आईटी उद्योग में काम करते हुए, हमने शायद "फेलओवर" शब्द कई बार सुना है, लेकिन यह सवाल भी उठा सकता है:वास्तव में एक विफलता क्या है? हम इसका उपयोग किस लिए कर सकते हैं? क्या इसका होना जरूरी है? हम यह कैसे कर सकते हैं?
हालांकि वे बहुत ही बुनियादी प्रश्न लग सकते हैं, किसी भी डेटाबेस वातावरण में उन्हें ध्यान में रखना महत्वपूर्ण है। और अक्सर हम बुनियादी बातों पर ध्यान नहीं देते...
शुरू करने के लिए, आइए कुछ बुनियादी अवधारणाओं को देखें।
विफलता क्या है?
विफलता एक प्रणाली की क्षमता है जो कुछ विफलता होने पर भी कार्य करना जारी रखती है। यह सुझाव देता है कि यदि प्राथमिक घटक विफल हो जाते हैं तो सिस्टम के कार्यों को द्वितीयक घटकों द्वारा ग्रहण किया जाता है।
PostgreSQL के मामले में, विभिन्न उपकरण हैं जो आपको एक डेटाबेस क्लस्टर को लागू करने की अनुमति देते हैं जो विफलताओं के लिए लचीला है। PostgreSQL में मूल रूप से उपलब्ध एक अतिरेक तंत्र प्रतिकृति है। और PostgreSQL 10 में नवीनता तार्किक प्रतिकृति का कार्यान्वयन है।
प्रतिकृति क्या है?
यह एक या अधिक डेटाबेस नोड्स में डेटा को कॉपी और अपडेट रखने की प्रक्रिया है। यह एक मास्टर नोड की अवधारणा का उपयोग करता है जो संशोधनों को प्राप्त करता है, और दास नोड्स जहां उन्हें दोहराया जाता है।
हमारे पास प्रतिकृति को वर्गीकृत करने के कई तरीके हैं:
- सिंक्रोनस प्रतिकृति:हमारे मास्टर नोड के खो जाने पर भी डेटा का कोई नुकसान नहीं होता है, लेकिन मास्टर में कमिट को स्लेव से पुष्टि की प्रतीक्षा करनी चाहिए, जो प्रदर्शन को प्रभावित कर सकता है।
- अतुल्यकालिक प्रतिकृति:यदि हम अपना मास्टर नोड खो देते हैं तो डेटा हानि की संभावना है। यदि घटना के समय किसी कारण से प्रतिकृति को अद्यतन नहीं किया जाता है, तो जो जानकारी कॉपी नहीं की गई है वह खो सकती है।
- भौतिक प्रतिकृति:डिस्क ब्लॉक कॉपी किए गए हैं।
- तार्किक प्रतिकृति:डेटा परिवर्तन की स्ट्रीमिंग।
- गर्म स्टैंडबाय स्लेव:वे कनेक्शन का समर्थन नहीं करते हैं।
- हॉट स्टैंडबाय स्लेव्स:केवल-पढ़ने के लिए कनेक्शन का समर्थन, रिपोर्ट या प्रश्नों के लिए उपयोगी।
विफलता का उपयोग किस लिए किया जाता है?
विफलता के कई संभावित उपयोग हैं। आइए कुछ उदाहरण देखें।
माइग्रेशन
अगर हम अपने डाउनटाइम को कम करके एक डेटासेंटर से दूसरे डेटासेंटर में माइग्रेट करना चाहते हैं, तो हम फ़ेलओवर का उपयोग कर सकते हैं।
मान लीजिए कि हमारा मास्टर डेटासेंटर ए में है, और हम अपने सिस्टम को डेटासेंटर बी में माइग्रेट करना चाहते हैं।
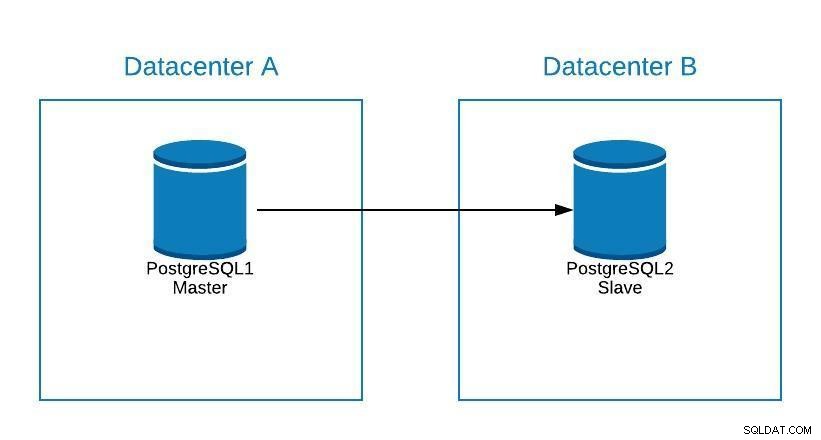 माइग्रेशन आरेख 1
माइग्रेशन आरेख 1 हम डेटासेंटर बी में एक प्रतिकृति बना सकते हैं। एक बार जब यह सिंक्रनाइज़ हो जाता है, तो हमें अपने सिस्टम को रोकना चाहिए, हमारे प्रतिकृति को नए मास्टर और फेलओवर में बढ़ावा देना चाहिए, इससे पहले कि हम अपने सिस्टम को डेटासेंटर बी में नए मास्टर को इंगित करें।
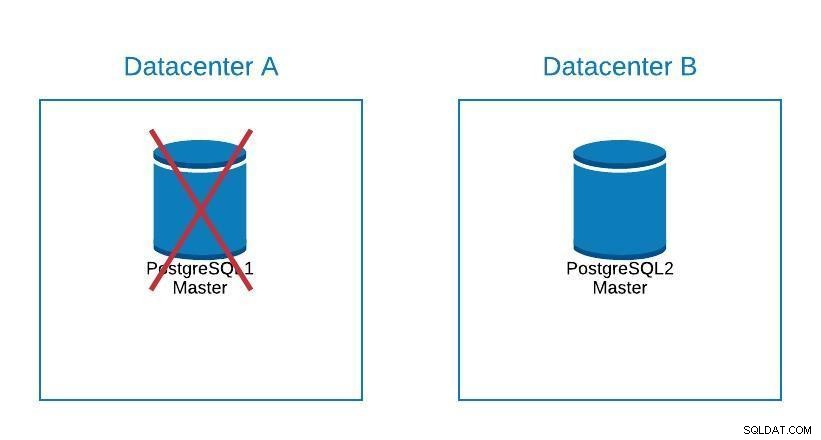 माइग्रेशन आरेख 2
माइग्रेशन आरेख 2 फ़ेलओवर केवल डेटाबेस के बारे में नहीं है, बल्कि एप्लिकेशन के बारे में भी है। वे कैसे जानते हैं कि किस डेटाबेस से जुड़ना है? हम निश्चित रूप से अपने आवेदन को संशोधित नहीं करना चाहते हैं, क्योंकि यह केवल हमारे डाउनटाइम का विस्तार करेगा .. इसलिए, हम लोड बैलेंसर को कॉन्फ़िगर कर सकते हैं ताकि जब हम अपने मास्टर को नीचे ले जाएं, तो यह स्वचालित रूप से अगले सर्वर को इंगित करेगा जिसे बढ़ावा दिया गया है।
एक अन्य विकल्प डीएनएस का उपयोग है। नए डेटासेंटर में मास्टर रेप्लिका को बढ़ावा देकर, हम होस्टनाम के आईपी पते को सीधे संशोधित करते हैं जो मास्टर को इंगित करता है। इस तरह हम अपने एप्लिकेशन को संशोधित करने से बचते हैं, और यद्यपि यह स्वचालित रूप से नहीं किया जा सकता है, यह एक विकल्प है यदि हम लोड बैलेंसर को लागू नहीं करना चाहते हैं।
सिंगल लोड बैलेंसर इंस्टेंस का होना बहुत अच्छा नहीं है क्योंकि यह विफलता का एकल बिंदु बन सकता है। इसलिए, आप रख-रखाव जैसी सेवा का उपयोग करके लोड बैलेंसर के लिए फ़ेलओवर भी लागू कर सकते हैं। इस तरह, अगर हमें अपने प्राथमिक लोड बैलेंसर के साथ कोई समस्या है, तो आईपी को हमारे सेकेंडरी लोड बैलेंसर में माइग्रेट करने के लिए Keepalived जिम्मेदार है, और सब कुछ पारदर्शी रूप से काम करना जारी रखता है।
रखरखाव
अगर हमें अपने पोस्टग्रेएसक्यूएल मास्टर डेटाबेस सर्वर पर कोई रखरखाव करना है, तो हम अपने दास को बढ़ावा दे सकते हैं, कार्य कर सकते हैं और अपने पुराने मास्टर पर एक दास का पुनर्निर्माण कर सकते हैं।
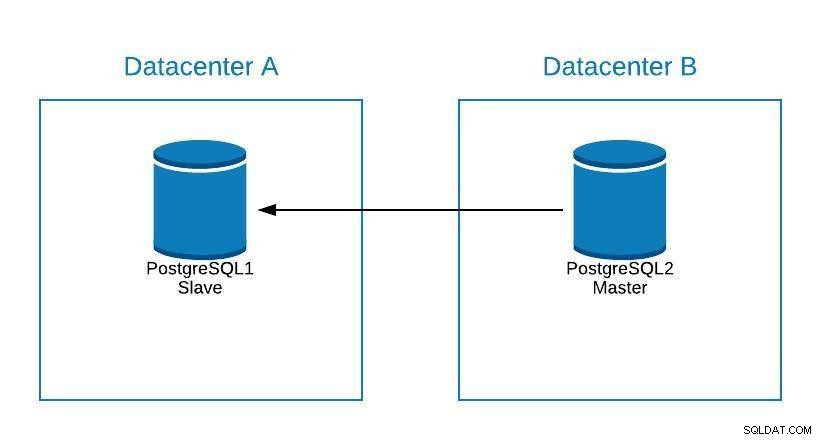 रखरखाव आरेख 1
रखरखाव आरेख 1 इसके बाद हम पुराने मालिक को फिर से पदोन्नत कर सकते हैं, और दास की पुनर्निर्माण प्रक्रिया को दोहरा सकते हैं, प्रारंभिक अवस्था में लौट सकते हैं।
रखरखाव आरेख 2 इस तरह, हम अपने सर्वर पर ऑफ़लाइन होने या रखरखाव करते समय जानकारी खोने का जोखिम उठाए बिना काम कर सकते हैं।
अपग्रेड करें
हालांकि PostgreSQL 11 अभी तक उपलब्ध नहीं है, लेकिन तार्किक प्रतिकृति का उपयोग करके PostgreSQL संस्करण 10 से अपग्रेड करना तकनीकी रूप से संभव होगा, जैसा कि अन्य इंजनों के साथ किया जा सकता है।
चरण एक नए डेटासेंटर में माइग्रेट करने के समान होंगे (माइग्रेशन अनुभाग देखें), केवल हमारा दास PostgreSQL 11 में होगा।
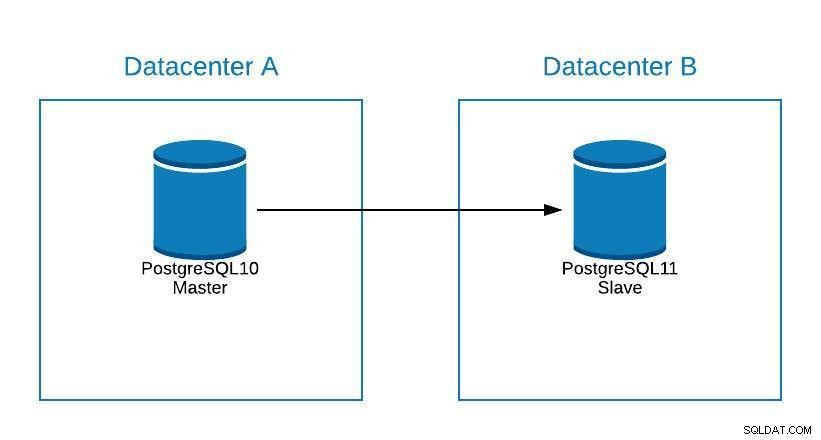 अपग्रेड डायग्राम 1
अपग्रेड डायग्राम 1 समस्याएं
फ़ेलओवर का सबसे महत्वपूर्ण कार्य हमारे डाउनटाइम को कम करना या हमारे मुख्य डेटाबेस में कोई समस्या होने पर जानकारी के नुकसान से बचना है।
अगर किसी कारण से हम अपना मास्टर डेटाबेस खो देते हैं, तो हम अपने दास को मास्टर करने के लिए एक फ़ेलओवर कर सकते हैं, और अपने सिस्टम को चालू रख सकते हैं।
ऐसा करने के लिए, PostgreSQL हमें कोई स्वचालित समाधान प्रदान नहीं करता है। हम इसे मैन्युअल रूप से कर सकते हैं, या किसी स्क्रिप्ट या बाहरी टूल के माध्यम से इसे स्वचालित कर सकते हैं।
हमारे गुलाम को मालिक बनाने के लिए:
-
pg_ctl प्रचार चलाएं
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - एक फ़ाइल बनाएं जो हमें अपनी डेटा निर्देशिका के पुनर्प्राप्ति.कॉन्फ़ में जोड़ना चाहिए।
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
एक विफलता रणनीति को लागू करने के लिए, हमें इसकी योजना बनाने और विभिन्न विफलता परिदृश्यों के माध्यम से पूरी तरह से परीक्षण करने की आवश्यकता है। चूंकि विफलताएं अलग-अलग तरीकों से हो सकती हैं, और समाधान आदर्श रूप से अधिकांश सामान्य परिदृश्यों के लिए काम करना चाहिए। यदि हम इसे स्वचालित करने का कोई तरीका ढूंढ रहे हैं, तो हम देख सकते हैं कि ClusterControl की क्या पेशकश है।
PostgreSQL फ़ेलओवर के लिए ClusterControl
ClusterControl में PostgreSQL प्रतिकृति और स्वचालित विफलता से संबंधित कई विशेषताएं हैं।
दास जोड़ें
यदि हम किसी अन्य डेटासेंटर में एक दास को जोड़ना चाहते हैं, या तो एक आकस्मिकता के रूप में या आपके सिस्टम को माइग्रेट करने के लिए, हम क्लस्टर क्रियाओं पर जा सकते हैं, और प्रतिकृति स्लेव जोड़ें का चयन कर सकते हैं।
 ClusterControl स्लेव 1 जोड़ें
ClusterControl स्लेव 1 जोड़ें हमें कुछ बुनियादी डेटा दर्ज करना होगा, जैसे आईपी या होस्टनाम, डेटा निर्देशिका (वैकल्पिक), सिंक्रोनस या एसिंक्रोनस स्लेव। हमें अपने दास को कुछ सेकंड के बाद उठना और चलाना चाहिए।
किसी अन्य डेटासेंटर का उपयोग करने के मामले में, हम एक एसिंक्रोनस स्लेव बनाने की सलाह देते हैं, क्योंकि अन्यथा विलंबता प्रदर्शन को काफी प्रभावित कर सकती है।
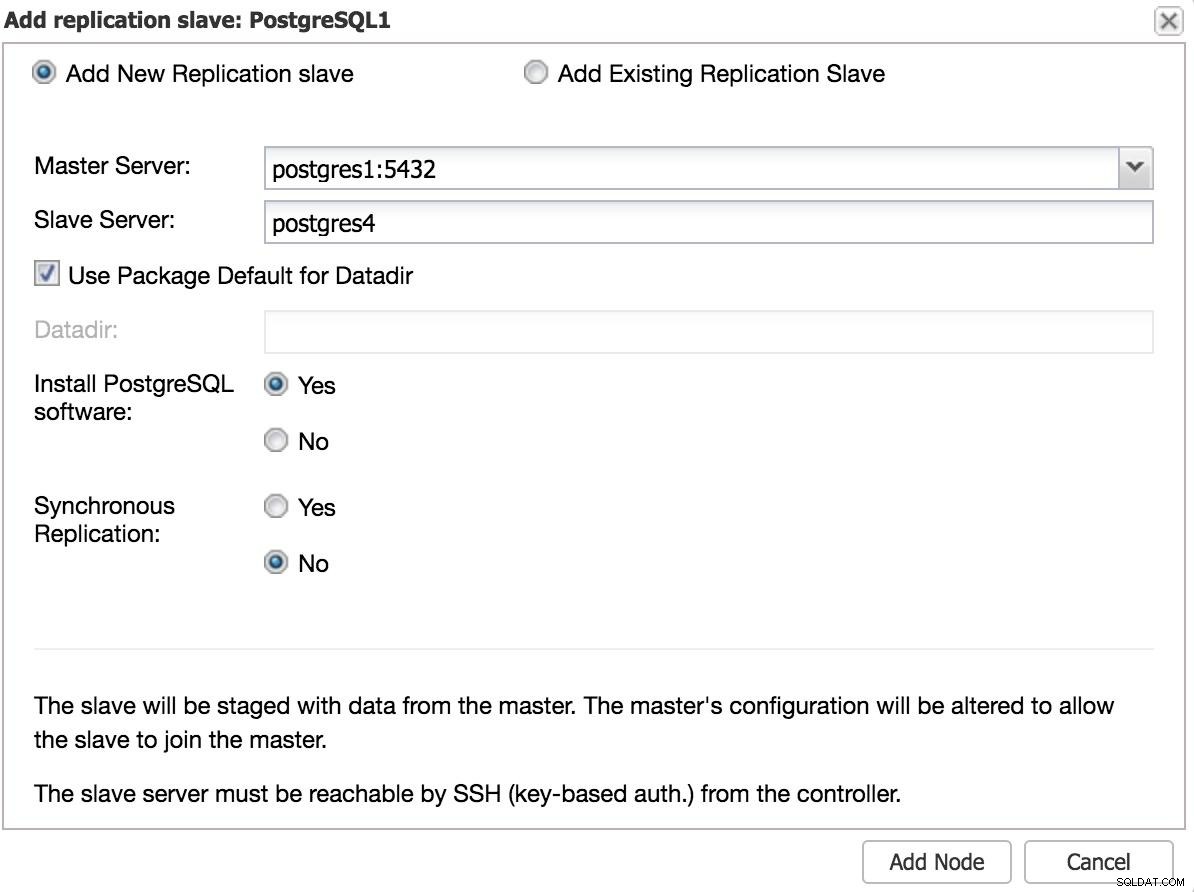 ClusterControl स्लेव 2 जोड़ें
ClusterControl स्लेव 2 जोड़ें मैन्युअल विफलता
ClusterControl के साथ, विफलता मैन्युअल रूप से या स्वचालित रूप से की जा सकती है।
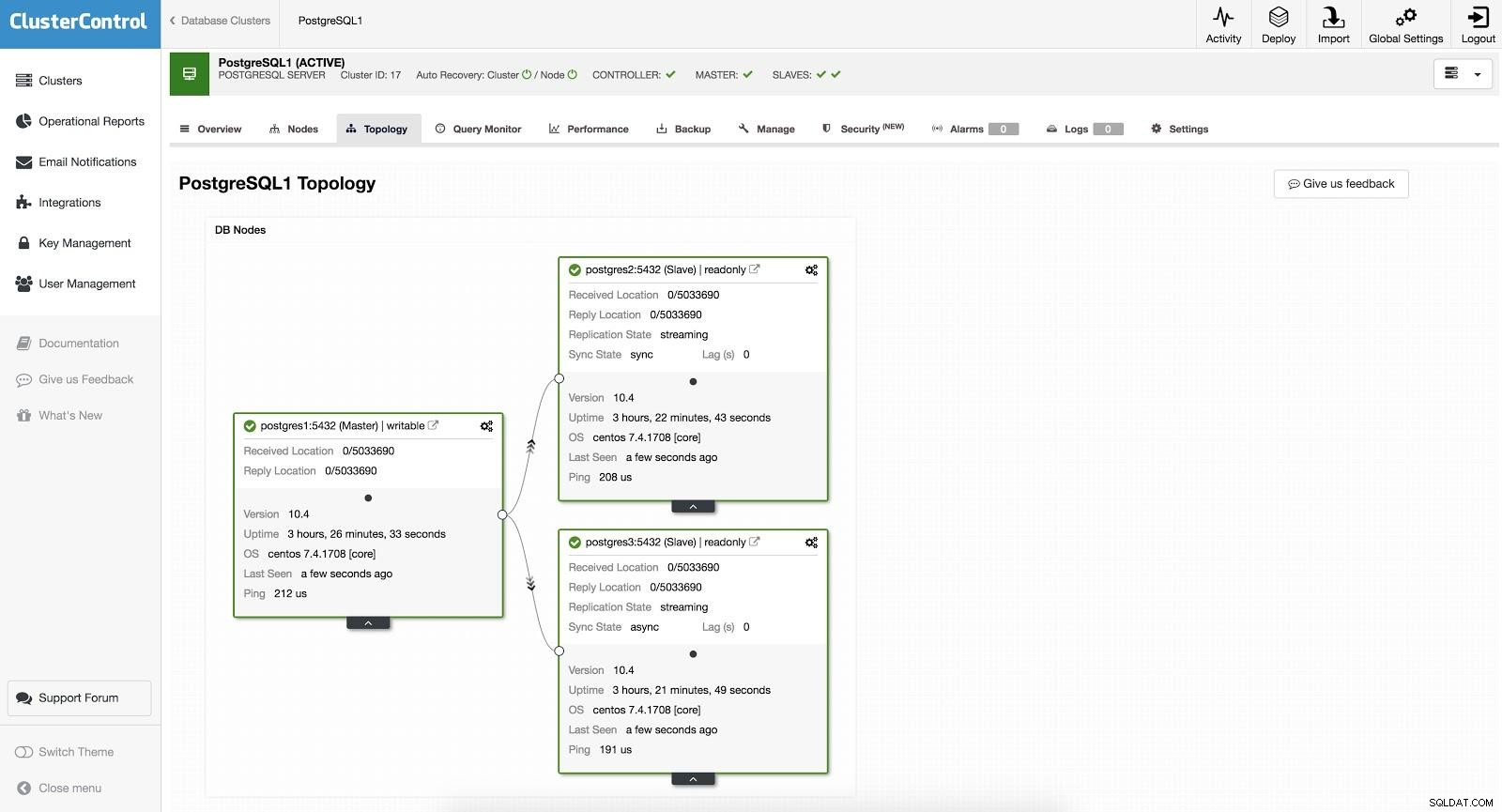 ClusterControl विफलता 1
ClusterControl विफलता 1 मैन्युअल फ़ेलओवर करने के लिए, ClusterControl -> Select Cluster -> Nodes पर जाएँ, और हमारे एक स्लेव के एक्शन नोड में, "प्रमोशन स्लेव" चुनें। इस तरह, कुछ सेकंड के बाद, हमारा गुलाम मालिक बन जाता है, और जो पहले हमारा मालिक था, वह गुलाम बन जाता है।
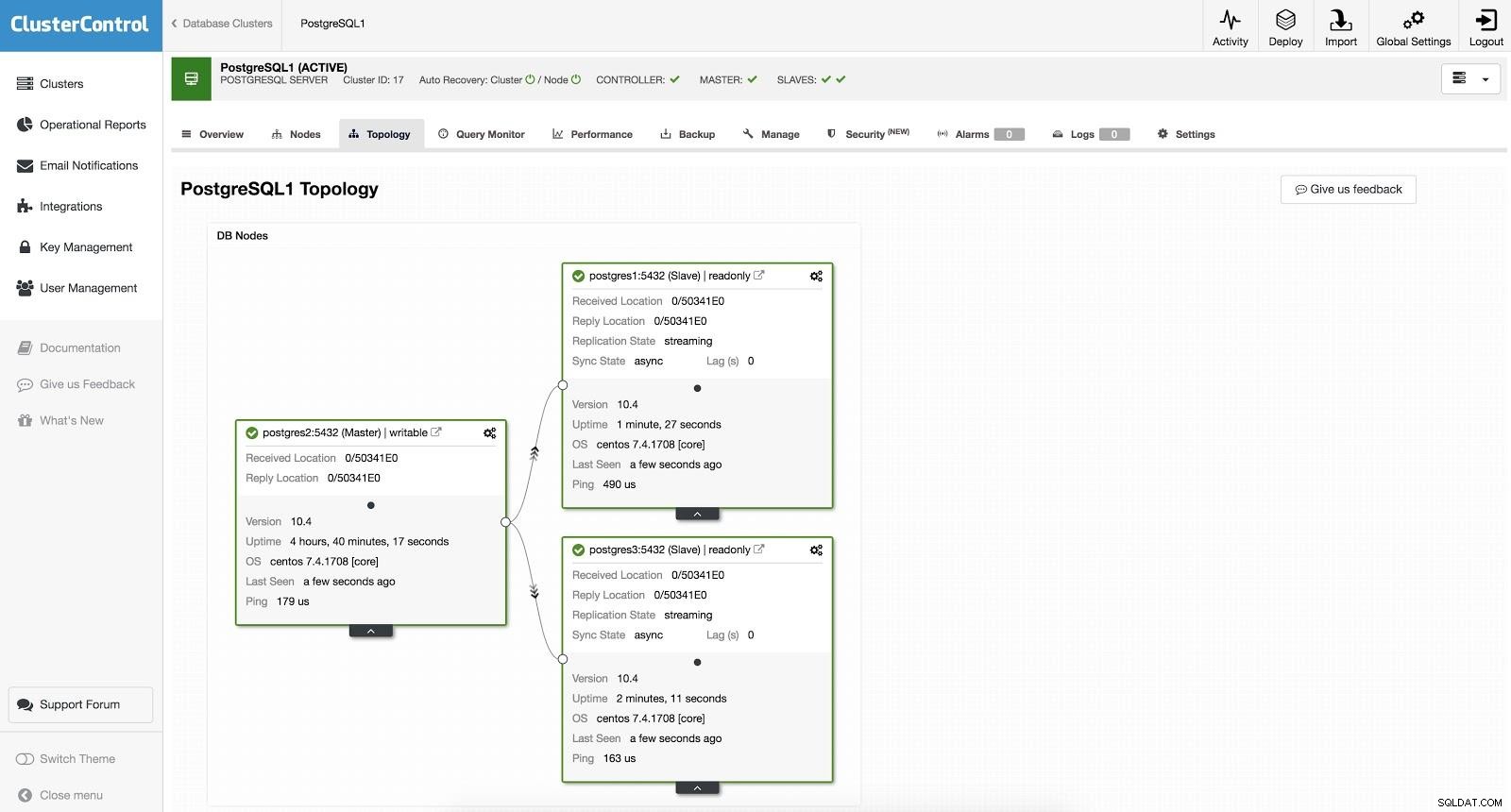 ClusterControl Failover 2
ClusterControl Failover 2 उपरोक्त माइग्रेशन, रखरखाव और अपग्रेड के कार्यों के लिए उपयोगी है जो हमने पहले देखा था।
स्वचालित विफलता
स्वचालित विफलता के मामले में, ClusterControl मास्टर में विफलताओं का पता लगाता है और नए मास्टर के रूप में सबसे वर्तमान डेटा वाले दास को बढ़ावा देता है। यह बाकी दासों पर भी काम करता है ताकि उन्हें नए स्वामी से दोहराया जा सके।
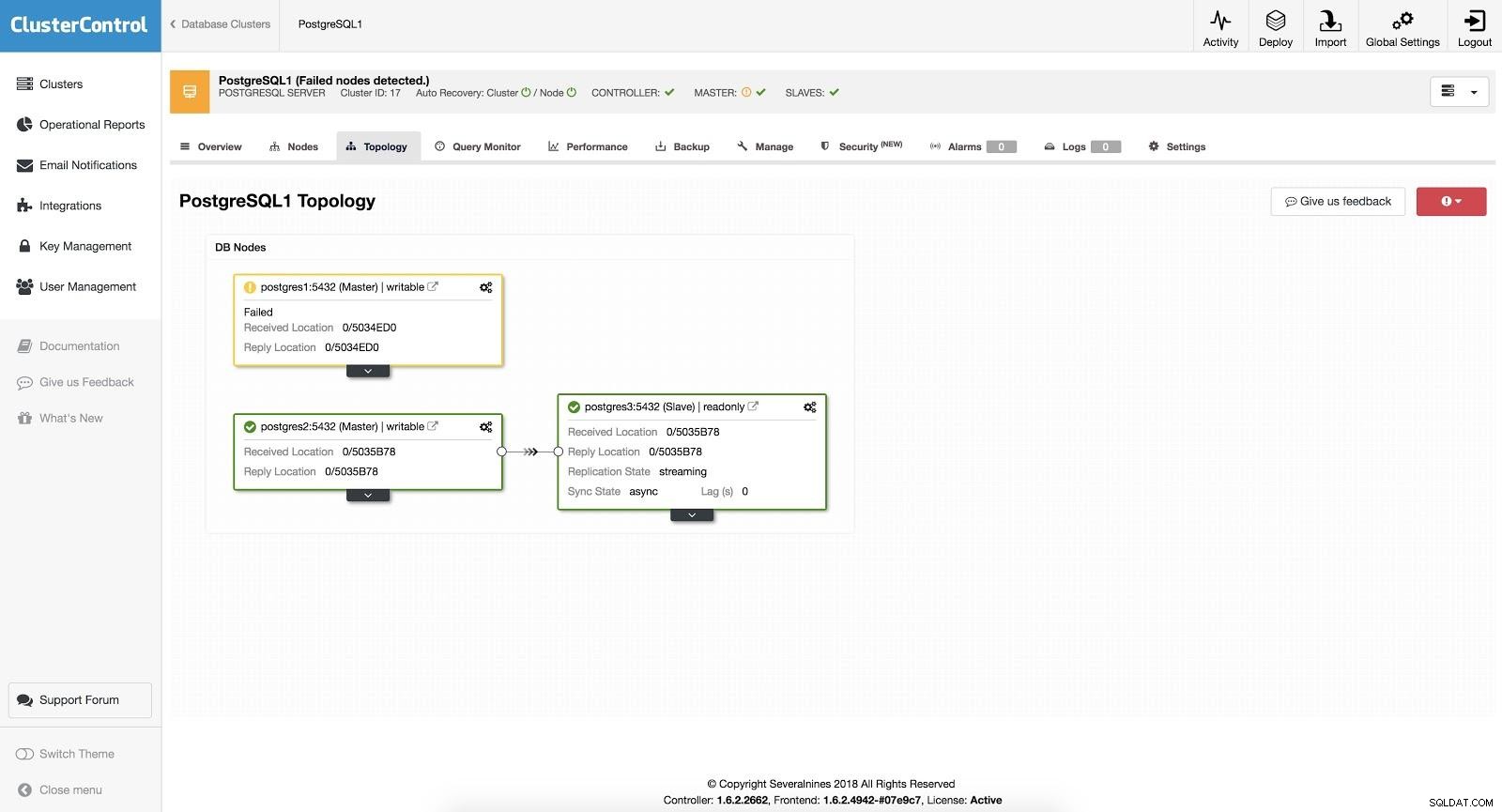 ClusterControl Failover 3
ClusterControl Failover 3 "स्वतः पुनर्प्राप्ति" विकल्प चालू होने पर, हमारा ClusterControl एक स्वचालित विफलता का प्रदर्शन करेगा और साथ ही हमें समस्या के बारे में सूचित करेगा। इस तरह, हमारे सिस्टम सेकंडों में और हमारे हस्तक्षेप के बिना ठीक हो सकते हैं।
क्लस्टर नियंत्रण हमें यह परिभाषित करने के लिए एक श्वेतसूची/ब्लैकलिस्ट को कॉन्फ़िगर करने की संभावना प्रदान करता है कि हम कैसे चाहते हैं कि एक मास्टर उम्मीदवार का निर्णय लेते समय हमारे सर्वर को ध्यान में रखा जाए (या नहीं लिया जाए)।
उपरोक्त कॉन्फ़िगरेशन के अनुसार उपलब्ध लोगों में से, ClusterControl हमारे डेटाबेस के संस्करण के आधार पर इस उद्देश्य के लिए pg_current_xlog_location (PostgreSQL 9+) या pg_current_wal_lsn (PostgreSQL 10+) का उपयोग करते हुए सबसे उन्नत स्लेव को चुनेगा।
कुछ सामान्य गलतियों से बचने के लिए, ClusterControl फ़ेलओवर प्रक्रिया पर कई जाँच भी करता है। एक उदाहरण यह है कि यदि हम अपने पुराने असफल गुरु को पुनः प्राप्त करने का प्रबंधन करते हैं, तो यह न तो एक स्वामी के रूप में और न ही एक दास के रूप में स्वचालित रूप से क्लस्टर में पुन:प्रस्तुत किया जाएगा। हमें इसे मैन्युअल रूप से करने की आवश्यकता है। यह उस स्थिति में डेटा हानि या असंगति की संभावना से बच जाएगा जब हमारे दास (जिसे हमने बढ़ावा दिया था) को विफलता के समय विलंबित किया गया था। हम समस्या का विस्तार से विश्लेषण करना भी चाह सकते हैं, लेकिन इसे अपने क्लस्टर में जोड़ते समय, हम संभवतः नैदानिक जानकारी खो देंगे।
इसके अलावा, यदि विफलता विफल हो जाती है, तो कोई और प्रयास नहीं किया जाता है, समस्या का विश्लेषण करने और संबंधित कार्यों को करने के लिए मैन्युअल हस्तक्षेप की आवश्यकता होती है। यह उस स्थिति से बचने के लिए है जहां ClusterControl, उच्च उपलब्धता प्रबंधक के रूप में, अगले दास और अगले दास को बढ़ावा देने का प्रयास करता है। कोई समस्या हो सकती है, और हम एकाधिक विफलताओं का प्रयास करके चीजों को और खराब नहीं करना चाहते हैं।
लोड बैलेंसर
जैसा कि हमने पहले उल्लेख किया है, लोड बैलेंसर हमारे फेलओवर पर विचार करने के लिए एक महत्वपूर्ण उपकरण है, खासकर यदि हम अपने डेटाबेस टोपोलॉजी में स्वचालित विफलता का उपयोग करना चाहते हैं।
विफलता के लिए उपयोगकर्ता और एप्लिकेशन दोनों के लिए पारदर्शी होने के लिए, हमें बीच में एक घटक की आवश्यकता होती है, क्योंकि यह एक दास को एक मास्टर को बढ़ावा देने के लिए पर्याप्त नहीं है। इसके लिए हम HAProxy + Keepalived का उपयोग कर सकते हैं।
HAProxy क्या है?
HAProxy एक लोड बैलेंसर है जो एक मूल से एक या अधिक गंतव्यों तक ट्रैफ़िक वितरित करता है और इस कार्य के लिए विशिष्ट नियमों और/या प्रोटोकॉल को परिभाषित कर सकता है। यदि कोई भी गंतव्य प्रत्युत्तर देना बंद कर देता है, तो उसे ऑफ़लाइन के रूप में चिह्नित कर दिया जाता है, और ट्रैफ़िक को शेष उपलब्ध गंतव्यों पर भेज दिया जाता है। यह ट्रैफ़िक को किसी दुर्गम गंतव्य पर भेजे जाने से रोकता है, और इस ट्रैफ़िक को किसी मान्य गंतव्य पर निर्देशित करके होने वाले नुकसान को रोकता है।
कीपलीव्ड क्या है?
Keepalived आपको सर्वर के एक सक्रिय/निष्क्रिय समूह के भीतर एक वर्चुअल IP को कॉन्फ़िगर करने की अनुमति देता है। यह वर्चुअल आईपी एक सक्रिय "प्राथमिक" सर्वर को सौंपा गया है। यदि यह सर्वर विफल हो जाता है, तो आईपी स्वचालित रूप से "सेकेंडरी" सर्वर में माइग्रेट हो जाता है जो निष्क्रिय पाया गया था, जिससे यह हमारे सिस्टम के लिए पारदर्शी तरीके से उसी आईपी के साथ काम करना जारी रखता है।
ClusterControl के साथ इस समाधान को लागू करने के लिए, हमने शुरू किया जैसे कि हम एक गुलाम जोड़ने जा रहे थे। क्लस्टर एक्शन पर जाएं और लोड बैलेंसर जोड़ें चुनें (क्लस्टरकंट्रोल एड स्लेव 1 इमेज देखें)।
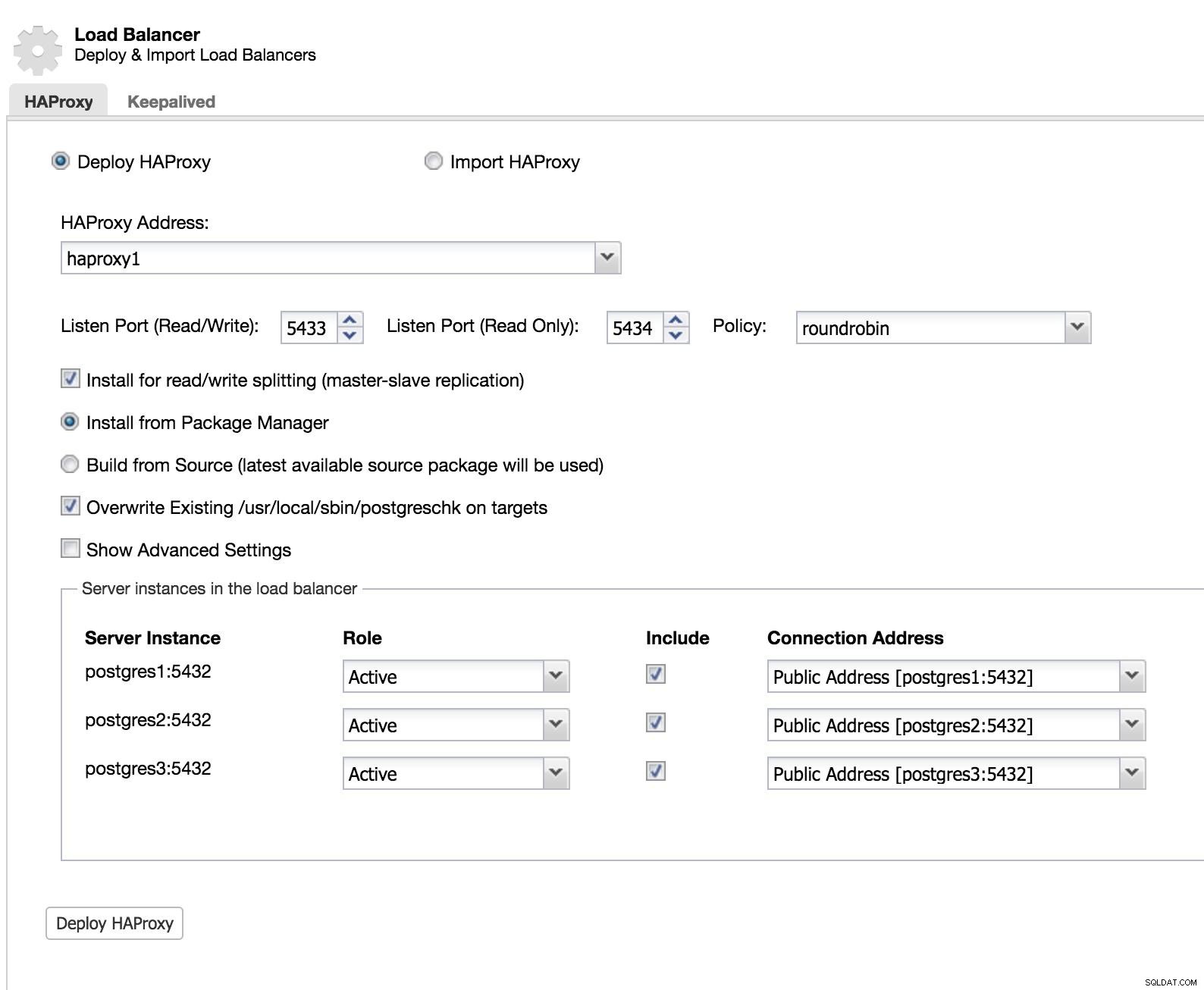 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 हम अपने नए लोड बैलेंसर की जानकारी जोड़ते हैं और हम इसे कैसे व्यवहार करना चाहते हैं (नीति)।
हमारे लोड बैलेंसर के लिए विफलता को लागू करने के मामले में, हमें कम से कम दो उदाहरणों को कॉन्फ़िगर करना होगा।
फिर हम Keepalived को कॉन्फ़िगर कर सकते हैं (Cluster चुनें -> मैनेज करें -> लोड बैलेंसर -> Keepalived)।
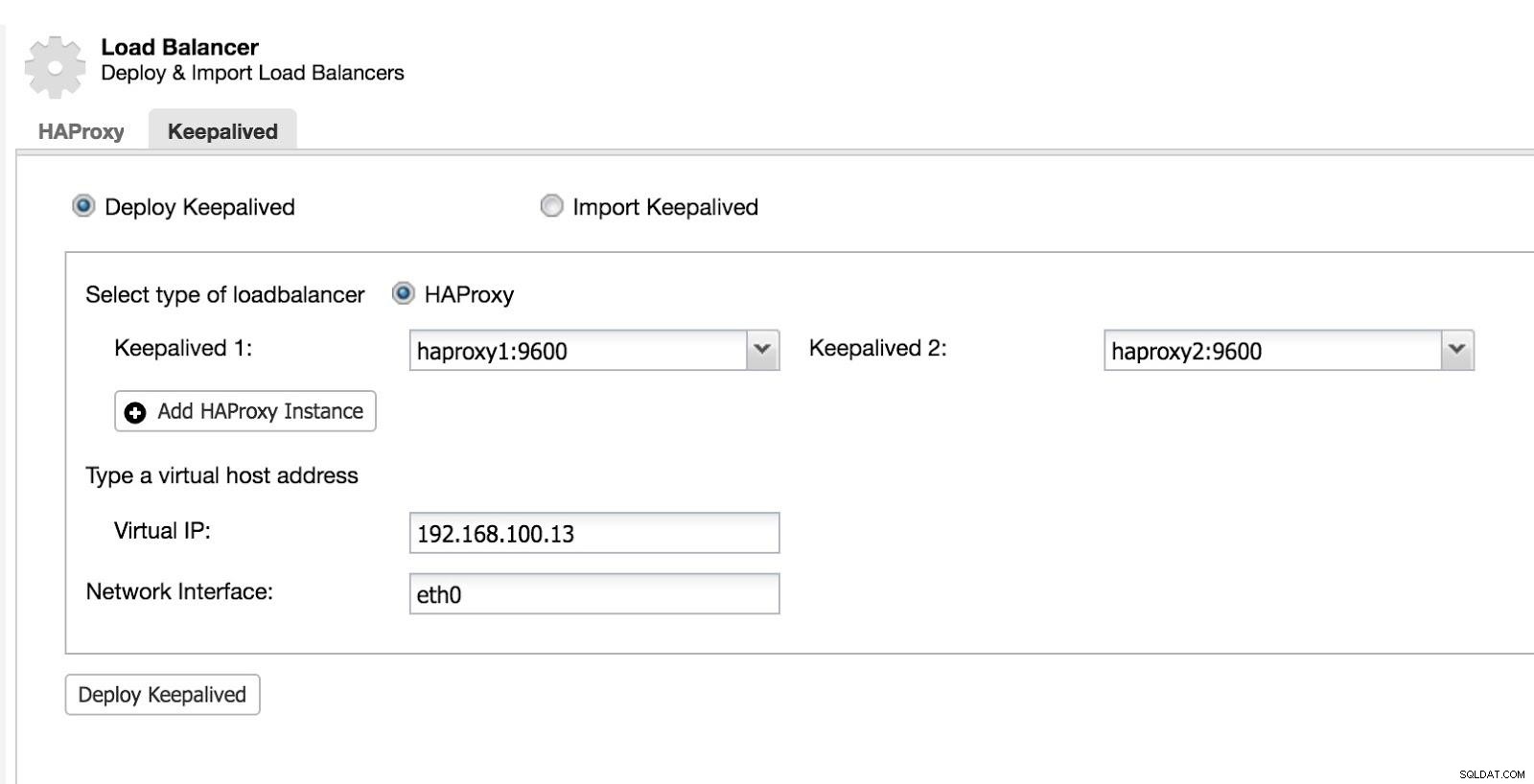 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 इसके बाद, हमारे पास निम्नलिखित टोपोलॉजी है:
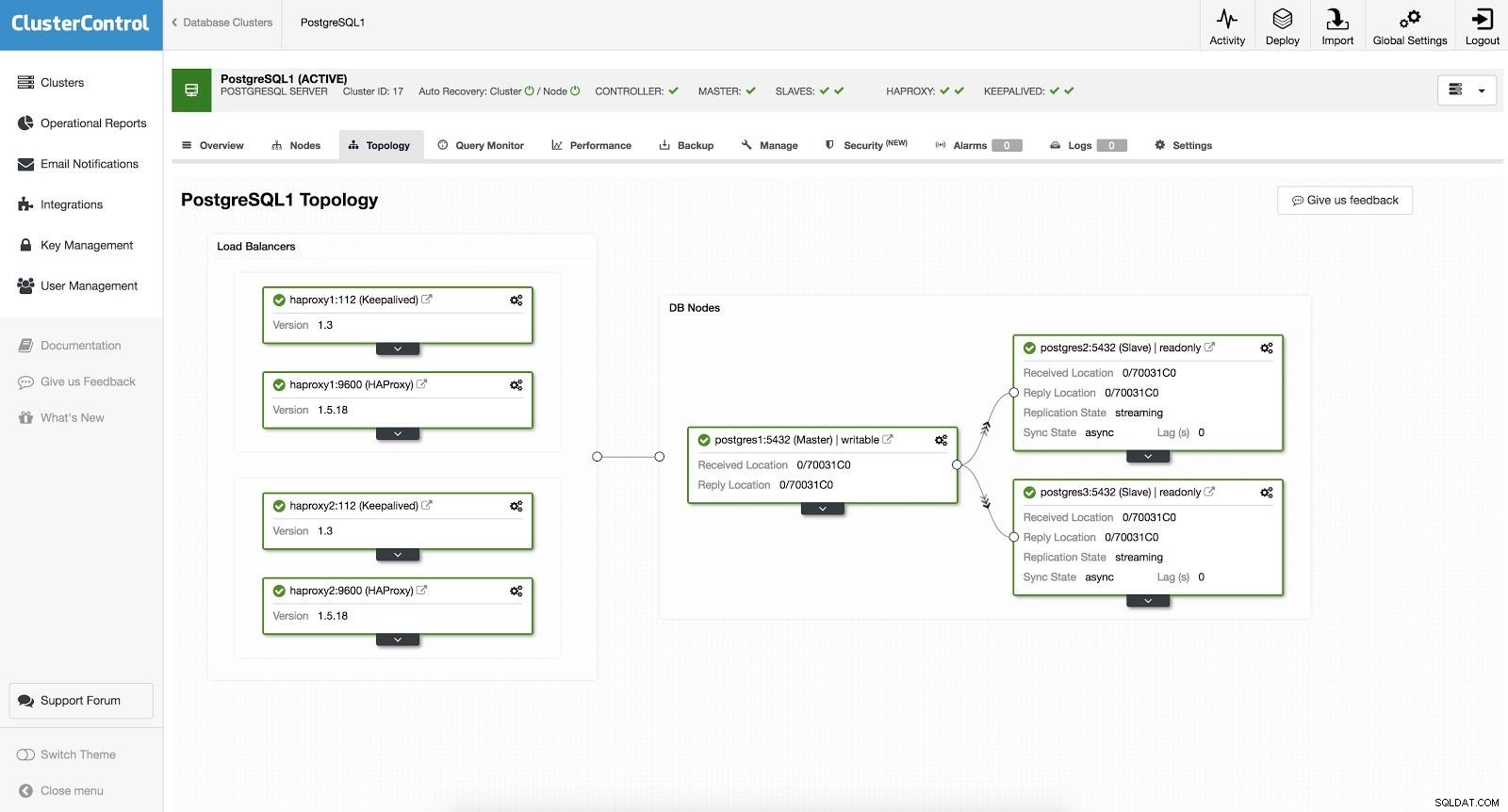 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy को दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर किया गया है, एक रीड-राइट और एक रीड-ओनली।
हमारे रीड-राइट पोर्ट में, हमारे पास हमारा मास्टर सर्वर ऑनलाइन है और हमारे बाकी नोड्स ऑफ़लाइन हैं। रीड-ओनली पोर्ट में, हमारे पास मास्टर और स्लेव दोनों ऑनलाइन हैं। इस तरह हम अपने नोड्स के बीच रीडिंग ट्रैफिक को बैलेंस कर सकते हैं। लिखते समय, रीड-राइट पोर्ट का उपयोग किया जाएगा, जो मास्टर को इंगित करेगा।
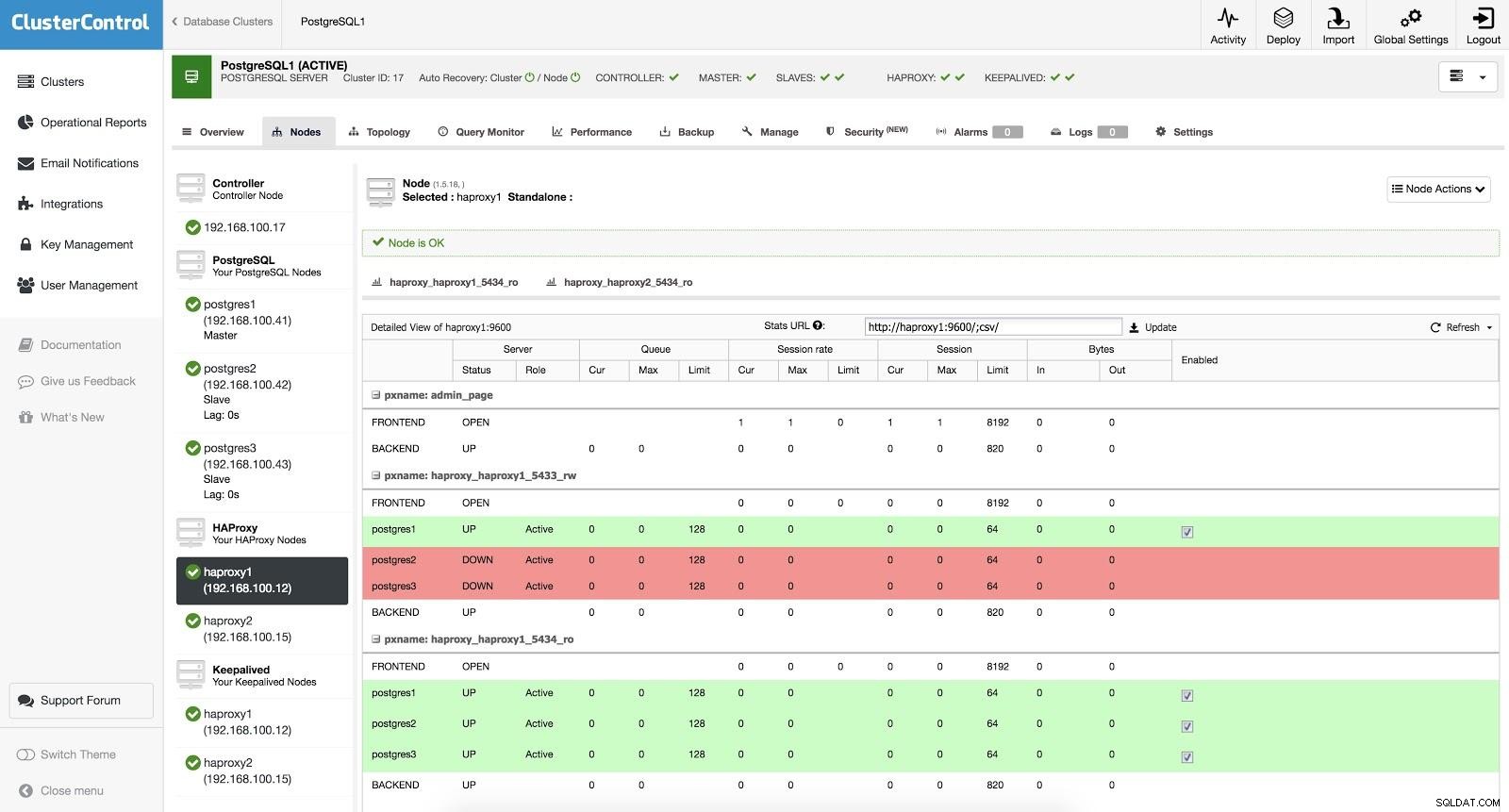 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 जब HAProxy को पता चलता है कि हमारा एक नोड, या तो मास्टर या स्लेव, पहुंच योग्य नहीं है, तो यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित करता है। HAProxy इस पर कोई ट्रैफिक नहीं भेजेगा। यह जाँच स्वास्थ्य जाँच स्क्रिप्ट द्वारा की जाती है जो परिनियोजन के समय ClusterControl द्वारा कॉन्फ़िगर की जाती है। ये जाँचते हैं कि क्या इंस्टेंस ऊपर हैं, क्या वे ठीक हो रहे हैं, या केवल-पढ़ने के लिए हैं।
जब ClusterControl एक दास को मास्टर करने के लिए बढ़ावा देता है, तो हमारा HAProxy पुराने मास्टर को ऑफ़लाइन (दोनों पोर्ट के लिए) के रूप में चिह्नित करता है और प्रचारित नोड को ऑनलाइन (रीड-राइट पोर्ट में) डालता है। इस तरह, हमारे सिस्टम सामान्य रूप से काम करते रहते हैं।
यदि हमारा सक्रिय HAProxy (जिसे एक वर्चुअल IP पता दिया गया है जिससे हमारा सिस्टम कनेक्ट होता है) विफल हो जाता है, तो Keepalived इस IP को हमारे निष्क्रिय HAProxy में स्वचालित रूप से माइग्रेट कर देता है। इसका मतलब यह है कि तब हमारे सिस्टम सामान्य रूप से कार्य करना जारी रखने में सक्षम होते हैं।
निष्कर्ष
जैसा कि हम देख सकते हैं, विफलता किसी भी उत्पादन डेटाबेस का एक मूलभूत हिस्सा है। सामान्य रखरखाव कार्य या माइग्रेशन करते समय यह उपयोगी हो सकता है। हम आशा करते हैं कि यह ब्लॉग विषय के परिचय के रूप में उपयोगी रहा है, इसलिए आप शोध करना जारी रख सकते हैं और अपनी स्वयं की विफलता रणनीतियाँ बना सकते हैं।