यह आलेख तालिका भावों के बारे में श्रृंखला का छठा भाग है। पिछले महीने भाग 5 में मैंने गैर-पुनरावर्ती सीटीई के तार्किक उपचार को कवर किया। इस महीने मैं पुनरावर्ती सीटीई के तार्किक उपचार को कवर करता हूं। मैं पुनरावर्ती सीटीई के लिए टी-एसक्यूएल के समर्थन के साथ-साथ मानक तत्वों का वर्णन करता हूं जो अभी तक टी-एसक्यूएल द्वारा समर्थित नहीं हैं। मैं असमर्थित तत्वों के लिए तार्किक रूप से समकक्ष टी-एसक्यूएल वर्कअराउंड प्रदान करता हूं।
नमूना डेटा
नमूना डेटा के लिए मैं कर्मचारी नामक एक तालिका का उपयोग करूंगा, जिसमें कर्मचारियों का एक पदानुक्रम होता है। एम्पीड कॉलम अधीनस्थ (चाइल्ड नोड) की कर्मचारी आईडी का प्रतिनिधित्व करता है, और एमजीग्रिड कॉलम प्रबंधक (पैरेंट नोड) की कर्मचारी आईडी का प्रतिनिधित्व करता है। tempdb डेटाबेस में कर्मचारी तालिका बनाने और पॉप्युलेट करने के लिए निम्न कोड का उपयोग करें:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary); ध्यान दें कि कर्मचारी पदानुक्रम की जड़- सीईओ- के पास एमजीग्रिड कॉलम में एक न्यूल है। बाकी सभी कर्मचारियों के पास एक प्रबंधक होता है, इसलिए उनका एमजीग्रिड कॉलम उनके प्रबंधक की कर्मचारी आईडी पर सेट होता है।
चित्र 1 में कर्मचारी पदानुक्रम का चित्रमय चित्रण है, जिसमें कर्मचारी का नाम, आईडी और पदानुक्रम में उसका स्थान दिखाया गया है।
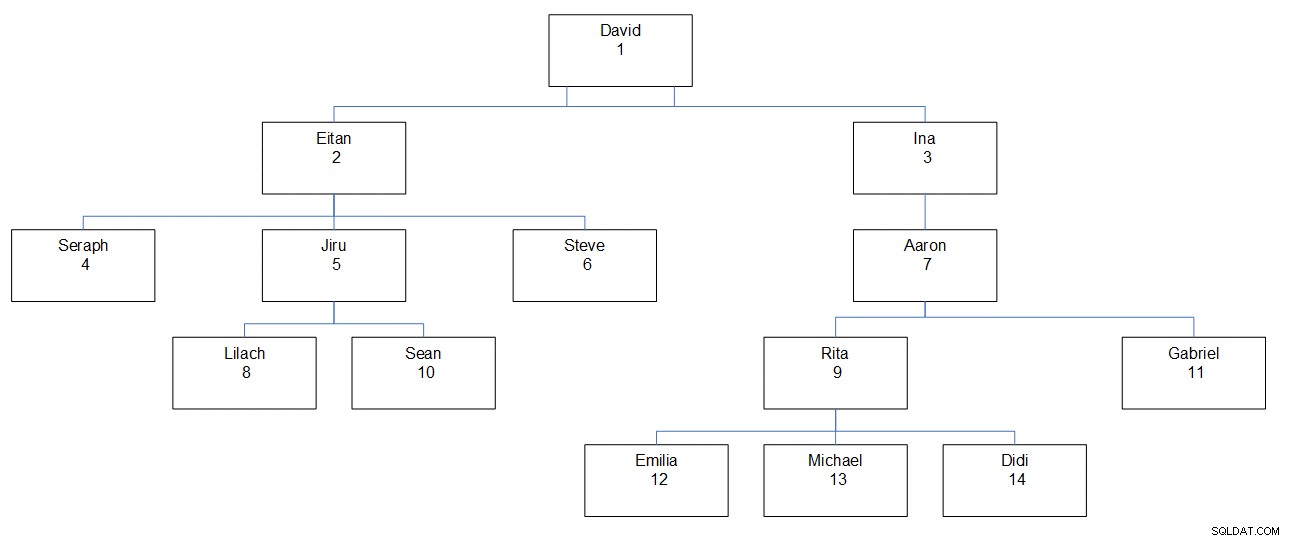 चित्र 1:कर्मचारी पदानुक्रम
चित्र 1:कर्मचारी पदानुक्रम
पुनरावर्ती CTE
रिकर्सिव सीटीई के कई उपयोग के मामले हैं। उपयोगों की एक क्लासिक श्रेणी का संबंध हमारे कर्मचारी पदानुक्रम की तरह, ग्राफ़ संरचनाओं को संभालने से है। ग्राफ़ से जुड़े कार्यों में अक्सर मनमाने लंबाई वाले पथों को पार करने की आवश्यकता होती है। उदाहरण के लिए, किसी प्रबंधक की कर्मचारी आईडी को देखते हुए, इनपुट कर्मचारी, साथ ही इनपुट कर्मचारी के सभी अधीनस्थों को सभी स्तरों पर लौटाएं; यानी प्रत्यक्ष और अप्रत्यक्ष अधीनस्थ। यदि आपके पास स्तरों की संख्या पर एक ज्ञात छोटी सीमा थी जिसका आपको अनुसरण करने की आवश्यकता हो सकती है (ग्राफ की डिग्री), तो आप अधीनस्थों के प्रति स्तर में शामिल होने के साथ एक क्वेरी का उपयोग कर सकते हैं। हालाँकि, यदि ग्राफ़ की डिग्री संभावित रूप से अधिक है, तो किसी बिंदु पर कई जॉइन के साथ एक क्वेरी लिखना अव्यावहारिक हो जाता है। एक अन्य विकल्प अनिवार्य पुनरावृत्त कोड का उपयोग करना है, लेकिन ऐसे समाधान लंबे होते हैं। यह वह जगह है जहां पुनरावर्ती सीटीई वास्तव में चमकते हैं—वे आपको घोषणात्मक, संक्षिप्त और सहज समाधान का उपयोग करने में सक्षम बनाते हैं।
इससे पहले कि मैं खोज और साइकिल चलाने की क्षमताओं को कवर करूं, मैं अधिक दिलचस्प सामग्री पर पहुंचने से पहले पुनरावर्ती सीटीई की मूल बातें शुरू करूंगा।
याद रखें कि CTE के विरुद्ध क्वेरी का सिंटैक्स इस प्रकार है:
के साथAS
(
<तालिका अभिव्यक्ति>
)
<बाहरी क्वेरी>;
यहां मैं WITH क्लॉज का उपयोग करके परिभाषित एक CTE दिखाता हूं, लेकिन जैसा कि आप जानते हैं, आप कॉमा द्वारा अलग किए गए कई CTE को परिभाषित कर सकते हैं।
नियमित, गैर-पुनरावर्ती, सीटीई में, आंतरिक तालिका अभिव्यक्ति एक क्वेरी पर आधारित होती है जिसका मूल्यांकन केवल एक बार किया जाता है। पुनरावर्ती सीटीई में, आंतरिक तालिका अभिव्यक्ति आमतौर पर दो प्रश्नों पर आधारित होती है जिन्हें सदस्यों . के रूप में जाना जाता है , हालांकि कुछ विशेष जरूरतों को पूरा करने के लिए आपके पास दो से अधिक हो सकते हैं। सदस्यों को आम तौर पर यूनियन ऑल ऑपरेटर द्वारा अलग किया जाता है ताकि यह इंगित किया जा सके कि उनके परिणाम एकीकृत हैं।
एक सदस्य एंकर सदस्य . हो सकता है -जिसका अर्थ है कि इसका मूल्यांकन केवल एक बार किया जाता है; या यह एक पुनरावर्ती सदस्य . हो सकता है -इसका मतलब है कि इसका बार-बार मूल्यांकन किया जाता है, जब तक कि यह एक खाली परिणाम सेट नहीं लौटाता। एक एंकर सदस्य और एक पुनरावर्ती सदस्य पर आधारित पुनरावर्ती CTE के विरुद्ध क्वेरी का सिंटैक्स यहां दिया गया है:
AS
(
<एंकर सदस्य>
UNION ALL
<पुनरावर्ती सदस्य>
)
<बाहरी क्वेरी>;
एक सदस्य को पुनरावर्ती बनाता है जो सीटीई नाम का संदर्भ रखता है। यह संदर्भ अंतिम निष्पादन के परिणाम सेट का प्रतिनिधित्व करता है। पुनरावर्ती सदस्य के पहले निष्पादन में, CTE नाम का संदर्भ एंकर सदस्य के परिणाम सेट का प्रतिनिधित्व करता है। एनटी निष्पादन में, जहां एन> 1, सीटीई नाम का संदर्भ पुनरावर्ती सदस्य के (एन -1) निष्पादन के परिणाम सेट का प्रतिनिधित्व करता है। जैसा कि उल्लेख किया गया है, एक बार पुनरावर्ती सदस्य एक खाली सेट देता है, इसे फिर से निष्पादित नहीं किया जाता है। बाहरी क्वेरी में सीटीई नाम का संदर्भ एंकर सदस्य के एकल निष्पादन के एकीकृत परिणाम सेट और पुनरावर्ती सदस्य के सभी निष्पादन का प्रतिनिधित्व करता है।
निम्नलिखित कोड इस उदाहरण में मूल कर्मचारी के रूप में कर्मचारी आईडी 3 पास करते हुए, दिए गए इनपुट प्रबंधक के लिए कर्मचारियों के उपप्रकार को वापस करने के उपरोक्त कार्य को लागू करता है:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; एंकर क्वेरी को केवल एक बार निष्पादित किया जाता है, इनपुट रूट कर्मचारी (हमारे मामले में कर्मचारी 3) के लिए पंक्ति लौटाता है।
पुनरावर्ती क्वेरी पिछले स्तर से कर्मचारियों के समूह में शामिल हो जाती है - सीटीई नाम के संदर्भ द्वारा प्रतिनिधित्व, प्रबंधकों के लिए एम के रूप में उपनाम - कर्मचारी तालिका से उनके प्रत्यक्ष अधीनस्थों के साथ, अधीनस्थों के लिए एस के रूप में उपनाम। जॉइन विधेय S.mgrid =M.empid है, जिसका अर्थ है कि अधीनस्थ का mgrid मान प्रबंधक के empid मान के बराबर है। पुनरावर्ती क्वेरी निम्नानुसार चार बार निष्पादित होती है:
- कर्मचारी 3 के अधीनस्थों को वापस करें; आउटपुट:कर्मचारी 7
- कर्मचारी 7 के अधीनस्थ लौटें; आउटपुट:कर्मचारी 9 और 11
- कर्मचारियों 9 और 11 के अधीनस्थों की वापसी; आउटपुट:12, 13 और 14
- कर्मचारियों की वापसी अधीनस्थ 12, 13 और 14; आउटपुट:खाली सेट; रिकर्सन रुक जाता है
बाहरी क्वेरी में सीटीई नाम का संदर्भ एंकर क्वेरी (कर्मचारी 3) के एकल निष्पादन के एकीकृत परिणामों का प्रतिनिधित्व करता है, जिसमें पुनरावर्ती क्वेरी (कर्मचारी 7, 9, 11, 12, 13 और कर्मचारी) के सभी निष्पादन के परिणाम होते हैं। 14)। यह कोड निम्न आउटपुट उत्पन्न करता है:
empid mgrid empname ------ ------ -------- 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi
प्रोग्रामिंग समाधानों में एक आम समस्या है भगोड़ा कोड जैसे अनंत लूप आमतौर पर एक बग के कारण होता है। रिकर्सिव सीटीई के साथ, एक बग रिकर्सिव सदस्य के रनवे निष्पादन को जन्म दे सकता है। उदाहरण के लिए, मान लीजिए कि एक इनपुट कर्मचारी के अधीनस्थों को वापस करने के हमारे समाधान में, आपके पास पुनरावर्ती सदस्य के शामिल होने के विधेय में एक बग था। ON S.mgrid =M.empid का उपयोग करने के बजाय, आपने ON S.mgrid =S.mgrid का उपयोग किया, जैसे:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C; तालिका में मौजूद गैर-अशक्त प्रबंधक आईडी वाले कम से कम एक कर्मचारी को देखते हुए, पुनरावर्ती सदस्य का निष्पादन एक गैर-रिक्त परिणाम लौटाता रहेगा। याद रखें कि पुनरावर्ती सदस्य के लिए निहित समाप्ति की स्थिति तब होती है जब उसका निष्पादन एक खाली परिणाम सेट देता है। यदि यह एक गैर-रिक्त परिणाम सेट देता है, तो SQL सर्वर इसे फिर से निष्पादित करता है। आप महसूस करते हैं कि यदि SQL सर्वर में पुनरावर्ती निष्पादन को सीमित करने के लिए कोई तंत्र नहीं है, तो यह केवल पुनरावर्ती सदस्य को बार-बार निष्पादित करता रहेगा। एक सुरक्षा उपाय के रूप में, T-SQL एक MAXRECURSION क्वेरी विकल्प का समर्थन करता है जो पुनरावर्ती सदस्य के निष्पादन की अधिकतम अनुमत संख्या को सीमित करता है। डिफ़ॉल्ट रूप से, यह सीमा 100 पर सेट है, लेकिन आप इसे किसी भी गैर-ऋणात्मक SMALLINT मान में बदल सकते हैं, जिसमें 0 कोई सीमा नहीं दर्शाता है। अधिकतम पुनरावर्तन सीमा को सकारात्मक मान N पर सेट करने का अर्थ है कि पुनरावर्ती सदस्य के N + 1 के निष्पादन का प्रयास एक त्रुटि के साथ निरस्त कर दिया गया है। उदाहरण के लिए, उपरोक्त बग्गी कोड को इस रूप में चलाने का अर्थ है कि आप 100 की डिफ़ॉल्ट अधिकतम रिकर्सन सीमा पर भरोसा करते हैं, इसलिए पुनरावर्ती सदस्य का 101 निष्पादन विफल हो जाता है:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...संदेश 530, स्तर 16, राज्य 1, पंक्ति 121
विवरण समाप्त किया गया। स्टेटमेंट पूरा होने से पहले अधिकतम 100 रिकर्सन समाप्त हो गया है।
मान लें कि आपके संगठन में यह मान लेना सुरक्षित है कि कर्मचारी पदानुक्रम 6 प्रबंधन स्तरों से अधिक नहीं होगा। आप अधिकतम पुनरावर्तन सीमा को 100 से बहुत छोटी संख्या तक कम कर सकते हैं, जैसे 10 सुरक्षित पक्ष पर रहने के लिए, जैसे:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C
OPTION (MAXRECURSION 10); अब यदि कोई बग है जिसके परिणामस्वरूप पुनरावर्ती सदस्य का भगोड़ा निष्पादन होता है, तो यह 101 निष्पादन के बजाय पुनरावर्ती सदस्य के 11 प्रयास किए गए निष्पादन में खोजा जाएगा:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...संदेश 530, स्तर 16, राज्य 1, पंक्ति 149
विवरण समाप्त किया गया। स्टेटमेंट पूरा होने से पहले अधिकतम रिकर्सन 10 समाप्त हो गया है।
यह ध्यान रखना महत्वपूर्ण है कि अधिकतम रिकर्सन सीमा का उपयोग मुख्य रूप से बग्गी रनवे कोड के निष्पादन को रोकने के लिए सुरक्षा उपाय के रूप में किया जाना चाहिए। याद रखें कि जब सीमा पार हो जाती है, तो कोड का निष्पादन त्रुटि के साथ निरस्त कर दिया जाता है। फ़िल्टरिंग उद्देश्यों के लिए विज़िट किए जाने वाले स्तरों की संख्या को सीमित करने के लिए आपको इस विकल्प का उपयोग नहीं करना चाहिए। आप नहीं चाहते कि कोड में कोई समस्या न होने पर कोई त्रुटि उत्पन्न हो।
फ़िल्टरिंग उद्देश्यों के लिए, आप प्रोग्राम के अनुसार विज़िट करने के लिए स्तरों की संख्या को सीमित कर सकते हैं। आप lvl नामक कॉलम को परिभाषित करते हैं जो इनपुट रूट कर्मचारी की तुलना में वर्तमान कर्मचारी के स्तर की संख्या को ट्रैक करता है। एंकर क्वेरी में आप lvl कॉलम को स्थिर 0 पर सेट करते हैं। पुनरावर्ती क्वेरी में आप इसे प्रबंधक के lvl मान प्लस 1 पर सेट करते हैं। इनपुट रूट के नीचे कई स्तरों को @maxlevel के रूप में फ़िल्टर करने के लिए, विधेय M.lvl <@ जोड़ें। पुनरावर्ती क्वेरी के ON क्लॉज के लिए maxlevel। उदाहरण के लिए, निम्न कोड कर्मचारी 3 और कर्मचारी 3 के अधीनस्थों के दो स्तरों को लौटाता है:
DECLARE @root AS INT = 3, @maxlevel AS INT = 2;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.lvl < @maxlevel
)
SELECT empid, mgrid, empname, lvl
FROM C; यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
empid mgrid empname lvl ------ ------ -------- ---- 3 1 Ina 0 7 3 Aaron 1 9 7 Rita 2 11 7 Gabriel 2
मानक खोज और चक्र खंड
आईएसओ/आईईसी एसक्यूएल मानक पुनरावर्ती सीटीई के लिए दो बहुत शक्तिशाली विकल्पों को परिभाषित करता है। एक खोज नामक एक खंड है जो पुनरावर्ती खोज क्रम को नियंत्रित करता है, और दूसरा एक खंड है जिसे CYCLE कहा जाता है जो ट्रैवर्स किए गए पथों में चक्रों की पहचान करता है। यहाँ दो खंडों के लिए मानक वाक्य रचना है:
7.18 <खोज या चक्र खंडफ़ंक्शन
रिकर्सिव क्वेरी एक्सप्रेशन के परिणाम में ऑर्डरिंग और साइकिल डिटेक्शन जानकारी की पीढ़ी निर्दिष्ट करें।
प्रारूप
<सूची तत्व के साथ> ::=
<क्वेरी नाम> [ <बाएं माता-पिता> <स्तंभ सूची के साथ> <दाएं माता-पिता> ]
AS <तालिका उपश्रेणी> [ <खोज या चक्र खंड> ]
<खोज या चक्र खंड> ::=
<खोज खंड> | <चक्र खंड> | <खोज खंड> <चक्र खंड>
खोज खंड> ::=
खोज <पुनरावर्ती खोज आदेश> सेट <अनुक्रम कॉलम>
<पुनरावर्ती खोज आदेश> ::=
<कॉलम नाम सूची> द्वारा सबसे पहले गहराई | चौड़ाई पहले <कॉलम नाम सूची>
अनुक्रम कॉलम> ::=<कॉलम नाम>
<चक्र खंड> ::=
चक्र <चक्र स्तंभ सूची> सेट <चक्र चिह्न स्तंभ> के लिए <चक्र चिह्न मान>
डिफ़ॉल्ट <गैर-चक्र चिह्न मान> <पथ स्तंभ> का उपयोग करना>
<चक्र स्तंभ सूची> ::=<चक्र स्तंभ> [ { <अल्पविराम> <चक्र स्तंभ> }… ]
<चक्र स्तंभ> ::=<स्तंभ नाम>
<चक्र चिह्न स्तंभ> ::=<स्तंभ नाम>
<पथ स्तंभ> ::=<स्तंभ नाम>
<साइकिल मार्क वैल्यू> ::=<वैल्यू एक्सप्रेशन>
<नॉन-साइकिल मार्क वैल्यू> ::=<वैल्यू एक्सप्रेशन>
टी-एसक्यूएल लिखते समय इन विकल्पों का समर्थन नहीं करता है, लेकिन निम्नलिखित लिंक में आप भविष्य में टी-एसक्यूएल में शामिल करने के लिए फीचर सुधार अनुरोध पा सकते हैं, और उनके लिए वोट कर सकते हैं:
- टी-एसक्यूएल में पुनरावर्ती सीटीई के लिए आईएसओ/आईईसी एसक्यूएल खोज खंड के लिए समर्थन जोड़ें
- T-SQL में पुनरावर्ती CTE के लिए ISO/IEC SQL CYCLE क्लॉज के लिए समर्थन जोड़ें
निम्नलिखित अनुभागों में मैं दो मानक विकल्पों का वर्णन करूँगा और तार्किक रूप से समकक्ष वैकल्पिक समाधान भी प्रदान करूँगा जो वर्तमान में T-SQL में उपलब्ध हैं।
खोज खंड
मानक खोज खंड कुछ निर्दिष्ट ऑर्डरिंग कॉलम द्वारा रिकर्सिव सर्च ऑर्डर को पहले चौड़ाई या गहराई के रूप में परिभाषित करता है, और विज़िट किए गए नोड्स की क्रमिक स्थिति के साथ एक नया अनुक्रम कॉलम बनाता है। आप पहले प्रत्येक स्तर (चौड़ाई) में खोज करने के लिए पहले चौड़ाई निर्दिष्ट करते हैं और फिर स्तरों (गहराई) के नीचे। आप पहले नीचे (गहराई) और फिर पार (चौड़ाई) खोजने के लिए DEPTH FIRST निर्दिष्ट करते हैं।
आप बाहरी क्वेरी के ठीक पहले खोज खंड निर्दिष्ट करते हैं।
मैं चौड़ाई पहले पुनरावर्ती खोज क्रम के लिए एक उदाहरण के साथ शुरू करूंगा। बस याद रखें कि यह सुविधा टी-एसक्यूएल में उपलब्ध नहीं है, इसलिए आप वास्तव में उन उदाहरणों को चलाने में सक्षम नहीं होंगे जो एसक्यूएल सर्वर या एज़ूर एसक्यूएल डेटाबेस में मानक क्लॉज का उपयोग करते हैं। निम्नलिखित कोड कर्मचारी 1 का उपप्रकार लौटाता है, एम्पिड द्वारा चौड़ाई पहले खोज आदेश के लिए पूछता है, एक अनुक्रम स्तंभ बनाता है जिसे seqbreadth कहा जाता है जिसमें विज़िट किए गए नोड्स की क्रमिक स्थिति होती है:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH BREADTH FIRST BY empid SET seqbreadth
--------------------------------------------
SELECT empid, mgrid, empname, seqbreadth
FROM C
ORDER BY seqbreadth; यहां इस कोड का वांछित आउटपुट दिया गया है:
empid mgrid empname seqbreadth ------ ------ -------- ----------- 1 NULL David 1 2 1 Eitan 2 3 1 Ina 3 4 2 Seraph 4 5 2 Jiru 5 6 2 Steve 6 7 3 Aaron 7 8 5 Lilach 8 9 7 Rita 9 10 5 Sean 10 11 7 Gabriel 11 12 9 Emilia 12 13 9 Michael 13 14 9 Didi 14
इस तथ्य से भ्रमित न हों कि seqbreadth मान empid मानों के समान प्रतीत होते हैं। यह केवल संयोग से है क्योंकि मैंने अपने द्वारा बनाए गए नमूना डेटा में एम्पीड मानों को मैन्युअल रूप से असाइन किया है।
चित्र 2 में कर्मचारी पदानुक्रम का एक चित्रमय चित्रण है, जिसमें एक बिंदीदार रेखा चौड़ाई के पहले क्रम को दिखाती है जिसमें नोड्स की खोज की गई थी। एम्पिड मान कर्मचारी के नाम के ठीक नीचे दिखाई देते हैं, और असाइन किए गए seqbreadth मान प्रत्येक बॉक्स के निचले बाएँ कोने में दिखाई देते हैं।
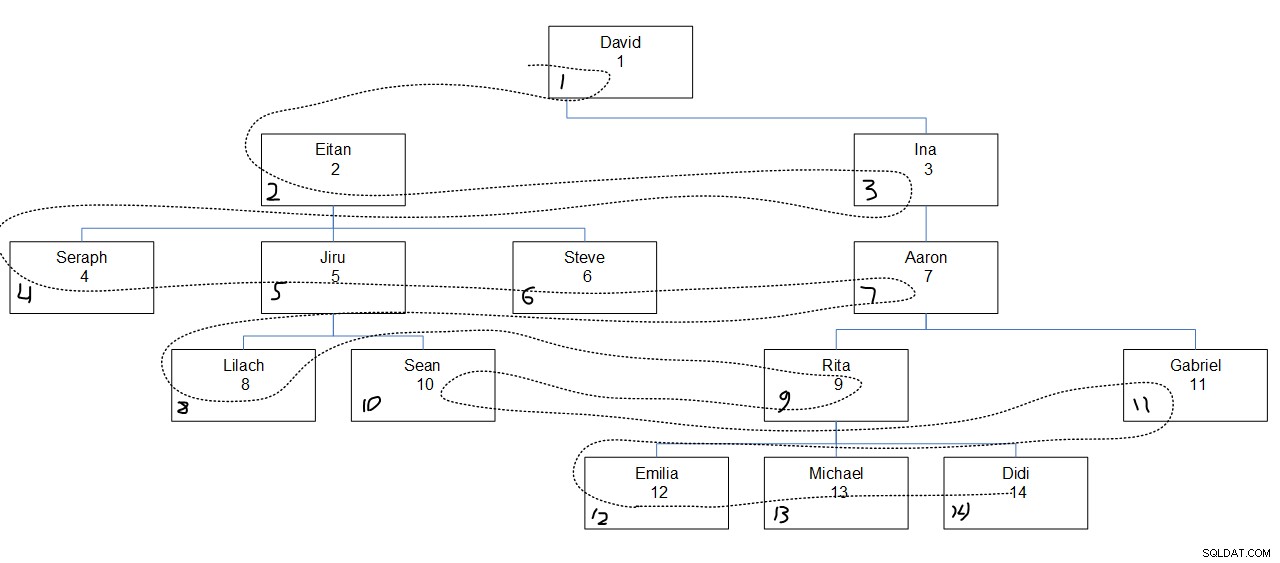 चित्र 2:पहले चौड़ाई खोजें
चित्र 2:पहले चौड़ाई खोजें
यहां ध्यान देने योग्य बात यह है कि प्रत्येक स्तर के भीतर, नोड के मूल संघ के बावजूद, निर्दिष्ट कॉलम ऑर्डर (हमारे मामले में एम्पीड) के आधार पर नोड्स की खोज की जाती है। उदाहरण के लिए, ध्यान दें कि चौथे स्तर में लिलाच पहले, रीटा दूसरे, शॉन तीसरे और गेब्रियल तक पहुंच गया है। ऐसा इसलिए है क्योंकि चौथे स्तर के सभी कर्मचारियों के बीच, उनका क्रम उनके समान मूल्यों पर आधारित है। ऐसा नहीं है कि लिलाच और सीन को लगातार खोजा जाना चाहिए क्योंकि वे एक ही प्रबंधक, जिरू के सीधे अधीनस्थ हैं।
टी-एसक्यूएल समाधान के साथ आना काफी सरल है जो मानक SAERCH DEPTH FIRST विकल्प के तार्किक समकक्ष प्रदान करता है। आप lvl नामक एक कॉलम बनाते हैं, जैसा कि मैंने रूट के संबंध में नोड के स्तर को ट्रैक करने के लिए पहले दिखाया था (पहले स्तर के लिए 0, दूसरे के लिए 1, और इसी तरह)। फिर आप ROW_NUMBER फ़ंक्शन का उपयोग करके बाहरी क्वेरी में वांछित परिणाम अनुक्रम कॉलम की गणना करते हैं। विंडो ऑर्डरिंग के रूप में आप पहले lvl निर्दिष्ट करते हैं, और फिर वांछित ऑर्डरिंग कॉलम (हमारे मामले में empid)। यहाँ संपूर्ण समाधान का कोड है:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadth
FROM C
ORDER BY seqbreadth; इसके बाद, आइए DEPTH FIRST सर्च ऑर्डर की जांच करें। मानक के अनुसार, निम्नलिखित कोड को कर्मचारी 1 के उपप्रकार को वापस करना चाहिए, एम्पिड द्वारा गहराई से पहले खोज आदेश के लिए पूछना, खोजे गए नोड्स की क्रमिक स्थिति के साथ सेक्डेप नामक अनुक्रम कॉलम बनाना:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH DEPTH FIRST BY empid SET seqdepth
----------------------------------------
SELECT empid, mgrid, empname, seqdepth
FROM C
ORDER BY seqdepth; इस कोड का वांछित आउटपुट निम्नलिखित है:
empid mgrid empname seqdepth ------ ------ -------- --------- 1 NULL David 1 2 1 Eitan 2 4 2 Seraph 3 5 2 Jiru 4 8 5 Lilach 5 10 5 Sean 6 6 2 Steve 7 3 1 Ina 8 7 3 Aaron 9 9 7 Rita 10 12 9 Emilia 11 13 9 Michael 12 14 9 Didi 13 11 7 Gabriel 14
वांछित क्वेरी आउटपुट को देखते हुए शायद यह पता लगाना मुश्किल है कि अनुक्रम मानों को जिस तरह से असाइन किया गया था, उन्हें क्यों असाइन किया गया था। चित्रा 3 मदद करनी चाहिए। इसमें कर्मचारी पदानुक्रम का एक ग्राफिकल चित्रण है, जिसमें प्रत्येक बॉक्स के निचले बाएं कोने में निर्दिष्ट अनुक्रम मानों के साथ, एक बिंदीदार रेखा गहराई पहले खोज क्रम को दर्शाती है।
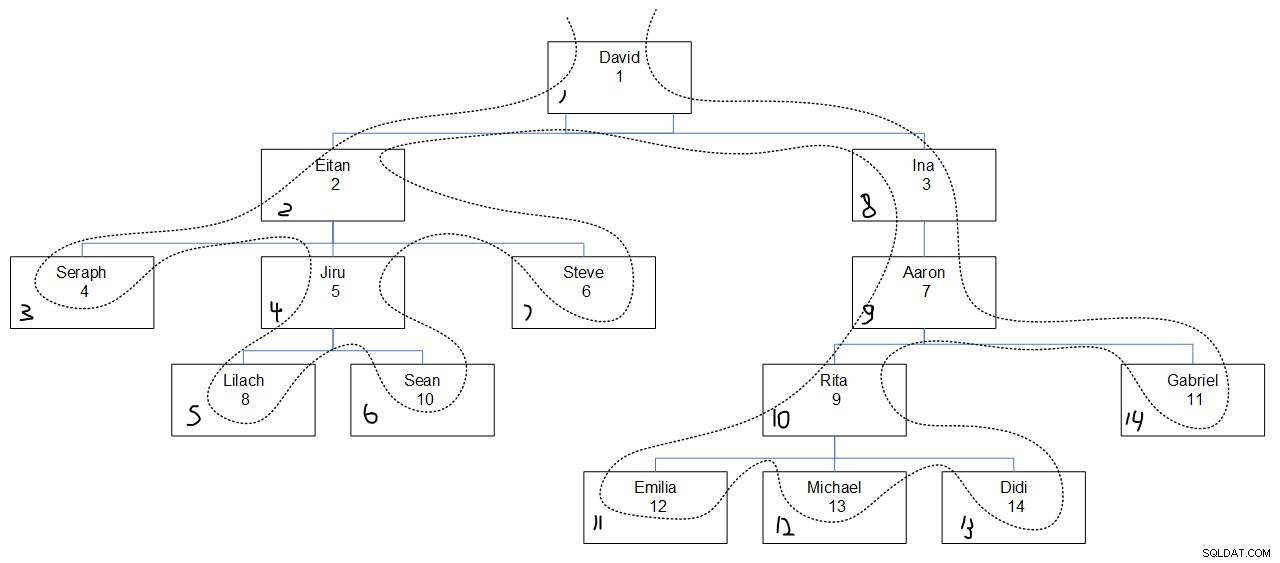 चित्र 3:पहले गहराई खोजें
चित्र 3:पहले गहराई खोजें
एक टी-एसक्यूएल समाधान के साथ आना जो मानक खोज गहराई पहले विकल्प के तार्किक समकक्ष प्रदान करता है, थोड़ा मुश्किल है, फिर भी करने योग्य है। मैं दो चरणों में समाधान का वर्णन करूंगा।
चरण 1 में, प्रत्येक नोड के लिए आप एक बाइनरी सॉर्ट पथ की गणना करते हैं जो नोड के प्रति पूर्वज एक सेगमेंट से बना होता है, जिसमें प्रत्येक सेगमेंट अपने भाई-बहनों के बीच पूर्वजों की सॉर्ट स्थिति को दर्शाता है। आप इस पथ का निर्माण उसी तरह करते हैं जैसे आप lvl कॉलम की गणना करते हैं। यही है, एंकर क्वेरी में रूट नोड के लिए एक खाली बाइनरी स्ट्रिंग से शुरू करें। फिर, पुनरावर्ती क्वेरी में आप माता-पिता के पथ को भाई-बहनों के बीच नोड की सॉर्ट स्थिति के साथ जोड़ते हैं, जब आप इसे बाइनरी सेगमेंट में परिवर्तित करते हैं। आप स्थिति की गणना करने के लिए ROW_NUMBER फ़ंक्शन का उपयोग करते हैं, माता-पिता द्वारा विभाजित (हमारे मामले में एमजीग्रिड) और प्रासंगिक ऑर्डरिंग कॉलम (हमारे मामले में एम्पीड) द्वारा आदेशित किया जाता है। आप अपने ग्राफ़ में माता-पिता के प्रत्यक्ष बच्चों की अधिकतम संख्या के आधार पर पंक्ति संख्या को पर्याप्त आकार के बाइनरी मान में परिवर्तित कर सकते हैं। BINARY(1) प्रति माता-पिता 255 बच्चों का समर्थन करता है, BINARY(2) 65,535, BINARY(3):16,777,215, BINARY(4):4,294,967,295 का समर्थन करता है। एक पुनरावर्ती CTE में, एंकर और पुनरावर्ती प्रश्नों में संबंधित कॉलम और आकार के समान होने चाहिए , इसलिए सॉर्ट पथ को दोनों में समान आकार के बाइनरी मान में बदलना सुनिश्चित करें।
हमारे समाधान में चरण 1 को लागू करने वाला कोड यहां दिया गया है (यह मानते हुए कि BINARY(1) प्रति सेगमेंट पर्याप्त है, जिसका अर्थ है कि आपके पास प्रति प्रबंधक 255 से अधिक प्रत्यक्ष अधीनस्थ नहीं हैं):
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, sortpath
FROM C; यह कोड निम्न आउटपुट उत्पन्न करता है:
empid mgrid empname sortpath ------ ------ -------- ----------- 1 NULL David 0x 2 1 Eitan 0x01 3 1 Ina 0x02 7 3 Aaron 0x0201 9 7 Rita 0x020101 11 7 Gabriel 0x020102 12 9 Emilia 0x02010101 13 9 Michael 0x02010102 14 9 Didi 0x02010103 4 2 Seraph 0x0101 5 2 Jiru 0x0102 6 2 Steve 0x0103 8 5 Lilach 0x010201 10 5 Sean 0x010202
ध्यान दें कि मैंने एक खाली बाइनरी स्ट्रिंग का उपयोग एकल उपट्री के रूट नोड के लिए सॉर्ट पथ के रूप में किया था जिसे हम यहां क्वेरी कर रहे हैं। यदि एंकर सदस्य संभावित रूप से कई सबट्री रूट वापस कर सकता है, तो बस एक सेगमेंट से शुरू करें जो एंकर क्वेरी में ROW_NUMBER गणना पर आधारित है, जिस तरह से आप इसे रिकर्सिव क्वेरी में गणना करते हैं। ऐसी स्थिति में, आपका क्रमबद्ध पथ एक खंड लंबा होगा।
चरण 2 में क्या करना बाकी है, बाहरी क्वेरी में सॉर्टपाथ द्वारा क्रमबद्ध पंक्ति संख्याओं की गणना करके वांछित परिणाम सेकडेप्थ कॉलम बनाना है, जैसे
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth
FROM C
ORDER BY seqdepth; यह समाधान अपने वांछित आउटपुट के साथ पहले दिखाए गए मानक खोज गहराई पहले विकल्प का उपयोग करने के तार्किक समकक्ष है।
एक बार जब आपके पास एक अनुक्रम स्तंभ होता है जो गहराई से पहले खोज क्रम को दर्शाता है (हमारे मामले में seqdepth), बस थोड़े से अधिक प्रयास से आप पदानुक्रम का एक बहुत अच्छा दृश्य चित्रण उत्पन्न कर सकते हैं। आपको उपरोक्त lvl कॉलम की भी आवश्यकता होगी। आप बाहरी क्वेरी को अनुक्रम स्तंभ द्वारा क्रमित करते हैं। आप कुछ विशेषता लौटाते हैं जिसका उपयोग आप नोड का प्रतिनिधित्व करने के लिए करना चाहते हैं (जैसे, हमारे मामले में empname), कुछ स्ट्रिंग (कहें '|') से पहले lvl बार दोहराया गया। इस तरह के दृश्य चित्रण को प्राप्त करने के लिए यहां पूरा कोड दिया गया है:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, empname, 0 AS lvl,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.empname, M.lvl + 1 AS lvl,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth,
REPLICATE(' | ', lvl) + empname AS emp
FROM C
ORDER BY seqdepth; यह कोड निम्न आउटपुट उत्पन्न करता है:
empid seqdepth emp ------ --------- -------------------- 1 1 David 2 2 | Eitan 4 3 | | Seraph 5 4 | | Jiru 8 5 | | | Lilach 10 6 | | | Sean 6 7 | | Steve 3 8 | Ina 7 9 | | Aaron 9 10 | | | Rita 12 11 | | | | Emilia 13 12 | | | | Michael 14 13 | | | | Didi 11 14 | | | Gabriel
यह बहुत अच्छा है!
चक्र खंड
ग्राफ संरचनाओं में चक्र हो सकते हैं। वे चक्र वैध या अमान्य हो सकते हैं। वैध चक्रों के लिए एक उदाहरण एक ग्राफ है जो शहरों और कस्बों को जोड़ने वाले राजमार्गों और सड़कों का प्रतिनिधित्व करता है। इसे चक्रीय ग्राफ़ . कहा जाता है . इसके विपरीत, एक कर्मचारी पदानुक्रम का प्रतिनिधित्व करने वाले ग्राफ जैसे कि हमारे मामले में चक्र नहीं होना चाहिए। इसे एसाइक्लिक . कहा जाता है ग्राफ। हालाँकि, मान लीजिए कि कुछ गलत अपडेट के कारण, आप अनजाने में एक चक्र के साथ समाप्त हो जाते हैं। उदाहरण के लिए, मान लें कि गलती से आप सीईओ (कर्मचारी 1) की प्रबंधक आईडी को कर्मचारी 14 में निम्नलिखित कोड चलाकर अपडेट कर देते हैं:
UPDATE Employees SET mgrid = 14 WHERE empid = 1;
अब आपके पास कर्मचारी पदानुक्रम में एक अमान्य चक्र है।
चाहे चक्र वैध हों या अमान्य, जब आप ग्राफ़ संरचना को पार करते हैं, तो आप निश्चित रूप से बार-बार चक्रीय पथ का अनुसरण नहीं करना चाहते हैं। दोनों ही मामलों में आप एक ही नोड की गैर-प्रथम घटना मिलने के बाद पथ का पीछा करना बंद करना चाहते हैं, और इस तरह के पथ को चक्रीय के रूप में चिह्नित करें।
तो क्या होता है जब आप एक ऐसे ग्राफ को क्वेरी करते हैं जिसमें रिकर्सिव क्वेरी का उपयोग करते हुए चक्र होते हैं, जिनका पता लगाने के लिए कोई तंत्र नहीं होता है? यह कार्यान्वयन पर निर्भर करता है। SQL सर्वर में, किसी बिंदु पर आप अधिकतम रिकर्सन सीमा पर पहुंच जाएंगे, और आपकी क्वेरी निरस्त कर दी जाएगी। उदाहरण के लिए, यह मानते हुए कि आपने उपरोक्त अद्यतन को चलाया है जिसने चक्र का परिचय दिया है, कर्मचारी 1 के उपप्रकार की पहचान करने के लिए निम्नलिखित पुनरावर्ती क्वेरी को चलाने का प्रयास करें:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; चूंकि यह कोड एक स्पष्ट अधिकतम रिकर्सन सीमा निर्धारित नहीं करता है, इसलिए 100 की डिफ़ॉल्ट सीमा मान ली जाती है। SQL सर्वर पूरा होने से पहले इस कोड के निष्पादन को रोकता है और एक त्रुटि उत्पन्न करता है:
empid mgrid empname ------ ------ -------- 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron ...संदेश 530, स्तर 16, राज्य 1, पंक्ति 432
विवरण समाप्त किया गया। स्टेटमेंट पूरा होने से पहले अधिकतम 100 रिकर्सन समाप्त हो गया है।
SQL मानक पुनरावर्ती CTE के लिए CYCLE नामक एक खंड को परिभाषित करता है, जिससे आप अपने ग्राफ़ में चक्रों से निपटने में सक्षम होते हैं। आप इस क्लॉज को बाहरी क्वेरी के ठीक पहले निर्दिष्ट करते हैं। यदि कोई खोज खंड भी मौजूद है, तो आप इसे पहले निर्दिष्ट करते हैं और फिर चक्र खंड। यहां CYCLE क्लॉज का सिंटैक्स दिया गया है:
साइकिल <चक्र स्तंभ सूची><चक्र चिह्न स्तंभ> सेट करें <चक्र चिह्न मान> डिफ़ॉल्ट <गैर-चक्र चिह्न मान>
<पथ स्तंभ> का उपयोग करना
एक चक्र का पता लगाना निर्दिष्ट चक्र स्तंभ सूची . पर आधारित है . उदाहरण के लिए, हमारे कर्मचारी पदानुक्रम में, आप शायद इस उद्देश्य के लिए एम्पीड कॉलम का उपयोग करना चाहेंगे। जब वही एम्पीड मान दूसरी बार प्रकट होता है, तो एक चक्र का पता लगाया जाता है, और क्वेरी आगे ऐसे पथ का अनुसरण नहीं करती है। आप एक नया चक्र चिह्न स्तंभ निर्दिष्ट करें यह इंगित करेगा कि कोई चक्र मिला या नहीं, और चक्र चिह्न . के रूप में आपके स्वयं के मान और गैर-चक्र चिह्न मूल्य। उदाहरण के लिए, वे 1 और 0 या 'हां' और 'नहीं', या आपके द्वारा चुने गए कोई अन्य मान हो सकते हैं। उपयोग खंड में आप एक नया सरणी स्तंभ नाम निर्दिष्ट करते हैं जो अब तक पाए गए नोड्स का पथ धारण करेगा।
यहां बताया गया है कि आप कुछ इनपुट रूट कर्मचारी के अधीनस्थों के लिए एक अनुरोध को कैसे संभालेंगे, एम्पीड कॉलम के आधार पर चक्रों का पता लगाने की क्षमता के साथ, एक चक्र का पता चलने पर चक्र चिह्न कॉलम में 1 इंगित करता है, और 0 अन्यथा:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
CYCLE empid SET cycle TO 1 DEFAULT 0
------------------------------------
SELECT empid, mgrid, empname
FROM C; यहां इस कोड का वांछित आउटपुट दिया गया है:
empid mgrid empname cycle ------ ------ -------- ------ 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
T-SQL वर्तमान में CYCLE क्लॉज का समर्थन नहीं करता है, लेकिन एक वर्कअराउंड है जो एक तार्किक समकक्ष प्रदान करता है। इसमें तीन चरण शामिल हैं। याद रखें कि पहले आपने रिकर्सिव सर्च ऑर्डर को संभालने के लिए बाइनरी सॉर्ट पथ बनाया था। इसी तरह, समाधान में पहले चरण के रूप में, आप एक वर्ण स्ट्रिंग-आधारित पूर्वजों पथ का निर्माण करते हैं जो वर्तमान नोड सहित वर्तमान नोड तक जाने वाले पूर्वजों के नोड आईडी (हमारे मामले में कर्मचारी आईडी) से बना है। आप शुरुआत में एक और अंत में एक सहित, नोड आईडी के बीच विभाजक चाहते हैं।
ऐसे पूर्वजों का पथ बनाने के लिए कोड यहां दिया गया है:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath
FROM C; यह कोड निम्न आउटपुट उत्पन्न करता है, फिर भी चक्रीय पथों का अनुसरण करता है, और इसलिए अधिकतम रिकर्सन सीमा पार हो जाने पर पूरा होने से पहले निरस्त कर दिया जाता है:
empid mgrid empname ancpath ------ ------ -------- ------------------- 1 14 David .1. 2 1 Eitan .1.2. 3 1 Ina .1.3. 7 3 Aaron .1.3.7. 9 7 Rita .1.3.7.9. 11 7 Gabriel .1.3.7.11. 12 9 Emilia .1.3.7.9.12. 13 9 Michael .1.3.7.9.13. 14 9 Didi .1.3.7.9.14. 1 14 David .1.3.7.9.14.1. 2 1 Eitan .1.3.7.9.14.1.2. 3 1 Ina .1.3.7.9.14.1.3. 7 3 Aaron .1.3.7.9.14.1.3.7. ...संदेश 530, स्तर 16, राज्य 1, पंक्ति 492
विवरण समाप्त किया गया। The maximum recursion 100 has been exhausted before statement completion.
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' .
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath, cycle
FROM C; This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle ------ ------ -------- ------------------- ------ 1 14 David .1. 0 2 1 Eitan .1.2. 0 3 1 Ina .1.3. 0 7 3 Aaron .1.3.7. 0 9 7 Rita .1.3.7.9. 0 11 7 Gabriel .1.3.7.11. 0 12 9 Emilia .1.3.7.9.12. 0 13 9 Michael .1.3.7.9.13. 0 14 9 Didi .1.3.7.9.14. 0 1 14 David .1.3.7.9.14.1. 1 2 1 Eitan .1.3.7.9.14.1.2. 0 3 1 Ina .1.3.7.9.14.1.3. 1 7 3 Aaron .1.3.7.9.14.1.3.7. 1 ...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.cycle = 0
)
SELECT empid, mgrid, empname, cycle
FROM C; This code runs to completion, and generates the following output:
empid mgrid empname cycle ------ ------ -------- ----------- 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid = NULL WHERE empid = 1;
Run the recursive query and you will find that there are no cycles present.
निष्कर्ष
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.



