यह अच्छा है लेकिन कभी-कभी बुरा भी हो सकता है।
पैरामीटर सूँघना क्वेरी ऑप्टिमाइज़र के बारे में है जो सर्वोत्तम क्वेरी योजना का पता लगाने के लिए दिए गए पैरामीटर के मान का उपयोग करता है। कई विकल्पों में से एक और जो समझने में बहुत आसान है, वह यह है कि क्या मान प्राप्त करने के लिए पूरी तालिका को स्कैन किया जाना चाहिए या यदि यह इंडेक्स का उपयोग करके तेज़ हो जाएगा। यदि आपके पैरामीटर में मान अत्यधिक चयनात्मक है, तो ऑप्टिमाइज़र संभवतः खोज के साथ एक क्वेरी योजना बनाएगा और यदि ऐसा नहीं है तो क्वेरी आपकी तालिका का स्कैन करेगी।
क्वेरी योजना को तब कैश किया जाता है और अलग-अलग मानों वाले लगातार प्रश्नों के लिए पुन:उपयोग किया जाता है। पैरामीटर सूँघने का बुरा हिस्सा तब होता है जब कैश्ड प्लान उन मानों में से किसी एक के लिए सबसे अच्छा विकल्प नहीं होता है।
नमूना डेटा:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T मूल्य पर एक गैर-संकुल सूचकांक के साथ दो हजार पंक्तियों वाली एक तालिका है। एक पंक्ति है जहाँ मान 1 . है और बाकी का मान 2 . है ।
नमूना क्वेरी:
select *
from T
where Value = @Value;
क्वेरी ऑप्टिमाइज़र के पास यहां विकल्प हैं या तो क्लस्टर्ड इंडेक्स स्कैन करना है और प्रत्येक पंक्ति के विरुद्ध जहां क्लॉज की जांच करना है या मेल खाने वाली पंक्तियों को खोजने के लिए इंडेक्स सीक का उपयोग करना है और फिर मांगे गए कॉलम से मान प्राप्त करने के लिए एक कुंजी लुकअप करना है। कॉलम सूची।
जब सूंघने वाला मान 1 हो क्वेरी योजना इस तरह दिखेगी:

और जब सूंघने का मान 2 हो यह इस तरह दिखेगा:
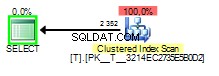
इस मामले में पैरामीटर सूँघने का बुरा हिस्सा तब होता है जब क्वेरी योजना एक 1 को सूँघते हुए बनाई जाती है लेकिन बाद में 2 . के मान के साथ निष्पादित किया गया ।
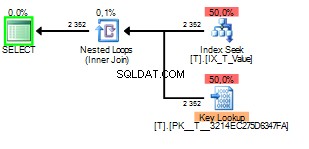
आप देख सकते हैं कि की लुकअप को 2352 बार निष्पादित किया गया था। एक स्कैन स्पष्ट रूप से बेहतर विकल्प होगा।
संक्षेप में, मैं कहूंगा कि पैरामीटर सूँघना एक अच्छी बात है कि आपको अपने प्रश्नों के मापदंडों का उपयोग करके जितना संभव हो उतना करने की कोशिश करनी चाहिए। कभी-कभी यह गलत हो सकता है और उन मामलों में यह विषम डेटा के कारण होता है जो आपके आँकड़ों के साथ खिलवाड़ कर रहा है।
अपडेट करें:
यहाँ कुछ dmv के विरुद्ध एक प्रश्न दिया गया है जिसका उपयोग आप यह पता लगाने के लिए कर सकते हैं कि आपके सिस्टम पर कौन से प्रश्न सबसे महंगे हैं। आप जो खोज रहे हैं उस पर विभिन्न मानदंडों का उपयोग करने के लिए क्लॉज द्वारा ऑर्डर में बदलें। मुझे लगता है कि TotalDuration शुरू करने के लिए एक अच्छी जगह है।
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;