पहले हमने Google क्लाउड प्लेटफ़ॉर्म (GCP) पर MySQL फ़ेलओवर और फ़ेलबैक प्राप्त करने पर चर्चा करते हुए एक ब्लॉग पोस्ट किया था और इस ब्लॉग में हम देखेंगे कि यह प्रतिद्वंद्वी, Amazon रिलेशनल डेटाबेस सर्विस (RDS) कैसे फ़ेलओवर को संभालता है। हम यह भी देखेंगे कि आप अपने पूर्व मास्टर नोड की विफलता कैसे कर सकते हैं, इसे मास्टर के रूप में अपने मूल क्रम में वापस ला सकते हैं।
प्रबंधित रिलेशनल डेटाबेस सेवाओं का समर्थन करने वाले तकनीकी-विशाल सार्वजनिक बादलों की तुलना करते समय, अमेज़ॅन एकमात्र ऐसा विकल्प है जो वितरित करने के लिए एक वैकल्पिक विकल्प (MySQL/MariaDB, PostgreSQL, Oracle, और SQL सर्वर के साथ) प्रदान करता है। अपनी तरह का डेटाबेस प्रबंधन जिसे Amazon Aurora कहा जाता है। जो लोग औरोरा से परिचित नहीं हैं, उनके लिए यह पूरी तरह से प्रबंधित रिलेशनल डेटाबेस इंजन है जो MySQL और PostgreSQL के साथ संगत है। Aurora प्रबंधित डेटाबेस सेवा Amazon RDS का हिस्सा है, जो एक वेब सेवा है जो क्लाउड में रिलेशनल डेटाबेस को सेट करना, संचालित करना और स्केल करना आसान बनाती है।
आपको फ़ेलओवर या फ़ेलबैक की आवश्यकता क्यों होगी?
एक बड़ी प्रणाली को डिजाइन करना जो दोष-सहिष्णु, अत्यधिक-उपलब्ध हो, जिसमें कोई सिंगल-पॉइंट-ऑफ-फेल्योर (एसपीओएफ) न हो, यह निर्धारित करने के लिए उचित परीक्षण की आवश्यकता होती है कि चीजें गलत होने पर यह कैसे प्रतिक्रिया करेगी।
यदि आप इस बात से चिंतित हैं कि आपके सिस्टम के दोष का पता लगाने, अलगाव और पुनर्प्राप्ति (FDIR) का जवाब देते समय आपका सिस्टम कैसा प्रदर्शन करेगा, तो फ़ेलओवर और फ़ेलबैक का अत्यधिक महत्व होना चाहिए।
Amazon RDS में डेटाबेस फ़ेलओवर
विफलता स्वचालित रूप से होती है (क्योंकि मैन्युअल विफलता को स्विचओवर कहा जाता है)। जैसा कि पिछले ब्लॉग में चर्चा की गई थी, विफलता की आवश्यकता तब होती है जब आपका वर्तमान डेटाबेस मास्टर नेटवर्क विफलता या होस्ट सिस्टम की असामान्य समाप्ति का अनुभव करता है। फ़ेलओवर इसे अतिरेक की स्थिर स्थिति या स्टैंडबाय कंप्यूटर सर्वर, सिस्टम, हार्डवेयर घटक, या नेटवर्क में बदल देता है।
अमेज़ॅन आरडीएस में आपको ऐसा करने की आवश्यकता नहीं है, न ही आपको स्वयं इसकी निगरानी करने की आवश्यकता है, क्योंकि आरडीएस एक प्रबंधित डेटाबेस सेवा है (जिसका अर्थ है कि अमेज़ॅन आपके लिए नौकरी संभालता है)। यह सेवा हार्डवेयर समस्याओं, बैकअप और पुनर्प्राप्ति, सॉफ़्टवेयर अपडेट, संग्रहण अपग्रेड और यहां तक कि सॉफ़्टवेयर पैचिंग जैसी चीज़ों का प्रबंधन करती है। हम इसके बारे में इस ब्लॉग में बाद में बात करेंगे।
Amazon RDS में डेटाबेस फ़ेलबैक
पिछले ब्लॉग में हमने यह भी बताया था कि आपको फ़ेलबैक की आवश्यकता क्यों होगी। एक विशिष्ट प्रतिकृति वातावरण में मास्टर को एक बड़ा भार उठाने के लिए पर्याप्त शक्तिशाली होना चाहिए, खासकर जब कार्यभार की आवश्यकता अधिक हो। आपके मास्टर सेटअप के लिए पर्याप्त हार्डवेयर स्पेक्स की आवश्यकता होती है ताकि यह सुनिश्चित हो सके कि यह लिखने की प्रक्रिया कर सकता है, प्रतिकृति ईवेंट उत्पन्न कर सकता है, महत्वपूर्ण पठन को संसाधित कर सकता है, आदि, स्थिर तरीके से। जब आपदा पुनर्प्राप्ति (या रखरखाव के लिए) के दौरान विफलता की आवश्यकता होती है, तो यह असामान्य नहीं है कि नए मास्टर का प्रचार करते समय आप निम्न हार्डवेयर का उपयोग कर सकते हैं। यह स्थिति अस्थायी रूप से ठीक हो सकती है, लेकिन लंबे समय में, नामित मास्टर को प्रतिकृति का नेतृत्व करने के लिए वापस लाया जाना चाहिए, जब इसे स्वस्थ माना जाता है (या रखरखाव पूरा हो जाता है)।
फेलओवर के विपरीत, फेलबैक ऑपरेशन आमतौर पर स्विचओवर का उपयोग करके नियंत्रित वातावरण में होते हैं। यह शायद ही कभी किया जाता है जब पैनिक-मोड में होता है। यह दृष्टिकोण आपके इंजीनियरों को एक सुचारु परिवर्तन सुनिश्चित करने के लिए सावधानीपूर्वक योजना बनाने और अभ्यास का पूर्वाभ्यास करने के लिए पर्याप्त समय प्रदान करता है। इसका मुख्य उद्देश्य केवल अच्छे, पुराने मास्टर को नवीनतम स्थिति में वापस लाना और प्रतिकृति सेटअप को उसके मूल टोपोलॉजी में पुनर्स्थापित करना है। चूंकि हम Amazon RDS के साथ काम कर रहे हैं, इसलिए वास्तव में आपको इस प्रकार के मुद्दों के बारे में अत्यधिक चिंतित होने की कोई आवश्यकता नहीं है क्योंकि यह एक प्रबंधित सेवा है जिसमें अधिकांश कार्य Amazon द्वारा नियंत्रित किए जाते हैं।
अमेज़ॅन आरडीएस डाटाबेस फेलओवर को कैसे संभालता है?
अपने Amazon RDS नोड्स को परिनियोजित करते समय, आप अपने डेटाबेस क्लस्टर को बहु-उपलब्धता क्षेत्र (AZ) या एकल-उपलब्धता क्षेत्र के साथ सेटअप कर सकते हैं। आइए उनमें से प्रत्येक की जाँच करें कि फ़ेलओवर को कैसे संसाधित किया जा रहा है।
मल्टी-एजेड सेटअप क्या है?
जब आपदा या आपदा आती है, जैसे कि अनियोजित व्यवधान या प्राकृतिक आपदाएं जहां आपके डेटाबेस इंस्टेंस प्रभावित होते हैं, तो Amazon RDS स्वचालित रूप से किसी अन्य उपलब्धता क्षेत्र में एक स्टैंडबाय प्रतिकृति पर स्विच हो जाता है। यह AZ आमतौर पर डेटा सेंटर की दूसरी शाखा में होता है, जो अक्सर वर्तमान उपलब्धता क्षेत्र से दूर होता है जहां इंस्टेंस स्थित होते हैं। ये AZ आपके डेटाबेस इंस्टेंस की सुरक्षा के लिए अत्यधिक उपलब्ध, अत्याधुनिक सुविधाएं हैं। विफलता का समय सेटअप के पूरा होने पर निर्भर करता है जो अक्सर डेटाबेस के आकार और गतिविधि के साथ-साथ प्राथमिक डीबी इंस्टेंस अनुपलब्ध होने पर मौजूद अन्य स्थितियों पर आधारित होता है।
विफलता समय आमतौर पर 60-120 सेकंड का होता है। हालांकि वे लंबे हो सकते हैं, क्योंकि बड़े लेनदेन या लंबी पुनर्प्राप्ति प्रक्रिया विफलता समय बढ़ा सकती है। जब फ़ेलओवर पूरा हो जाता है, तो RDS कंसोल (UI) को नए उपलब्धता क्षेत्र को प्रतिबिंबित करने में अतिरिक्त समय भी लग सकता है।
सिंगल-एजेड सेटअप क्या है?
सिंगल-एजेड सेटअप का उपयोग केवल आपके डेटाबेस इंस्टेंस के लिए किया जाना चाहिए यदि आपका आरटीओ (रिकवरी टाइम ऑब्जेक्टिव) और आरपीओ (रिकवरी पॉइंट ऑब्जेक्टिव) इसकी अनुमति देने के लिए पर्याप्त हैं। सिंगल-एजेड का उपयोग करने में जोखिम शामिल हैं, जैसे कि बड़े डाउनटाइम जो व्यावसायिक संचालन को बाधित कर सकते हैं।
आम RDS विफलता परिदृश्य
डाउनटाइम की मात्रा विफलता के प्रकार पर निर्भर करती है। आइए देखें कि ये क्या हैं और इंस्टेंस की रिकवरी कैसे की जाती है।
पुनर्प्राप्ति योग्य इंस्टेंस विफलता
Amazon RDS इंस्टेंस विफलता तब होती है जब अंतर्निहित EC2 इंस्टेंस विफल हो जाता है। घटना होने पर, AWS एक ईवेंट नोटिफिकेशन को ट्रिगर करेगा और Amazon RDS इवेंट नोटिफिकेशन का उपयोग करके आपको एक अलर्ट भेजेगा। यह सिस्टम अलर्ट प्रोसेसर के रूप में AWS सिंपल नोटिफिकेशन सर्विस (SNS) का उपयोग करता है।
RDS स्वचालित रूप से उसी उपलब्धता क्षेत्र में एक नया इंस्टेंस लॉन्च करने का प्रयास करेगा, EBS वॉल्यूम संलग्न करेगा, और पुनर्प्राप्ति का प्रयास करेगा। इस परिदृश्य में, RTO सामान्यतया 30 मिनट से कम है। आरपीओ शून्य है क्योंकि ईबीएस वॉल्यूम को पुनर्प्राप्त करने में सक्षम था। EBS वॉल्यूम एकल उपलब्धता क्षेत्र में है और इस प्रकार की पुनर्प्राप्ति मूल आवृत्ति के समान उपलब्धता क्षेत्र में होती है।
गैर-वसूली योग्य इंस्टेंस विफलताएं या ईबीएस वॉल्यूम विफलताएं
असफल RDS इंस्टेंस रिकवरी के लिए (या यदि अंतर्निहित EBS वॉल्यूम में डेटा हानि की विफलता होती है) पॉइंट-इन-टाइम रिकवरी (PITR) आवश्यक है। PITR स्वचालित रूप से Amazon द्वारा नियंत्रित नहीं किया जाता है, इसलिए आपको या तो इसे स्वचालित करने के लिए एक स्क्रिप्ट बनाने की आवश्यकता है (AWS लैम्ब्डा का उपयोग करके) या इसे मैन्युअल रूप से करें।
आरटीओ समय के लिए एक नया अमेज़ॅन आरडीएस इंस्टेंस शुरू करने की आवश्यकता होती है, जिसमें एक बार एक नया डीएनएस नाम होगा, और फिर अंतिम बैकअप के बाद से सभी परिवर्तनों को लागू करना होगा।
RPO आमतौर पर 5 मिनट का होता है, लेकिन आप इसे RDS:describe-db-instances:LatestRestorableTime पर कॉल करके ढूंढ सकते हैं। लॉग की संख्या के आधार पर समय 10 मिनट से लेकर घंटों तक भिन्न हो सकता है जिसे लागू करने की आवश्यकता होती है। यह केवल परीक्षण द्वारा निर्धारित किया जा सकता है क्योंकि यह डेटाबेस के आकार, पिछले बैकअप के बाद से किए गए परिवर्तनों की संख्या और डेटाबेस पर कार्यभार के स्तर पर निर्भर करता है। चूंकि बैकअप और लेन-देन लॉग Amazon S3 में संग्रहीत हैं, इसलिए यह पुनर्प्राप्ति क्षेत्र के किसी भी समर्थित उपलब्धता क्षेत्र में हो सकती है।
नया इंस्टेंस बनने के बाद, आपको अपने क्लाइंट के एंडपॉइंट नाम को अपडेट करना होगा। आपके पास पुराने डीबी इंस्टेंस के एंडपॉइंट नाम पर इसका नाम बदलने का विकल्प भी है (लेकिन इसके लिए आपको पुराने असफल इंस्टेंस को हटाना होगा) लेकिन इससे समस्या का मूल कारण असंभव हो जाता है।
उपलब्धता क्षेत्र में व्यवधान
उपलब्धता क्षेत्र में व्यवधान अस्थायी और दुर्लभ हो सकते हैं, हालांकि, यदि AZ विफलता अधिक स्थायी है तो इंस्टेंस को विफल स्थिति में सेट कर दिया जाएगा। पुनर्प्राप्ति पहले बताए अनुसार काम करेगी और पॉइंट-इन-टाइम पुनर्प्राप्ति का उपयोग करके एक अलग AZ में एक नया उदाहरण बनाया जा सकता है। यह चरण मैन्युअल रूप से या स्क्रिप्टिंग द्वारा किया जाना है। इस प्रकार के पुनर्प्राप्ति परिदृश्य के लिए रणनीति आपकी बड़ी आपदा पुनर्प्राप्ति (DR) योजनाओं का हिस्सा होनी चाहिए।
यदि उपलब्धता क्षेत्र की विफलता अस्थायी है, तो डेटाबेस डाउन हो जाएगा लेकिन उपलब्ध स्थिति में रहेगा। आप इस प्रकार के परिदृश्य का पता लगाने के लिए एप्लिकेशन-स्तरीय निगरानी (अमेज़ॅन या तीसरे पक्ष के टूल का उपयोग करके) के लिए ज़िम्मेदार हैं। यदि ऐसा होता है तो आप उपलब्धता क्षेत्र के ठीक होने की प्रतीक्षा कर सकते हैं, या आप समय-समय पर पुनर्प्राप्ति के साथ किसी अन्य उपलब्धता क्षेत्र में इंस्टेंस को पुनर्प्राप्त करना चुन सकते हैं।
आरटीओ वह समय होगा जो एक नया आरडीएस इंस्टेंस शुरू करने में लगता है और फिर अंतिम बैकअप के बाद से सभी परिवर्तनों को लागू करता है। उपलब्धता क्षेत्र की विफलता के समय तक आरपीओ लंबा हो सकता है।
Amazon RDS पर परीक्षण विफलता और विफलता
हमने एक मल्टी-एजेड परिनियोजन के साथ db.r4.large का उपयोग करके एक Amazon RDS Aurora बनाया और सेटअप किया (जो एक अलग AZ में एक ऑरोरा प्रतिकृति/रीडर बनाएगा) जो केवल EC2 के माध्यम से सुलभ है। यदि आप Amazon RDS को फेलओवर मैकेनिज्म के रूप में रखना चाहते हैं, तो आपको निर्माण के समय इस विकल्प को चुनना सुनिश्चित करना होगा।
हमारे RDS इंस्टेंस के प्रावधान के दौरान, इसमें लगभग ~11 मिनट का समय लगा उदाहरण उपलब्ध और सुलभ हो गए। निर्माण के बाद आरडीएस में उपलब्ध नोड्स का स्क्रीनशॉट नीचे दिया गया है:
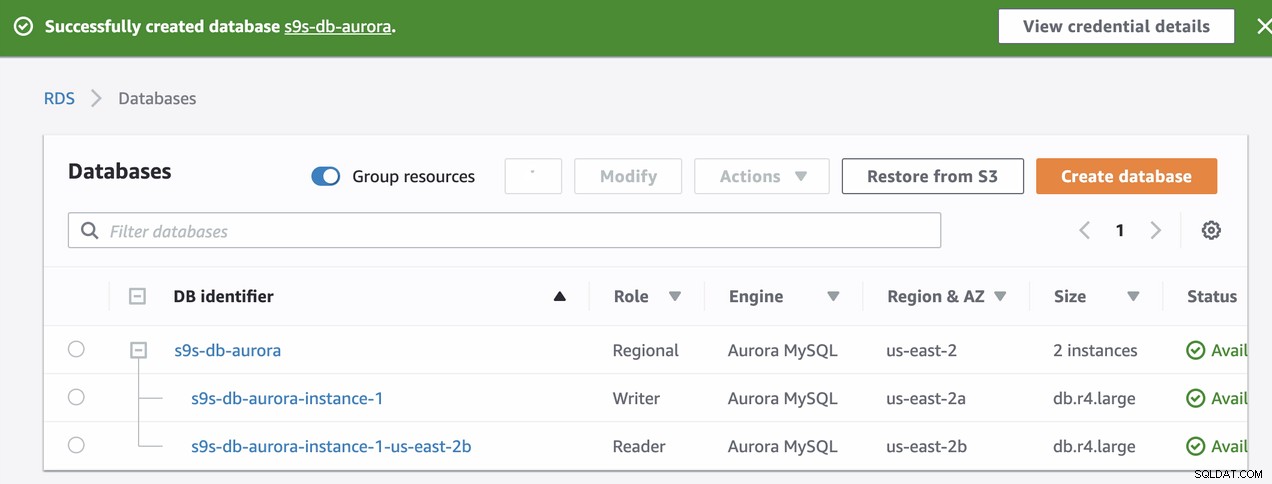
इन दोनों नोड्स के अपने निर्दिष्ट समापन बिंदु नाम होंगे, जिन्हें हम क्लाइंट के दृष्टिकोण से कनेक्ट करने के लिए उपयोग करें। पहले इसे सत्यापित करें और इनमें से प्रत्येक नोड के लिए अंतर्निहित होस्टनाम की जांच करें। जाँच करने के लिए, आप नीचे इस बैश कमांड को चला सकते हैं और उसके अनुसार होस्टनाम/एंडपॉइंट नामों को बदल सकते हैं:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+परिणाम इस प्रकार स्पष्ट करता है,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)अमेज़ॅन आरडीएस फ़ेलओवर सिम्युलेट करना
अब, Amazon RDS Aurora लेखक उदाहरण के लिए एक विफलता अनुकरण करने के लिए एक क्रैश का अनुकरण करते हैं, जो कि s9s-db-aurora-instance-1 है जिसमें एंडपॉइंट s9s-db-aurora.cluster-cmu8qdlvkepg.us है। -पूर्व-2.rds.amazonaws.com।
ऐसा करने के लिए, mysql क्लाइंट कमांड प्रॉम्प्ट का उपयोग करके अपने लेखक उदाहरण से कनेक्ट करें और फिर नीचे सिंटैक्स जारी करें:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];इस कमांड को जारी करने से इसकी Amazon RDS रिकवरी डिटेक्शन होती है और यह बहुत जल्दी काम करती है। हालांकि क्वेरी परीक्षण उद्देश्यों के लिए है, यह तब भिन्न हो सकती है जब यह घटना किसी तथ्यात्मक घटना में होती है। हो सकता है कि आप उनके दस्तावेज़ों में इंस्टेंस क्रैश के परीक्षण के बारे में अधिक जानने में रुचि रखते हों। देखें कि हम नीचे कैसे समाप्त होते हैं:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)उपरोक्त SQL कमांड चलाने का अर्थ है कि उसे कम से कम 3 मिनट के लिए डिस्क विफलता का अनुकरण करना होगा। मैंने सिमुलेशन शुरू करने के लिए समय पर निगरानी की और फेलओवर शुरू होने में लगभग 18 सेकंड का समय लगा।
नीचे देखें कि कैसे RDS सिम्युलेशन विफलता और विफलता को संभालता है,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+इस सिमुलेशन के परिणाम काफी दिलचस्प हैं। आइए इसे एक बार में लें।
- लगभग 10:06:29 पर, मैंने ऊपर बताए अनुसार सिमुलेशन क्वेरी चलाना शुरू किया।
- लगभग 10:06:44 बजे, यह दर्शाता है कि समापन बिंदु s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com ip-10-20-1- के असाइन किए गए होस्टनाम के साथ- 139 जहां वास्तव में यह केवल-पढ़ने का उदाहरण है, पहुंच से बाहर हो गया, फिर भी सिम्युलेशन कमांड को रीड-राइट इंस्टेंस के तहत चलाया गया था।
- लगभग 10:06:51 पर, यह दिखाता है कि समापन बिंदु s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com ip-10-20-1- के असाइन किए गए होस्टनाम के साथ- 139 ऊपर है, लेकिन इसे पढ़ने-लिखने की स्थिति के रूप में चिह्नित किया गया है। ध्यान दें कि ऑरोरा MySQL प्रबंधित इंस्टेंस के लिए वेरिएबल innodb_read_only, यह निर्धारित करने के लिए इसका पहचानकर्ता है कि क्या होस्ट रीड-राइट या रीड-ओनली नोड है और ऑरोरा भी MySQL कॉम्पटेबल इंस्टेंस के लिए केवल InnoDB स्टोरेज इंजन पर चलता है।
- लगभग 10:07:13 बजे, क्रम बदल गया है। इसका मतलब है कि विफलता हो गई थी और उदाहरणों को इसके निर्दिष्ट समापन बिंदुओं को सौंपा गया है।
नीचे दिए गए परिणाम को चेकआउट करें जो RDS कंसोल में दिखाया गया है:
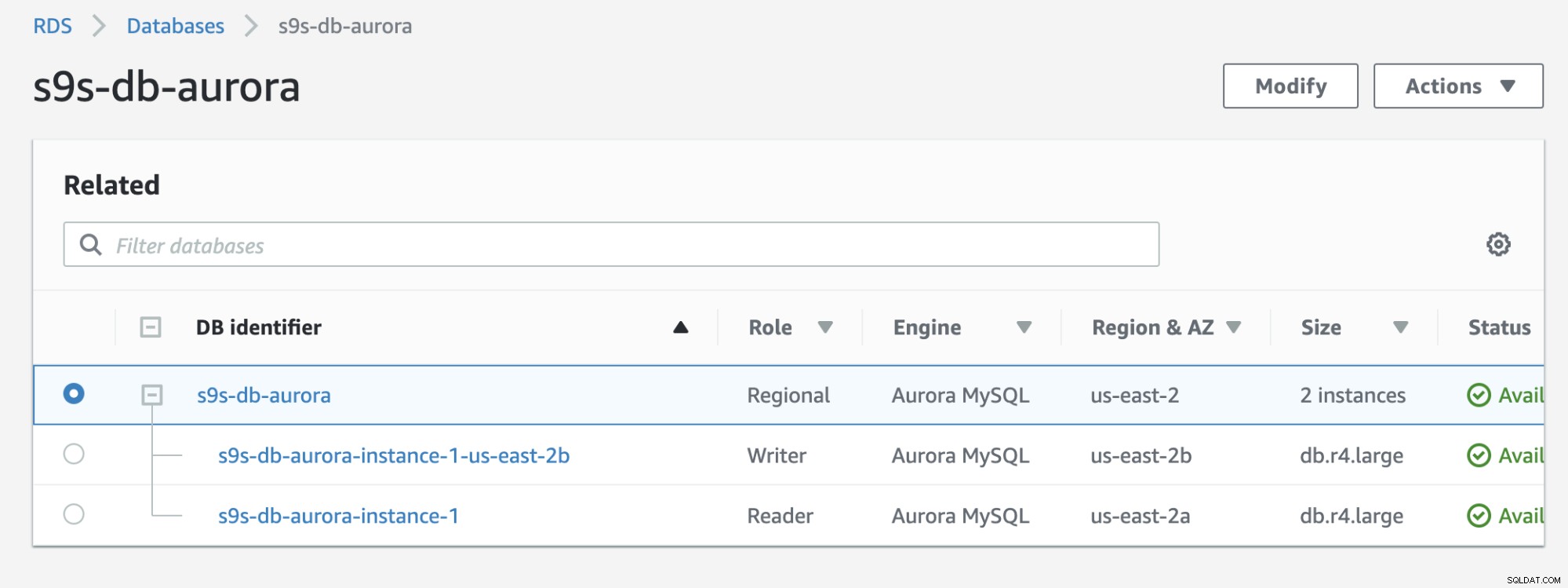
यदि आप पहले वाले से तुलना करें तो s9s-db-aurora- इंस्टेंस -1 एक पाठक था, लेकिन फिर फेलओवर के बाद एक लेखक के रूप में पदोन्नत हो गया। परीक्षण सहित प्रक्रिया में कार्य को पूरा करने में लगभग 44 सेकंड का समय लगा, लेकिन फेलओवर शो लगभग 30 सेकंड में पूरा हुआ। यह एक विफलता के लिए प्रभावशाली और तेज़ है, विशेष रूप से यह एक प्रबंधित सेवा डेटाबेस है; यानी आपको किसी हार्डवेयर या रखरखाव के मुद्दों के बारे में चिंता करने की ज़रूरत नहीं है।
Amazon RDS में फ़ेलबैक करना
अमेज़ॅन आरडीएस में फ़ेलबैक बहुत आसान है। इसे पढ़ने से पहले, आइए एक नई पाठक प्रतिकृति जोड़ें। हमें यह जांचने और पहचानने के लिए एक विकल्प की आवश्यकता है कि जब एडब्ल्यूएस आरडीएस असफल होने की कोशिश करता है तो वह किस नोड से चुनेगा-वांछित मास्टर (या पिछले मास्टर को फेलबैक) और यह देखने के लिए कि क्या यह प्राथमिकता के आधार पर सही नोड का चयन करता है। अब तक के उदाहरणों की वर्तमान सूची और इसके समापन बिंदु नीचे दिखाए गए हैं।
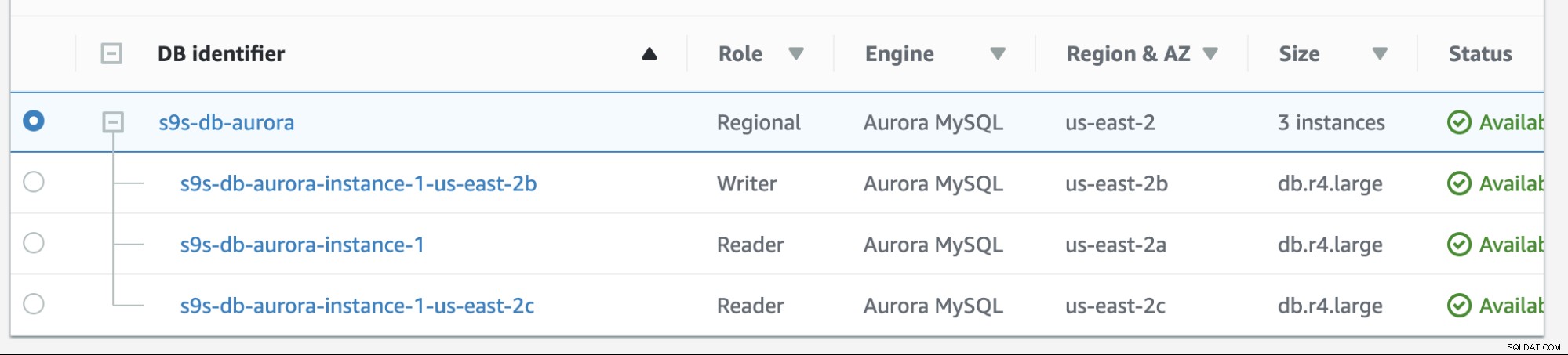

नई प्रतिकृति us-east-2c AZ पर db होस्टनाम के साथ स्थित है आईपी-10-20-2-239 का।
हम वांछित फ़ेलबैक लक्ष्य के रूप में उदाहरण s9s-db-aurora-instance-1 का उपयोग करके एक फ़ेलबैक करने का प्रयास करेंगे। इस सेटअप में हमारे पास दो पाठक उदाहरण हैं। यह सुनिश्चित करने के लिए कि विफलता के दौरान सही नोड उठाया जाता है, आपको यह स्थापित करने की आवश्यकता होगी कि क्या प्राथमिकता या उपलब्धता शीर्ष पर है (टियर -0> टियर -1> टियर -2 और इसी तरह टियर -15 तक)। यह उदाहरण को संशोधित करके या प्रतिकृति के निर्माण के दौरान किया जा सकता है।
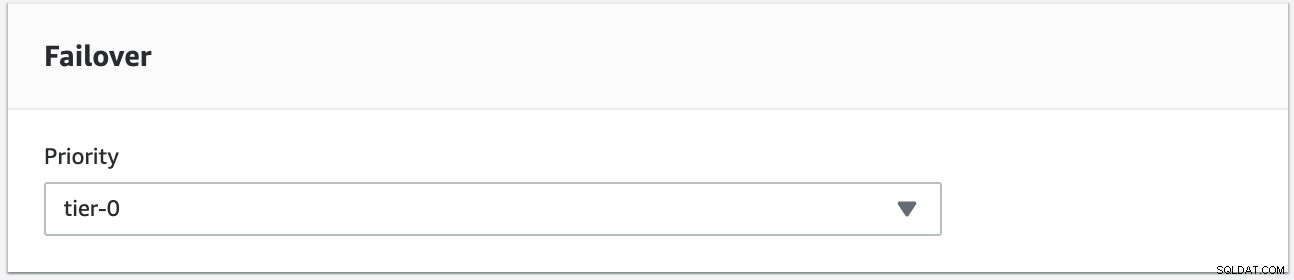
आप इसे अपने RDS कंसोल में सत्यापित कर सकते हैं।
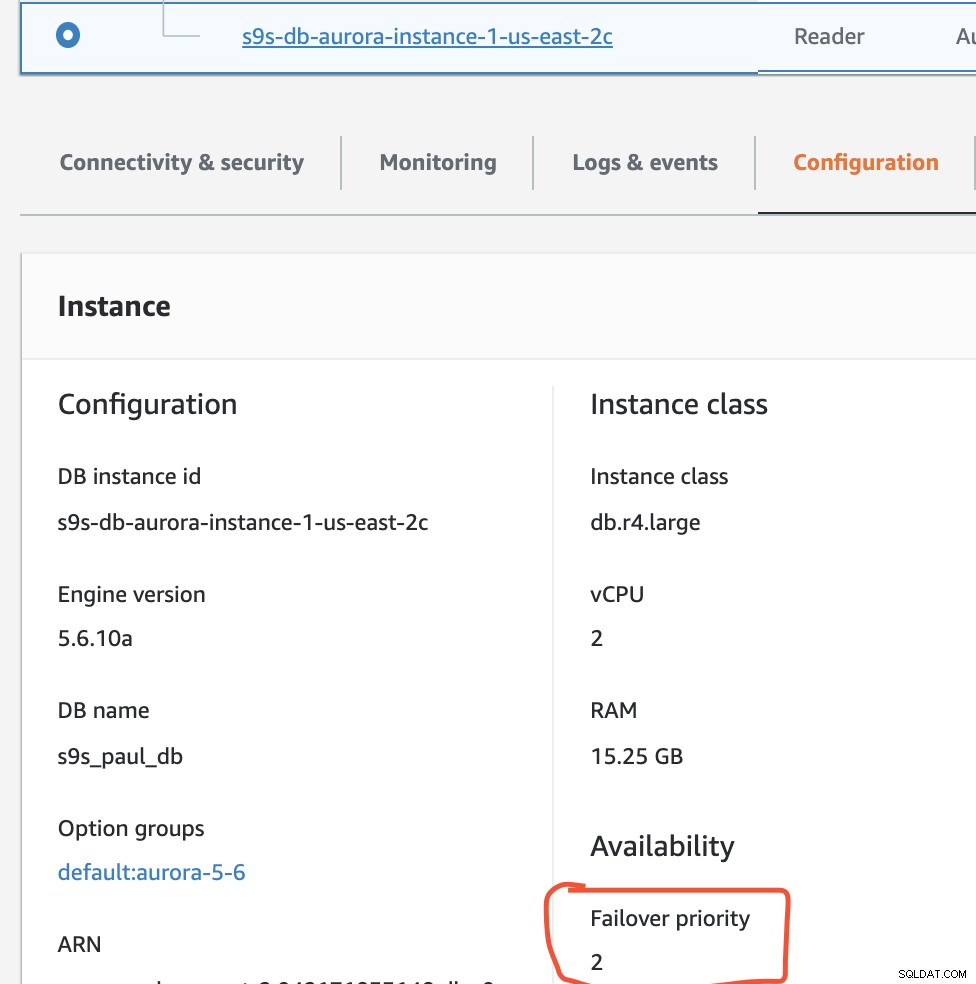
इस सेटअप में s9s-db-aurora-instance-1 की प्राथमिकता है =0 (और एक रीड-रेप्लिका है), s9s-db-aurora-instance-1-us-east-2b में प्राथमिकता =1 (और वर्तमान लेखक है), और s9s-db-aurora-instance-1-us- East-2c की प्राथमिकता =2 है (और यह एक पठन-प्रतिकृति भी है)। आइए देखें कि जब हम असफल होने का प्रयास करते हैं तो क्या होता है।
आप इस आदेश का उपयोग करके राज्य की निगरानी कर सकते हैं।
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;फेलओवर ट्रिगर होने के बाद, यह हमारे वांछित लक्ष्य पर वापस आ जाएगा, जो कि नोड s9s-db-aurora-instance-1 है।
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+असफल होने का प्रयास 13:30:59 बजे शुरू हुआ और यह लगभग 13:31:38 (निकटतम 30 सेकंड का निशान) पूरा हुआ। यह इस परीक्षण पर ~ 32 सेकंड तक समाप्त होता है, जो अभी भी तेज़ है।
मैंने कई बार फेलओवर/फेलबैक सत्यापित किया है और यह इंस्टेंस s9s-db-aurora-instance-1 और s9s-db-aurora-instance-1- के बीच लगातार अपनी रीड-राइट स्थिति का आदान-प्रदान कर रहा है। यूएस-ईस्ट-2बी. यह s9s-db-aurora-instance-1-us-east-2c को तब तक छोड़ देता है जब तक कि दोनों नोड्स समस्याओं का सामना नहीं कर रहे हों (जो कि बहुत दुर्लभ है क्योंकि वे सभी अलग-अलग AZ में स्थित हैं)।
फेलओवर/फेलबैक प्रयासों के दौरान, आरडीएस लगभग 15 - 25 सेकंड (जो बहुत तेज है) पर विफलता के दौरान तीव्र संक्रमण गति से चलता है। ध्यान रखें, हमारे पास इस उदाहरण पर बड़ी डेटा फ़ाइलें संग्रहीत नहीं हैं, लेकिन यह अभी भी काफी प्रभावशाली है क्योंकि प्रबंधन के लिए और कुछ नहीं है।
निष्कर्ष
सिंगल-एजेड चलाने से फेलओवर होने पर खतरा पैदा हो जाता है। अमेज़ॅन आरडीएस आपको अपने सिंगल-एजेड को मल्टी-एजेड सक्षम सेटअप में संशोधित और परिवर्तित करने की अनुमति देता है, हालांकि यह आपके लिए कुछ लागत जोड़ देगा। सिंगल-एजेड ठीक हो सकता है यदि आप उच्च आरटीओ और आरपीओ समय के साथ ठीक हैं, लेकिन निश्चित रूप से उच्च-ट्रैफिक, मिशन-महत्वपूर्ण, व्यावसायिक अनुप्रयोगों के लिए अनुशंसित नहीं है।
मल्टी-एजेड के साथ, आप अमेज़ॅन आरडीएस पर फ़ेलओवर और फ़ेलबैक को स्वचालित कर सकते हैं, अपना समय क्वेरी ट्यूनिंग या ऑप्टिमाइज़ेशन पर केंद्रित कर सकते हैं। यह DevOps या DBA के सामने आने वाली कई समस्याओं को कम करता है।
हालांकि Amazon RDS कुछ संगठनों में दुविधा का कारण बन सकता है (क्योंकि यह प्लेटफ़ॉर्म अज्ञेयवादी नहीं है), यह अभी भी विचार करने योग्य है; विशेष रूप से यदि आपके आवेदन के लिए दीर्घकालिक डीआर योजना की आवश्यकता है और आप हार्डवेयर और क्षमता नियोजन के बारे में चिंता करने में समय व्यतीत नहीं करना चाहते हैं।



