकार के उपयोग के मामलों में तैयार प्रदर्शन को बेहतर बनाने के लिए डिज़ाइन किया गया है। पहली परत जावा हीप में है और कैश की दूसरी परत कई अलग-अलग स्थानों में रह सकती है जिनमें शामिल हैं:ऑफ-हीप मेमोरी, इंटेल ऑप्टेन मेमोरी, एसएसडी या एचडीडी।
अधिकांश ग्राहकों के लिए बकेट कैश की दूसरी परत के लिए अनुशंसित कॉन्फ़िगरेशन ऑफ-हीप रहा है। इस कॉन्फ़िगरेशन में परिनियोजन अंतर्निहित ऑन-हीप कैश की तुलना में बहुत बड़े मेमोरी आकार तक स्केल करने में सक्षम हैं, क्योंकि ऑफ-हीप इंजन JVM कचरा संग्रहण दबाव से बचा जाता है। बड़ा कैश आकार महत्वपूर्ण रूप से बेहतर HBase पठन प्रदर्शन प्रदान करता है।
CDH 6.2 से शुरू होकर, Cloudera में अब Intel की नई जारी ऑप्टेन मेमोरी को बकेट कैश के दूसरे स्तर के लिए वैकल्पिक गंतव्य के रूप में उपयोग करने की क्षमता शामिल है। यह परिनियोजन कॉन्फ़िगरेशन आपको निरंतर लागत के लिए कैश के आकार का ~ 3x (DRAM पर ऑफ-हीप कैश की तुलना में) सक्षम बनाता है। पारंपरिक ऑफ-हीप कॉन्फ़िगरेशन की तुलना में इसमें कुछ अतिरिक्त विलंबता होती है, लेकिन हमारे परीक्षण से संकेत मिलता है कि डेटा के कामकाजी सेट के अधिक (यदि सभी नहीं) को कैश में फिट करने की अनुमति देकर सेट अप परिणाम शुद्ध प्रदर्शन में सुधार करता है जब डेटा अंततः एचडीएफएस (एचडीडी का उपयोग करके) पर संग्रहीत किया जाता है।
क्लाउड पर परिनियोजन या ऑन-प्रिमाइसेस ऑब्जेक्ट स्टोरेज का उपयोग करते समय, प्रदर्शन में सुधार और भी बेहतर होगा क्योंकि ऑब्जेक्ट स्टोरेज कम मात्रा में डेटा के यादृच्छिक पढ़ने के लिए बहुत महंगा हो जाता है। नीचे दी गई तालिका बकेट कैश के दूसरे स्तर को कॉन्फ़िगर करने की योजना बनाते समय आवश्यक लागत, आकार और विलंबता ट्रेड-ऑफ का बोध कराती है।
| भंडारण | $ लागत / GB | आकार (स्थिर लागत) | विलंबता |
| ऑफ-हीप DRAM | 35 | 1.0 जीबी | ~70 एनएस |
| इंटेल ऑप्टेन¹ | 13 | 2.7 जीबी | 180-340 एनएस |
| एसएसडी | 0.15 | 233.3 जीबी | 10-100 µs |
| HDD² | 0.027 | 1.3 टीबी | 4-10 एमएस |
| ऑब्जेक्ट स्टोरेज³ | 0.006 | 5.8 टीबी | 10-100 एमएस |
प्रदर्शन सुधार के लिए ऑप्टेन डीसी पर्सिस्टेंट मेमोरी का लाभ उठाने पर इंटेल और क्लौडेरा सहयोग के बारे में अधिक जानने के लिए इस ब्लॉग को पढ़ें।
संदर्भ:
- Optane DC परसिस्टेंट मेमोरी परफॉर्मेंस ओवरव्यू (https://www.youtube.com/watch?v=UTVt_AZmWjM) - मिनट 6:53,
https:// www.pcper.com/news/Storage/Intels-Optane-DC-Persistent-Memory-DIMMs-Push-Latency-Closer-DRAM,
https://www.tomshardware.com/news/intel-optane- dimm-price-performance,39007.html - https://www.backblaze.com/blog/hard-drive-cost-per-gigabyte/,
https://www. Westerndigital.com/ उत्पाद/डेटा-सेंटर-ड्राइव#हार्ड-डिस्क-एचडीडी - https://www.qualeed.com/en/qbackup/cloud-storage-comparison/, https://www.dellemc.com/en-us/collaterals/ unauth/analyst-reports/products/storage/esg-ecnomic-value-audi-dell-emc-elastic-cloud-storage.pdf



