MySQL को स्थापित करना और उपयोग करना आसान है, यह हमेशा डेवलपर्स और सिस्टम एडमिनिस्ट्रेटर के साथ लोकप्रिय रहा है। दूसरी ओर, व्यवसाय-महत्वपूर्ण उद्यम कार्यभार के लिए उत्पादन-तैयार MySQL वातावरण को तैनात करना एक अलग कहानी है। यह थोड़ा चुनौती भरा हो सकता है, और इसके लिए डेटाबेस के गहन ज्ञान की आवश्यकता होती है। इस ब्लॉग पोस्ट में, हम अपने MySQL परिनियोजन उत्पादन-तैयार पर विचार करने से पहले उठाए जाने वाले कुछ कदमों पर चर्चा करेंगे।
उच्च उपलब्धता

यदि आप उन भाग्यशाली लोगों में से हैं जो घंटों के डाउनटाइम को स्वीकार कर सकते हैं, तो आप यहां पढ़ना बंद कर सकते हैं और अगले पैराग्राफ पर जा सकते हैं। 99.999% व्यापार-महत्वपूर्ण प्रणालियों के लिए, यह स्वीकार्य नहीं होगा। इसलिए उत्पादन-तैयार परिनियोजन में उच्च उपलब्धता उपायों को शामिल करना होगा। डेटाबेस इंस्टेंस की स्वचालित विफलता, साथ ही एक प्रॉक्सी परत जो टोपोलॉजी और MySQL की स्थिति में परिवर्तन का पता लगाती है और तदनुसार ट्रैफ़िक को रूट करती है, एक मुख्य आवश्यकता होगी। ऐसे कई उपकरण हैं जिनका उपयोग ऐसे वातावरण के निर्माण के लिए किया जा सकता है, उदाहरण के लिए MHA, MRM या ClusterControl।
प्रॉक्सी परत
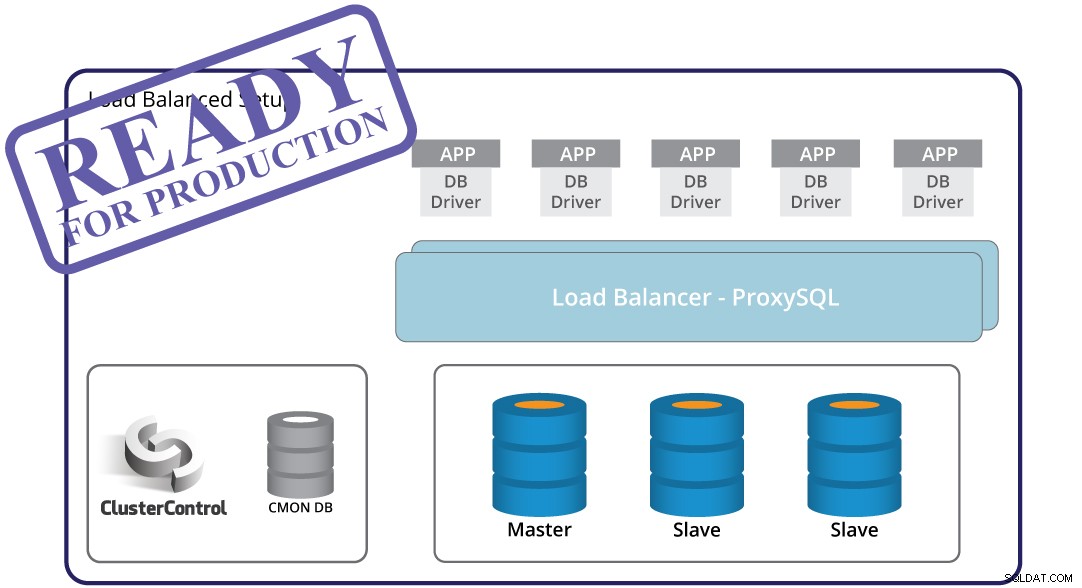
उत्पादन के लिए तैयार बुनियादी ढांचे का निर्माण करते समय मास्टर विफलता का पता लगाना, स्वचालित विफलता और पुनर्प्राप्ति - ये महत्वपूर्ण हैं। लेकिन अपने आप में, यह पर्याप्त नहीं है। अभी भी एक एप्लिकेशन है जिसे फेलओवर द्वारा ट्रिगर किए गए टोपोलॉजी परिवर्तन के अनुकूल होना होगा। बेशक, एप्लिकेशन को कोड करना संभव है, इसलिए यह इंस्टेंस विफलताओं से अवगत है। हालांकि यह टोपोलॉजी परिवर्तनों को संभालने का एक बोझिल और अनम्य तरीका है। यहां डेटाबेस प्रॉक्सी आता है - एप्लिकेशन और डेटाबेस के बीच एक मध्य परत। एक प्रॉक्सी एप्लिकेशन से आपके डेटाबेस लेयर की जटिलता को छुपा सकता है - सभी एप्लिकेशन प्रॉक्सी से कनेक्ट करने के लिए करते हैं और प्रॉक्सी बाकी का ख्याल रखेगा। प्रॉक्सी क्वेरी को डेटाबेस इंस्टेंस पर रूट करेगा, यह टोपोलॉजी परिवर्तनों को संभालेगा और आवश्यकतानुसार फिर से रूट करेगा। एक प्रॉक्सी का उपयोग रीड-राइट स्प्लिट को लागू करने के लिए भी किया जा सकता है, आवेदन को एक और जटिल मामले से कवर करने के लिए राहत देता है। यह एक और चुनौती पैदा करता है - किस प्रॉक्सी का उपयोग करना है? इसे कैसे कॉन्फ़िगर करें? इसकी निगरानी कैसे करें? इसे अत्यधिक उपलब्ध कैसे किया जाए, ताकि यह SPOF न बने?
ClusterControl यहाँ सहायता कर सकता है। इसका उपयोग प्रॉक्सी परत बनाने के लिए विभिन्न प्रॉक्सी को तैनात करने के लिए किया जा सकता है:ProxySQL, HAProxy और MaxScale। यह सुनिश्चित करने के लिए प्रॉक्सी को पूर्व-कॉन्फ़िगर करता है कि वे ट्रैफ़िक को सही तरीके से संभालेंगे। यदि आपको अपने एप्लिकेशन के लिए प्रॉक्सी सेटअप को अनुकूलित करने की आवश्यकता है तो यह किसी भी कॉन्फ़िगरेशन परिवर्तन को लागू करना आसान बनाता है। रीड-राइट स्प्लिट को किसी भी प्रॉक्सी क्लस्टरकंट्रोल सपोर्ट का उपयोग करके कॉन्फ़िगर किया जा सकता है। ClusterControl भी प्रॉक्सी पर नज़र रखता है, और विफलता के मामले में उन्हें पुनर्प्राप्त करेगा। प्रॉक्सी परत विफलता का एकल बिंदु बन सकती है, क्योंकि स्वचालित पुनर्प्राप्ति पर्याप्त नहीं हो सकती है - इसे संबोधित करने के लिए, ClusterControl Keepalived को परिनियोजित कर सकता है और विफलता को स्वचालित करने के लिए वर्चुअल IP को कॉन्फ़िगर कर सकता है।
बैकअप
यहां तक कि अगर आपको उच्च उपलब्धता को लागू करने की आवश्यकता नहीं है, तो भी आपको शायद अपने डेटा की परवाह करनी होगी। बैकअप लगभग हर उत्पादन डेटाबेस के लिए जरूरी है। बैकअप के अलावा और कुछ नहीं आपको एक आकस्मिक ड्रॉप टेबल या ड्रॉप स्कीमा से बचा सकता है (ठीक है, शायद एक विलंबित प्रतिकृति दास, लेकिन केवल कुछ समय के लिए)। MySQL बैकअप लेने के कई तरीके प्रदान करता है - mysqldump, xtrabackup, विभिन्न प्रकार के स्नैपशॉट (कुछ केवल विशेष हार्डवेयर या क्लाउड प्रदाता के साथ उपलब्ध हैं)। सही बैकअप रणनीति तैयार करना आसान नहीं है, यह तय करना कि कौन से टूल का उपयोग करना है और फिर पूरी प्रक्रिया को स्क्रिप्ट करें ताकि यह सही ढंग से निष्पादित हो सके। यह रॉकेट साइंस भी नहीं है, और इसके लिए सावधानीपूर्वक योजना और परीक्षण की आवश्यकता है। एक बार बैकअप लेने के बाद, आप समाप्त नहीं होते हैं। क्या आप सुनिश्चित हैं कि बैकअप बहाल किया जा सकता है, और डेटा कचरा नहीं है? अपने बैकअप को सत्यापित करने में समय लगता है, और शायद आपकी टूडू सूची में सबसे रोमांचक चीज नहीं होगी। लेकिन यह अभी भी महत्वपूर्ण है, और इसे नियमित रूप से करने की आवश्यकता है।
ClusterControl में व्यापक बैकअप है और कार्यक्षमता को पुनर्स्थापित करता है। यह तार्किक बैकअप के लिए mysqldump और भौतिक बैकअप के लिए Percona Xtrabackup का समर्थन करता है - उन उपकरणों का उपयोग लगभग हर वातावरण में किया जा सकता है, या तो क्लाउड या ऑन-प्रिमाइसेस। ऑनलाइन फ़ैशन में तार्किक और भौतिक बैकअप, वृद्धिशील या पूर्ण के मिश्रण के साथ बैकअप रणनीति बनाना संभव है।
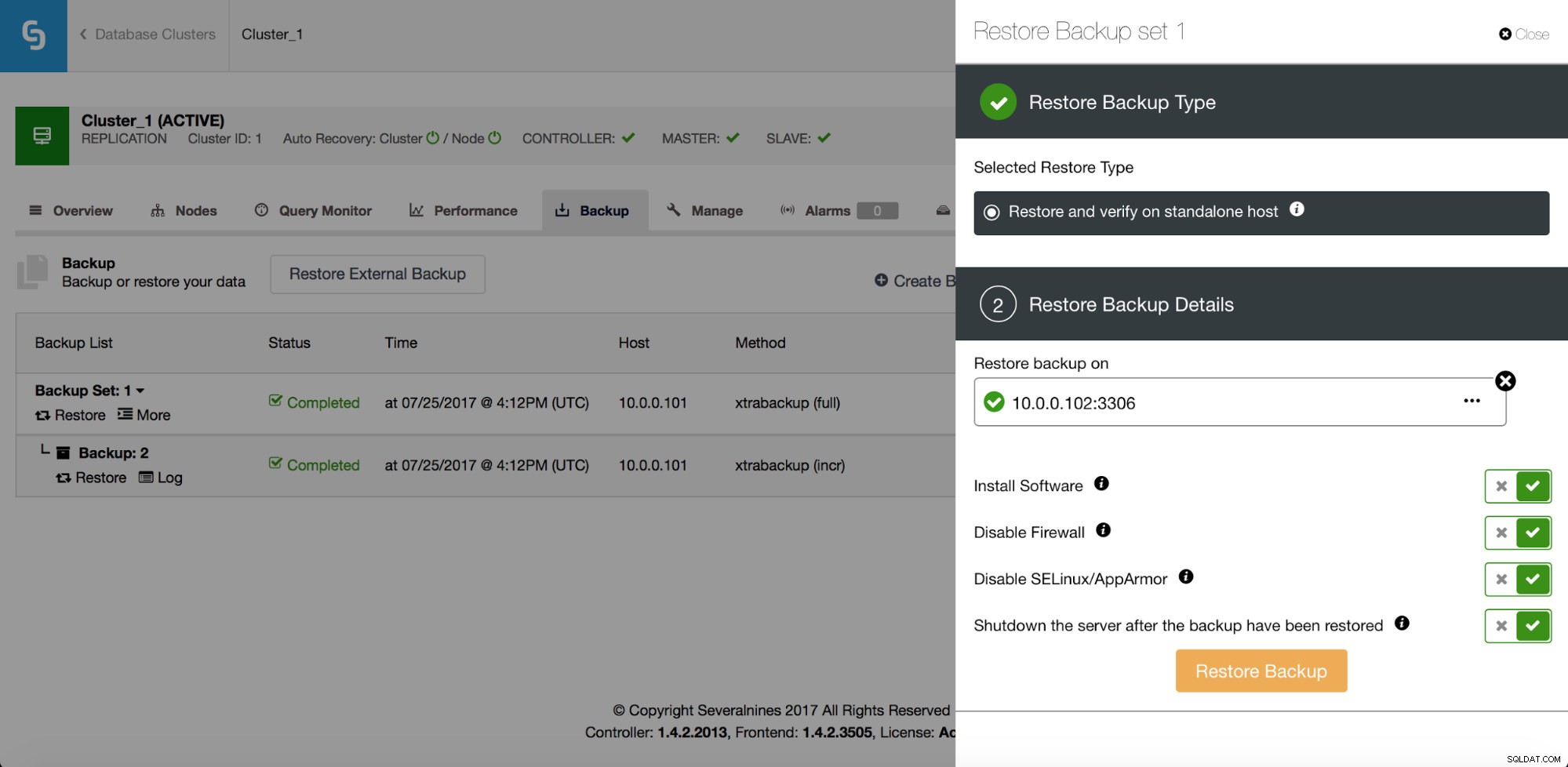
पुनर्प्राप्ति के अलावा, इसमें बैकअप सत्यापित करने के विकल्प भी हैं - उदाहरण के लिए इसे एक अलग होस्ट पर पुनर्स्थापित करें ताकि यह सत्यापित किया जा सके कि बैकअप प्रक्रिया ठीक है या नहीं।
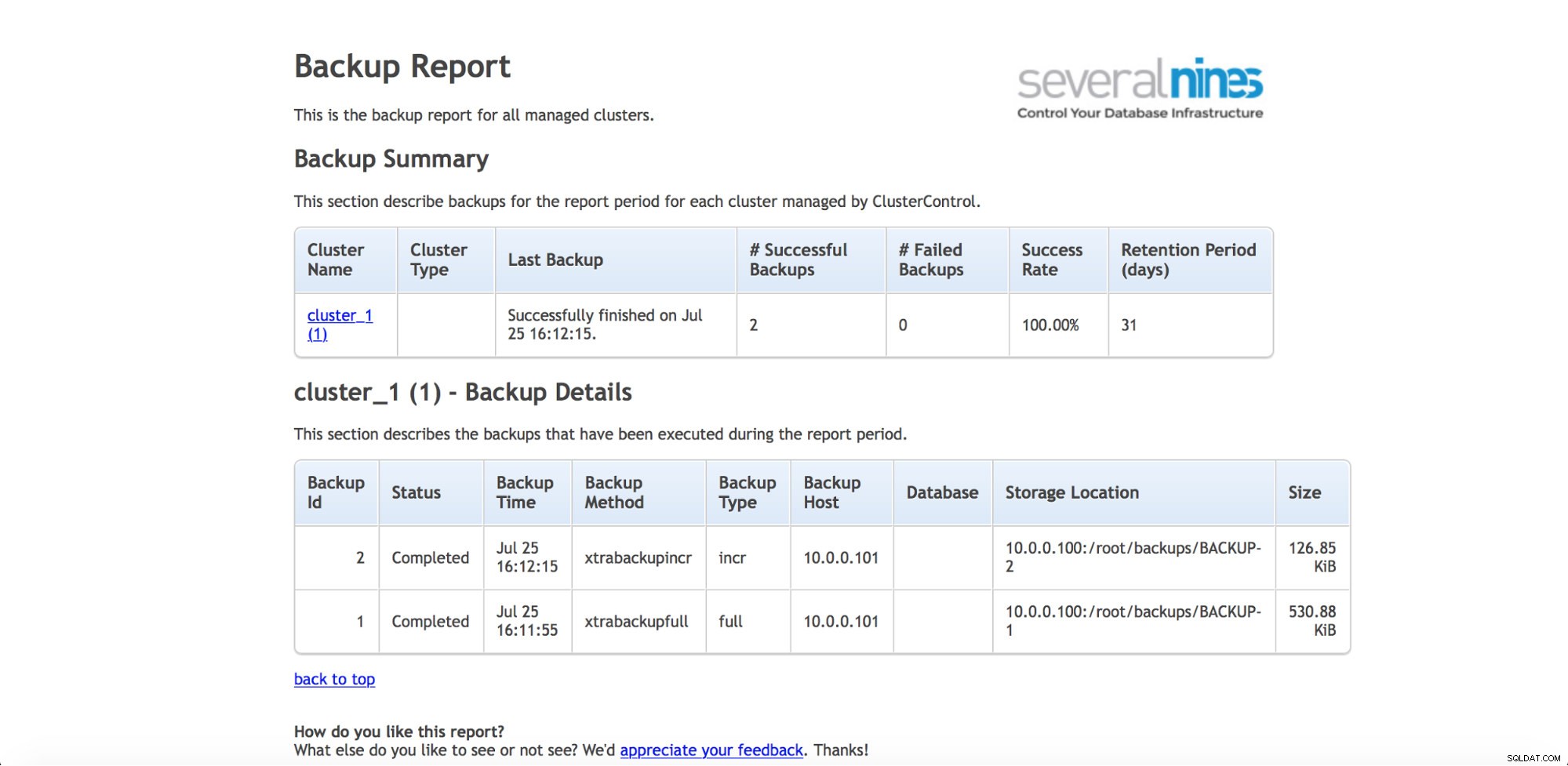
यदि आप नियमित रूप से बैकअप पर नज़र रखना चाहते हैं (और आप शायद ऐसा करना चाहते हैं), तो ClusterControl में परिचालन रिपोर्ट उत्पन्न करने की क्षमता है। बैकअप रिपोर्ट आपको निष्पादित बैकअप को ट्रैक करने में मदद करती है, और सूचित करती है कि क्या उन्हें लेते समय कोई समस्या थी।
डेटाबेस प्रबंधन के लिए डिवाइप्स मार्गदर्शिका जानें कि आपको अपने ओपन सोर्स डेटाबेस को स्वचालित और प्रबंधित करने के लिए क्या जानना आवश्यक है मुफ्त में डाउनलोड करेंनिगरानी और रुझान

सेवाओं की उचित निगरानी के बिना कोई भी परिनियोजन उत्पादन के लिए तैयार नहीं है। आप यह सुनिश्चित करना चाहते हैं कि अगर कुछ सेवाएं अनुपलब्ध हो जाती हैं तो आपको सतर्क किया जाएगा ताकि आप कार्रवाई कर सकें, जांच कर सकें या पुनर्प्राप्ति प्रक्रिया शुरू कर सकें। बेशक, आप भी ट्रेंडिंग सॉल्यूशन रखना चाहते हैं। इस बात पर पर्याप्त जोर नहीं दिया जा सकता है कि बुनियादी ढांचे की स्थिति का आकलन करने के लिए या किसी भी जांच के लिए, या तो पोस्टमार्टम या सेवाओं की स्थिति की वास्तविक समय की निगरानी के लिए निगरानी डेटा होना कितना महत्वपूर्ण है। मेट्रिक्स महत्व में समान नहीं हैं - यदि आप किसी विशेष डेटाबेस उत्पाद से बहुत परिचित नहीं हैं, तो संभवतः आपको यह नहीं पता होगा कि एकत्र करने और देखने के लिए सबसे महत्वपूर्ण मीट्रिक कौन से हैं। निश्चित रूप से, आप सब कुछ एकत्र करने में सक्षम हो सकते हैं, लेकिन जब डेटा की समीक्षा करने की बात आती है, तो प्रति होस्ट सैकड़ों मीट्रिक के माध्यम से जाना शायद ही संभव हो - आपको यह जानना होगा कि आपको उनमें से किस पर ध्यान देना चाहिए।
ओपन सोर्स वर्ल्ड विभिन्न डेटाबेस से मेट्रिक्स की निगरानी और संग्रह करने के लिए डिज़ाइन किए गए टूल से भरा है - उनमें से अधिकांश के लिए आपको उन्हें अपने समग्र मॉनिटरिंग इंफ्रास्ट्रक्चर, चैटटॉप प्लेटफॉर्म या ऑनकॉल सपोर्ट टूल्स (जैसे पेजरड्यूटी) के साथ एकीकृत करने की आवश्यकता होगी। कई घटकों को स्थापित और एकीकृत करने की भी आवश्यकता हो सकती है - भंडारण (किसी प्रकार का समय-श्रृंखला डेटाबेस), प्रस्तुति परत और डेटा संग्रह उपकरण।
ClusterControl थोड़ा अलग दृष्टिकोण है, क्योंकि यह वास्तविक समय की निगरानी, ट्रेंडिंग और डैशबोर्ड के साथ एक एकल उत्पाद है जो सबसे महत्वपूर्ण विवरण दिखाता है। डेटाबेस सलाहकार, जो साधारण कॉन्फ़िगरेशन सलाह, थ्रेसहोल्ड पर चेतावनी या भविष्यवाणियों के लिए अधिक जटिल नियमों से कुछ भी हो सकते हैं, आम तौर पर व्यापक अनुशंसाएं तैयार करेंगे।
बढ़ाने की क्षमता

डेटाबेस आकार में बढ़ते हैं, और यह संभावना नहीं है कि यह लेनदेन की मात्रा या उपयोगकर्ताओं की संख्या के मामले में बढ़ेगा। उत्पादन के लिए स्केल आउट या अप करने की क्षमता महत्वपूर्ण हो सकती है। यहां तक कि अगर आप उत्पाद जीवनचक्र की शुरुआत में अपनी हार्डवेयर आवश्यकताओं का अनुमान लगाने में बहुत अच्छा काम करते हैं, तो आपको शायद विकास के चरण को संभालना होगा - जब तक आपका उत्पाद सफल होता है, यानी (लेकिन हम सभी की योजना यही है, ठीक है) ?) आपके पास आने वाले भार से निपटने के लिए अपने बुनियादी ढांचे को आसानी से बढ़ाने के साधन होने चाहिए। वेबसर्वर जैसी स्टेटलेस सेवाओं के लिए, यह काफी आसान है - आपको बस अपने संस्करण नियंत्रण उपकरण से नवीनतम उत्पादन छवि या कोड का उपयोग करके अधिक उदाहरणों का प्रावधान करने की आवश्यकता है। डेटाबेस जैसी स्टेटफुल सेवाओं के लिए, यह अधिक कठिन है। आपको अपने वर्तमान उत्पादन डेटा का उपयोग करके नए उदाहरणों का प्रावधान करना होगा, प्रतिकृति सेट करना होगा या वर्तमान और नए उदाहरणों के बीच किसी प्रकार का क्लस्टरिंग करना होगा। यह एक जटिल प्रक्रिया हो सकती है और इसे ठीक करने के लिए, आपको चुने गए क्लस्टरिंग या प्रतिकृति मॉडल का अधिक गहन ज्ञान होना चाहिए।
ClusterControl, जैसा कि नाम से पता चलता है, क्लस्टर या प्रतिकृति डेटाबेस सेटअप के निर्माण के लिए व्यापक समर्थन प्रदान करता है। उपयोग की जाने वाली विधियां हजारों तैनाती के माध्यम से युद्ध परीक्षण हैं। यह एक कमांड लाइन इंटरफेस (सीएलआई) के साथ आता है, इसलिए इसे कॉन्फ़िगरेशन प्रबंधन प्रणालियों के साथ आसानी से एकीकृत किया जा सकता है। कृपया इसे ध्यान में रखें, हालांकि, हो सकता है कि आप अपने डेटाबेस के पूल में अक्सर परिवर्तन नहीं करना चाहें - एक नए इंस्टेंस के प्रावधान में समय लगता है और मौजूदा डेटाबेस में कुछ ओवरहेड जोड़ता है। इसलिए हो सकता है कि आप "अति-प्रावधान" पक्ष पर थोड़ा रहना चाहें ताकि आपके क्लस्टर के अतिभारित होने से पहले आपके पास नए उदाहरण को स्पिन करने के लिए कुछ समय हो।
कुल मिलाकर, यह सुनिश्चित करने के लिए कि आपका वातावरण उत्पादन के लिए तैयार है, प्रारंभिक परिनियोजन के बाद भी आपको कई कदम उठाने होंगे। सही टूल के साथ, वहां पहुंचना बहुत आसान है।