SQLAlchemy आपको Python में डेटाबेस के साथ काम करने में मदद करता है। इस पोस्ट में, हम आपको वह सब कुछ बताते हैं जो आपको इस मॉड्यूल के साथ आरंभ करने के लिए जानना आवश्यक है।
पिछले लेख में, हमने बात की थी कि ईटीएल प्रक्रिया में पायथन का उपयोग कैसे करें। हमने संग्रहीत कार्यविधियों और SQL प्रश्नों को निष्पादित करके कार्य पूरा करने पर ध्यान केंद्रित किया। इस लेख और अगले में, हम एक अलग दृष्टिकोण का उपयोग करेंगे। SQL कोड लिखने के बजाय, हम SQLAlchemy टूलकिट का उपयोग करेंगे। SQLAlchemy को स्थापित करने और उपयोग करने पर त्वरित परिचय के रूप में आप इस आलेख को अलग से भी उपयोग कर सकते हैं।
तैयार? आइए शुरू करते हैं।
SQLAlchemy क्या है?
पायथन अपनी संख्या और विभिन्न प्रकार के मॉड्यूल के लिए जाना जाता है। ये मॉड्यूल हमारे कोडिंग समय को महत्वपूर्ण रूप से कम करते हैं क्योंकि वे एक विशिष्ट कार्य को प्राप्त करने के लिए आवश्यक रूटीन को लागू करते हैं। डेटा के साथ काम करने वाले कई मॉड्यूल उपलब्ध हैं, जिनमें SQLAlchemy भी शामिल है।
SQLAlchemy का वर्णन करने के लिए, मैं SQLAlchemy.org के एक उद्धरण का उपयोग करूंगा:
SQLAlchemy, Python SQL टूलकिट और ऑब्जेक्ट रिलेशनल मैपर है जो एप्लिकेशन डेवलपर्स को SQL की पूर्ण शक्ति और लचीलापन देता है।
यह प्रसिद्ध उद्यम-स्तरीय दृढ़ता का एक पूर्ण सूट प्रदान करता है। पैटर्न, कुशल और उच्च-प्रदर्शन वाले डेटाबेस एक्सेस के लिए डिज़ाइन किया गया है, जिसे एक सरल और पाइथोनिक डोमेन भाषा में अनुकूलित किया गया है।
यहां सबसे महत्वपूर्ण हिस्सा ओआरएम (ऑब्जेक्ट-रिलेशनल मैपर) के बारे में है, जो हमें डेटाबेस ऑब्जेक्ट्स को सूचियों के बजाय पायथन ऑब्जेक्ट्स के रूप में मानने में मदद करता है।
इससे पहले कि हम SQLAlchemy के साथ आगे बढ़ें, आइए रुकें और ORM के बारे में बात करें।
ओआरएम इस्तेमाल करने के फायदे और नुकसान
कच्चे SQL की तुलना में, ORM के अपने फायदे और नुकसान हैं - और इनमें से अधिकांश SQLAlchemy पर भी लागू होते हैं।
द गुड स्टफ:
- कोड पोर्टेबिलिटी। ORM डेटाबेस के बीच वाक्यात्मक अंतरों का ध्यान रखता है।
- केवल एक भाषा आपके डेटाबेस को संभालने के लिए आवश्यक है। हालांकि, ईमानदार होने के लिए, ओआरएम का उपयोग करने के लिए यह मुख्य प्रेरणा नहीं होनी चाहिए।
- ORM आपके कोड को सरल बनाते हैं , जैसे वे रिश्तों का ख्याल रखते हैं और उन्हें वस्तुओं की तरह मानते हैं, जो कि बहुत अच्छा है यदि आप ओओपी के अभ्यस्त हैं।
- आप कार्यक्रम के अंदर अपने डेटा में हेरफेर कर सकते हैं ।
दुर्भाग्य से, सब कुछ एक कीमत के साथ आता है। ओआरएम के बारे में बहुत अच्छी बातें:
- कुछ मामलों में, ORM धीमा हो सकता है ।
- जटिल क्वेरी लिखना और भी जटिल हो सकता है, या धीमी क्वेरी का परिणाम हो सकता है। लेकिन SQLAlchemy का उपयोग करते समय ऐसा नहीं है।
- यदि आप अपने DBMS को अच्छी तरह से जानते हैं, तो ORM में समान सामग्री को लिखना सीखना समय की बर्बादी है।
अब जबकि हमने उस विषय को संभाल लिया है, आइए SQLAlchemy पर वापस आते हैं।
शुरू करने से पहले...
... आइए इस लेख के लक्ष्य के बारे में खुद को याद दिलाएं। यदि आप केवल SQLAlchemy को स्थापित करने में रुचि रखते हैं और सरल कमांड को निष्पादित करने के तरीके के बारे में एक त्वरित ट्यूटोरियल की आवश्यकता है, तो यह लेख ऐसा करेगा। हालाँकि, इस लेख में प्रस्तुत कमांड का उपयोग अगले लेख में ETL प्रक्रिया को करने और SQL (संग्रहीत कार्यविधियाँ) और पायथन कोड को बदलने के लिए किया जाएगा जो हमने पिछले लेखों में प्रस्तुत किया था।
ठीक है, अब शुरुआत से ही शुरू करते हैं:SQLAlchemy स्थापित करने के साथ।
SQLAlchemy इंस्टॉल करना
<एच4>1. जांचें कि क्या मॉड्यूल पहले से स्थापित हैपायथन मॉड्यूल का उपयोग करने के लिए, आपको इसे स्थापित करना होगा (अर्थात, यदि यह पहले स्थापित नहीं था)। यह जांचने का एक तरीका है कि कौन से मॉड्यूल स्थापित किए गए हैं, इस कमांड का उपयोग पायथन शेल में कर रहे हैं:
help('modules')
यह जांचने के लिए कि क्या कोई विशिष्ट मॉड्यूल स्थापित है, बस इसे आयात करने का प्रयास करें। इन आदेशों का प्रयोग करें:
import sqlalchemy sqlalchemy.__version__
यदि SQLAlchemy पहले से स्थापित है, तो पहली पंक्ति सफलतापूर्वक निष्पादित होगी। import मॉड्यूल आयात करने के लिए उपयोग किया जाने वाला एक मानक पायथन कमांड है। यदि मॉड्यूल स्थापित नहीं है, तो पायथन एक त्रुटि फेंक देगा - वास्तव में त्रुटियों की एक सूची, लाल पाठ में - जिसे आप याद नहीं कर सकते :)
दूसरा आदेश SQLAlchemy का वर्तमान संस्करण लौटाता है। लौटाया गया परिणाम नीचे दिखाया गया है:

हमें एक और मॉड्यूल की भी आवश्यकता होगी, और वह है PyMySQL . यह एक शुद्ध-पायथन लाइटवेट MySQL क्लाइंट लाइब्रेरी है। यह मॉड्यूल सरल प्रश्नों को चलाने से लेकर अधिक जटिल डेटाबेस क्रियाओं तक, MySQL डेटाबेस के साथ काम करने के लिए आवश्यक सभी चीजों का समर्थन करता है। help('modules') . का उपयोग करके हम जांच सकते हैं कि यह मौजूद है या नहीं , जैसा कि पहले बताया गया है, या निम्नलिखित दो कथनों का उपयोग करते हुए:
import pymysql pymysql.__version__
बेशक, ये वही कमांड हैं जिनका उपयोग हम परीक्षण करने के लिए करते थे कि क्या SQLAlchemy स्थापित किया गया था।
क्या होगा यदि SQLAlchemy या PyMySQL पहले से स्थापित नहीं है?
पहले से स्थापित मॉड्यूल को आयात करना कठिन नहीं है। लेकिन क्या होगा यदि आपके लिए आवश्यक मॉड्यूल पहले से स्थापित नहीं हैं?
कुछ मॉड्यूल में एक इंस्टॉलेशन पैकेज होता है, लेकिन अधिकतर आप उन्हें स्थापित करने के लिए पाइप कमांड का उपयोग करेंगे। पीआईपी एक पायथन उपकरण है जिसका उपयोग मॉड्यूल को स्थापित और अनइंस्टॉल करने के लिए किया जाता है। मॉड्यूल स्थापित करने का सबसे आसान तरीका (विंडोज़ ओएस में) है:
- कमांड प्रॉम्प्ट का उपयोग करें -> रन -> cmd ।
- पायथन निर्देशिका की स्थिति cd C:\...\Python\Python37\Scripts ।
- पाइप कमांड चलाएँ
install(हमारे मामले में, हमpip install pyMySQLचलाएंगे औरpip install sqlAlchemy।
पीआईपी का उपयोग मौजूदा मॉड्यूल को अनइंस्टॉल करने के लिए भी किया जा सकता है। ऐसा करने के लिए, आपको pip uninstall . का उपयोग करना चाहिए .
SQLAlchemy का उपयोग करने के लिए आवश्यक सब कुछ स्थापित करते समय आवश्यक है, यह बहुत दिलचस्प नहीं है। न ही यह वास्तव में हमारी रुचि का हिस्सा है। हम उन डेटाबेस से भी नहीं जुड़े हैं जिनका हम उपयोग करना चाहते हैं। हम इसे अभी हल करेंगे:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
उपरोक्त स्क्रिप्ट का उपयोग करके, हम अपने स्थानीय सर्वर, subscription_live पर स्थित डेटाबेस से एक कनेक्शन स्थापित करेंगे। डेटाबेस।
(नोट: बदलें <उपयोगकर्ता नाम>:<पासवर्ड> अपने वास्तविक उपयोगकर्ता नाम और पासवर्ड के साथ।)
आइए स्क्रिप्ट को देखें, कमांड बाय कमांड।
import sqlalchemy from sqlalchemy.engine import create_engine
ये दो लाइनें हमारे मॉड्यूल और create_engine को इम्पोर्ट करती हैं समारोह।
इसके बाद, हम अपने सर्वर पर स्थित डेटाबेस से एक कनेक्शन स्थापित करेंगे।
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
create_engine फ़ंक्शन इंजन बनाता है, और .connect() का उपयोग करता है , डेटाबेस से जुड़ता है। create_engine फ़ंक्शन इन मापदंडों का उपयोग करता है:
dialect+driver://username:password@host:port/database
हमारे मामले में, बोली mysql है , ड्राइवर है pymysql (पहले स्थापित) और शेष चर सर्वर और डेटाबेस के लिए विशिष्ट हैं जिन्हें हम कनेक्ट करना चाहते हैं।
(नोट: यदि आप स्थानीय रूप से कनेक्ट कर रहे हैं, तो localhost का उपयोग करें आपके "स्थानीय" आईपी पते के बजाय, 127.0.0.1 और उपयुक्त पोर्ट :3306 ।)

कमांड का परिणाम print(engine_live.table_names()) ऊपर चित्र में दिखाया गया है। जैसा कि अपेक्षित था, हमें अपने परिचालन/लाइव डेटाबेस से सभी तालिकाओं की सूची मिली है।
इस खंड में, हम सबसे महत्वपूर्ण SQL कमांड का विश्लेषण करेंगे, तालिका संरचना की जांच करेंगे, और सभी चार DML कमांड निष्पादित करेंगे:SELECT, INSERT, UPDATE, और DELETE।
हम इस लिपि में प्रयुक्त कथनों पर अलग से चर्चा करेंगे। कृपया ध्यान दें कि हम पहले ही इस स्क्रिप्ट के कनेक्शन भाग से गुजर चुके हैं और हमने पहले से ही तालिका नामों को सूचीबद्ध कर लिया है। इस लाइन में मामूली बदलाव हैं:
from sqlalchemy import create_engine, select, MetaData, Table, asc
हमने अभी वह सब कुछ आयात किया है जिसका उपयोग हम SQLAlchemy से करेंगे।
टेबल और संरचना
हम पायथन शेल में निम्न कमांड टाइप करके स्क्रिप्ट चलाएंगे:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
परिणाम निष्पादित स्क्रिप्ट है। अब बाकी की स्क्रिप्ट का विश्लेषण करते हैं।
SQLAlchemy तालिकाओं, संरचना और संबंधों से संबंधित जानकारी आयात करता है। उस जानकारी के साथ काम करने के लिए, डेटाबेस में तालिकाओं (और उनके कॉलम) की सूची की जाँच करना उपयोगी हो सकता है:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

यह बस कनेक्टेड डेटाबेस से सभी तालिकाओं की एक सूची देता है।
नोट: table_names() विधि दिए गए इंजन के लिए तालिका नामों की एक सूची देता है। आप पूरी सूची को प्रिंट कर सकते हैं या लूप का उपयोग करके इसके माध्यम से पुनरावृति कर सकते हैं (जैसा कि आप किसी अन्य सूची के साथ कर सकते हैं)।
इसके बाद, हम चयनित तालिका से सभी विशेषताओं की एक सूची लौटाएंगे। स्क्रिप्ट का प्रासंगिक भाग और परिणाम नीचे दिखाया गया है:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
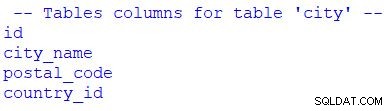
आप देख सकते हैं कि मैंने for . का उपयोग किया है परिणाम सेट के माध्यम से लूप करने के लिए। हम table_city.c को बदल सकते हैं table_city.columns . के साथ ।
नोट: SQLAlchemy में डेटाबेस विवरण लोड करने और मेटाडेटा बनाने की प्रक्रिया को प्रतिबिंब कहा जाता है।
नोट: मेटाडेटा वह ऑब्जेक्ट है जो डेटाबेस में ऑब्जेक्ट्स के बारे में जानकारी रखता है, इसलिए डेटाबेस में टेबल भी इस ऑब्जेक्ट से जुड़े होते हैं। सामान्य तौर पर, यह ऑब्जेक्ट डेटाबेस स्कीमा कैसा दिखता है, इसके बारे में जानकारी संग्रहीत करता है। जब आप परिवर्तन करना चाहते हैं या डीबी स्कीमा के बारे में तथ्य प्राप्त करना चाहते हैं तो आप इसे संपर्क के एकल बिंदु के रूप में उपयोग करेंगे।
नोट: विशेषताएँ autoload = True और autoload_with = engine_live यह सुनिश्चित करने के लिए उपयोग किया जाना चाहिए कि तालिका विशेषताएँ अपलोड की जाएंगी (यदि वे पहले से नहीं हैं)।
चुनें
मुझे नहीं लगता कि मुझे यह समझाने की ज़रूरत है कि चयन कथन कितना महत्वपूर्ण है :) तो, मान लीजिए कि आप चयन कथन लिखने के लिए SQLAlchemy का उपयोग कर सकते हैं। यदि आप MySQL सिंटैक्स के अभ्यस्त हैं, तो इसे अनुकूलित करने में कुछ समय लगेगा; फिर भी, सब कुछ बहुत तार्किक है। इसे यथासंभव सरलता से रखने के लिए, मैं कहूंगा कि SELECT स्टेटमेंट को काट दिया गया है और कुछ हिस्सों को छोड़ दिया गया है, लेकिन सब कुछ अभी भी उसी क्रम में है।
आइए अब कुछ सेलेक्ट स्टेटमेंट देखें।
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
पहला वाला एक साधारण चयन कथन है दी गई तालिका से सभी मान लौटा रहा है। इस कथन का सिंटैक्स बहुत सरल है:मैंने तालिका का नाम select() में रखा है . कृपया ध्यान दें कि मैंने:
- बयान तैयार किया -
stmt = select([table_city]। print(stmt)का उपयोग करके स्टेटमेंट को प्रिंट किया , जो हमें उस कथन के बारे में एक अच्छा विचार देता है जिसे अभी निष्पादित किया गया है। इसका उपयोग डिबगिंग के लिए भी किया जा सकता है।- परिणाम को
print(connection_live.execute(stmt).fetchall())के साथ प्रिंट किया । - परिणाम के माध्यम से लूप किया और प्रत्येक एक रिकॉर्ड को मुद्रित किया।
नोट: चूंकि हमने SQLAlchemy में प्राथमिक और विदेशी कुंजी बाधाओं को भी लोड किया है, SELECT स्टेटमेंट टेबल ऑब्जेक्ट्स की एक सूची को तर्क के रूप में लेता है और जहां आवश्यक हो वहां स्वचालित रूप से संबंध स्थापित करता है।
परिणाम नीचे चित्र में दिखाया गया है:

पायथन तालिका से सभी विशेषताओं को लाएगा और उन्हें वस्तु में संग्रहीत करेगा। जैसा कि दिखाया गया है, हम इस ऑब्जेक्ट का उपयोग अतिरिक्त ऑपरेशन करने के लिए कर सकते हैं। हमारे बयान का अंतिम परिणाम city टेबल।
अब, हम अधिक जटिल क्वेरी के लिए तैयार हैं। मैंने अभी-अभी एक ऑर्डर बाय क्लॉज जोड़ा है ।
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

नोट: asc() विधि पैरामीटर के रूप में परिभाषित कॉलम का उपयोग करते हुए, पैरेंट ऑब्जेक्ट के विरुद्ध आरोही सॉर्टिंग करती है।
लौटाई गई सूची वही है, लेकिन अब इसे आरोही क्रम में आईडी मान द्वारा क्रमबद्ध किया गया है। यह ध्यान रखना महत्वपूर्ण है कि हमने बस .order_by( जोड़ दिया है पिछली चयन क्वेरी के लिए। .order_by(...) विधि हमें लौटाए गए परिणाम सेट के क्रम को बदलने की अनुमति देती है, उसी तरह जैसे हम SQL क्वेरी में उपयोग करेंगे। इसलिए, पैरामीटर को कॉलम नाम या कॉलम ऑर्डर और एएससी या डीईएससी का उपयोग करके एसक्यूएल तर्क का पालन करना चाहिए।
इसके बाद, हम कहां जोड़ेंगे हमारे सेलेक्ट स्टेटमेंट के लिए।
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

नोट: .where() विधि का उपयोग उस स्थिति का परीक्षण करने के लिए किया जाता है जिसे हमने तर्क के रूप में उपयोग किया है। हम .filter() . का भी उपयोग कर सकते हैं विधि, जो अधिक जटिल परिस्थितियों को छानने में बेहतर है।
एक बार फिर, .where भाग को केवल हमारे SELECT स्टेटमेंट से जोड़ा जाता है। ध्यान दें कि हमने शर्त को कोष्ठक के अंदर रखा है। कोष्ठक में जो भी स्थिति है, उसी तरह से परीक्षण किया जाता है जैसे कि SELECT स्टेटमेंट के WHERE भाग में इसका परीक्षण किया जाएगा। =के बजाय ==का उपयोग करके समानता की स्थिति का परीक्षण किया जाता है।
आखिरी चीज जिसे हम SELECT के साथ आजमाएंगे, वह है दो टेबलों को जोड़ना। आइए पहले कोड और उसके परिणाम पर एक नज़र डालें।
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

उपरोक्त कथन में दो महत्वपूर्ण भाग हैं:
select([table_city.columns.city_name, table_country.columns.country_name])परिभाषित करता है कि हमारे परिणाम में कौन से कॉलम लौटाए जाएंगे।.select_from(table_city.join(table_country))जॉइन कंडीशन/टेबल को परिभाषित करता है। ध्यान दें कि हमें चाबियों सहित पूर्ण जुड़ने की स्थिति नहीं लिखनी है। ऐसा इसलिए है क्योंकि SQLAlchemy "जानता है" कि इन दो तालिकाओं को कैसे जोड़ा जाता है, क्योंकि प्राथमिक कुंजी और विदेशी कुंजी नियम पृष्ठभूमि में आयात किए जाते हैं।
सम्मिलित करें / अद्यतन करें / हटाएं
ये तीन शेष डीएमएल कमांड हैं जिन्हें हम इस लेख में शामिल करेंगे। जबकि उनकी संरचना बहुत जटिल हो सकती है, ये आदेश आमतौर पर बहुत सरल होते हैं। इस्तेमाल किया गया कोड नीचे प्रस्तुत किया गया है।
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
तीनों स्टेटमेंट के लिए एक ही पैटर्न का उपयोग किया जाता है:स्टेटमेंट तैयार करना, उसे प्रिंट करना और निष्पादित करना, और प्रत्येक स्टेटमेंट के बाद रिजल्ट को प्रिंट करना ताकि हम देख सकें कि डेटाबेस में वास्तव में क्या हुआ था। एक बार फिर ध्यान दें कि कथन के कुछ हिस्सों को वस्तुओं (.values(), .where()) के रूप में माना जाता था।

हम इस ज्ञान का उपयोग आगामी लेख में SQLAlchemy का उपयोग करके एक संपूर्ण ETL स्क्रिप्ट बनाने के लिए करेंगे।
अगला ऊपर:ETL प्रक्रिया में SQLAlchemy
आज हमने विश्लेषण किया है कि SQLAlchemy कैसे सेट करें और सरल DML कमांड कैसे करें। अगले लेख में, हम इस ज्ञान का उपयोग SQLAlchemy का उपयोग करके पूरी ETL प्रक्रिया लिखने के लिए करेंगे।
आप इस लेख में प्रयुक्त पूरी स्क्रिप्ट यहाँ से डाउनलोड कर सकते हैं।