इसका मुख्य लक्ष्य Hadoop Tutorial आपको प्रत्येक घटक का विस्तृत विवरण प्रदान करना है जिसका उपयोग Hadoop कार्य में किया जाता है। इस ट्यूटोरियल में, हम Hadoop में पार्टिशनर को कवर करने जा रहे हैं।
Hadoop पार्टिशनर क्या है, Hadoop में पार्टिशनर की क्या आवश्यकता है, MapReduce में डिफॉल्ट पार्टिशनर क्या है, Hadoop में कितने MapReduce पार्टिशनर का उपयोग किया जाता है?
हम इस MapReduce ट्यूटोरियल में इन सभी सवालों के जवाब देंगे।
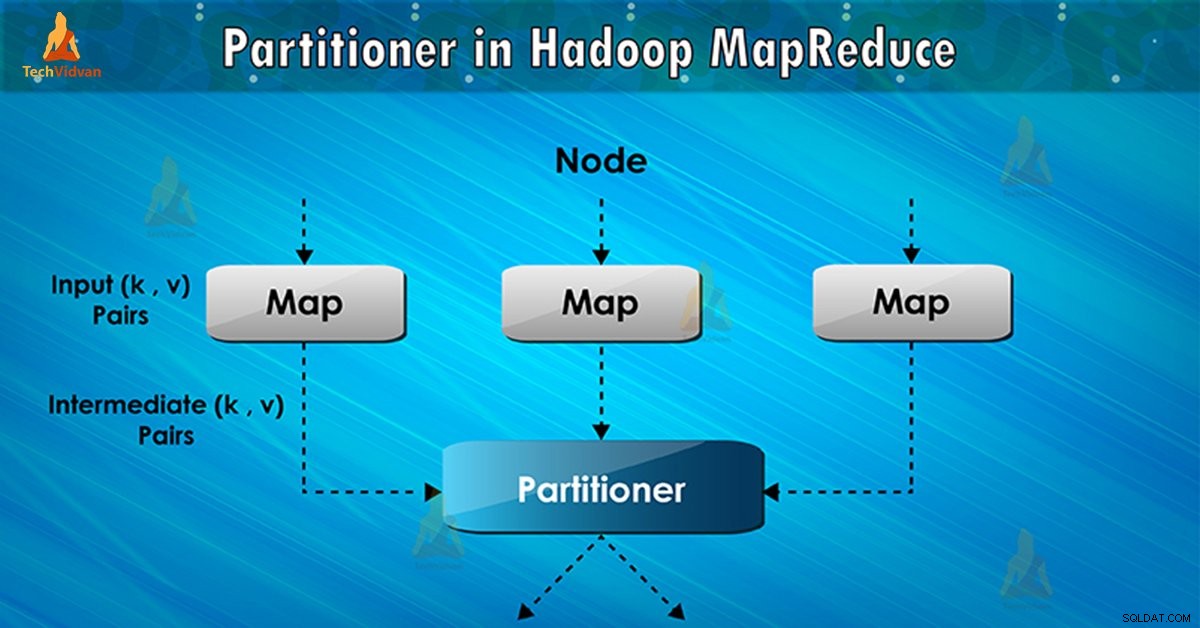
Hadoop पार्टिशनर क्या है?
MapReduce कार्य निष्पादन में पार्टिशनर मध्यवर्ती मानचित्र-आउटपुट की कुंजियों के विभाजन को नियंत्रित करता है। हैश फ़ंक्शन की सहायता से, कुंजी (या कुंजी का एक उपसमुच्चय) विभाजन को प्राप्त करता है। विभाजन की कुल संख्या कम कार्यों की संख्या के बराबर है।
कुंजी मान . के आधार पर , फ्रेमवर्क विभाजन, प्रत्येक मैपर आउटपुट समान कुंजी मान वाले रिकॉर्ड एक ही विभाजन (प्रत्येक मैपर के भीतर) में जाते हैं। फिर प्रत्येक विभाजन एक reducer . को भेजा जाता है ।
विभाजन वर्ग तय करता है कि कौन सा विभाजन दिया गया है (कुंजी, मान) जोड़ी जाएगी। MapReduce डेटा प्रवाह में विभाजन चरण मानचित्र चरण के बाद और चरण कम करने से पहले होता है।
Hadoop में MapReduce Partitioner की आवश्यकता
MapReduce कार्य निष्पादन में, यह एक इनपुट डेटा सेट लेता है और कुंजी मान युग्म की सूची तैयार करता है। ये की-वैल्यू पेयर मैप फेज का परिणाम है। जिसमें इनपुट डेटा विभाजित होता है और प्रत्येक कार्य विभाजन को संसाधित करता है और प्रत्येक मानचित्र, कुंजी मान जोड़े की सूची को आउटपुट करता है।
फिर, फ्रेमवर्क कार्य को कम करने के लिए मानचित्र आउटपुट भेजता है। मानचित्र आउटपुट पर उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन को कम करें। चरण कम करने से पहले, मानचित्र आउटपुट का विभाजन कुंजी के आधार पर होता है।
Hadoop विभाजन निर्दिष्ट करता है कि प्रत्येक कुंजी के सभी मान एक साथ समूहीकृत किए जाते हैं। यह यह भी सुनिश्चित करता है कि एक ही कुंजी के सभी मान एक ही रेड्यूसर पर जाएं। यह रेड्यूसर पर मैप आउटपुट के समान वितरण की अनुमति देता है।
MapReduce जॉब में पार्टिशनर यह निर्धारित करके मैपर आउटपुट को रिड्यूसर पर रीडायरेक्ट करता है कि कौन सा रिड्यूसर विशेष कुंजी को हैंडल करता है।
Hadoop डिफ़ॉल्ट पार्टिशनर
हैश पार्टिशनर डिफ़ॉल्ट पार्टिशनर है। यह कुंजी के लिए हैश मान की गणना करता है। यह इस परिणाम के आधार पर विभाजन भी निर्दिष्ट करता है।
Hadoop में कितने पार्टिशनर हैं?
पार्टिशनर की कुल संख्या रेड्यूसर की संख्या पर निर्भर करती है। Hadoop Partitioner डेटा को रेड्यूसर की संख्या के अनुसार विभाजित करता है। यह JobConf.setNumReduceTasks() . द्वारा सेट किया गया है विधि।
इस प्रकार सिंगल रेड्यूसर सिंगल पार्टीशनर से डेटा को प्रोसेस करता है। ध्यान देने वाली महत्वपूर्ण बात यह है कि फ्रेमवर्क केवल तभी विभाजनकर्ता बनाता है जब कई रिड्यूसर हों।
Hadoop MapReduce में खराब विभाजन
यदि MapReduce जॉब में डेटा इनपुट में एक कुंजी किसी अन्य कुंजी से अधिक दिखाई देती है। ऐसी स्थिति में, विभाजन को डेटा भेजने के लिए हम दो तंत्रों का उपयोग करते हैं जो इस प्रकार हैं:
- अधिक संख्या में प्रदर्शित होने वाली कुंजी एक पार्टीशन को भेजी जाएगी।
- अन्य सभी कुंजी उनके हैशकोड () . के आधार पर विभाजन में भेजी जाएंगी ।
अगर हैशकोड () विधि अन्य प्रमुख डेटा को विभाजन श्रेणी में वितरित नहीं करती है। तब डेटा रिड्यूसर को नहीं भेजा जाएगा।
डेटा के खराब विभाजन का मतलब है कि कुछ रिड्यूसर में अन्य की तुलना में अधिक डेटा इनपुट होगा। उनके पास अन्य रेड्यूसर की तुलना में अधिक काम होगा। इस प्रकार पूरे काम को लोड के अपने अतिरिक्त बड़े हिस्से को पूरा करने के लिए एक रेड्यूसर की प्रतीक्षा करनी पड़ती है।
MapReduce में खराब विभाजन को कैसे दूर करें?
Hadoop MapReduce में खराब पार्टीशनर को दूर करने के लिए, हम कस्टम पार्टीशनर बना सकते हैं। यह विभिन्न रेड्यूसर में कार्यभार साझा करने की अनुमति देता है।
निष्कर्ष
अंत में, पार्टिशनर रेड्यूसर पर मैप आउटपुट के समान वितरण की अनुमति देता है। MapReducer Partitioner में, मानचित्र आउटपुट का विभाजन कुंजी और मान के आधार पर होता है।
इसलिए, हमने इस ब्लॉग में पार्टिशनर के संपूर्ण अवलोकन को कवर किया है। आशा है आपको पसंद है। यदि हडूप पार्टिशनर के बारे में आपके मन में कोई संदेह आता है, तो हमारे साथ साझा करना न भूलें।



