सामान्यतया, सबसे अच्छा प्रकार का सॉर्ट वह है जिसे पूरी तरह से टाला जाता है। सावधानीपूर्वक अनुक्रमण और कभी-कभी कुछ रचनात्मक क्वेरी लेखन के साथ, हम निष्पादन योजनाओं से सॉर्ट ऑपरेटर की आवश्यकता को अक्सर हटा सकते हैं। जहां सॉर्ट किया जाने वाला डेटा बड़ा है, इस प्रकार के सॉर्ट से बचने से बहुत महत्वपूर्ण प्रदर्शन सुधार हो सकते हैं।
दूसरा सबसे अच्छा प्रकार वह है जिसे हम टाल नहीं सकते हैं, लेकिन जो उचित मात्रा में स्मृति सुरक्षित रखता है, और कुछ सार्थक करने के लिए इसका सभी या अधिकतर उपयोग करता है। सार्थक होना कई रूप ले सकते हैं। कभी-कभी, एक सॉर्ट बाद के ऑपरेशन को सक्षम करके अपने लिए भुगतान से अधिक कर सकता है जो सॉर्ट किए गए इनपुट पर अधिक कुशलता से काम करता है। दूसरी बार, सॉर्ट करना केवल सादा आवश्यक है, और हमें इसे यथासंभव कुशल बनाने की आवश्यकता है।
फिर वे प्रकार आते हैं जिनसे हम आमतौर पर बचना चाहते हैं:वे जो अपनी आवश्यकता से कहीं अधिक मेमोरी आरक्षित करते हैं, और वे जो बहुत कम आरक्षित करते हैं। बाद वाला मामला वह है जिस पर ज्यादातर लोग ध्यान केंद्रित करते हैं। मेमोरी में आवश्यक सॉर्टिंग ऑपरेशन को पूरा करने के लिए अपर्याप्त मेमोरी आरक्षित (या उपलब्ध) के साथ, एक सॉर्ट ऑपरेटर, कुछ अपवादों के साथ, डेटा पंक्तियों को tempdb तक फैला देगा। . वास्तव में, इसका अर्थ लगभग हमेशा भौतिक भंडारण के लिए क्रमबद्ध पृष्ठों को लिखना (और निश्चित रूप से बाद में उन्हें पढ़ना) होता है।
SQL सर्वर के आधुनिक संस्करणों में, एक स्पिल्ड सॉर्ट का परिणाम पोस्ट-निष्पादन योजनाओं में एक चेतावनी आइकन में होता है, जिसमें यह विवरण शामिल हो सकता है कि कितना डेटा गिराया गया था, कितने थ्रेड शामिल थे, और स्पिल स्तर।
पृष्ठभूमि:स्पिल स्तर
4000MB डेटा को सॉर्ट करने के कार्य पर विचार करें, जब हमारे पास केवल 500MB मेमोरी उपलब्ध हो। जाहिर है, हम एक बार में पूरे सेट को मेमोरी में सॉर्ट नहीं कर सकते, लेकिन हम टास्क को तोड़ सकते हैं:
हम पहले 500MB डेटा पढ़ते हैं, उस सेट को मेमोरी में सॉर्ट करते हैं, फिर परिणाम को डिस्क पर लिखते हैं। इसे कुल 8 बार करने से पूरे 4000MB इनपुट की खपत होती है, जिसके परिणामस्वरूप सॉर्ट किए गए डेटा के 8 सेट 500MB आकार के होते हैं। दूसरा चरण सॉर्ट किए गए डेटा सेट का 8-तरफ़ा मर्ज करना है। ध्यान दें कि एक मर्ज आवश्यक है, सेट का एक साधारण संयोजन नहीं है क्योंकि डेटा को केवल मध्यवर्ती चरण में एक विशेष 500एमबी सेट के भीतर आवश्यकतानुसार क्रमबद्ध करने की गारंटी है।
सिद्धांत रूप में, हम आठ प्रकार के रनों में से प्रत्येक से एक समय में एक पंक्ति को पढ़ और मर्ज कर सकते हैं, लेकिन यह बहुत कुशल नहीं होगा। इसके बजाय, हम प्रत्येक प्रकार के पहले भाग को मेमोरी में वापस चलाते हैं, कहते हैं 60MB। यह हमारे पास उपलब्ध 500MB में से 8 x 60MB =480MB की खपत करता है। फिर हम कुछ समय के लिए मेमोरी में 8-वे मर्ज को कुशलता से निष्पादित कर सकते हैं, अंतिम सॉर्ट किए गए आउटपुट को 20MB मेमोरी के साथ अभी भी उपलब्ध है। जैसे ही प्रत्येक प्रकार के रन मेमोरी बफ़र्स खाली होते हैं, हम उस प्रकार के एक नए खंड को मेमोरी में चलाते हैं। एक बार सभी प्रकार के रन का उपभोग हो जाने के बाद, सॉर्ट पूरा हो गया है।
कुछ अतिरिक्त विवरण और अनुकूलन हैं जिन्हें हम शामिल कर सकते हैं, लेकिन यह स्तर 1 स्पिल की मूल रूपरेखा है, जिसे सिंगल-पास स्पिल के रूप में भी जाना जाता है। अंतिम सॉर्ट किए गए आउटपुट का उत्पादन करने के लिए डेटा पर एक अतिरिक्त पास की आवश्यकता होती है।
अब, एक एन-वे मर्ज सैद्धांतिक रूप से किसी भी आकार के किसी भी आकार को, किसी भी मात्रा में स्मृति में समायोजित कर सकता है, बस मध्यवर्ती स्थानीय रूप से सॉर्ट किए गए सेटों की संख्या में वृद्धि करके। समस्या यह है कि जैसे-जैसे 'एन' बढ़ता है, हम डेटा के छोटे हिस्से को पढ़ना और लिखना समाप्त कर देते हैं। उदाहरण के लिए, 500MB मेमोरी में 400GB डेटा को सॉर्ट करने का मतलब 800-वे मर्ज जैसा कुछ होगा, किसी भी समय मेमोरी में प्रत्येक इंटरमीडिएट सॉर्ट किए गए सेट से केवल 0.6MB (800 x 0.6MB =480MB, एक के लिए कुछ जगह छोड़ना) आउटपुट बफर)।
इसके समाधान के लिए एकाधिक मर्ज पास का उपयोग किया जा सकता है। सामान्य विचार यह है कि जब तक हम कुशलतापूर्वक अंतिम क्रमबद्ध आउटपुट स्ट्रीम का उत्पादन नहीं कर लेते, तब तक छोटे टुकड़ों को बड़े पैमाने पर विलय करना है। उदाहरण में, इसका मतलब यह हो सकता है कि एक बार में 800 फर्स्ट-पास सॉर्ट किए गए सेटों में से 40 को मर्ज किया जाए, जिसके परिणामस्वरूप 20 बड़े चंक्स हों, जिन्हें आउटपुट बनाने के लिए फिर से मर्ज किया जा सकता है। डेटा पर कुल दो अतिरिक्त पास के साथ, यह एक स्तर 2 स्पिल होगा, और इसी तरह। सौभाग्य से, स्पिल स्तर में एक रैखिक वृद्धि सॉर्ट आकार में एक घातीय वृद्धि को सक्षम करती है, इसलिए डीप सॉर्ट स्पिल स्तर शायद ही कभी आवश्यक होते हैं।
"स्तर 15,000" फैल
इस बिंदु पर, आप सोच रहे होंगे कि छोटे मेमोरी ग्रांट और विशाल डेटा आकार के संयोजन के परिणामस्वरूप संभवतः 15,000 के स्तर पर क्या फैल सकता है। संपूर्ण इंटरनेट को 1MB मेमोरी में सॉर्ट करने का प्रयास कर रहे हैं? हो सकता है, लेकिन इसे प्रदर्शित करना बहुत कठिन है। ईमानदार होने के लिए, मुझे नहीं पता कि SQL सर्वर में वास्तव में उच्च स्पिल स्तर भी संभव है या नहीं। यहां लक्ष्य (एक धोखा, निश्चित रूप से) SQL सर्वर को रिपोर्ट . प्राप्त करना है स्तर 15,000 स्पिल।
मुख्य घटक विभाजन है। SQL सर्वर 2012 के बाद से, हमें प्रति ऑब्जेक्ट अधिकतम 15,000 विभाजन (सुविधाजनक) की अनुमति दी गई है (2008 SP2 और 2008 R2 SP1 पर 15,000 विभाजन के लिए समर्थन भी उपलब्ध है, लेकिन आपको इसे प्रति डेटाबेस मैन्युअल रूप से सक्षम करना होगा, और सभी के बारे में जागरूक रहना होगा। चेतावनी)।
पहली चीज जो हमें चाहिए वह है 15,000-तत्व विभाजन फ़ंक्शन और एक संबद्ध विभाजन योजना। वास्तव में विशाल इनलाइन कोड ब्लॉक से बचने के लिए, निम्न स्क्रिप्ट आवश्यक विवरण उत्पन्न करने के लिए गतिशील SQL का उपयोग करती है:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); यदि आपका सेटअप 15,000 विभाजनों के साथ संघर्ष करता है (विशेष रूप से स्मृति के दृष्टिकोण से, जैसा कि हम जल्द ही देखेंगे) स्क्रिप्ट को कम संख्या में संशोधित करना काफी आसान है। अगले चरण में एक पूर्णांक स्तंभ के साथ एक सामान्य (विभाजित नहीं) हीप तालिका बनाना है, और फिर इसे 1 से 15,000 तक के पूर्णांकों से भरना है:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; वह 100ms या तो में पूरा होना चाहिए। यदि आपके पास एक संख्या तालिका उपलब्ध है, तो अधिक सेट-आधारित अनुभव के लिए इसका उपयोग करने के लिए स्वतंत्र महसूस करें। जिस तरह से आधार तालिका आबाद है, वह महत्वपूर्ण नहीं है। हमारे 15,000 स्तर के स्पिल को प्राप्त करने के लिए, हमें केवल टेबल पर एक विभाजित क्लस्टर इंडेक्स बनाने की आवश्यकता है:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
निष्पादन का समय उपयोग में भंडारण प्रणाली पर बहुत निर्भर करता है। मेरे लैपटॉप पर, कुछ साल पहले एक काफी विशिष्ट उपभोक्ता एसएसडी का उपयोग करते हुए, इसमें लगभग 20 सेकंड लगते हैं, जो कि काफी महत्वपूर्ण है क्योंकि हम कुल मिलाकर केवल 15,000 पंक्तियों से निपट रहे हैं। बहुत ही भयानक I/O प्रदर्शन के साथ काफी कम-स्पेक Azure VM पर, उसी परीक्षण में लगभग 20 मिनट का समय लगा।
विश्लेषण
अनुक्रमणिका निर्माण के लिए निष्पादन योजना है:
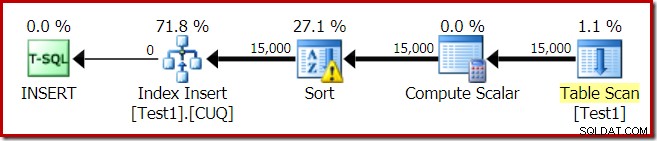
टेबल स्कैन हमारी हीप टेबल से 15,000 पंक्तियों को पढ़ता है। कंप्यूट स्केलर आंतरिक फ़ंक्शन RangePartitionNew() का उपयोग करके प्रत्येक पंक्ति के लिए गंतव्य अनुक्रमणिका विभाजन संख्या की गणना करता है . सॉर्ट योजना का सबसे दिलचस्प हिस्सा है, इसलिए हम इसे और अधिक विस्तार से देखेंगे।
सबसे पहले, क्रमबद्ध चेतावनी, जैसा कि प्लान एक्सप्लोरर में दिखाया गया है:

एसएसएमएस से एक समान चेतावनी (स्क्रिप्ट के एक अलग रन से ली गई):
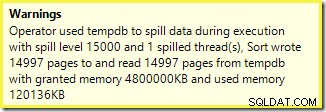
ध्यान देने वाली पहली बात यह है कि वादे के अनुसार 15,000 सॉर्ट स्पिल स्तर की रिपोर्ट है। यह पूरी तरह सटीक नहीं है, लेकिन विवरण काफी दिलचस्प हैं। इस योजना के क्रम में एक Partition ID है संपत्ति, जो सामान्य रूप से मौजूद नहीं है:
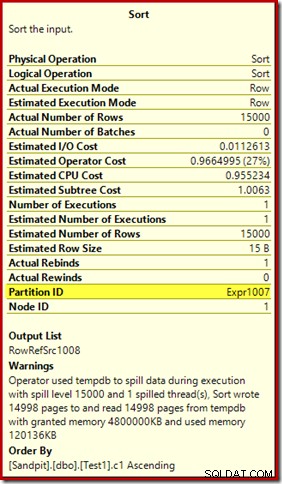
यह गुण कंप्यूट स्केलर में आंतरिक विभाजन फ़ंक्शन परिभाषा के बराबर सेट है।
यह एक गैर-संरेखित अनुक्रमणिका बिल्ड . है , क्योंकि स्रोत और गंतव्य में अलग-अलग विभाजन व्यवस्था है। इस मामले में, वह अंतर उत्पन्न होता है क्योंकि स्रोत ढेर तालिका विभाजित नहीं होती है, लेकिन गंतव्य अनुक्रमणिका होती है। परिणामस्वरूप, रनटाइम पर 15,000 अलग-अलग प्रकार बनाए जाते हैं:प्रति गैर-रिक्त लक्ष्य विभाजन के लिए एक। इनमें से प्रत्येक प्रकार स्तर 1 तक फैल जाता है, और SQL सर्वर इन सभी स्पिल को 15,000 के अंतिम सॉर्ट स्पिल स्तर देने के लिए जोड़ता है।
15,000 अलग-अलग प्रकार बड़े मेमोरी ग्रांट की व्याख्या करते हैं। प्रत्येक प्रकार के उदाहरण का न्यूनतम आकार 40 पृष्ठों का होता है, जो कि 40 x 8KB =320KB है। इसलिए 15,000 प्रकारों के लिए न्यूनतम 15,000 x 320KB =4,800,000KB मेमोरी की आवश्यकता होती है। यह केवल 4.6GB RAM की शर्मीली है जो विशेष रूप से एक क्वेरी के लिए आरक्षित है जो एक पूर्णांक कॉलम वाली 15,000 पंक्तियों को सॉर्ट करती है। और प्रत्येक प्रकार केवल एक पंक्ति प्राप्त करने के बावजूद डिस्क पर फैल जाता है! यदि अनुक्रमणिका निर्माण के लिए समांतरता का उपयोग किया जाता है, तो स्मृति अनुदान को धागे की संख्या से और बढ़ाया जा सकता है। यह भी ध्यान दें कि एकल पंक्ति एक पृष्ठ में लिखी जाती है, जो कि tempdb से लिखे और पढ़े जाने वाले पृष्ठों की संख्या की व्याख्या करती है। एक दौड़ की स्थिति प्रतीत होती है, जिसका अर्थ है कि पृष्ठों की रिपोर्ट की गई संख्या अक्सर 15,000 से कुछ कम होती है।
यह उदाहरण निश्चित रूप से एक किनारे के मामले को दर्शाता है, लेकिन यह समझना अभी भी कठिन है कि प्रत्येक प्रकार की स्मृति में क्रमबद्ध करने के बजाय अपनी एकल पंक्ति क्यों फैलती है। शायद यह किसी कारण से डिज़ाइन द्वारा है, या शायद यह केवल एक बग है। जो भी हो, 4.6GB मेमोरी ग्रांट और 15,000 के स्तर के स्पिल के साथ कुछ सौ KB डेटा को इतना लंबा समय लेते हुए देखना अभी भी काफी मनोरंजक है। जब तक आप इसे उत्पादन के माहौल में नहीं पाते, हो सकता है। वैसे भी, यह जागरूक होने वाली बात है।
भ्रामक 15,000 स्तर की स्पिल रिपोर्ट शो प्लान आउटपुट में प्रतिनिधित्व सीमाओं के लिए काफी नीचे आती है। मौलिक मुद्दा कुछ ऐसा है जो कई जगहों पर उत्पन्न होता है जहां बार-बार क्रियाएं होती हैं, उदाहरण के लिए नेस्टेड लूप के अंदरूनी हिस्से में शामिल होते हैं। इन मामलों में कुल योग के बजाय अधिक सटीक विश्लेषण देखने में सक्षम होना निश्चित रूप से उपयोगी होगा। समय के साथ, इस क्षेत्र में थोड़ा सुधार हुआ है, इसलिए अब हमारे पास कुछ कार्यों के लिए प्रति थ्रेड या प्रति विभाजन अधिक योजना जानकारी है। हालांकि अभी लंबा सफर तय करना है।
यह अभी भी मददगार से कम है कि 15,000 अलग-अलग स्तर 1 स्पिल को यहां एकल 15,000 स्तर स्पिल के रूप में रिपोर्ट किया गया है।
परीक्षण विविधताएं
यह आलेख विशेष उदाहरण संचालन को और अधिक कुशल बनाने के बारे में योजना की जानकारी सीमाओं और खराब प्रदर्शन की संभावना को उजागर करने के बारे में अधिक है, जब यह विशेष उदाहरण संचालन को और अधिक कुशल बनाने के बारे में है, लेकिन कुछ दिलचस्प बदलाव भी हैं जिन्हें मैं भी देखना चाहता हूं ।
ऑनलाइन, tempdb में क्रमित करें
ONLINE = ON, SORT_IN_TEMPDB = ON के साथ समान विभाजन अनुक्रमणिका निर्माण कार्य करना एक ही विशाल स्मृति अनुदान और स्पिलिंग से ग्रस्त नहीं है:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
ध्यान दें कि ONLINE . का उपयोग करके अपने आप में पर्याप्त नहीं है। वास्तव में, इसका परिणाम पहले की तरह ही सभी समान मुद्दों के साथ होता है, प्लस प्रत्येक अनुक्रमणिका विभाजन को ऑनलाइन बनाने के लिए एक अतिरिक्त ओवरहेड। मेरे लिए, इसका परिणाम एक मिनट से अधिक के निष्पादन समय में होता है। अच्छाई जानती है कि भयानक I/O प्रदर्शन के साथ कम-विशिष्ट Azure इंस्टेंस पर कितना समय लगेगा।
वैसे भी, निष्पादन योजना ONLINE = ON, SORT_IN_TEMPDB = ON के साथ है:

गंतव्य विभाजन संख्या की गणना से पहले सॉर्ट किया जाता है। इसमें विभाजन आईडी संपत्ति नहीं है, इसलिए यह सिर्फ एक सामान्य प्रकार है। पूरा ऑपरेशन लगभग दस सेकंड तक चलता है (अभी भी बहुत सारे विभाजन बनाने बाकी हैं)। यह 3MB से कम मेमोरी सुरक्षित रखता है, और अधिकतम 816KB का उपयोग करता है। 4.6GB और 15,000 स्पिल में काफी सुधार।
पहले इंडेक्स करें, फिर डेटा
डेटा को पहले हीप टेबल पर लिखकर इसी तरह के परिणाम प्राप्त किए जा सकते हैं:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; इसके बाद, एक खाली विभाजित क्लस्टर तालिका बनाएं और ढेर से डेटा डालें:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; 2MB मेमोरी ग्रांट और बिना किसी स्पिलिंग के, इसमें लगभग दस सेकंड लगते हैं:
बेशक, (अन-विभाजित) स्रोत तालिका को अनुक्रमणित करके, और अनुक्रमणिका क्रम में डेटा सम्मिलित करके सॉर्ट को पूरी तरह से टाला जा सकता है (सबसे अच्छा सॉर्ट कोई सॉर्ट नहीं है, याद रखें)।
विभाजित ढेर, फिर डेटा, फिर अनुक्रमणिका
इस अंतिम भिन्नता के लिए, हम पहले एक विभाजित ढेर बनाते हैं और 15,000 परीक्षण पंक्तियों को लोड करते हैं:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; वह स्क्रिप्ट एक या दो सेकंड के लिए चलती है, जो बहुत अच्छी है। अंतिम चरण विभाजित क्लस्टर इंडेक्स बनाना है:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
यह एक पूर्ण आपदा है, दोनों एक प्रदर्शन के दृष्टिकोण से, और एक शो योजना की जानकारी के दृष्टिकोण से। निम्नलिखित निष्पादन योजना के साथ, ऑपरेशन केवल एक मिनट से भी कम समय के लिए चलता है:

यह एक कोलोकेटेड इंसर्ट प्लान है। लगातार स्कैन में प्रत्येक पार्टीशन आईडी के लिए एक पंक्ति होती है। लूप का आंतरिक भाग ढेर के वर्तमान विभाजन की तलाश करता है (हाँ, ढेर पर एक खोज)। सॉर्ट में एक पार्टीशन आईडी प्रॉपर्टी होती है (यह प्रति लूप पुनरावृत्ति स्थिर होने के बावजूद) इसलिए प्रति विभाजन एक प्रकार और अवांछनीय स्पिलिंग व्यवहार होता है। हीप टेबल पर चेतावनी के आंकड़े नकली हैं।
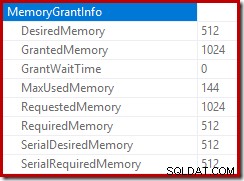
सम्मिलित योजना का मूल इंगित करता है कि 1MB का स्मृति अनुदान आरक्षित किया गया था, जिसमें अधिकतम 144KB का उपयोग किया गया था:
सॉर्ट ऑपरेटर स्तर 15,000 स्पिल की रिपोर्ट नहीं करता है, लेकिन अन्यथा शामिल प्रति-लूप पुनरावृत्ति गणित की पूरी गड़बड़ी करता है:

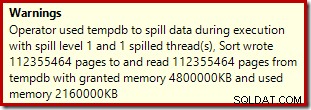
निष्पादन के दौरान स्मृति अनुदान DMV की निगरानी से पता चलता है कि यह क्वेरी वास्तव में केवल 1MB आरक्षित करती है, जिसमें लूप के प्रत्येक पुनरावृत्ति पर अधिकतम 144KB का उपयोग किया जाता है। (इसके विपरीत, पहले परीक्षण में 4.6GB मेमोरी आरक्षण बिल्कुल वास्तविक है।) यह निश्चित रूप से भ्रमित करने वाला है।
समस्या (जैसा कि पहले उल्लेख किया गया है) यह है कि SQL सर्वर इस बारे में भ्रमित हो जाता है कि कई पुनरावृत्तियों पर क्या हुआ, इसकी रिपोर्ट करना सबसे अच्छा है। प्रति विभाजन प्रति पुनरावृत्ति योजना प्रदर्शन जानकारी शामिल करना शायद व्यावहारिक नहीं है, लेकिन इस तथ्य से दूर नहीं है कि वर्तमान व्यवस्था कई बार भ्रमित परिणाम उत्पन्न करती है। हम केवल यह आशा कर सकते हैं कि इस प्रकार की जानकारी को अधिक सुसंगत प्रारूप में रिपोर्ट करने का एक बेहतर तरीका एक दिन मिल सकता है।