उपयोगकर्ता के अनुकूल खोज को लागू करना मुश्किल हो सकता है, लेकिन इसे बहुत कुशलता से भी किया जा सकता है। मुझे इसके बारे में कैसे पता है? कुछ समय पहले, मुझे एक मोबाइल ऐप पर एक खोज इंजन लागू करने की आवश्यकता थी। ऐप Ionic फ्रेमवर्क पर बनाया गया था और यह CakePHP 2 बैकएंड से कनेक्ट होगा। जब उपयोगकर्ता टाइप कर रहा था तब परिणाम प्रदर्शित करने का विचार था। इसके लिए कई विकल्प थे, लेकिन उनमें से सभी मेरी परियोजना की आवश्यकताओं को पूरा नहीं करते थे।
यह स्पष्ट करने के लिए कि इस प्रकार के कार्य में क्या शामिल है, आइए गीतों और उनके संभावित संबंधों (जैसे कलाकार, एल्बम, आदि) की खोज करने की कल्पना करें।
रिकॉर्ड्स को प्रासंगिकता के आधार पर क्रमबद्ध करना होगा, जो इस बात पर निर्भर करेगा कि खोज शब्द रिकॉर्ड से ही मेल खाता है या संबंधित तालिकाओं में अन्य कॉलम से मेल खाता है। साथ ही, खोज को कम से कम कुछ बुनियादी शब्द उपजी को लागू करना चाहिए। (स्टेमिंग का उपयोग किसी शब्द के मूल रूप को प्राप्त करने के लिए किया जाता है। "स्टेम", "स्टेमर", "स्टेमिंग", और "स्टेमिंग" सभी की जड़ एक ही होती है:"स्टेम"।)
यहां प्रस्तुत दृष्टिकोण का परीक्षण कई लाख रिकॉर्ड के साथ किया गया था और उपयोगकर्ता के टाइप करते समय उपयोगी परिणाम प्राप्त करने में सक्षम था।
पूर्ण-पाठ खोज उत्पादों पर विचार करें
ऐसे कई तरीके हैं जिनसे हम इस तरह की खोज को लागू कर सकते हैं। समय और सर्वर संसाधनों के संबंध में हमारी परियोजना में कुछ बाधाएं थीं, इसलिए हमें समाधान को यथासंभव सरल रखना था। अंततः कुछ दावेदार सामने आए:
इलास्टिक्स खोज
Elasticsearch दस्तावेज़-उन्मुख सेवा में पूर्ण-पाठ खोज प्रदान करता है। इसे वितरित तरीके से भारी मात्रा में लोड का प्रबंधन करने के लिए डिज़ाइन किया गया है:यह प्रासंगिकता के आधार पर परिणामों को रैंक कर सकता है, एकत्रीकरण कर सकता है, और शब्द स्टेमिंग के साथ काम कर सकता है और समानार्थी शब्द। यह टूल रियल टाइम सर्च के लिए है। उनकी वेबसाइट से:
Elasticsearch उपलब्ध सबसे शक्तिशाली पूर्ण-पाठ खोज क्षमताओं को प्रदान करने के लिए Apache Lucene के शीर्ष पर वितरित क्षमताओं का निर्माण करता है। शक्तिशाली, डेवलपर के अनुकूल क्वेरी API बहुभाषी खोज, भौगोलिक स्थान, प्रासंगिक डीड-यू-मीन सुझावों, स्वतः पूर्ण, और परिणाम स्निपेट का समर्थन करता है।
Elasticsearch एक REST सेवा के रूप में काम कर सकता है, http अनुरोधों का जवाब दे सकता है, और इसे बहुत जल्दी स्थापित किया जा सकता है। हालांकि, इंजन को एक सेवा के रूप में शुरू करने के लिए आपको कुछ सर्वर एक्सेस विशेषाधिकारों की आवश्यकता होती है। और यदि आपका होस्टिंग प्रदाता लीक से हटकर Elasticsearch का समर्थन नहीं करता है, तो आपको कुछ पैकेज इंस्टॉल करने होंगे।
लब्बोलुआब यह है कि यदि आप एक रॉक-सॉलिड सर्च सॉल्यूशन चाहते हैं तो यह उत्पाद एक बढ़िया विकल्प है। (नोट:आपको एक वीपीएस या समर्पित सर्वर की आवश्यकता हो सकती है क्योंकि हार्डवेयर आवश्यकताएं काफी मांग वाली हैं।)
स्फिंक्स
इलास्टिक्स खोज की तरह, स्फिंक्स भी एक बहुत ही ठोस पूर्ण-पाठ खोज उत्पाद प्रदान करता है:क्रेगलिस्ट इसके साथ प्रति दिन 300,000,000 से अधिक प्रश्नों की सेवा करता है। स्फिंक्स एक देशी रीस्टफुल इंटरफ़ेस प्रदान नहीं करता है। यह सी में लागू किया गया है, इलास्टिक्स खोज की तुलना में एक छोटे हार्डवेयर पदचिह्न के साथ (जो जावा में लागू किया गया है और किसी भी ओएस पर एक जेवीएम के साथ चल सकता है)। Sphinx को ठीक से चलाने के लिए आपको कुछ समर्पित RAM/CPU के साथ सर्वर तक रूट पहुंच की भी आवश्यकता होगी।
MySQL पूर्ण-पाठ खोज
ऐतिहासिक रूप से, MyISAM इंजन में पूर्ण-पाठ खोजों का समर्थन किया गया था। संस्करण 5.6 के बाद, MySQL ने InnoDB स्टोरेज इंजन में पूर्ण-पाठ खोजों का भी समर्थन किया। यह बहुत अच्छी खबर रही है, क्योंकि यह डेवलपर्स को InnoDB की संदर्भात्मक अखंडता, लेनदेन करने की क्षमता और पंक्ति स्तर के ताले से लाभ उठाने में सक्षम बनाता है।
MySQL में मूल रूप से पूर्ण-पाठ खोजों के दो दृष्टिकोण हैं:प्राकृतिक भाषा और बूलियन मोड। (तीसरा विकल्प दूसरी विस्तार क्वेरी के साथ प्राकृतिक भाषा खोज को बढ़ाता है।)
प्राकृतिक और बूलियन मोड के बीच मुख्य अंतर यह है कि बूलियन कुछ ऑपरेटरों को खोज के हिस्से के रूप में अनुमति देता है। उदाहरण के लिए, बूलियन ऑपरेटरों का उपयोग किया जा सकता है यदि किसी शब्द की क्वेरी में दूसरों की तुलना में अधिक प्रासंगिकता है या यदि कोई विशिष्ट शब्द परिणामों में मौजूद होना चाहिए, आदि। यह ध्यान देने योग्य है कि दोनों मामलों में, परिणामों को प्रासंगिकता द्वारा क्रमबद्ध किया जा सकता है खोज के दौरान MySQL.
निर्णय लेना
हमारी समस्या के लिए सबसे उपयुक्त बूलियन मोड में InnoDb पूर्ण-पाठ खोजों का उपयोग करना था। क्यों?
- खोज फ़ंक्शन को लागू करने के लिए हमारे पास बहुत कम समय था।
- इस समय, हमारे पास क्रंच करने के लिए कोई बड़ा डेटा नहीं था और न ही इलास्टिक्स खोज या स्फिंक्स जैसी किसी चीज़ की आवश्यकता के लिए भारी भार था।
- हमने साझा होस्टिंग का उपयोग किया है जो Elasticsearch या Sphinx का समर्थन नहीं करती है और इस स्तर पर हार्डवेयर काफी सीमित था।
- जबकि हम अपने खोज फ़ंक्शन में शब्द स्टेमिंग चाहते थे, यह एक सौदा ब्रेकर नहीं था:हम कुछ सरल PHP कोडिंग और डेटा डीनॉर्मलाइज़ेशन के माध्यम से इसे (बाधाओं के भीतर) लागू कर सकते थे
- बूलियन मोड में पूर्ण-पाठ खोज वाइल्डकार्ड (स्टेमिंग शब्द के लिए) के साथ शब्दों को खोज सकते हैं और प्रासंगिकता के आधार पर परिणामों को क्रमबद्ध कर सकते हैं।
बूलियन मोड में पूर्ण-पाठ खोज
जैसा कि पहले उल्लेख किया गया है, प्राकृतिक भाषा खोज सबसे सरल तरीका है:कॉलम में केवल एक वाक्यांश या एक शब्द खोजें जहां आपने एक पूर्ण-पाठ अनुक्रमणिका सेट की है और आपको प्रासंगिकता के आधार पर परिणाम मिलेंगे।
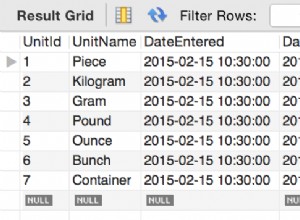
सामान्यीकृत वर्टाबेलो मॉडल में
आइए देखें कि एक साधारण खोज कैसे काम करेगी। हम पहले एक नमूना तालिका बनाएंगे:
-- वर्टाबेलो द्वारा बनाया गया (https://vertabelo.com)-- अंतिम संशोधन दिनांक:2016-04-25 15:01:22.153-- टेबल्स-- टेबल:आर्टिस्टक्रिएट टेबल आर्टिस्ट (आईडी int(11) नहीं NULL AUTO_INCREMENT, नाम varchar(255) NOT NULL, बायो टेक्स्ट नॉट NULL, CONSTRAINT Artist_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX Artist_idx_1 ऑन आर्टिस्ट (नाम);-- फाइल का अंत।
प्राकृतिक भाषा मोड में
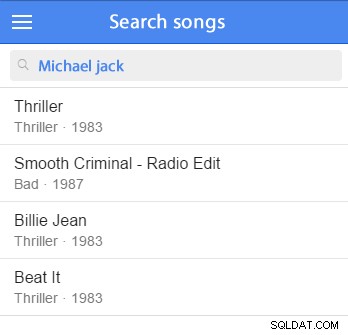
आप कुछ नमूना डेटा सम्मिलित कर सकते हैं और परीक्षण शुरू कर सकते हैं। (इसे अपने नमूना डेटासेट में जोड़ना अच्छा होगा।) उदाहरण के लिए, हम माइकल जैक्सन को खोजने का प्रयास करेंगे:
चुनें *कलाकारों से जहां मैच (कलाकारों का नाम) के खिलाफ ('माइकल जैक्सन' प्राकृतिक भाषा मोड में)
इस क्वेरी में ऐसे रिकॉर्ड मिलेंगे जो खोज शब्दों से मेल खाते हैं और प्रासंगिकता के आधार पर मिलान रिकॉर्ड को सॉर्ट करेंगे; मैच जितना बेहतर होगा, उतना ही प्रासंगिक होगा और सूची में परिणाम उतना ही अधिक दिखाई देगा।
बूलियन मोड में
हम वही खोज बूलियन मोड में कर सकते हैं। यदि हम अपनी क्वेरी पर कोई भी ऑपरेटर लागू नहीं करते हैं, तो अंतर केवल इतना होगा कि परिणाम नहीं . हैं प्रासंगिकता के अनुसार क्रमबद्ध:
चुनें *कलाकारों से जहां मैच (कलाकारों का नाम) के खिलाफ (बूलियन मोड में 'माइकल जैक्सन')
वाइल्डकार्ड ऑपरेटर बूलियन मोड में है
चूँकि हम तने हुए और आंशिक शब्दों को खोजना चाहते हैं, हमें वाइल्डकार्ड ऑपरेटर (*) की आवश्यकता होगी। इस ऑपरेटर का उपयोग बूलियन मोड खोजों में किया जा सकता है, यही वजह है कि हमने उस मोड को चुना।
तो, आइए बूलियन खोज की शक्ति को उजागर करें और कलाकार के नाम के हिस्से को खोजने का प्रयास करें। हम वाइल्डकार्ड ऑपरेटर का उपयोग ऐसे किसी भी कलाकार से मिलान करने के लिए करेंगे जिसका नाम 'मिच' से शुरू होता है:
चुनें *कलाकारों से जहां मैच (नाम) के खिलाफ (बूलियन मोड में 'मिच*')
बूलियन मोड में प्रासंगिकता के अनुसार क्रमित करना
अब आइए खोज के लिए परिकलित प्रासंगिकता देखें। इससे हमें यह समझने में मदद मिलेगी कि हम बाद में केक के साथ किस प्रकार की छँटाई करेंगे:
चुनें *, मैच (नाम) के खिलाफ (बूलियन मोड में 'mich*') रैंक के रूप में कलाकारों से जहां मैच (नाम) के खिलाफ (बूलियन मोड में 'mich*') रैंक डीईएससी द्वारा ऑर्डर करें
यह क्वेरी खोज मिलान और प्रासंगिक मान प्राप्त करती है जो MySQL प्रत्येक रिकॉर्ड के लिए गणना करता है। इंजन ऑप्टिमाइज़र यह पता लगाएगा कि हम प्रासंगिकता का चयन कर रहे हैं, इसलिए यह रैंक की पुनर्गणना करने की जहमत नहीं उठाएगा।
पूर्ण-पाठ खोज में वर्ड स्टेमिंग
जब हम किसी खोज में मूल शब्द को शामिल करते हैं, तो खोज अधिक उपयोगकर्ता के अनुकूल हो जाती है। भले ही परिणाम अपने आप में एक शब्द न हो, एल्गोरिदम व्युत्पन्न शब्दों के लिए समान मूल उत्पन्न करने का प्रयास करते हैं। उदाहरण के लिए, स्टेम "आर्गू" एक अंग्रेजी शब्द नहीं है, लेकिन इसका उपयोग "आर्ग्यू", "ऑर्ग्यू", "आर्ग्यूज़", "एर्गस", "आर्गस" और अन्य शब्दों के लिए स्टेम के रूप में किया जा सकता है।
स्टेमिंग परिणामों में सुधार करता है, क्योंकि उपयोगकर्ता एक ऐसा शब्द दर्ज कर सकता है जिसका कोई सटीक मिलान नहीं है लेकिन इसका "स्टेम" है। हालांकि PHP स्टेमर या स्नोबॉल का पायथन स्टेमर एक विकल्प हो सकता है (यदि आपके पास अपने सर्वर पर रूट एसएसएच एक्सेस है), तो हम PorterStemmer.php क्लास का उपयोग करेंगे।
यह वर्ग अंग्रेजी में शब्दों को स्टेम करने के लिए मार्टिन पोर्टर द्वारा प्रस्तावित एल्गोरिथम को लागू करता है। जैसा कि लेखक ने अपनी वेबसाइट में कहा है, यह किसी भी उद्देश्य के लिए उपयोग करने के लिए स्वतंत्र है। बस केकपीएचपी के भीतर अपनी विक्रेता निर्देशिका के अंदर फ़ाइल को छोड़ दें, अपने मॉडल में पुस्तकालय शामिल करें, और एक शब्द को स्टेम करने के लिए स्थिर विधि को कॉल करें:
//केकेपीएचपी के वेंडर्स फोल्डर के भीतर लाइब्रेरी (पोर्टरस्टेमर.php कहा जाना चाहिए) शामिल करेंApp::import('Vendor', 'PorterStemmer'); // एक शब्द को स्टेम करें (शब्दों को एक-एक करके स्टेम किया जाना चाहिए) पोर्टरस्टेमर ::स्टेम ('स्टेमिंग'); // आउटपुट 'स्टेम' होगा
हमारा लक्ष्य खोज को तेज़ और कुशल बनाना है और परिणामों को उनकी पूर्ण-पाठ प्रासंगिकता के अनुसार क्रमबद्ध करने में सक्षम होना है। ऐसा करने के लिए, हमें शब्द स्टेमिंग को दो तरीकों से नियोजित करना होगा:
- उपयोगकर्ता द्वारा दर्ज किए गए शब्द
- गीत से संबंधित डेटा (जिसे हम कॉलम में स्टोर करेंगे और प्रासंगिकता के आधार पर परिणामों के लिए सॉर्ट करेंगे)
पहले प्रकार के शब्द स्टेमिंग को इस प्रकार पूरा किया जा सकता है:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ / अवांछित वर्ण हटाएं $ शब्द =विस्फोट ("", ट्रिम ($ खोज)); $ स्टेम्डसर्च =""; $ unstemmedSearch =""; foreach ($ शब्द के रूप में $ शब्द) {$ स्टेमडसर्च। =पोर्टरस्टेमर ::स्टेम ($ शब्द) । "*";//हम प्रत्येक शब्द $unstemmedSearch =$word के बाद वाइल्डकार्ड जोड़ते हैं। "*";// उस कलाकार कॉलम को खोजने के लिए जो स्टेम नहीं है}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") {//अन्यथा mySql शिकायत करेगा, क्योंकि आप अकेले वाइल्डकार्ड का उपयोग नहीं कर सकते हैं $stemmedSearch =""; $unstemmedSearch ="";}
हमने दो तार बनाए हैं:एक कलाकार का नाम खोजने के लिए (बिना तने के), और एक दूसरे तने वाले स्तंभों में खोजने के लिए। इससे हमें बाद में अपना ‘विरुद्ध’ . बनाने में मदद मिलेगी पूर्ण-पाठ क्वेरी का हिस्सा। अब देखते हैं कि हम गाने के डेटा को कैसे स्टेम और सॉर्ट कर सकते हैं।
गीत डेटा को असामान्य बनाना
हमारा सॉर्टिंग मानदंड पहले गीत के कलाकार (बिना स्टेम किए) के मिलान पर आधारित होगा। इसके बाद गाने का नाम, एल्बम और संबंधित श्रेणियां आएंगी। स्टेमिंग का उपयोग सभी द्वितीयक खोज मानदंडों पर किया जाएगा।
इसे स्पष्ट करने के लिए, मान लीजिए कि मैं 'निर्वाण' की खोज करता हूं और 'XYZ' द्वारा 'निर्वाण गेम्स' नामक एक गीत है, और कलाकार 'निर्वाण' द्वारा 'पोली' नामक एक और गीत है। परिणाम पहले 'पोली' को सूचीबद्ध करना चाहिए, क्योंकि कलाकार के नाम पर मिलान गीत के नाम (मेरे मानदंड के आधार पर) से अधिक महत्वपूर्ण है।
ऐसा करने के लिए, मैंने songs तालिका, प्रत्येक खोज/सॉर्टिंग मानदंड के लिए एक जिसे हम चाहते हैं:
ALTER TABLE `गाने` जोड़ें `denorm_artist` VARCHAR(255) Not NULL के बाद`trackname`, `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist` जोड़ें, `denorm_album` जोड़ें VARCHAR(255) NOT NULL AFTER` denorm_trackname`, `denorm_categories` जोड़ें VARCHAR(500) NOT NULL के बाद`denorm_album`, FULLTEXT जोड़ें (`denorm_artist`), FULLTEXT जोड़ें(`denorm_trackname`), FULLTEXT जोड़ें (`denorm_album`),(` FULLTEXT जोड़ें);
हमारा पूरा डेटाबेस मॉडल इस तरह दिखेगा:
जब भी आप CakePHP में ऐड/एडिट का उपयोग करके कोई गाना सेव करते हैं, तो आपको बस कलाकार का नाम denorm_artist कॉलम में स्टोर करना होगा। इसे बिना छेड़े। इसके बाद, तने हुए ट्रैक का नाम denorm_trackname . में जोड़ें फ़ील्ड (जैसा कि हमने खोजे गए टेक्स्ट में किया था) और स्टेम एल्बम का नाम denorm_album में सेव करें। कॉलम। अंत में, गाने के लिए सेट स्टेम्ड कैटेगरी को denorm_categories . में स्टोर करें फ़ील्ड, शब्दों को संयोजित करना और प्रत्येक उपजी श्रेणी के नाम के बीच एक स्थान जोड़ना।
केकपीएचपी में पूर्ण-पाठ खोज और प्रासंगिकता छँटाई
'निर्वाण' की खोज के उदाहरण को जारी रखते हुए, आइए देखें कि इससे मिलती-जुलती क्वेरी क्या हासिल कर सकती है:
ट्रैकनाम चुनें, MATCH(denorm_artist) के खिलाफ ('निर्वाण*' बूलियन मोड में) रैंक1 के रूप में, MATCH(denorm_trackname) AGAINST ('निर्वाण*' इन बूलियन मोड) रैंक2 के रूप में, MATCH(denorm_album) के खिलाफ ('निर्वाण') बूलियन मोड में) रैंक3 के रूप में, MATCH(denorm_categories) के विरुद्ध (बूलियन मोड में 'निर्वाण*') रैंक4 के रूप में गाने से जहां MATCH(denorm_artist) के खिलाफ ('निर्वाण*' बूलियन मोड में) या MATCH(denorm_trackname) के खिलाफ ' बूलियन मोड में) या मैच (denorm_album) के खिलाफ (बूलियन मोड में 'निर्वाण *') या मैच (denorm_श्रेणियों) के खिलाफ (बूलियन मोड में 'निर्वाण *') रैंक 1 डीईएससी द्वारा आदेश, रैंक 2 डीईएससी, रैंक 4 डीईएससी, रैंक 4 डीईएससी पूर्व>
हमें निम्न आउटपुट प्राप्त होगा:
| ट्रैकनाम | रैंक1 | रैंक2 | रैंक3 | रैंक4 |
| पोली | 0.0906190574169159 | 0 | 0 | 0 |
| निर्वाण खेल | 0 | 0.0906190574169159 | 0 | 0 |
केकपीएचपी में ऐसा करने के लिए, ढूंढें विधि को 'फ़ील्ड', 'शर्तों' और 'ऑर्डर' मापदंडों के संयोजन का उपयोग करके बुलाया जाना चाहिए। पूर्व PHP उदाहरण कोड के साथ जारी:
//Song.php मॉडल फ़ाइल के भीतर $fields =array("Song.trackname", "MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) के रूप में `रैंक1`", "MATCH(Song. denorm_trackname) के विरुद्ध (बूलियन मोड में {$stemmedSearch}) `रैंक2`", "MATCH(Song.denorm_album) के विरुद्ध `रैंक3` के रूप में (बूलियन मोड में {$stemmedSearch}", "MATCH(Song.denorm_categories) के विरुद्ध ( {$stemmedSearch} बूलियन मोड में) `रैंक4`" के रूप में);$आदेश ="`रैंक1` डीईएससी, `रैंक2` डीईएससी, `रैंक3` डीईएससी, `रैंक4` डीईएससी, सॉन्ग.ट्रैकनाम एएससी";$शर्तें =सरणी( "OR" => सरणी ("MATCH(Song.denorm_artist) अगेंस्ट ({$unstemmedSearch} IN BOOLEAN MODE)", "MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)", "MATCH(Song. denorm_album) के खिलाफ ({$stemmedSearch} बूलियन मोड में)", "MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)" ));$results =$this->find ('सभी', सरणी ('शर्तें' => $ शर्तें, 'फ़ील्ड' => $ फ़ील्ड, 'ऑर्डर' => $ ऑर्डर);
$results हमारे द्वारा पहले परिभाषित मानदंडों के अनुसार क्रमबद्ध गीतों की श्रेणी होगी।
इस समाधान का उपयोग उन खोजों को उत्पन्न करने के लिए किया जा सकता है जो उपयोगकर्ता के लिए सार्थक हैं - डेवलपर्स से बहुत अधिक समय की आवश्यकता के बिना या कोड में बड़ी जटिलता जोड़ने के बिना।
केकपीएचपी खोजों को और भी बेहतर बनाना
यह ध्यान देने योग्य है कि अधिक डेटा वाले असामान्य स्तंभों को "मसालेदार" करने से बेहतर परिणाम प्राप्त हो सकते हैं।
"स्पाइसिंग" से मेरा मतलब है कि आप असामान्य कॉलम में अतिरिक्त कॉलम से अधिक डेटा शामिल कर सकते हैं, जिसे आप परिणामों को अधिक प्रासंगिक बनाने के लक्ष्य के साथ उपयोगी मानते हैं, उदाहरण के लिए यदि आप जानते थे कि किसी कलाकार का देश खोज शब्दों में शामिल हो सकता है, तो आप denorm_artist . में कलाकार के नाम के साथ देश जोड़ सकता है कॉलम। इससे खोज परिणामों की गुणवत्ता में सुधार होगा।
मेरे अनुभव से (आपके द्वारा उपयोग किए जाने वाले वास्तविक डेटा और आपके द्वारा निरूपित किए गए कॉलम के आधार पर) शीर्षतम परिणाम वास्तव में सटीक होते हैं। यह मोबाइल ऐप्स के लिए बहुत अच्छा है, क्योंकि लंबी सूची को नीचे स्क्रॉल करने से उपयोगकर्ता को निराशा हो सकती है।
अंत में, यदि आपको उन तालिकाओं से अधिक डेटा प्राप्त करने की आवश्यकता है जिनसे गीत संबंधित है, तो आप हमेशा शामिल हो सकते हैं और कलाकार, श्रेणियां, एल्बम, गीत टिप्पणियां इत्यादि प्राप्त कर सकते हैं। यदि आप केकेपीएचपी के नियंत्रण योग्य व्यवहार फ़िल्टर का उपयोग कर रहे हैं, तो मैं जॉइन को कुशलता से पूरा करने के लिए EagerLoader प्लगइन जोड़ने का सुझाव दें।
यदि पूर्ण-पाठ खोज को लागू करने के लिए आपका अपना दृष्टिकोण है, तो कृपया इसे नीचे टिप्पणी में साझा करें। हम सभी एक दूसरे के अनुभव से सीख सकते हैं।