जनवरी 2015 में वापस, मेरे अच्छे दोस्त और साथी SQL सर्वर MVP रोब फ़ार्ले ने 2012 से पहले SQL सर्वर संस्करणों में माध्यिका खोजने की समस्या के लिए एक उपन्यास समाधान के बारे में लिखा था। साथ ही साथ एक दिलचस्प पढ़ा जा रहा है, यह पता चला है कुछ उन्नत निष्पादन योजना विश्लेषण प्रदर्शित करने के लिए और क्वेरी ऑप्टिमाइज़र और निष्पादन इंजन के कुछ सूक्ष्म व्यवहारों को उजागर करने के लिए उपयोग करने के लिए एक महान उदाहरण।
एकल माध्यक
हालांकि रॉब का लेख विशेष रूप से एक समूहीकृत माध्यिका गणना को लक्षित करता है, मैं उसकी पद्धति को एक बड़ी एकल माध्य गणना समस्या पर लागू करके शुरू करने जा रहा हूं, क्योंकि यह महत्वपूर्ण मुद्दों को सबसे स्पष्ट रूप से उजागर करता है। नमूना डेटा एक बार फिर आरोन बर्ट्रेंड के मूल लेख से आएगा:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); पर अद्वितीय क्लस्टर इंडेक्स cx बनाएं इस समस्या के लिए रोब फ़ार्ले की तकनीक को लागू करने से निम्नलिखित कोड मिलता है:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
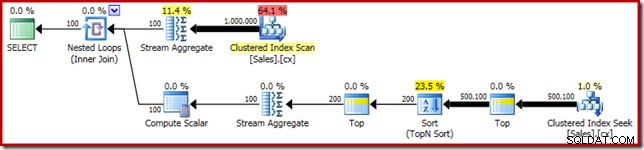
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); हमेशा की तरह, मैंने तालिका में पंक्तियों की संख्या गिनने पर टिप्पणी की है और प्रदर्शन भिन्नता के स्रोत से बचने के लिए इसे स्थिरांक से बदल दिया है। महत्वपूर्ण क्वेरी के लिए निष्पादन योजना इस प्रकार है:

यह क्वेरी 5800ms . तक चलती है मेरी परीक्षण मशीन पर।
द सॉर्ट स्पिल
इस खराब प्रदर्शन का प्राथमिक कारण उपरोक्त निष्पादन योजना को देखने से स्पष्ट होना चाहिए:सॉर्ट ऑपरेटर पर चेतावनी से पता चलता है कि अपर्याप्त कार्यस्थान स्मृति अनुदान ने भौतिक tempdb डिस्क:
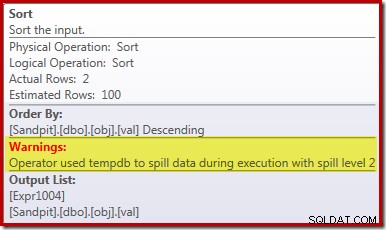
2012 से पहले SQL सर्वर के संस्करणों में, आपको इसे देखने के लिए सॉर्ट स्पिल इवेंट के लिए अलग से निगरानी करने की आवश्यकता होगी। वैसे भी, अपर्याप्त सॉर्ट मेमोरी आरक्षण कार्डिनैलिटी अनुमान त्रुटि के कारण होता है, जैसा कि पूर्व-निष्पादन (अनुमानित) योजना से पता चलता है:

सॉर्ट इनपुट पर 100-पंक्ति कार्डिनैलिटी अनुमान ऑप्टिमाइज़र द्वारा एक (बेहद गलत) अनुमान है, जो पूर्ववर्ती शीर्ष ऑपरेटर में स्थानीय चर अभिव्यक्ति के कारण है:

ध्यान दें कि यह कार्डिनैलिटी अनुमान त्रुटि एक पंक्ति-लक्ष्य समस्या नहीं है। ट्रेस फ़्लैग 4138 लागू करने से पहले शीर्ष के नीचे पंक्ति-लक्ष्य प्रभाव निकल जाएगा, लेकिन शीर्ष-पश्चात अनुमान अभी भी 100-पंक्ति अनुमान होगा (इसलिए सॉर्ट के लिए स्मृति आरक्षण अभी भी बहुत छोटा होगा):

स्थानीय चर के मान को इंगित करना
ऐसे कई तरीके हैं जिनसे हम इस कार्डिनैलिटी आकलन समस्या का समाधान कर सकते हैं। एक विकल्प यह है कि ऑप्टिमाइज़र को वैरिएबल में रखे गए मान के बारे में जानकारी प्रदान करने के लिए संकेत का उपयोग किया जाए:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); संकेत का उपयोग करने से प्रदर्शन में सुधार होता है 3250ms 5800ms. . से निष्पादन के बाद की योजना से पता चलता है कि छँटाई अब फैलती नहीं है:

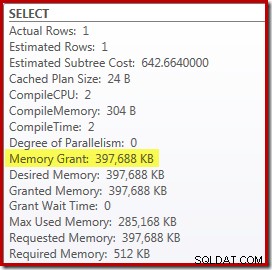
हालांकि इसमें कुछ कमियां भी हैं। सबसे पहले, इस नई निष्पादन योजना के लिए 388MB . की आवश्यकता है स्मृति अनुदान - स्मृति जो अन्यथा सर्वर द्वारा योजनाओं, अनुक्रमित और डेटा को कैश करने के लिए उपयोग की जा सकती है:
दूसरा, संकेत के लिए एक अच्छी संख्या चुनना मुश्किल हो सकता है जो भविष्य के सभी निष्पादनों के लिए अच्छी तरह से काम करेगा, बिना अनावश्यक रूप से स्मृति को जमा किए।
यह भी ध्यान दें कि स्पिल को पूरी तरह से खत्म करने के लिए हमें वेरिएबल के लिए एक मान का संकेत देना था जो वैरिएबल के वास्तविक मूल्य से 10% अधिक है। यह असामान्य नहीं है, क्योंकि सामान्य सॉर्टिंग एल्गोरिदम एक साधारण इन-प्लेस सॉर्ट की तुलना में अधिक जटिल है। सॉर्ट किए जाने वाले सेट के आकार के बराबर मेमोरी को आरक्षित करना हमेशा (या आम तौर पर भी) रनटाइम पर स्पिल से बचने के लिए पर्याप्त नहीं होगा।
एम्बेड करना और फिर से कंपाइल करना
एक अन्य विकल्प SQL Server 2008 SP1 CU5 या बाद के संस्करण पर क्वेरी-स्तरीय पुनर्संकलन संकेत जोड़कर सक्षम किए गए पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन का लाभ उठाना है। यह क्रिया ऑप्टिमाइज़र को वेरिएबल के रनटाइम मान को देखने और उसके अनुसार अनुकूलित करने की अनुमति देगी:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
यह निष्पादन समय को 3150ms . तक सुधारता है - OPTIMIZE FOR . का उपयोग करने से 100ms बेहतर संकेत देना। इसके और छोटे सुधार का कारण नई पोस्ट-निष्पादन योजना से पहचाना जा सकता है:

व्यंजक (2 – @Count % 2) - जैसा कि पहले दूसरे टॉप ऑपरेटर में देखा गया था - अब इसे एक ही ज्ञात मान में मोड़ा जा सकता है। एक पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन शीर्ष को सॉर्ट के साथ जोड़ सकता है, जिसके परिणामस्वरूप एकल टॉप एन सॉर्ट होता है। यह पुनर्लेखन पहले संभव नहीं था क्योंकि टॉप + सॉर्ट को टॉप एन सॉर्ट में संक्षिप्त करना केवल एक स्थिर शाब्दिक शीर्ष मान (चर या पैरामीटर नहीं) के साथ काम करता है।
टॉप एन सॉर्ट के साथ टॉप और सॉर्ट को बदलने से प्रदर्शन पर थोड़ा लाभकारी प्रभाव पड़ता है (यहां 100ms), लेकिन यह लगभग पूरी तरह से मेमोरी की आवश्यकता को समाप्त कर देता है, क्योंकि टॉप एन सॉर्ट को केवल एन उच्चतम (या निम्नतम) का ट्रैक रखना होता है। पंक्तियाँ, बजाय पूरे सेट। एल्गोरिथम में इस परिवर्तन के परिणामस्वरूप, इस क्वेरी के लिए निष्पादन के बाद की योजना से पता चलता है कि न्यूनतम 1MB मेमोरी इस योजना में शीर्ष एन सॉर्ट के लिए आरक्षित थी, और केवल 16KB रनटाइम पर उपयोग किया गया था (याद रखें, पूर्ण-क्रम योजना के लिए 388MB की आवश्यकता है):
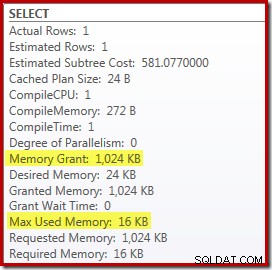
पुनर्संकलन से बचना
पुन:संकलित क्वेरी संकेत का उपयोग करने का (स्पष्ट) दोष यह है कि इसे प्रत्येक निष्पादन पर पूर्ण संकलन की आवश्यकता होती है। इस मामले में, ओवरहेड बहुत छोटा है - लगभग 1ms CPU समय और 272KB मेमोरी। फिर भी, क्वेरी को इस तरह से संशोधित करने का एक तरीका है कि हमें बिना किसी संकेत का उपयोग किए, और बिना पुन:संकलन के शीर्ष एन सॉर्ट का लाभ मिलता है।
यह विचार यह मानने से आता है कि एक अधिकतम अंतिम माध्यिका गणना के लिए दो पंक्तियों की आवश्यकता होगी। यह एक पंक्ति हो सकती है, या यह रनटाइम पर दो हो सकती है, लेकिन यह कभी भी अधिक नहीं हो सकती है। इस अंतर्दृष्टि का अर्थ है कि हम तार्किक रूप से अनावश्यक शीर्ष (2) मध्यवर्ती चरण को क्वेरी में निम्नानुसार जोड़ सकते हैं:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); नया शीर्ष (सभी महत्वपूर्ण निरंतर शाब्दिक के साथ) का अर्थ है कि अंतिम निष्पादन योजना में वांछित टॉप एन सॉर्ट ऑपरेटर को पुन:संकलित किए बिना दिखाया गया है:

इस निष्पादन योजना का प्रदर्शन 3150ms पर पुन:संकलित-संकेतित संस्करण से अपरिवर्तित है और स्मृति आवश्यकता समान है। ध्यान दें कि पैरामीटर एम्बेडिंग की कमी का मतलब है कि क्रम के नीचे कार्डिनैलिटी अनुमान 100-पंक्ति अनुमान हैं (हालांकि यह यहां प्रदर्शन को प्रभावित नहीं करता है)।
इस स्तर पर मुख्य बात यह है कि यदि आप एक कम-मेमोरी टॉप एन सॉर्ट चाहते हैं, तो आपको एक निरंतर शाब्दिक का उपयोग करना होगा, या ऑप्टिमाइज़र को पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन के माध्यम से एक शाब्दिक देखने के लिए सक्षम करना होगा।
द कंप्यूट स्केलर
388MB . को हटा रहा है स्मृति अनुदान (100ms के प्रदर्शन में सुधार करते हुए) निश्चित रूप से सार्थक है, लेकिन एक बहुत बड़ी प्रदर्शन जीत उपलब्ध है। इस अंतिम सुधार का संभावित लक्ष्य क्लस्टर्ड इंडेक्स स्कैन के ठीक ऊपर कंप्यूट स्केलर है।
यह गणना स्केलर अभिव्यक्ति से संबंधित है (0E + f.val) AVG . में निहित है क्वेरी में कुल। यदि यह आपको अजीब लगे, तो औसत गणना में पूर्णांक अंकगणित से बचने के लिए यह एक काफी सामान्य क्वेरी-लेखन ट्रिक (जैसे 1.0 से गुणा करना) है, लेकिन इसके कुछ बहुत ही महत्वपूर्ण दुष्प्रभाव हैं।
यहाँ घटनाओं का एक विशेष क्रम है जिसका हमें चरण दर चरण अनुसरण करने की आवश्यकता है।
सबसे पहले, ध्यान दें कि 0E फ्लोट . के साथ एक निरंतर शाब्दिक शून्य है डेटा प्रकार। इसे पूर्णांक कॉलम वैल में जोड़ने के लिए, क्वेरी प्रोसेसर को कॉलम को पूर्णांक से फ्लोट में बदलना होगा (डेटा प्रकार वरीयता नियमों के अनुसार)। एक समान प्रकार का रूपांतरण आवश्यक होगा यदि हमने कॉलम को 1.0 से गुणा करने के लिए चुना था (एक निहित संख्यात्मक डेटा प्रकार के साथ एक शाब्दिक)। महत्वपूर्ण बात यह है कि यह नियमित चाल एक अभिव्यक्ति पेश करती है ।
अब, SQL सर्वर आम तौर पर अभिव्यक्तियों को नीचे धकेलने का प्रयास करता है संकलन और अनुकूलन के दौरान जहाँ तक संभव हो योजना वृक्ष। यह कई कारणों से किया जाता है, जिसमें गणना किए गए कॉलम के साथ मिलान अभिव्यक्ति को आसान बनाना, और बाधा जानकारी का उपयोग करके सरलीकरण की सुविधा प्रदान करना शामिल है। यह पुश-डाउन नीति बताती है कि कंप्यूट स्केलर योजना के लीफ स्तर के बहुत करीब क्यों दिखाई देता है, जबकि क्वेरी में अभिव्यक्ति की मूल टेक्स्ट स्थिति का सुझाव होगा।
इस पुश-डाउन को करने का जोखिम यह है कि अभिव्यक्ति की गणना आवश्यकता से अधिक बार की जा सकती है। ज्वॉइन्स, एग्रीगेशन और फिल्टर्स के प्रभाव के कारण, अधिकांश प्लान्स में कम करने वाली रो काउंट की सुविधा होती है, क्योंकि हम प्लान ट्री को ऊपर ले जाते हैं। अभिव्यक्ति को पेड़ से नीचे धकेलने से उन भावों का मूल्यांकन आवश्यकता से अधिक बार (यानी अधिक पंक्तियों में) करने का जोखिम होता है।
इसे कम करने के लिए, SQL Server 2005 ने एक अनुकूलन पेश किया जिससे कंप्यूट स्केलर्स बस परिभाषित कर सकते हैं एक अभिव्यक्ति, वास्तव में मूल्यांकन . के काम के साथ अभिव्यक्ति स्थगित जब तक योजना में बाद के ऑपरेटर को परिणाम की आवश्यकता न हो। जब यह अनुकूलन उद्देश्य के अनुसार काम करता है, तो प्रभाव अभिव्यक्ति को पेड़ के नीचे धकेलने के सभी लाभों को प्राप्त करना है, जबकि अभी भी वास्तव में अभिव्यक्ति का वास्तव में जितनी बार आवश्यकता है उतनी बार मूल्यांकन करना है।
इस कंप्यूट स्केलर सामग्री का क्या अर्थ है
हमारे चल रहे उदाहरण में, 0E + val अभिव्यक्ति मूल रूप से AVG . से संबद्ध थी एग्रीगेट, इसलिए हम इसे स्ट्रीम एग्रीगेट पर (या थोड़ा बाद में) देखने की उम्मीद कर सकते हैं। हालांकि, इस अभिव्यक्ति को नीचे धकेल दिया गया [Expr1004] के रूप में लेबल किए गए व्यंजक के साथ स्कैन के ठीक बाद एक नया कंप्यूट स्केलर बनने के लिए पेड़।
निष्पादन योजना को देखते हुए, हम देख सकते हैं कि [Expr1004] स्ट्रीम एग्रीगेट द्वारा संदर्भित है (प्लान एक्सप्लोरर एक्सप्रेशंस टैब एक्सट्रैक्ट नीचे दिखाया गया है):

सभी चीजें समान होने पर, अभिव्यक्ति का मूल्यांकन [Expr1004] स्थगित . होगा जब तक कि कुल को औसत गणना के योग भाग के लिए उन मानों की आवश्यकता न हो। चूंकि समुच्चय केवल एक या दो पंक्तियों का ही सामना कर सकता है, इसके परिणामस्वरूप [Expr1004] का मूल्यांकन केवल एक या दो बार किया जाना चाहिए:
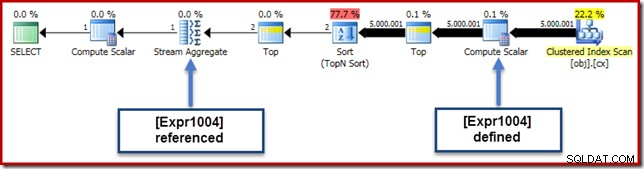
दुर्भाग्य से, यह बिल्कुल नहीं है कि यह यहाँ कैसे काम करता है। समस्या ब्लॉकिंग सॉर्ट ऑपरेटर है:
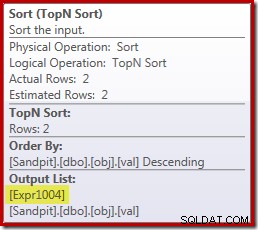
यह [Expr1004] का मूल्यांकन करने के लिए बाध्य करता है, इसलिए स्ट्रीम एग्रीगेट पर केवल एक या दो बार मूल्यांकन किए जाने के बजाय, सॉर्ट का अर्थ है कि हम val को परिवर्तित कर देते हैं। एक फ्लोट में कॉलम और उसमें शून्य जोड़ना 5,000,001 बार!
एक समाधान
आदर्श रूप से, SQL सर्वर इस सब के बारे में थोड़ा अधिक स्मार्ट होगा, लेकिन ऐसा नहीं है कि यह आज कैसे काम करता है। अभिव्यक्तियों को योजना ट्री से नीचे धकेलने से रोकने के लिए कोई क्वेरी संकेत नहीं है, और हम कंप्यूट स्केलर्स को प्लान गाइड के साथ भी बाध्य नहीं कर सकते हैं। अनिवार्य रूप से, एक अनिर्दिष्ट ट्रेस ध्वज है, लेकिन यह ऐसा नहीं है जिसके बारे में मैं वर्तमान संदर्भ में जिम्मेदारी से बात कर सकता हूं।
इसलिए, बेहतर या बदतर के लिए, यह हमें एक क्वेरी पुनर्लेखन खोजने की कोशिश के साथ छोड़ देता है जो SQL सर्वर को अभिव्यक्ति को कुल से अलग करने और क्वेरी के परिणाम को बदले बिना, इसे सॉर्ट से नीचे धकेलने से रोकता है। यह उतना आसान नहीं है जितना आप सोच सकते हैं, लेकिन नीचे दिया गया (निश्चित रूप से थोड़ा अजीब दिखने वाला) संशोधन CASE का उपयोग करके इसे प्राप्त करता है एक गैर-नियतात्मक आंतरिक कार्य पर अभिव्यक्ति:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); क्वेरी के इस अंतिम रूप के लिए निष्पादन योजना नीचे दिखाई गई है:

ध्यान दें कि एक कंप्यूट स्केलर अब क्लस्टर्ड इंडेक्स स्कैन और शीर्ष के बीच प्रकट नहीं होता है। 0E + val अभिव्यक्ति की गणना अब स्ट्रीम एग्रीगेट पर अधिकतम दो पंक्तियों (पांच मिलियन के बजाय!) पर की जाती है और प्रदर्शन में 32% और बढ़ जाता है 3150ms से 2150ms . तक परिणामस्वरूप।
यह अभी भी OFFSET . के उप-सेकंड प्रदर्शन के साथ उस कुएं की तुलना नहीं करता है और गतिशील कर्सर माध्यिका-गणना समाधान, लेकिन यह अभी भी मूल 5800ms पर एक बहुत ही महत्वपूर्ण सुधार का प्रतिनिधित्व करता है इस पद्धति के लिए एक बड़ी एकल-माध्यिका समस्या सेट पर।
CASE ट्रिक निश्चित रूप से भविष्य में काम करने की गारंटी नहीं है। टेकअवे अजीब केस एक्सप्रेशन ट्रिक्स का उपयोग करने के बारे में इतना नहीं है, क्योंकि यह कंप्यूट स्केलर्स के संभावित प्रदर्शन प्रभावों के बारे में है। एक बार जब आप इस तरह की चीज़ों के बारे में जान जाते हैं, तो आप 1.0 से गुणा करने या औसत गणना के अंदर फ्लोट शून्य जोड़ने से पहले दो बार सोच सकते हैं।
अपडेट करें: कृपया रॉबर्ट हेनिग द्वारा एक अच्छे समाधान के लिए पहली टिप्पणी देखें जिसके लिए किसी भी अनिर्दिष्ट प्रवंचना की आवश्यकता नहीं है। जब आप अगली बार किसी पूर्णांक को दशमलव (या फ़्लोट) से गुणा करने का प्रयास करते हैं, तो उसे ध्यान में रखना चाहिए।
समूहीकृत माध्यिका
पूर्णता के लिए, और इस विश्लेषण को रॉब के मूल लेख से अधिक निकटता से जोड़ने के लिए, हम समूहीकृत माध्य गणना में समान सुधारों को लागू करके समाप्त करेंगे। छोटे सेट आकार (प्रति समूह) का मतलब है कि प्रभाव निश्चित रूप से छोटे होंगे।
समूहीकृत औसत नमूना डेटा (फिर से मूल रूप से हारून बर्ट्रेंड द्वारा बनाया गया) में एक सौ काल्पनिक बिक्री लोगों में से प्रत्येक के लिए दस हजार पंक्तियां शामिल हैं:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); रोब फ़ार्ले के समाधान को सीधे लागू करने से निम्नलिखित कोड मिलता है, जो 560ms . में निष्पादित होता है मेरी मशीन पर।
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); निष्पादन योजना में एकल माध्यिका से स्पष्ट समानताएँ हैं:
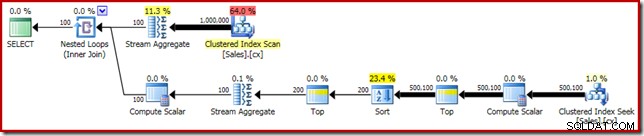
हमारा पहला सुधार एक स्पष्ट शीर्ष (2) जोड़कर सॉर्ट को टॉप एन सॉर्ट से बदलना है। यह निष्पादन समय को 560ms से थोड़ा सुधार कर 550ms . कर देता है ।
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); निष्पादन योजना उम्मीद के मुताबिक शीर्ष एन सॉर्ट दिखाती है:
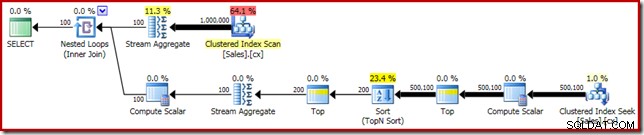
अंत में, हम पुश किए गए कंप्यूट स्केलर एक्सप्रेशन को हटाने के लिए विषम-दिखने वाले CASE एक्सप्रेशन को तैनात करते हैं। इससे प्रदर्शन में और सुधार होता है 450ms (मूल से 20% सुधार):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); तैयार निष्पादन योजना इस प्रकार है: