सभी आधुनिक डेटाबेस सिस्टम एक क्वेरी ऑप्टिमाइज़र मॉड्यूल का समर्थन करते हैं ताकि SQL क्वेरीज़ को निष्पादित करने के लिए सबसे कुशल रणनीति की स्वचालित रूप से पहचान की जा सके। कुशल रणनीति को "योजना" कहा जाता है और इसे लागत के संदर्भ में मापा जाता है जो सीधे "क्वेरी निष्पादन / प्रतिक्रिया समय" के समानुपाती होता है। योजना को क्वेरी ऑप्टिमाइज़र से ट्री आउटपुट के रूप में दर्शाया गया है। प्लान ट्री नोड्स को मुख्य रूप से निम्नलिखित 3 श्रेणियों में विभाजित किया जा सकता है:
- नोड्स स्कैन करें :जैसा कि मेरे पिछले ब्लॉग "पोस्टग्रेएसक्यूएल में विभिन्न स्कैन विधियों का एक अवलोकन" में बताया गया है, यह इंगित करता है कि बेस टेबल डेटा को किस तरह लाने की आवश्यकता है।
- नोड्स में शामिल हों :जैसा कि मेरे पिछले ब्लॉग "पोस्टग्रेएसक्यूएल में जॉइन विधियों का एक अवलोकन" में बताया गया है, यह इंगित करता है कि दो तालिकाओं का परिणाम प्राप्त करने के लिए दो तालिकाओं को एक साथ कैसे जोड़ा जाना चाहिए।
- भौतिकीकरण नोड्स :इसे सहायक नोड भी कहते हैं। पिछले दो प्रकार के नोड इस बात से संबंधित थे कि आधार तालिका से डेटा कैसे प्राप्त किया जाए और दो तालिकाओं से प्राप्त डेटा को कैसे जोड़ा जाए। इस श्रेणी में नोड्स को आगे के विश्लेषण या रिपोर्ट तैयार करने के लिए पुनर्प्राप्त डेटा के शीर्ष पर लागू किया जाता है, उदा। डेटा को सॉर्ट करना, डेटा का कुल योग, आदि।
एक साधारण क्वेरी उदाहरण पर विचार करें जैसे...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;मान लें कि नीचे दी गई क्वेरी के अनुरूप एक योजना तैयार की गई है:
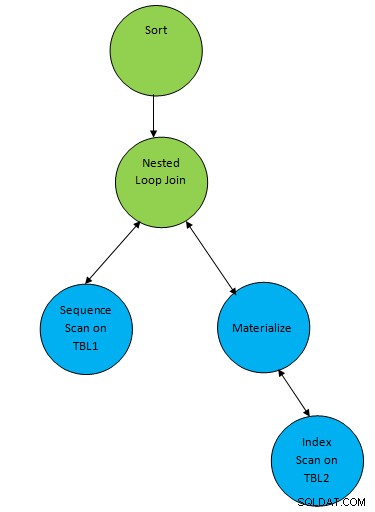
इसलिए यहां एक सहायक नोड "सॉर्ट" परिणाम के शीर्ष पर जोड़ा गया है आवश्यक क्रम में डेटा को सॉर्ट करने के लिए शामिल हों।
PostgreSQL क्वेरी ऑप्टिमाइज़र द्वारा उत्पन्न कुछ सहायक नोड्स नीचे दिए गए हैं:
- क्रमबद्ध करें
- कुल
- ग्रुप बाय एग्रीगेट
- सीमा
- अद्वितीय
- लॉकरो
- सेटऑप
आइए इनमें से प्रत्येक नोड को समझते हैं।
क्रमबद्ध करें
जैसा कि नाम से पता चलता है, जब भी सॉर्ट किए गए डेटा की आवश्यकता होती है, तो इस नोड को एक प्लान ट्री के हिस्से के रूप में जोड़ा जाता है। नीचे दिए गए दो मामलों की तरह क्रमबद्ध डेटा की स्पष्ट या अप्रत्यक्ष रूप से आवश्यकता हो सकती है:
उपयोगकर्ता परिदृश्य को आउटपुट के रूप में सॉर्ट किए गए डेटा की आवश्यकता होती है। इस मामले में, सॉर्ट नोड अन्य सभी प्रसंस्करण सहित संपूर्ण डेटा पुनर्प्राप्ति के शीर्ष पर हो सकता है।
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)नोट: भले ही उपयोगकर्ता को क्रमबद्ध क्रम में अंतिम आउटपुट की आवश्यकता होती है, यदि संबंधित तालिका और सॉर्टिंग कॉलम पर कोई अनुक्रमणिका है, तो अंतिम योजना में सॉर्ट नोड नहीं जोड़ा जा सकता है। इस मामले में, यह इंडेक्स स्कैन का चयन कर सकता है जिसके परिणामस्वरूप डेटा का क्रमबद्ध क्रमबद्ध क्रम होगा। उदाहरण के लिए, आइए उपरोक्त उदाहरण पर एक इंडेक्स बनाएं और परिणाम देखें:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)जैसा कि मेरे पिछले ब्लॉग में बताया गया है पोस्टग्रेएसक्यूएल में जॉइन विधियों का एक अवलोकन, मर्ज जॉइन में शामिल होने से पहले दोनों टेबल डेटा को सॉर्ट करने की आवश्यकता होती है। तो ऐसा हो सकता है कि मर्ज जॉइन को सॉर्टिंग की अतिरिक्त लागत के साथ भी किसी अन्य जॉइन विधि से सस्ता पाया गया। तो इस मामले में, तालिका के शामिल होने और स्कैन विधि के बीच सॉर्ट नोड जोड़ा जाएगा ताकि सॉर्ट किए गए रिकॉर्ड को शामिल विधि में पारित किया जा सके।
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)कुल
यदि एकाधिक इनपुट पंक्तियों से एकल परिणामों की गणना करने के लिए एक समग्र फ़ंक्शन का उपयोग किया जाता है, तो समग्र नोड को एक योजना ट्री के हिस्से के रूप में जोड़ा जाता है। उपयोग किए गए कुछ समग्र कार्य COUNT, SUM, AVG (औसत), MAX (MAXIMUM) और MIN (MINIMUM) हैं।
एक समग्र नोड एक आधार संबंध स्कैन के शीर्ष पर या (और) संबंधों के जुड़ने पर आ सकता है। उदाहरण:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
इस प्रकार के नोड "एग्रीगेट" नोड के एक्सटेंशन हैं। यदि उनके समूह के अनुसार कई इनपुट पंक्तियों को संयोजित करने के लिए कुल कार्यों का उपयोग किया जाता है, तो इस प्रकार के नोड्स को एक प्लान ट्री में जोड़ा जाता है। इसलिए यदि क्वेरी में किसी भी समग्र फ़ंक्शन का उपयोग किया गया है और इसके साथ ही क्वेरी में ग्रुप बाय क्लॉज है, तो या तो हैशएग्रेगेट या ग्रुपएग्रीगेट नोड को प्लान ट्री में जोड़ा जाएगा।
चूंकि PostgreSQL एक इष्टतम योजना ट्री बनाने के लिए लागत आधारित अनुकूलक का उपयोग करता है, इसलिए यह अनुमान लगाना लगभग असंभव है कि इनमें से किस नोड का उपयोग किया जाएगा। लेकिन आइए समझते हैं कि इसका उपयोग कब और कैसे किया जाता है।
हैश एग्रीगेट
HashAggregate डेटा को समूहबद्ध करने के लिए हैश तालिका बनाकर काम करता है। इसलिए हैशएग्रीगेट का इस्तेमाल ग्रुप लेवल एग्रीगेट द्वारा किया जा सकता है, अगर एग्रीगेट अनसोल्ड डेटा सेट पर हो रहा है।
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)यहां डेमो1 तालिका स्कीमा डेटा पिछले अनुभाग में दिखाए गए उदाहरण के अनुसार है। चूंकि समूह में केवल 1000 पंक्तियाँ हैं, इसलिए हैश तालिका बनाने के लिए आवश्यक संसाधन छँटाई की लागत से कम है। क्वेरी प्लानर हैशएग्रीगेट को चुनने का फैसला करता है।
ग्रुपएग्रीगेट
GroupAggregate सॉर्ट किए गए डेटा पर काम करता है, इसलिए इसे किसी अतिरिक्त डेटा संरचना की आवश्यकता नहीं होती है। यदि एकत्रीकरण सॉर्ट किए गए डेटा सेट पर है, तो GroupAggregate का उपयोग समूह स्तरीय समुच्चय द्वारा किया जा सकता है। सॉर्ट किए गए डेटा पर समूह बनाने के लिए या तो यह स्पष्ट रूप से सॉर्ट कर सकता है (सॉर्ट नोड जोड़कर) या यह इंडेक्स द्वारा प्राप्त डेटा पर काम कर सकता है, जिस स्थिति में यह निहित रूप से सॉर्ट किया जाता है।
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) यहां डेमो2 तालिका स्कीमा डेटा पिछले अनुभाग में दिखाए गए उदाहरण के अनुसार है। चूँकि यहाँ समूह में 100000 पंक्तियाँ हैं, इसलिए हैश तालिका बनाने के लिए आवश्यक संसाधन छँटाई की लागत से अधिक महंगा हो सकता है। तो क्वेरी प्लानर GroupAggregate को चुनने का फैसला करता है। यहां देखें कि "डेमो 2" तालिका से चुने गए रिकॉर्ड स्पष्ट रूप से सॉर्ट किए गए हैं और जिसके लिए प्लान ट्री में एक नोड जोड़ा गया है।
नीचे एक और उदाहरण देखें, जहां इंडेक्स स्कैन के कारण पहले से ही डेटा पुनर्प्राप्त किया जाता है:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) नीचे एक और उदाहरण देखें, जिसमें इंडेक्स स्कैन होने के बावजूद, इसे स्पष्ट रूप से उस कॉलम के रूप में सॉर्ट करने की आवश्यकता है जिस पर इंडेक्स और ग्रुपिंग कॉलम समान नहीं हैं। तो फिर भी इसे ग्रुपिंग कॉलम के अनुसार क्रमबद्ध करने की आवश्यकता है।
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)नोट: GroupAggregate/HashAggregate का उपयोग कई अन्य अप्रत्यक्ष प्रश्नों के लिए किया जा सकता है, भले ही क्वेरी में समूह के साथ एकत्रीकरण न हो। यह इस बात पर निर्भर करता है कि योजनाकार क्वेरी की व्याख्या कैसे करता है। उदा. मान लें कि हमें तालिका से अलग मान प्राप्त करने की आवश्यकता है, फिर इसे संबंधित कॉलम द्वारा एक समूह के रूप में देखा जा सकता है और फिर प्रत्येक समूह से एक मान लिया जा सकता है।
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)इसलिए यहां हैशएग्रीगेट का उपयोग किया जाता है, भले ही इसमें कोई एकत्रीकरण और समूह शामिल न हो।
सीमा
यदि चयन क्वेरी में "लिमिट/ऑफसेट" क्लॉज का उपयोग किया जाता है, तो लिमिट नोड्स प्लान ट्री में जुड़ जाते हैं। इस क्लॉज का उपयोग पंक्तियों की संख्या को सीमित करने के लिए किया जाता है और वैकल्पिक रूप से डेटा पढ़ना शुरू करने के लिए एक ऑफसेट प्रदान करता है। नीचे उदाहरण:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)अद्वितीय
अंतर्निहित परिणाम से एक अलग मान प्राप्त करने के लिए इस नोड का चयन किया जाता है। ध्यान दें कि क्वेरी, चयनात्मकता और अन्य संसाधन जानकारी के आधार पर, विशिष्ट नोड का उपयोग किए बिना भी विशिष्ट मान को हैशएग्रीगेट/ग्रुपएग्रीगेट का उपयोग करके पुनर्प्राप्त किया जा सकता है। उदाहरण:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)लॉकरो
PostgreSQL चयनित सभी पंक्तियों को लॉक करने के लिए कार्यक्षमता प्रदान करता है। पंक्तियों को क्रमशः "साझा करने के लिए" और "अद्यतन के लिए" खंड के आधार पर "साझा" मोड या "अनन्य" मोड में चुना जा सकता है। इस ऑपरेशन को हासिल करने के लिए प्लान ट्री में एक नया नोड "लॉकरो" जोड़ा जाता है।
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)सेटऑप
PostgreSQL दो या अधिक क्वेरी के परिणामों को संयोजित करने के लिए कार्यक्षमता प्रदान करता है। इसलिए जैसे ही ज्वाइन नोड का प्रकार दो तालिकाओं में शामिल होने के लिए चुना जाता है, उसी प्रकार दो या दो से अधिक प्रश्नों के परिणामों को संयोजित करने के लिए एक समान प्रकार का सेटऑप नोड चुना जाता है। उदाहरण के लिए, कर्मचारियों के साथ उनकी आईडी, नाम, आयु और उनके वेतन के साथ एक तालिका पर विचार करें:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 अब आइए 25 वर्ष से अधिक आयु वाले कर्मचारियों को प्राप्त करें:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) अब हम कर्मचारियों को 95 मिलियन से अधिक वेतन प्राप्त करते हैं:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)अब 25 वर्ष से अधिक आयु के कर्मचारियों और 95 मिलियन से अधिक वेतन वाले कर्मचारियों को प्राप्त करने के लिए, हम नीचे इंटरसेक्ट क्वेरी लिख सकते हैं:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) तो यहां, इन दो अलग-अलग प्रश्नों के प्रतिच्छेदन का मूल्यांकन करने के लिए एक नए प्रकार का नोड हैशसेटऑप जोड़ा गया है।
ध्यान दें कि यहां अन्य दो प्रकार के नए नोड जोड़े गए हैं:
जोड़ें
यह नोड कई परिणामों को एक में सेट करने के लिए जोड़ा जाता है।
सबक्वायरी स्कैन
यह नोड किसी भी सबक्वेरी का मूल्यांकन करने के लिए जोड़ा जाता है। उपरोक्त योजना में, एक अतिरिक्त स्थिर कॉलम मान का मूल्यांकन करने के लिए सबक्वेरी को जोड़ा जाता है जो इंगित करता है कि किस इनपुट सेट ने एक विशिष्ट पंक्ति का योगदान दिया है।
HashedSetop अंतर्निहित परिणाम के हैश का उपयोग करके काम करता है लेकिन क्वेरी ऑप्टिमाइज़र द्वारा सॉर्ट आधारित सेटऑप ऑपरेशन उत्पन्न करना संभव है। क्रमबद्ध आधारित सेटोप नोड को "सेटोप" के रूप में दर्शाया जाता है।
नोट:एक ही प्रश्न के साथ उपरोक्त परिणाम में दिखाए गए समान परिणाम प्राप्त करना संभव है, लेकिन यहां इसे केवल एक आसान प्रदर्शन के लिए प्रतिच्छेदन का उपयोग करके दिखाया गया है।
निष्कर्ष
पोस्टग्रेएसक्यूएल के सभी नोड उपयोगी होते हैं और क्वेरी, डेटा आदि की प्रकृति के आधार पर चुने जाते हैं। कई क्लॉज नोड्स के साथ एक से एक मैप किए जाते हैं। कुछ खंडों के लिए नोड्स के लिए कई विकल्प हैं, जो अंतर्निहित डेटा लागत गणना के आधार पर तय किए जाते हैं।