इस Hadoop ट्यूटोरियल . में , हम आपको Hadoop Combiner का विस्तृत विवरण प्रदान करेंगे। सबसे पहले, हम देखेंगे कि MapReduce Combiner क्या है, MapReduce में Combiner की मुख्य भूमिका क्या है।
फिर हम Hadoop में कॉम्बिनर के साथ और बिना MapReduce प्रोग्राम के उदाहरण पर चर्चा करेंगे। अंत में, हम MapReduce में Combiner के कुछ फायदे और नुकसान भी देखेंगे।
Hadoop Combiner क्या है?
संयोजक इसे “मिनी-रेड्यूसर . के रूप में भी जाना जाता है ” जो मैपर . को सारांशित करता है Reducer . को पास करने से पहले उसी कुंजी के साथ आउटपुट रिकॉर्ड ।
बड़े डेटासेट पर जब हम MapReduce जॉब चलाते हैं। तो मैपर इंटरमीडिएट डेटा का बड़ा हिस्सा उत्पन्न करता है। फिर ढांचा आगे की प्रक्रिया के लिए इस मध्यवर्ती डेटा को रेड्यूसर पर भेजता है।
इससे भारी नेटवर्क जाम हो जाता है। Hadoop फ्रेमवर्क एक फ़ंक्शन प्रदान करता है जिसे Combiner . के रूप में जाना जाता है जो नेटवर्क की भीड़ को कम करने में महत्वपूर्ण भूमिका निभाता है।
कॉम्बिनर का प्राथमिक काम "मिनी-रेड्यूसर" मैपर से आउटपुट डेटा को रेड्यूसर को पास करने से पहले संसाधित करना है। यह मैपर के बाद और रेड्यूसर से पहले चलता है। इसका उपयोग वैकल्पिक है।
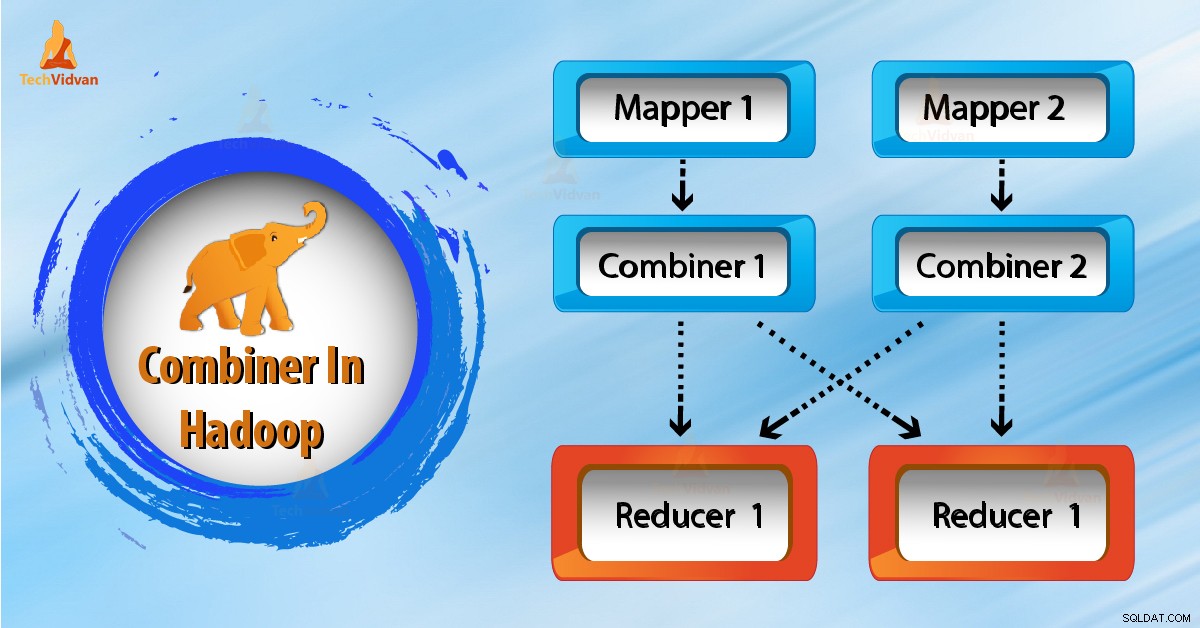
हाडोप में कॉम्बिनर कैसे काम करता है?
अब आइए जानें कि जब हम MapReduce में कॉम्बिनर का उपयोग करते हैं तो चीजें कैसे बदलती हैं?

जैसा कि हम उपरोक्त चित्र में देखते हैं, कोई संयोजक नहीं है। इनपुट दो मैपर में विभाजित है। फ्रेमवर्क मैपर्स से 9 कुंजियाँ उत्पन्न करता है।
तो, अब हमारे पास (9 कुंजी/मान) मध्यवर्ती डेटा है। आगे मैपर यह कुंजी-मान भेजता है सीधे रेड्यूसर के लिए। रेड्यूसर को डेटा भेजते समय, यह कुछ नेटवर्क बैंडविड्थ की खपत करता है। डेटा का आकार बड़ा होने पर डेटा को रिड्यूसर में स्थानांतरित करने में अधिक समय लगता है।

अब उपरोक्त आरेख से, यदि हम मैपर और रेड्यूसर के बीच एक संयोजक का उपयोग करते हैं। फिर कॉम्बिनर रिड्यूसर को भेजने से पहले 9 की/वैल्यू को फेरबदल करेगा। और फिर आउटपुट के रूप में 4 की/वैल्यू पेयर जेनरेट करता है।
अब, रेड्यूसर को केवल 4 कुंजी/मूल्य जोड़ी डेटा को संसाधित करने की आवश्यकता है जो 2 संयोजकों से उत्पन्न होते हैं। इसलिए अंतिम आउटपुट का उत्पादन करने के लिए रेड्यूसर केवल 4 बार निष्पादित होता है। इस प्रकार, यह समग्र प्रदर्शन को बढ़ाता है।
MapReduce में कॉम्बिनर के लाभ
आइए अब MapReduce में Hadoop Combiner के लाभों पर चर्चा करें।
- कॉम्बिनर के उपयोग से मैपर और रेड्यूसर के बीच डेटा ट्रांसफर में लगने वाला समय कम हो जाता है।
- Combiner रिड्यूसर के समग्र प्रदर्शन में सुधार करता है।
- यह उस डेटा की मात्रा को कम करता है जिसे रेड्यूसर को संसाधित करना होता है।
MapReduce में कॉम्बिनर के नुकसान
Hadoop Combiner के कुछ नुकसान भी हैं। आइए अब उसी पर चर्चा करें।
- स्थानीय फाइल सिस्टम में, जब Hadoop की-वैल्यू पेयर को स्टोर करता है और बाद में कंबाइनर चलाता है तो यह महंगी डिस्क IO का कारण बनेगा।
- MapReduce जॉब कॉम्बिनर निष्पादन पर निर्भर नहीं हो सकती क्योंकि इसके निष्पादन में कोई गारंटी नहीं है।
निष्कर्ष
इसलिए, नेटवर्क की भीड़ को कम करने में Hadoop Combiner एक महत्वपूर्ण भूमिका निभाता है। यह मैपर के आउटपुट को सारांशित करके रेड्यूसर के समग्र प्रदर्शन में सुधार करता है।
मुझे आशा है कि अब आपको Hadoop Combiner की स्पष्ट समझ हो गई होगी। यदि अभी भी आपके पास कोई प्रश्न है, तो कृपया हमें बताएं कि नीचे एक अनुभाग में एक टिप्पणी छोड़ दें।



