पायथन इन दिनों बहुत लोकप्रिय है। चूंकि पायथन एक सामान्य-उद्देश्य वाली प्रोग्रामिंग भाषा है, इसका उपयोग एक्सट्रैक्ट, ट्रांसफॉर्म, लोड (ETL) प्रक्रिया को करने के लिए भी किया जा सकता है। विभिन्न ईटीएल मॉड्यूल उपलब्ध हैं, लेकिन आज हम पायथन और माईएसक्यूएल के संयोजन के साथ रहेंगे। हम संग्रहीत प्रक्रियाओं को लागू करने और SQL कथन तैयार करने और निष्पादित करने के लिए पायथन का उपयोग करेंगे।
हम दो समान-लेकिन-भिन्न दृष्टिकोणों का उपयोग करेंगे। सबसे पहले, हम संग्रहीत प्रक्रियाओं को लागू करेंगे जो पूरा काम करेंगे, और उसके बाद हम विश्लेषण करेंगे कि हम पाइथन में MySQL कोड का उपयोग करके संग्रहीत प्रक्रियाओं के बिना उसी प्रक्रिया को कैसे कर सकते हैं।
तैयार? इससे पहले कि हम खुदाई करें, आइए डेटा मॉडल - या डेटा मॉडल देखें, क्योंकि इस आलेख में उनमें से दो हैं।
डेटा मॉडल
हमें दो डेटा मॉडल की आवश्यकता होगी, एक हमारे परिचालन डेटा को स्टोर करने के लिए और दूसरा हमारे रिपोर्टिंग डेटा को स्टोर करने के लिए।
पहला मॉडल ऊपर की तस्वीर में दिखाया गया है। इस मॉडल का उपयोग सदस्यता-आधारित व्यवसाय के लिए परिचालन (लाइव) डेटा संग्रहीत करने के लिए किया जाता है। इस मॉडल के बारे में अधिक जानकारी के लिए, कृपया हमारे पिछले लेख पर एक नज़र डालें, एक डीडब्ल्यूएच बनाना, भाग एक:एक सदस्यता व्यवसाय डेटा मॉडल।
परिचालन और रिपोर्टिंग डेटा को अलग करना आमतौर पर एक बहुत ही बुद्धिमान निर्णय होता है। उस अलगाव को प्राप्त करने के लिए, हमें एक डेटा वेयरहाउस (DWH) बनाना होगा। हम पहले ही ऐसा कर चुके हैं; आप ऊपर की तस्वीर में मॉडल देख सकते हैं। इस मॉडल का विस्तार से वर्णन पोस्ट डीडब्ल्यूएच बनाना, भाग दो:एक सदस्यता व्यवसाय डेटा मॉडल में भी किया गया है।
अंत में, हमें लाइव डेटाबेस से डेटा निकालने, इसे बदलने और इसे हमारे DWH में लोड करने की आवश्यकता है। हमने SQL संग्रहीत कार्यविधियों का उपयोग करके पहले ही ऐसा कर लिया है। आप डेटा वेयरहाउस बनाना, भाग 3:एक सदस्यता व्यवसाय डेटा मॉडल में कुछ कोड उदाहरणों के साथ-साथ इसका विवरण प्राप्त कर सकते हैं कि हम क्या हासिल करना चाहते हैं।
यदि आपको DWH के बारे में अतिरिक्त जानकारी चाहिए, तो हम इन लेखों को पढ़ने की सलाह देते हैं:
- द स्टार स्कीमा
- द स्नोफ्लेक स्कीमा
- स्टार स्कीमा बनाम स्नोफ्लेक स्कीमा।
आज हमारा कार्य SQL संग्रहीत कार्यविधियों को Python कोड से बदलना है। हम कुछ पायथन जादू बनाने के लिए तैयार हैं। आइए पायथन में केवल संग्रहीत कार्यविधियों का उपयोग करके प्रारंभ करें।
विधि 1:संग्रहीत कार्यविधियों का उपयोग करके ETL
इससे पहले कि हम प्रक्रिया का वर्णन करना शुरू करें, यह उल्लेख करना महत्वपूर्ण है कि हमारे सर्वर पर दो डेटाबेस हैं।
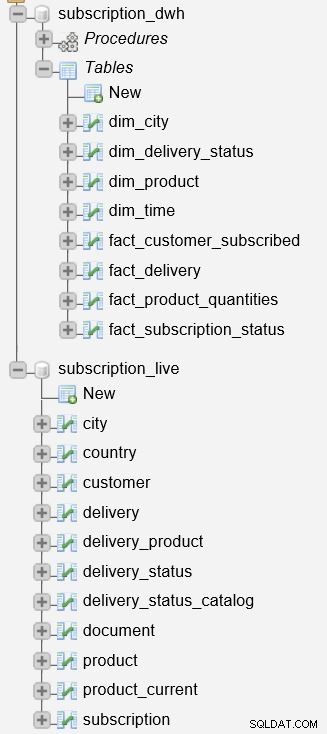
subscription_live डेटाबेस का उपयोग लेन-देन संबंधी/लाइव डेटा को संग्रहीत करने के लिए किया जाता है, जबकि subscription_dwh हमारा रिपोर्टिंग डेटाबेस (DWH) है।
हमने पहले ही आयाम और तथ्य तालिकाओं को अद्यतन करने के लिए उपयोग की जाने वाली संग्रहीत प्रक्रियाओं का वर्णन किया है। वे subscription_live डेटाबेस, इसे subscription_dwh डेटाबेस, और subscription_dwh डेटाबेस। ये दो प्रक्रियाएं हैं:
p_update_dimensions- आयाम तालिकाओं को अपडेट करता हैdim_timeऔरdim_city।p_update_facts- दो फैक्ट टेबल अपडेट करता है,fact_customer_subscribedऔरfact_subscription_status।
यदि आप इन प्रक्रियाओं के लिए पूरा कोड देखना चाहते हैं, तो डेटा वेयरहाउस बनाना, भाग 3:एक सदस्यता व्यवसाय डेटा मॉडल पढ़ें।
अब हम एक साधारण पायथन स्क्रिप्ट लिखने के लिए तैयार हैं जो सर्वर से कनेक्ट होगी और ETL प्रक्रिया को निष्पादित करेगी। आइए पहले पूरी स्क्रिप्ट पर एक नज़र डालें (etl_procedures.py ) फिर हम सबसे महत्वपूर्ण भागों की व्याख्या करेंगे।
# आयात MySQL कनेक्टरआयात mysql.connector# सर्वर से कनेक्ट करेंकनेक्शन =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('connected to डेटाबेस.')कर्सर =कनेक्शन.कर्सर ()# मैं डाइमेंशन अपडेट करता हूं। टेबल अपडेट किए गए।')# कमिट और क्लोज कनेक्शनकर्सर।क्लोज () कनेक्शन। कमिट () कनेक्शन। क्लोज () प्रिंट ('डेटाबेस से डिस्कनेक्ट किया गया।') etl_procedures.py
मॉड्यूल आयात करना और डेटाबेस से कनेक्ट करना
पायथन परिभाषाओं और बयानों को संग्रहीत करने के लिए मॉड्यूल का उपयोग करता है। आप मौजूदा मॉड्यूल का उपयोग कर सकते हैं या अपना खुद का लिख सकते हैं। मौजूदा मॉड्यूल का उपयोग करना आपके जीवन को सरल बना देगा क्योंकि आप पूर्व-लिखित कोड का उपयोग कर रहे हैं, लेकिन अपना खुद का मॉड्यूल लिखना भी बहुत उपयोगी है। जब आप पायथन दुभाषिया को छोड़ देते हैं और इसे फिर से चलाते हैं, तो आप उन कार्यों और चरों को खो देंगे जिन्हें आपने पहले परिभाषित किया था। बेशक, आप एक ही कोड को बार-बार टाइप नहीं करना चाहते हैं। इससे बचने के लिए, आप अपनी परिभाषाओं को एक मॉड्यूल में संग्रहीत कर सकते हैं और इसे पायथन में आयात कर सकते हैं।
etl_procedures.py पर वापस जाएं . हमारे कार्यक्रम में, हम MySQL Connector आयात के साथ शुरू करते हैं:
# आयात MySQL कनेक्टरआयात mysql.connectorपायथन के लिए MySQL Connector का उपयोग एक मानकीकृत ड्राइवर के रूप में किया जाता है जो एक MySQL सर्वर/डेटाबेस से जुड़ता है। यदि आपने पहले ऐसा नहीं किया है तो आपको इसे डाउनलोड और इंस्टॉल करना होगा। डेटाबेस से जुड़ने के अलावा, यह डेटाबेस के साथ काम करने के लिए कई तरीके और गुण प्रदान करता है। हम उनमें से कुछ का उपयोग करेंगे, लेकिन आप यहां संपूर्ण दस्तावेज़ीकरण देख सकते हैं।
इसके बाद, हमें अपने डेटाबेस से कनेक्ट करना होगा:
# सर्वर कनेक्शन से कनेक्ट करें =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('connected to database.')cursor =connection .कर्सर () पहली पंक्ति एक सर्वर से कनेक्ट होगी (इस मामले में, मैं अपनी स्थानीय मशीन से कनेक्ट कर रहा हूं) आपके क्रेडेंशियल्स का उपयोग करके (
बदलें) औरवास्तविक मूल्यों के साथ)। कनेक्शन स्थापित करते समय, आप उस डेटाबेस को भी निर्दिष्ट कर सकते हैं जिससे आप कनेक्ट करना चाहते हैं, जैसा कि नीचे दिखाया गया है:
कनेक्शन =mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ') मैंने जानबूझकर केवल एक सर्वर से कनेक्ट किया है न कि किसी विशिष्ट डेटाबेस से क्योंकि मैं एक ही सर्वर पर स्थित दो डेटाबेस का उपयोग करूंगा।
अगला कमांड -
इस भाग की अंतिम पंक्ति है:
कर्सर =कनेक्शन.कर्सर ()
कर्सर डेटा के साथ काम करने के लिए उपयोग की जाने वाली हैंडलर संरचना है। हम उनका उपयोग डेटाबेस से डेटा पुनर्प्राप्त करने (चयन) के लिए करेंगे, लेकिन डेटा को संशोधित करने के लिए भी (INSERT, UPDATE, DELETE) करेंगे। कर्सर का उपयोग करने से पहले, हमें इसे बनाना होगा। और यही यह पंक्ति करती है।कॉल करने की प्रक्रिया
पिछला भाग सामान्य था और डेटाबेस से संबंधित अन्य कार्यों के लिए इस्तेमाल किया जा सकता था। कोड का निम्नलिखित भाग विशेष रूप से ईटीएल के लिए है:हमारी संग्रहीत प्रक्रियाओं को
cursor.callprocके साथ कॉल करना आज्ञा। यह इस तरह दिखता है:
# 1. अद्यतन आयाम कर्सर. /पूर्व>कॉलिंग प्रक्रिया काफी हद तक आत्म-व्याख्यात्मक है। प्रत्येक कॉल के बाद, एक प्रिंट कमांड जोड़ा गया था। फिर से, यह हमें केवल एक सूचना देता है कि सब कुछ ठीक हो गया।
प्रतिबद्ध और बंद करें
स्क्रिप्ट का अंतिम भाग डेटाबेस में परिवर्तन करता है और सभी उपयोग की गई वस्तुओं को बंद कर देता है:
# कमिट और क्लोज कनेक्शनcursor.close()connection.commit()connection.close()print('disconnected from database.')कॉलिंग प्रक्रिया काफी हद तक आत्म-व्याख्यात्मक है। प्रत्येक कॉल के बाद, एक प्रिंट कमांड जोड़ा गया था। फिर से, यह हमें केवल एक सूचना देता है कि सब कुछ ठीक हो गया।
यहां प्रतिबद्ध होना जरूरी है; इसके बिना, डेटाबेस में कोई परिवर्तन नहीं होगा, भले ही आपने कोई प्रक्रिया कॉल की हो या SQL कथन निष्पादित किया हो।
स्क्रिप्ट चलाना
आखिरी चीज जो हमें करने की जरूरत है वह है हमारी स्क्रिप्ट को चलाना। हम इसे प्राप्त करने के लिए पायथन शेल में निम्नलिखित कमांड का उपयोग करेंगे:
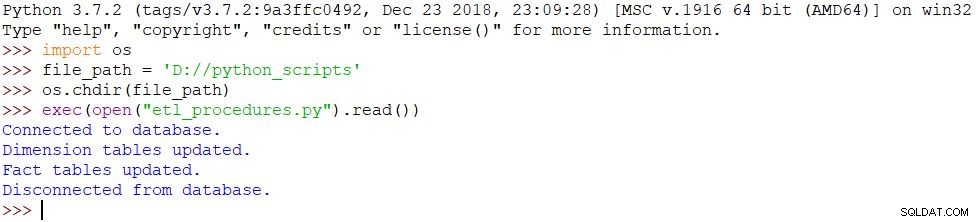
आयात osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())स्क्रिप्ट निष्पादित की जाती है और उसके अनुसार डेटाबेस में सभी परिवर्तन किए जाते हैं। परिणाम नीचे चित्र में देखा जा सकता है।
विधि 2:पायथन और MySQL का उपयोग करके ETL
ऊपर प्रस्तुत दृष्टिकोण सीधे MySQL में संग्रहीत प्रक्रियाओं को कॉल करने के दृष्टिकोण से बहुत भिन्न नहीं है। फर्क सिर्फ इतना है कि अब हमारे पास एक स्क्रिप्ट है जो हमारे लिए पूरा काम करेगी।
हम एक और दृष्टिकोण का उपयोग कर सकते हैं:सब कुछ पायथन लिपि के अंदर रखना। हम पायथन स्टेटमेंट शामिल करेंगे, लेकिन हम SQL क्वेरीज़ भी तैयार करेंगे और उन्हें डेटाबेस पर निष्पादित करेंगे। स्रोत डेटाबेस (लाइव) और गंतव्य डेटाबेस (DWH) संग्रहीत कार्यविधियों के उदाहरण के समान हैं।
इससे पहले कि हम इस पर ध्यान दें, आइए पूरी स्क्रिप्ट पर एक नज़र डालें (etl_queries.py ):
डेटाटाइम आयात तिथि से# आयात MySQL कनेक्टरआयात mysql.connector# सर्वर से कनेक्ट करेंकनेक्शन =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print ('डेटाबेस से जुड़ा है।')# 1. आयाम अपडेट करें# 1.1 अपडेट dim_time# तारीख - कल कल =तारीख। सेऑर्डिनल (दिनांक। आज ()। टूर्डिनल () -1) कल_स्ट्र ='"' + स्ट्र (कल) + ' "'# परीक्षण अगर तारीख पहले से ही टेबल कर्सर में है =कनेक्शन.कर्सर () क्वेरी =("सेलेक्ट काउंट (*)" "सदस्यता_dwh.dim_time से" "जहां टाइम_डेट =" + कल_स्ट्र) कर्सर.एक्सक्यूट (क्वेरी) परिणाम =कर्सर .fetchall()कल_सब्सक्रिप्शन_काउंट =इंट (परिणाम [0] [0]) अगर कल_सब्सक्रिप्शन_काउंट ==0:कल_वर्ष ='वर्ष ("' + स्ट्र (कल) + '")' कल_महीना ='महीना ("' + स्ट्र (कल) कल `(`time_date`, `time_year`, `time_month`, `time_week` , `time_weekday`, `ts`) " " VALUES (" + कल_स्ट्र + "," + कल_वर्ष + "," + कल_महीना + "," + कल_सप्ताह + "," + कल_सप्ताह का दिन + ", अब ())") कर्सर .execute(query)# 1.2 अपडेट dim_cityquery =( "INSERT INTO Subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "चुनें city_live.city_name, city_live.postal_code, country_live.country_name , Now() " "FROM Subscription_live.city city_live" "INNER में शामिल हों सदस्यता_लाइव.देश देश_लाइव पर शहर_लाइव.कंट्री_आईडी =country_live.id " "बाएं जॉइन सदस्यता_dwh.dim_city city_dwh पर शहर_लाइव.सिटी_नाम =city_dwh.city_name और city_live_dwh.code =city_live_dwh. postal_code और country_live.country_name =city_dwh.country_name " "WHERE city_dwh.id IS NULL")cursor.execute(query)print('आयाम टेबल अपडेट किया गया।')# 2. अपडेट फैक्ट्स# 2.1 अपडेट ग्राहकों ने सब्सक्राइब किया# पुराने डेटा को डिलीट करें वही दिनांक =("डिलीट सब्सक्रिप्शन_dwh.`fact_customer_subcribed`।* " "FROM Subscription_dwh.`fa ct_customer_subcribed` " "INNER JOIN Subscription_dwh.`dim_time` ON Subscription_dwh.`fact_customer_subcribed`।`dim_time_id` =Subscription_dwh.`dim_time`।`id` " "WHERE Subscription_dwh.`dim_time`। निष्पादित करें (क्वेरी) # नई डेटाक्वेरी डालें =("सब्सक्रिप्शन_डीडब्ल्यूएच। City_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(केस जब customer_live.active =1 फिर 1 ELSE 0 END) कुल_सक्रिय के रूप में, SUM(केस जब customer_live.active =0 तब 1 ELSE 0 END) कुल_निष्क्रिय के रूप में, SUM( मामला जब customer_live.active =1 और DATE(customer_live.time_updated) =@time_date तब 1 ELSE 0 END) दैनिक_नए के रूप में, SUM(केस जब customer_live.active =0 और DATE(customer_live.time_updated) =@time_date तब 1 ELSE 0 END ) दैनिक_कैंसल के रूप में, मिन (अब ()) एएस टीएस "" से सब्सक्रिप्शन_लाइव। `ग्राहक` ग्राहक_लाइव " "INNER जॉइन सबस्क्राइब ption_live.`city' city_live ON customer_live.city_id =city_live.id " "INNER JOIN Subscription_live.`country' country_live पर city_live.country_id =country_live.id " "INNER JOIN Subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh .postal_code =city_dwh.postal_code और country_live.country_name =city_dwh.country_name ""INNER जॉइन सब्सक्रिप्शन_dwh.dim_time time_dwh ON time_dwh.time_date =" + कल_स्ट्र + " "" (CROUP BY city_dwh.id, time_dwh.id") )# 2.2 सब्सक्रिप्शन स्टेटस अपडेट करें# उसी डेटक्वेरी के लिए पुराना डेटा डिलीट करें =("डिलीट सब्सक्रिप्शन_डीडब्ल्यूएच।`फैक्ट_सब्सक्रिप्शन_स्टैटस`। dim_time_id` =subscribe_dwh.`dim_time`।`id` ""WHERE Subscription_dwh.`dim_time`। `time_date` =" + कल_स्ट्र)cursor.execute(query)# नई डेटा क्वेरी डालें =("सब्सक्रिप्शन_dwh में डालें" तथ्य _subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "चुनें city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN Subscription_live.active =1 फिर 1 ELSE 0 END) जैसे Total_active, SUM(केस जब Subscription_live.active =0 फिर 1 ELSE 0 END) जैसे Total_inactive, SUM(केस जब Subscription_live.active =1 और DATE(subscription_live.time_updated) =@ time_date फिर 1 ELSE 0 END) दैनिक_नए के रूप में, SUM(केस जब सब्सक्रिप्शन_लाइव.एक्टिव =0 और DATE(subscription_live.time_updated) =@time_date फिर 1 ELSE 0 END) AS दैनिक_रद्द, मिन(अब ()) AS ts " "FROM Subscription_live .`customer` customer_live " "INNER JOIN Subscription_live.`subscription` Subscription_live ON Subscription_live.customer_id =customer_live.id " "INNER JOIN Subscription_live.`city` City_live ON customer_live.city_id =city_live.id " "INNER JOIN Subscription_live.`country` देश_लाइव पर शहर_लाइव.कंट्री_आईडी =देश_लाइव.आईडी " "INNER शहर_लाइव.सिटी_नाम =City_dwh.city_name और City_live.postal_code =city_dwh.postal_code और country_live.country_name =city_dwh.country_name ""INNER =" + कल सदस्यता_dwh.dim_time_str_dwh पर शामिल हों। BY City_dwh.id, time_dwh.id")cursor.execute(query)print('Fact Tables update.')# कमिट और क्लोज कनेक्शनcursor.close()connection.commit()connection.close()print('Disconnected from Database ।') etl_queries.py
मॉड्यूल आयात करना और डेटाबेस से कनेक्ट करना
एक बार फिर, हमें निम्न कोड का उपयोग करके MySQL आयात करना होगा:
mysql.connector आयात करेंहम डेटाटाइम मॉड्यूल भी आयात करेंगे, जैसा कि नीचे दिखाया गया है। पायथन में दिनांक-संबंधित संचालन के लिए हमें इसकी आवश्यकता है:
डेटाटाइम आयात तिथि सेडेटाबेस से जुड़ने की प्रक्रिया पिछले उदाहरण की तरह ही है।
dim_time आयाम अपडेट करना
dim_timeतालिका में, हमें यह जांचना होगा कि क्या मूल्य (कल के लिए) पहले से ही तालिका में है। ऐसा करने के लिए हमें पायथन के दिनांक कार्यों (एसक्यूएल के बजाय) का उपयोग करना होगा:
# तारीख - कल कल =date.fromordinal(date.today().toordinal()-1)yesterday_str ='"' + str(कल) + '"'कोड की पहली पंक्ति दिनांक चर में कल की तारीख लौटाएगी, जबकि दूसरी पंक्ति इस मान को एक स्ट्रिंग के रूप में संग्रहीत करेगी। हमें एक स्ट्रिंग के रूप में इसकी आवश्यकता होगी क्योंकि जब हम SQL क्वेरी बनाएंगे तो हम इसे किसी अन्य स्ट्रिंग के साथ जोड़ देंगे।
इसके बाद, हमें यह जांचना होगा कि क्या यह तारीख पहले से ही
dim_timeटेबल। कर्सर घोषित करने के बाद, हम SQL क्वेरी तैयार करेंगे। क्वेरी को निष्पादित करने के लिए, हमcursor.execute. का उपयोग करेंगे आदेश:
# टेस्ट अगर तारीख पहले से ही टेबल कर्सर में है =कनेक्शन.कर्सर () क्वेरी =("सेलेक्ट COUNT(*)" "FROM Subscription_dwh.dim_time" "WHERE time_date =" + कल_स्ट्र)cursor.execute(query)'" 'हम क्वेरी परिणाम को परिणाम में संगृहीत करेंगे चर। परिणाम में 0 या 1 पंक्तियाँ होंगी, इसलिए हम पहली पंक्ति के पहले कॉलम का परीक्षण कर सकते हैं। इसमें या तो 0 या 1 होगा। (याद रखें, हमारे पास एक ही तारीख एक आयाम तालिका में केवल एक बार हो सकती है।)
यदि दिनांक पहले से तालिका में नहीं है, तो हम स्ट्रिंग तैयार करेंगे जो SQL क्वेरी का हिस्सा होगी:
result =कर्सर.fetchall()कल_सब्सक्रिप्शन_काउंट =int(result[0][0])अगर कल_सब्सक्रिप्शन_काउंट ==0:कल_वर्ष ='YEAR("' + str(कल) + '")' कल_माह ='महीना( "' + str(कल) + '")' कल_वीक ='सप्ताह("' + str(कल) + '")' कल_सप्ताह का दिन ='सप्ताह का दिन("' + str(कल) + '")''आखिरकार, हम एक क्वेरी बनाएंगे और उसे निष्पादित करेंगे। यह
dim_timeप्रतिबद्ध होने के बाद तालिका। कृपया ध्यान दें कि मैंने डेटाबेस नाम (subscription_dwh)
query =("INSERT INTO Subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "" VALUES ("+ कल_स्ट्र +", " + कल_वर्ष + "," + कल_महीना + ", " + कल_सप्ताह + ", " + कल_सप्ताह का दिन + ", अब ())") कर्सर.निष्पादन(क्वेरी)dim_city आयाम अपडेट करें
dim_cityतालिका और भी सरल है क्योंकि हमें डालने से पहले कुछ भी परीक्षण करने की आवश्यकता नहीं है। हम वास्तव में उस परीक्षण को SQL क्वेरी में शामिल करेंगे।
# 1.2 अपडेट dim_cityquery =( "INSERT INTO Subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "Select city_live.city_name, city_live.postal_code, country_live.country_name, Now () " "FROM Subscription_live.city city_live" "INNER में शामिल हों सदस्यता_लाइव.देश देश_लाइव सिटी_लाइव.कंट्री_आईडी =देश_लाइव.आईडी पर country_live.country_name =city_dwh.country_name " "जहां शहर_dwh.id IS NULL")cursor.execute(query)यहां हम एक एक्जीक्यूट SQL क्वेरी तैयार करते हैं। ध्यान दें कि मैंने फिर से दोनों डेटाबेस के नामों सहित तालिकाओं के लिए पूर्ण पथ का उपयोग किया है (
subscription_liveऔरsubscription_dwh)तथ्य तालिका अपडेट करना
आखिरी चीज जो हमें करने की जरूरत है वह है हमारी फैक्ट टेबल को अपडेट करना। प्रक्रिया लगभग आयाम तालिकाओं को अद्यतन करने के समान है:हम प्रश्न तैयार करते हैं और उन्हें निष्पादित करते हैं। ये प्रश्न बहुत अधिक जटिल हैं, लेकिन वे वही हैं जो संग्रहीत प्रक्रियाओं में उपयोग किए जाते हैं।
हमने संग्रहीत कार्यविधियों की तुलना में एक सुधार जोड़ा है:तथ्य तालिका में उसी तिथि के मौजूदा डेटा को हटाना। यह हमें एक ही तिथि के लिए कई बार एक स्क्रिप्ट चलाने की अनुमति देगा। अंत में, हमें लेन-देन करने और सभी वस्तुओं और कनेक्शन को बंद करने की आवश्यकता होगी।
स्क्रिप्ट चलाना
इस भाग में हमारे पास एक छोटा सा बदलाव है, जो एक अलग स्क्रिप्ट कह रहा है:
- आयात os- file_path ='D://python_scripts'- os.chdir(file_path)- exec(open("etl_queries.py").read())क्योंकि हमने समान संदेशों का उपयोग किया है और स्क्रिप्ट सफलतापूर्वक पूर्ण हुई है, परिणाम समान है:
ईटीएल में आप पायथन का उपयोग कैसे करेंगे?
आज हमने पायथन लिपि के साथ ईटीएल प्रक्रिया करने का एक उदाहरण देखा। ऐसा करने के अन्य तरीके हैं, उदा। कई ओपन-सोर्स समाधान जो डेटाबेस के साथ काम करने और ईटीएल प्रक्रिया को करने के लिए पायथन पुस्तकालयों का उपयोग करते हैं। अगले लेख में, हम उनमें से एक के साथ खेलेंगे। इस बीच, बेझिझक अपना अनुभव पायथन और ईटीएल के साथ साझा करें।