Hadoop क्लस्टर के बारे में सब कुछ जानने के लिए उत्सुक हैं?
Hadoop कमोडिटी हार्डवेयर के समूहों में बड़ी मात्रा में डेटा के विश्लेषण और भंडारण के लिए एक सॉफ्टवेयर ढांचा है। इस लेख में, हम एक Hadoop क्लस्टर का अध्ययन करेंगे।
आइए सबसे पहले क्लस्टर के परिचय के साथ शुरुआत करते हैं।
क्लस्टर क्या है?
क्लस्टर नोड्स का एक संग्रह है। नोड्स और कुछ नहीं बल्कि एक नेटवर्क के भीतर कनेक्शन/चौराहे का एक बिंदु है।
एक कंप्यूटर क्लस्टर एक नेटवर्क से जुड़े कंप्यूटरों का एक संग्रह है, जो एक दूसरे के साथ संचार करने में सक्षम है, और एक सिस्टम के रूप में काम करता है।
Hadoop क्लस्टर क्या है?
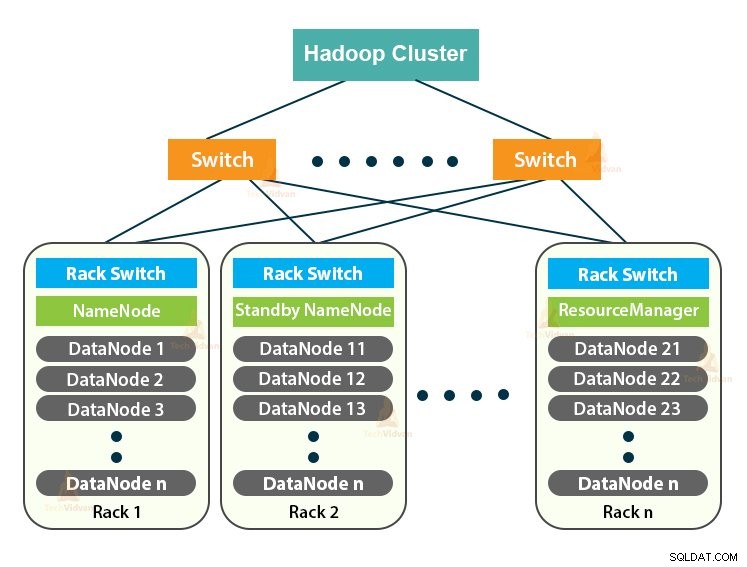
Hadoop क्लस्टर सिर्फ एक कंप्यूटर क्लस्टर है जिसका उपयोग बड़ी मात्रा में डेटा को वितरित तरीके से संभालने के लिए किया जाता है।
यह एक कम्प्यूटेशनल क्लस्टर है जिसे एक वितरित कंप्यूटिंग वातावरण में बड़ी मात्रा में असंरचित या संरचित डेटा के भंडारण के साथ-साथ विश्लेषण करने के लिए डिज़ाइन किया गया है।
Hadoop क्लस्टर को साझा-कुछ नहीं सिस्टम . के रूप में भी जाना जाता है क्योंकि नेटवर्क बैंडविड्थ को छोड़कर क्लस्टर में नोड्स के बीच कुछ भी साझा नहीं किया जाता है। यह प्रसंस्करण विलंबता को कम करता है।
इस प्रकार, जब बड़ी मात्रा में डेटा पर प्रश्नों को संसाधित करने की आवश्यकता होती है, तो क्लस्टर-व्यापी विलंबता कम से कम हो जाती है।
आइए अब हम Hadoop क्लस्टर की वास्तुकला का अध्ययन करें।
Hadoop क्लस्टर का आर्किटेक्चर
Hadoop क्लस्टर एक मास्टर-स्लेव आर्किटेक्चर का अनुसरण करता है। इसमें मास्टर नोड, स्लेव नोड और क्लाइंट नोड शामिल हैं।
<एच5>1. Hadoop क्लस्टर में मास्टरहडूप क्लस्टर में मास्टर एक उच्च शक्ति वाली मशीन है जिसमें मेमोरी और सीपीयू का उच्च विन्यास होता है। दो डेमॉन जो NameNode और ResourceManager हैं, मास्टर नोड पर चलते हैं।
ए. NameNode के कार्य
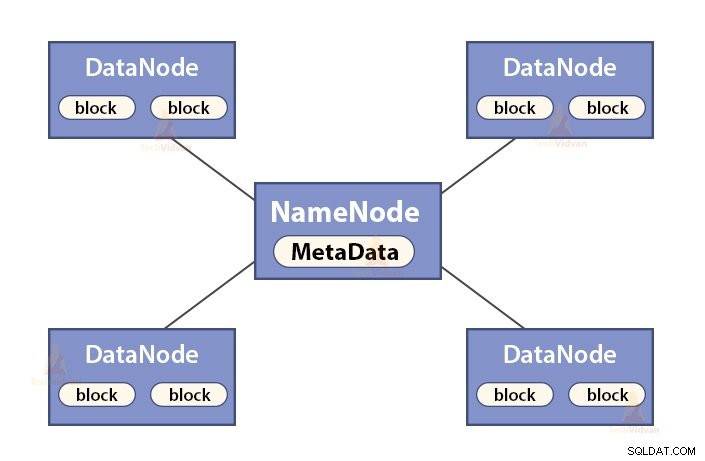
NameNode Hadoop HDFS . में एक मास्टर नोड है . NameNode फाइल सिस्टम नेमस्पेस को मैनेज करता है। यह तेजी से पुनर्प्राप्ति के लिए मेमोरी में फाइल सिस्टम मेटा-डेटा को स्टोर करता है। इसलिए, इसे हाई-एंड मशीनों पर कॉन्फ़िगर किया जाना चाहिए।
NameNode के कार्य हैं:
- फाइलसिस्टम नेमस्पेस को मैनेज करता है
- फ़ाइल के ब्लॉक के बारे में मेटा-डेटा स्टोर करता है, स्थान, अनुमतियों आदि को ब्लॉक करता है।
- यह फाइल सिस्टम नेमस्पेस ऑपरेशंस जैसे ओपनिंग, क्लोजिंग, फाइलों और निर्देशिकाओं का नाम बदलने आदि को निष्पादित करता है।
- यह DataNode का रखरखाव और प्रबंधन करता है।
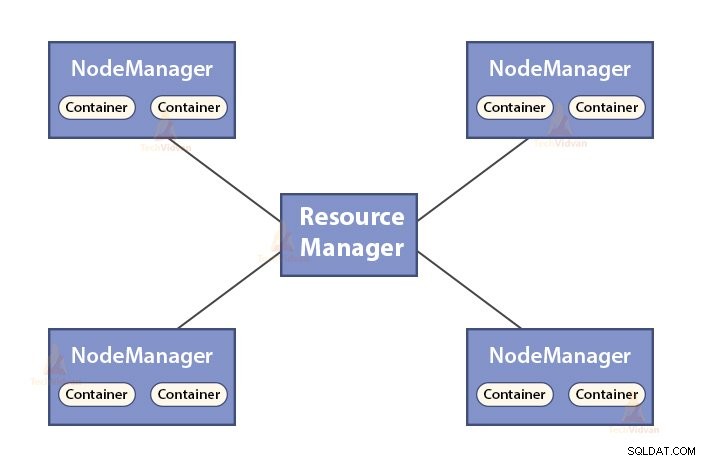
- ResourceManager YARN का मास्टर डेमॉन है।
- संसाधन प्रबंधक सिस्टम में सभी अनुप्रयोगों के बीच संसाधनों की मध्यस्थता करता है।
- यह क्लस्टर में जीवित और मृत नोड्स का ट्रैक रखता है।
2. Hadoop क्लस्टर में गुलाम
Hadoop क्लस्टर में दास सस्ते कमोडिटी हार्डवेयर हैं। दो डेमॉन जो DataNodes और YARN NodeManagers हैं, स्लेव नोड्स पर चलते हैं।
ए. DataNodes के कार्य
- DataNodes वास्तविक व्यावसायिक डेटा संग्रहीत करता है। यह एक फाइल के ब्लॉक को स्टोर करता है।
- यह NameNode के निर्देशों के आधार पर ब्लॉक निर्माण, विलोपन, प्रतिकृति करता है।
- डेटानोड क्लाइंट को पढ़ने/लिखने के संचालन की सेवा के लिए जिम्मेदार है।
- NodeManager YARN का गुलाम डेमॉन है।
- यह कंटेनरों के लिए जिम्मेदार है, उनके संसाधन उपयोग (जैसे सीपीयू, डिस्क, मेमोरी, नेटवर्क) की निगरानी और संसाधन प्रबंधक को इसकी रिपोर्ट करना।
- नोडमैनेजर उस नोड के स्वास्थ्य की भी जांच करता है जिस पर वह चल रहा है।
3. Hadoop क्लस्टर में क्लाइंट नोड
Hadoop में क्लाइंट नोड न तो मास्टर नोड हैं और न ही स्लेव नोड। उनके पास सभी क्लस्टर सेटिंग्स के साथ उन पर Hadoop स्थापित है।
क्लाइंट नोड्स के कार्य
- क्लाइंट नोड्स Hadoop क्लस्टर में डेटा लोड करते हैं।
- यह MapReduce नौकरियों को प्रस्तुत करता है, यह वर्णन करते हुए कि उस डेटा को कैसे संसाधित किया जाना चाहिए।
- प्रसंस्करण पूरा होने के बाद नौकरी के परिणाम प्राप्त करें।
हम अधिक नोड्स जोड़कर Hadoop क्लस्टर को बढ़ा सकते हैं। यह Hadoop को रैखिक रूप से मापनीय . बनाता है . प्रत्येक नोड जोड़ के साथ, हमें थ्रूपुट में एक समान बढ़ावा मिलता है। अगर हमारे पास 'n' नोड हैं, तो 1 नोड जोड़ने से (1/n) अतिरिक्त कंप्यूटिंग शक्ति मिलती है।
सिंगल नोड Hadoop क्लस्टर VS मल्टी-नोड Hadoop क्लस्टर
<एच4>1. सिंगल नोड हडूप क्लस्टर
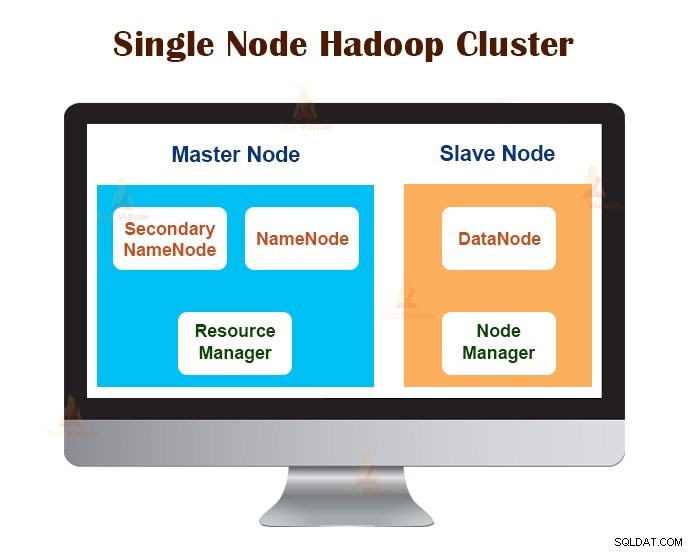
सिंगल नोड हडूप क्लस्टर एक मशीन पर तैनात किया गया है। NameNode, DataNode, ResourceManager, NodeManager जैसे सभी डेमॉन एक ही मशीन/होस्ट पर चलते हैं।
सिंगल-नोड क्लस्टर सेटअप में, सब कुछ एक जेवीएम इंस्टेंस पर चलता है। Hadoop उपयोगकर्ता को JAVA_HOME चर सेट करने के अलावा कोई कॉन्फ़िगरेशन सेटिंग नहीं करनी थी।
एकल नोड Hadoop क्लस्टर के लिए डिफ़ॉल्ट प्रतिकृति कारक हमेशा 1 होता है।
<एच4>2. मल्टी-नोड हडूप क्लस्टरमल्टी-नोड हडूप क्लस्टर कई मशीनों पर तैनात है। मल्टी-नोड हडूप क्लस्टर में सभी डेमॉन अलग-अलग मशीनों/होस्टों पर ऊपर और चलते हैं।
एक मल्टी-नोड Hadoop क्लस्टर मास्टर-स्लेव आर्किटेक्चर का अनुसरण करता है। डेमॉन नामेनोड और रिसोर्समैनेजर मास्टर नोड्स पर चलते हैं, जो हाई-एंड कंप्यूटर मशीन हैं।
डेमॉन DataNodes और NodeManagers स्लेव नोड्स (वर्कर नोड्स) पर चलते हैं, जो कि सस्ते कमोडिटी हार्डवेयर हैं।
मल्टी-नोड हडूप क्लस्टर में, मास्टर सर्वर के भौतिक स्थान के स्थान के बावजूद दास मशीन किसी भी स्थान पर मौजूद हो सकती है।
Hadoop क्लस्टर में प्रयुक्त संचार प्रोटोकॉल
एचडीएफएस संचार प्रोटोकॉल टीसीपी/आईपी प्रोटोकॉल के शीर्ष पर स्तरित हैं। क्लाइंट NameNode मशीन पर कॉन्फ़िगर करने योग्य TCP पोर्ट के माध्यम से NameNode के साथ संबंध स्थापित करता है।
Hadoop क्लस्टर क्लाइंट प्रोटोकॉल के माध्यम से क्लाइंट से कनेक्शन स्थापित करता है। इसके अलावा, DataNode DataNode प्रोटोकॉल का उपयोग करके NameNode से बात करता है।
रिमोट प्रोसीजर कॉल (RPC) एब्स्ट्रैक्शन क्लाइंट प्रोटोकॉल और डेटानोड प्रोटोकॉल को लपेटता है। डिज़ाइन के अनुसार, NameNode कोई RPC शुरू नहीं करता है। यह केवल क्लाइंट या DataNodes द्वारा जारी किए गए RPC अनुरोधों का जवाब देता है।
Hadoop क्लस्टर बनाने की सर्वोत्तम प्रक्रियाएं
एक Hadoop क्लस्टर का प्रदर्शन सीपीयू, मेमोरी, नेटवर्क बैंडविड्थ, हार्ड ड्राइव और अन्य अच्छी तरह से कॉन्फ़िगर की गई सॉफ़्टवेयर परतों का उपयोग करने वाले अच्छी तरह से आयामी हार्डवेयर संसाधनों के आधार पर विभिन्न कारकों पर निर्भर करता है।
Hadoop क्लस्टर बनाना एक गैर-तुच्छ काम है। इसके लिए विभिन्न कारकों पर विचार करने की आवश्यकता है जैसे कि सही हार्डवेयर चुनना, Hadoop क्लस्टर का आकार बदलना और Hadoop क्लस्टर को कॉन्फ़िगर करना।
आइए अब हम प्रत्येक को विस्तार से देखें।
<एच4>1. Hadoop क्लस्टर के लिए सही हार्डवेयर चुननाकई संगठन, Hadoop इन्फ्रास्ट्रक्चर की स्थापना करते समय, एक कठिन परिस्थिति में होते हैं क्योंकि उन्हें इस बात की जानकारी नहीं होती है कि उन्हें एक अनुकूलित Hadoop वातावरण स्थापित करने के लिए किस प्रकार की मशीनों को खरीदने की आवश्यकता है, और आदर्श कॉन्फ़िगरेशन का उन्हें उपयोग करना चाहिए।
Hadoop क्लस्टर के लिए सही हार्डवेयर चुनने के लिए, निम्नलिखित बातों पर विचार करना चाहिए:
- डेटा की मात्रा जिसे क्लस्टर संभालेगा।
- क्लस्टर जिस प्रकार के वर्कलोड से निपटेगा (सीपीयू बाउंड, आई/ओ बाउंड)।
- डेटा भंडारण पद्धति जैसे डेटा कंटेनर, उपयोग की गई डेटा संपीड़न तकनीक, यदि कोई हो।
- एक डेटा प्रतिधारण नीति, यानी हम डेटा को फ्लश करने से पहले कितनी देर तक रखना चाहते हैं।
Hadoop क्लस्टर के आकार को निर्धारित करने के लिए, Hadoop उपयोगकर्ताओं द्वारा Hadoop क्लस्टर पर संसाधित किए जाने वाले डेटा वॉल्यूम को एक महत्वपूर्ण विचार होना चाहिए।
संसाधित किए जाने वाले डेटा की मात्रा जानने से, यह तय करने में मदद मिलती है कि डेटा को कुशलतापूर्वक संसाधित करने के लिए कितने नोड्स की आवश्यकता होगी और प्रत्येक नोड के लिए आवश्यक मेमोरी क्षमता। स्वीकृत हार्डवेयर के प्रदर्शन और लागत के बीच संतुलन होना चाहिए।
<एच4>3. Hadoop क्लस्टर को कॉन्फ़िगर करनाHadoop क्लस्टर के लिए आदर्श कॉन्फ़िगरेशन ढूँढना कोई आसान काम नहीं है। Hadoop ढांचे को उस क्लस्टर के लिए अनुकूलित किया जाना चाहिए जो वह चल रहा है और नौकरी के लिए भी।
Hadoop क्लस्टर के लिए आदर्श कॉन्फ़िगरेशन तय करने का सबसे अच्छा तरीका है कि Hadoop जॉब्स को एक बेसलाइन प्राप्त करने के लिए उपलब्ध डिफ़ॉल्ट कॉन्फ़िगरेशन के साथ चलाया जाए। उसके बाद, हम यह देखने के लिए कार्य इतिहास लॉग फ़ाइलों का विश्लेषण कर सकते हैं कि कहीं कोई संसाधन कमज़ोर तो नहीं है या कार्य को चलाने में लगने वाला समय अपेक्षा से अधिक है।
यदि ऐसा है, तो कॉन्फ़िगरेशन बदलें। उसी प्रक्रिया को दोहराने से Hadoop क्लस्टर कॉन्फ़िगरेशन को ट्यून किया जा सकता है जो व्यावसायिक आवश्यकताओं के लिए सबसे उपयुक्त है।
Hadoop क्लस्टर का प्रदर्शन काफी हद तक डेमॉन को आवंटित संसाधनों पर निर्भर करता है। छोटे से मध्यम डेटा संदर्भ के लिए, Hadoop प्रत्येक DataNode पर एक CPU कोर सुरक्षित रखता है, जबकि, लंबे डेटासेट के लिए, यह HDFS और MapReduce डेमॉन के लिए प्रत्येक DataNode पर 2 CPU कोर आवंटित करता है।
Hadoop क्लस्टर प्रबंधन
Hadoop क्लस्टर को उत्पादन में तैनात करने पर, यह स्पष्ट है कि इसे सभी आयामों के साथ स्केल करना चाहिए जो कि वॉल्यूम, विविधता और वेग हैं।
उत्पादन के लिए तैयार होने के लिए इसमें जो विभिन्न विशेषताएं होनी चाहिए, वे हैं - चौबीसों घंटे उपलब्धता, मजबूत, प्रबंधनीयता और प्रदर्शन। Hadoop क्लस्टर प्रबंधन बड़ी डेटा पहल का मुख्य पहलू है।
Hadoop क्लस्टर प्रबंधन के लिए सबसे अच्छे टूल में निम्नलिखित विशेषताएं होनी चाहिए:-
- इसे 24×7 उच्च उपलब्धता, संसाधन प्रावधान, विविध सुरक्षा, कार्य-भार प्रबंधन, स्वास्थ्य निगरानी, प्रदर्शन अनुकूलन सुनिश्चित करना चाहिए। साथ ही, इसे एक या अधिक नोड्स में कार्य शेड्यूलिंग, नीति प्रबंधन, बैकअप और पुनर्प्राप्ति प्रदान करने की आवश्यकता है।
- लोड बैलेंसिंग, हॉट स्टैंडबाय, रीसिंक्रनाइज़ेशन और ऑटो-फेलओवर के साथ अनावश्यक HDFS NameNode उच्च उपलब्धता को लागू करें।
- नीति-आधारित नियंत्रणों को लागू करना जो किसी भी एप्लिकेशन को पहले से ही अधिकतम-आउट हडूप क्लस्टर पर संसाधनों के अनुपातहीन हिस्से को हथियाने से रोकते हैं।
- Hadoop क्लस्टर पर किसी भी सॉफ़्टवेयर लेयर के परिनियोजन के प्रबंधन के लिए रिग्रेशन परीक्षण करना। यह सुनिश्चित करने के लिए है कि कोई भी कार्य या डेटा क्रैश न हो या दैनिक कार्यों में कोई अड़चन न आए।
Hadoop क्लस्टर के लाभ
Hadoop क्लस्टर द्वारा प्रदान किए जाने वाले विभिन्न लाभ हैं:
<एच4>1. स्केलेबलHadoop क्लस्टर स्केलेबल हैं। हम बिना किसी डाउनटाइम और बिना किसी अतिरिक्त प्रयास के Hadoop क्लस्टर में कितने भी नोड जोड़ सकते हैं। प्रत्येक नोड जोड़ के साथ, हमें थ्रूपुट में एक समान बढ़ावा मिलता है।
<एच4>2. मजबूतीHadoop क्लस्टर अपने विश्वसनीय स्टोरेज के लिए जाना जाता है। यह डेटा को मज़बूती से संग्रहीत कर सकता है, यहाँ तक कि DataNode विफलता, NameNode विफलता और नेटवर्क विभाजन जैसे मामलों में भी। DataNode समय-समय पर NameNode को दिल की धड़कन का संकेत भेजता है।
नेटवर्क विभाजन में, DataNodes का एक सेट NameNode से अलग हो जाता है, जिसके कारण NameNode को इन DataNodes से कोई दिल की धड़कन प्राप्त नहीं होती है। NameNode तब इन DataNodes को मृत मानता है और उन्हें कोई I/O अनुरोध अग्रेषित नहीं करता है।
साथ ही, इन DataNodes में संग्रहीत ब्लॉकों का प्रतिकृति कारक उनके निर्दिष्ट मान से नीचे आता है। नतीजतन, NameNode फिर इन ब्लॉकों की प्रतिकृति शुरू करता है और विफलता से उबरता है।
<एच4>3. क्लस्टर पुनर्संतुलनHadoop HDFS आर्किटेक्चर स्वचालित रूप से क्लस्टर रीबैलेंसिंग करता है। यदि DataNode में खाली स्थान थ्रेशोल्ड स्तर से नीचे आता है, तो HDFS आर्किटेक्चर स्वचालित रूप से कुछ डेटा को अन्य DataNode में ले जाता है जहाँ पर्याप्त स्थान उपलब्ध होता है।
<एच4>4. किफ़ायतीHadoop क्लस्टर की स्थापना लागत प्रभावी है क्योंकि इसमें सस्ते कमोडिटी हार्डवेयर शामिल हैं। कोई भी संगठन महंगे सर्वर हार्डवेयर पर ज्यादा खर्च किए बिना आसानी से एक शक्तिशाली Hadoop क्लस्टर स्थापित कर सकता है।
इसके अलावा, Hadoop क्लस्टर अपने वितरित भंडारण टोपोलॉजी के साथ पारंपरिक प्रणाली की सीमाओं को पार करते हैं। सिस्टम में अतिरिक्त सस्ती स्टोरेज इकाइयों को जोड़कर सीमित स्टोरेज को बढ़ाया जा सकता है।
5. लचीला
Hadoop क्लस्टर अत्यधिक लचीले होते हैं क्योंकि वे किसी भी प्रकार के डेटा को संसाधित कर सकते हैं, या तो संरचित, अर्ध-संरचित, या असंरचित और गीगाबाइट से लेकर पेटाबाइट तक के किसी भी आकार के।
<एच4>6. तेज़ संसाधनHadoop क्लस्टर में, डेटा को एक वितरित वातावरण में समानांतर रूप से संसाधित किया जा सकता है। यह Hadoop को तेज़ डेटा प्रोसेसिंग क्षमता प्रदान करता है। Hadoop क्लस्टर कुछ ही सेकंड में टेराबाइट्स या पेटाबाइट्स डेटा को प्रोसेस कर सकते हैं।
<एच4>7. डेटा अखंडताबग्गी सॉफ़्टवेयर, स्टोरेज डिवाइस में दोष आदि के कारण डेटा ब्लॉक में किसी भी भ्रष्टाचार की जाँच करने के लिए, Hadoop क्लस्टर फ़ाइल के प्रत्येक ब्लॉक पर चेकसम लागू करता है। यदि यह किसी भी ब्लॉक को दूषित पाता है, तो यह एक और डेटानोड बनाने की कोशिश करता है जिसमें उसी ब्लॉक की प्रतिकृति होती है। इस प्रकार, Hadoop क्लस्टर डेटा अखंडता को बनाए रखता है।
सारांश
इस लेख को पढ़ने के बाद, हम कह सकते हैं कि Hadoop क्लस्टर एक विशेष कम्प्यूटेशनल क्लस्टर है जिसे बड़े डेटा के विश्लेषण और भंडारण के लिए डिज़ाइन किया गया है। Hadoop क्लस्टर मास्टर-स्लेव आर्किटेक्चर का अनुसरण करता है।
मास्टर नोड हाई-एंड कंप्यूटर मशीन है, और स्लेव नोड सामान्य सीपीयू और मेमोरी कॉन्फ़िगरेशन वाली मशीनें हैं। हमने यह भी देखा है कि Hadoop क्लस्टर को सिंगल-नोड Hadoop क्लस्टर नामक एक मशीन पर या मल्टी-नोड Hadoop क्लस्टर नामक कई मशीनों पर सेट किया जा सकता है।
इस लेख में, हमने Hadoop क्लस्टर बनाते समय पालन की जाने वाली सर्वोत्तम प्रथाओं को भी शामिल किया था। हमने Hadoop क्लस्टर के कई फायदे भी देखे थे, जिनमें मापनीयता, लचीलापन, लागत-प्रभावशीलता आदि शामिल हैं।



