डेटाबेस को बेहतर तरीके से चलाने की जरूरत है, लेकिन यह इतना आसान काम नहीं है। सूचना स्कीमा डेटाबेस डेटाबेस अनुकूलन के युद्ध में आपका गुप्त हथियार हो सकता है।
हम ग्राफिकल इंटरफ़ेस या SQL कमांड की एक श्रृंखला का उपयोग करके डेटाबेस बनाने के लिए उपयोग किए जाते हैं। यह पूरी तरह से ठीक है, लेकिन पृष्ठभूमि में क्या हो रहा है, इसके बारे में थोड़ा समझना भी अच्छा है। यह डेटाबेस के निर्माण, रखरखाव और अनुकूलन के लिए महत्वपूर्ण है, और यह 'पर्दे के पीछे' होने वाले परिवर्तनों को ट्रैक करने का एक अच्छा तरीका भी है।
इस लेख में, हम मुट्ठी भर SQL प्रश्नों को देखेंगे जो आपको MySQL डेटाबेस के कामकाज में मदद कर सकते हैं।
INFORMATION_SCHEMA डेटाबेस
हम पहले ही INFORMATION_SCHEMA . पर चर्चा कर चुके हैं इस लेख में डेटाबेस। यदि आपने इसे पहले से नहीं पढ़ा है, तो मैं निश्चित रूप से सुझाव दूंगा कि आप इसे जारी रखने से पहले करें।
यदि आपको INFORMATION_SCHEMA . पर पुनश्चर्या की आवश्यकता है डेटाबेस - या यदि आप पहला लेख नहीं पढ़ने का निर्णय लेते हैं - तो यहां कुछ बुनियादी तथ्य दिए गए हैं जिन्हें आपको जानना आवश्यक है:
INFORMATION_SCHEMAडेटाबेस एएनएसआई मानक का हिस्सा है। हम MySQL के साथ काम करेंगे, लेकिन अन्य RDBMS के अपने रूप हैं। आप H2 डेटाबेस, HSQLDB, MariaDB, Microsoft SQL Server और PostgreSQL के संस्करण पा सकते हैं।- यह वह डेटाबेस है जो सर्वर पर अन्य सभी डेटाबेस का ट्रैक रखता है; हमें यहां सभी वस्तुओं का विवरण मिलेगा।
- किसी भी अन्य डेटाबेस की तरह,
INFORMATION_SCHEMAडेटाबेस में कई संबंधित टेबल और विभिन्न वस्तुओं के बारे में जानकारी होती है। - आप SQL का उपयोग करके इस डेटाबेस को क्वेरी कर सकते हैं और इसके परिणामों का उपयोग कर सकते हैं:
- डेटाबेस की स्थिति और प्रदर्शन की निगरानी करें, और
- क्वेरी परिणामों के आधार पर स्वचालित रूप से कोड जनरेट करें।
अब INFORMATION_SCHEMA डेटाबेस को क्वेरी करने के लिए आगे बढ़ते हैं। हम उस डेटा मॉडल को देखकर शुरू करेंगे जिसका हम उपयोग करने जा रहे हैं।
डेटा मॉडल
इस लेख में हम जिस मॉडल का उपयोग करेंगे, वह नीचे दिखाया गया है।
यह एक सरलीकृत मॉडल है जो हमें कक्षाओं, प्रशिक्षकों, छात्रों और अन्य संबंधित विवरणों के बारे में जानकारी संग्रहीत करने की अनुमति देता है। आइए संक्षेप में तालिकाओं पर चलते हैं।
हम प्रशिक्षकों की सूची lecturer टेबल। प्रत्येक व्याख्याता के लिए, हम एक first_name रिकॉर्ड करेंगे और एक last_name ।
class तालिका हमारे विद्यालय में सभी कक्षाओं को सूचीबद्ध करती है। इस तालिका में प्रत्येक रिकॉर्ड के लिए, हम class_name . स्टोर करेंगे , व्याख्याता की आईडी, एक नियोजित start_date और end_date , और कोई भी अतिरिक्त class_details . सादगी के लिए, मैं मान लूंगा कि हमारे पास प्रति कक्षा केवल एक व्याख्याता है।
कक्षाएं आमतौर पर व्याख्यान की एक श्रृंखला के रूप में आयोजित की जाती हैं। उन्हें आम तौर पर एक या अधिक परीक्षाओं की आवश्यकता होती है। हम संबंधित व्याख्यानों और परीक्षाओं की सूचियां lecture और exam टेबल। दोनों के पास संबंधित वर्ग की आईडी और अपेक्षित start_time होगा और end_time ।
अब हमें अपनी कक्षाओं के लिए छात्रों की जरूरत है। सभी विद्यार्थियों की सूची student टेबल। एक बार फिर, हम केवल first_name संग्रहित करेंगे और last_name प्रत्येक छात्र का।
अंतिम चीज़ जो हमें करने की ज़रूरत है वह है छात्रों की गतिविधियों पर नज़र रखना। हम प्रत्येक कक्षा के लिए पंजीकृत छात्र की सूची, छात्र की उपस्थिति रिकॉर्ड और उनके परीक्षा परिणामों की एक सूची संग्रहीत करेंगे। शेष तीन तालिकाओं में से प्रत्येक – on_class , on_lecture और on_exam - इसमें छात्र का संदर्भ और उपयुक्त तालिका का संदर्भ होगा। केवल on_exam तालिका का एक अतिरिक्त मान होगा:ग्रेड।
हाँ, यह मॉडल बहुत सरल है। हम छात्रों, व्याख्याताओं और कक्षाओं के बारे में कई अन्य विवरण जोड़ सकते हैं। रिकॉर्ड अपडेट या हटाए जाने पर हम ऐतिहासिक मूल्यों को संग्रहीत कर सकते हैं। फिर भी, यह मॉडल इस लेख के प्रयोजनों के लिए पर्याप्त होगा।
डेटाबेस बनाना
हम अपने स्थानीय सर्वर पर एक डेटाबेस बनाने और उसके अंदर क्या हो रहा है इसकी जांच करने के लिए तैयार हैं। हम "Generate SQL script . का उपयोग करके मॉडल (वर्टबेलो में) निर्यात करेंगे " बटन।
फिर हम MySQL सर्वर इंस्टेंस पर एक डेटाबेस बनाएंगे। मैंने अपने डेटाबेस को “classes_and_students . कहा है "
अगली चीज़ जो हमें करने की ज़रूरत है वह है पहले से जेनरेट की गई SQL स्क्रिप्ट को चलाना।
अब हमारे पास इसकी सभी वस्तुओं (टेबल, प्राथमिक और विदेशी कुंजी, वैकल्पिक कुंजी) के साथ डेटाबेस है।
डेटाबेस आकार
स्क्रिप्ट चलने के बाद, “classes and students . के बारे में डेटा "डेटाबेस INFORMATION_SCHEMA . में संग्रहीत है डेटाबेस। यह डेटा कई अलग-अलग तालिकाओं में है। मैं उन सभी को यहाँ फिर से सूचीबद्ध नहीं करूँगा; हमने पिछले लेख में ऐसा किया था।
आइए देखें कि हम इस डेटाबेस पर मानक SQL का उपयोग कैसे कर सकते हैं। मैं एक बहुत ही महत्वपूर्ण प्रश्न के साथ शुरुआत करूंगा:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
हम केवल INFORMATION_SCHEMA.TABLES यहाँ तालिका। इस तालिका से हमें सर्वर पर सभी तालिकाओं के बारे में पर्याप्त से अधिक जानकारी मिलनी चाहिए। कृपया ध्यान दें कि मैंने "classes_and_students से केवल तालिकाओं को फ़िल्टर किया है "डेटाबेस SET का उपयोग कर रहा है पहली पंक्ति में चर और बाद में क्वेरी में इस मान का उपयोग करना। अधिकांश तालिकाओं में TABLE_NAME स्तंभ होते हैं और TABLE_SCHEMA , जो इस डेटा से संबंधित तालिका और स्कीमा/डेटाबेस को दर्शाता है।
यह क्वेरी हमारे डेटाबेस का वर्तमान आकार और हमारे डेटाबेस के लिए आरक्षित खाली स्थान लौटा देगी। यहाँ वास्तविक परिणाम है:

जैसा कि अपेक्षित था, हमारे खाली डेटाबेस का आकार 1 एमबी से कम है, और आरक्षित खाली स्थान बहुत अधिक है।
तालिका आकार और गुण
अगली दिलचस्प बात यह होगी कि हमारे डेटाबेस में तालिकाओं के आकार को देखें। ऐसा करने के लिए, हम निम्नलिखित क्वेरी का उपयोग करेंगे:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
क्वेरी पिछले वाले के लगभग समान है, एक अपवाद के साथ:परिणाम तालिका स्तर पर समूहीकृत है।
इस क्वेरी द्वारा दिए गए परिणाम की एक तस्वीर यहां दी गई है:
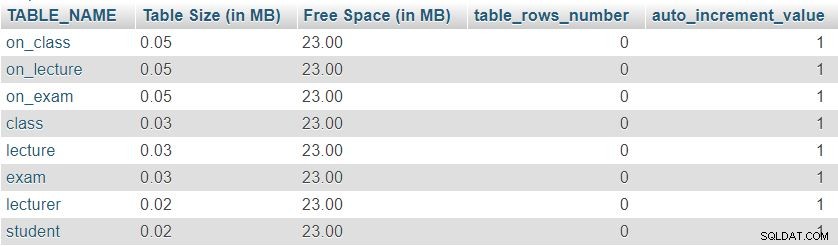
सबसे पहले, हम देख सकते हैं कि सभी आठ तालिकाओं में न्यूनतम “तालिका आकार” . है तालिका परिभाषा के लिए आरक्षित, जिसमें कॉलम, प्राथमिक कुंजी और अनुक्रमणिका शामिल है। “खाली जगह” सभी तालिकाओं के बीच समान रूप से वितरित किया जाता है।
हम वर्तमान में प्रत्येक तालिका में पंक्तियों की संख्या और auto_increment के वर्तमान मान को भी देख सकते हैं प्रत्येक तालिका के लिए संपत्ति। चूंकि सभी टेबल पूरी तरह से खाली हैं, इसलिए हमारे पास कोई डेटा नहीं है और auto_increment 1 पर सेट है (एक मान जो अगली सम्मिलित पंक्ति को सौंपा जाएगा)।
प्राथमिक कुंजियां
प्रत्येक तालिका में प्राथमिक कुंजी मान परिभाषित होना चाहिए, इसलिए यह जांचना बुद्धिमानी है कि यह हमारे डेटाबेस के लिए सही है या नहीं। ऐसा करने का एक तरीका बाधाओं की सूची के साथ सभी तालिकाओं की सूची में शामिल होना है। इससे हमें वह जानकारी मिलनी चाहिए जिसकी हमें आवश्यकता है।
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
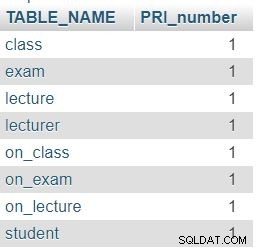
हमने INFORMATION_SCHEMA.COLUMNS इस क्वेरी में तालिका। जबकि क्वेरी का पहला भाग डेटाबेस में सभी तालिकाओं को वापस कर देगा, दूसरा भाग (LEFT JOIN के बाद) ) इन तालिकाओं में पंचायती राज संस्थाओं की संख्या की गणना करेगा। हमने LEFT JOIN . का इस्तेमाल किया क्योंकि हम देखना चाहते हैं कि क्या किसी तालिका में COLUMNS . में 0 PRI है टेबल।
जैसा कि अपेक्षित था, हमारे डेटाबेस में प्रत्येक तालिका में ठीक एक प्राथमिक कुंजी (पीआरआई) कॉलम होता है।
“द्वीप”?
"द्वीप" टेबल हैं जो बाकी मॉडल से पूरी तरह से अलग हैं। वे तब होते हैं जब किसी तालिका में कोई विदेशी कुंजी नहीं होती है और किसी अन्य तालिका में संदर्भित नहीं होती है। यह वास्तव में तब तक नहीं होना चाहिए जब तक कि वास्तव में कोई अच्छा कारण न हो, उदा। जब तालिकाओं में पैरामीटर होते हैं या मॉडल के अंदर परिणाम या रिपोर्ट संग्रहीत करते हैं।
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
इस क्वेरी के पीछे क्या विचार है? ठीक है, हम INFORMATION_SCHEMA.KEY_COLUMN_USAGE तालिका का परीक्षण करने के लिए कि क्या तालिका का कोई स्तंभ किसी अन्य तालिका का संदर्भ है या यदि किसी स्तंभ का उपयोग किसी अन्य तालिका में संदर्भ के रूप में किया जाता है। क्वेरी का पहला भाग सभी तालिकाओं का चयन करता है। पहले LEFT JOIN के बाद, हम इस तालिका के किसी भी कॉलम को संदर्भ के रूप में उपयोग किए जाने की संख्या की गणना करते हैं। दूसरे LEFT JOIN के बाद, हम इस तालिका के किसी भी कॉलम को किसी अन्य तालिका के संदर्भ में गिनते हैं।
लौटाया गया परिणाम है:
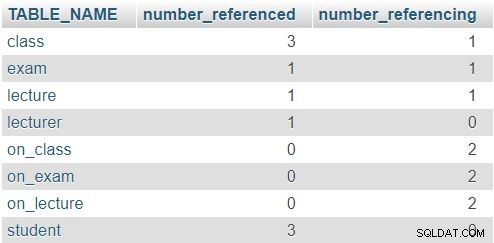
class तालिका, संख्या 3 और 1 इंगित करती है कि इस तालिका को तीन बार संदर्भित किया गया था (lecture , exam , और on_class टेबल) और यह कि इसमें एक विशेषता है जो दूसरी तालिका को संदर्भित करती है (lecturer_id ) अन्य तालिकाएँ समान पैटर्न का अनुसरण करती हैं, हालाँकि वास्तविक संख्याएँ निश्चित रूप से भिन्न होंगी। यहां नियम यह है कि किसी भी पंक्ति में दोनों स्तंभों में 0 नहीं होना चाहिए।
पंक्तियां जोड़ना
अब तक, सब कुछ उम्मीद के मुताबिक ही हुआ है। हमने अपने डेटा मॉडल को वर्टाबेलो से स्थानीय MySQL सर्वर में सफलतापूर्वक आयात कर लिया है। सभी तालिकाओं में कुंजियाँ होती हैं, जैसा हम चाहते हैं, और सभी तालिकाएँ एक-दूसरे से संबंधित हैं - हमारे मॉडल में कोई "द्वीप" नहीं है।
अब, हम अपनी तालिकाओं में कुछ पंक्तियाँ सम्मिलित करेंगे और हमारे डेटाबेस में परिवर्तनों को ट्रैक करने के लिए पहले प्रदर्शित प्रश्नों का उपयोग करेंगे।
व्याख्याता तालिका में 1,000 पंक्तियों को जोड़ने के बाद, हम फिर से "Table Sizes and Properties से क्वेरी चलाएंगे। " खंड। यह निम्नलिखित परिणाम लौटाएगा:
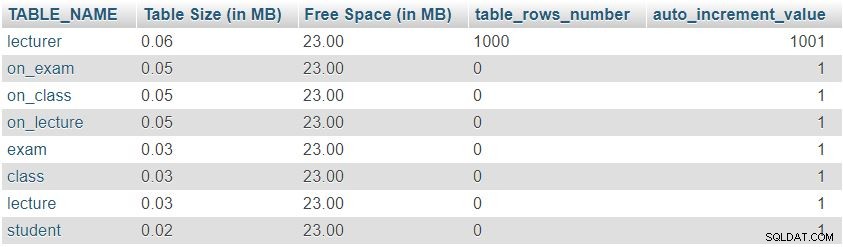
हम आसानी से देख सकते हैं कि पंक्तियों की संख्या और auto_increment मान अपेक्षानुसार बदल गए हैं, लेकिन तालिका के आकार में कोई महत्वपूर्ण परिवर्तन नहीं हुआ है।
यह सिर्फ एक परीक्षण उदाहरण था; वास्तविक जीवन की स्थितियों में, हम महत्वपूर्ण परिवर्तन देखेंगे। पंक्तियों की संख्या उपयोगकर्ताओं या स्वचालित प्रक्रियाओं (अर्थात तालिकाएँ जो शब्दकोश नहीं हैं) द्वारा पॉप्युलेट की गई तालिकाओं में भारी रूप से बदल जाएगी। ऐसी तालिकाओं के आकार और मूल्यों की जाँच करना अवांछित व्यवहार को शीघ्रता से ढूँढ़ने और ठीक करने का एक बहुत अच्छा तरीका है।
साझा करना चाहते हैं?
डेटाबेस के साथ काम करना इष्टतम प्रदर्शन के लिए निरंतर खोज है। उस खोज में और अधिक सफल होने के लिए, आपको उपलब्ध किसी भी उपकरण का उपयोग करना चाहिए। आज हमने कुछ प्रश्न देखे हैं जो बेहतर प्रदर्शन के लिए हमारी लड़ाई में उपयोगी हैं। क्या आपको कुछ और उपयोगी लगा? क्या आपने INFORMATION_SCHEMA . के साथ खेला है पहले डेटाबेस? नीचे दी गई टिप्पणियों में अपना अनुभव साझा करें।



