इस श्रृंखला के भाग 1 में, हमने अपने ऑनलाइन डेटाबेस मॉडलिंग टूल में SuiteCRM डेटाबेस संरचना को सफलतापूर्वक आयात किया। तभी हमने देखा कि मॉडल में 201 टेबल हैं, जिनके बीच कोई संबंध नहीं है। हमें टेबल का एक जंगली गुच्छा मिला जो वास्तव में गन्दा लग रहा था। इस लेख में, मैं आपको दिखाऊंगा कि आप इतने बड़े मॉडल को कैसे व्यवस्थित कर सकते हैं।
Vertabelo में आयात करने के ठीक बाद, SuiteCRM डेटाबेस मॉडल इस प्रकार दिखता है:
मॉडल काम करता है - लेकिन कुशलता से नहीं। हमें इसे वास्तव में उपयोगी बनाने के लिए इसे संशोधित करने की आवश्यकता होगी। चूँकि हम बाद . SuiteCRM डेटाबेस का विश्लेषण करना चाहते हैं इसके GUI पर क्रियाएं की जाती हैं, हमें तालिका परिभाषाओं और तालिकाओं के बीच संबंधों को समझने की आवश्यकता है। आइए तालिकाओं को विषय क्षेत्रों में समूहीकृत करके और सबसे महत्वपूर्ण संबंध स्थापित करके प्रारंभ करें।
वर्टाबेलो आपको बड़े आरेखों को व्यवस्थित करने में मदद करने के लिए तीन मुख्य उपकरण प्रदान करता है:
- विषय क्षेत्र
- टेबल और शॉर्टकट देखें
- संदर्भ शॉर्टकट
मैं इस लेख में बाद में उनका वर्णन करूंगा, लेकिन आप इस वीडियो को देखकर और भी जान सकते हैं।
चरण 1. विदेशी कुंजियों के स्वचालित निर्माण को अक्षम करें
सबसे पहले, हम विदेशी कुंजियों की स्वचालित पीढ़ी को अक्षम कर देंगे। जब हम प्राथमिक तालिका से संदर्भित तालिका में संबंध खींचते हैं, तो डिफ़ॉल्ट रूप से, वर्टाबेलो विदेशी कुंजी विशेषताएँ उत्पन्न करता है। यह आमतौर पर एक अच्छी बात है, लेकिन यहां नहीं। हमारे पास पहले से ही विशेषताएँ हैं जो विदेशी कुंजियों का प्रतिनिधित्व करती हैं। हमारे पास तालिकाओं के बीच "वास्तविक" संबंधों की कमी है। इस विकल्प को बंद करने के लिए, “मेरा खाता” . पर क्लिक करें शीर्ष मेनू में और “व्यक्तिगत प्राथमिकताएं” . ढूंढें अनुभाग।
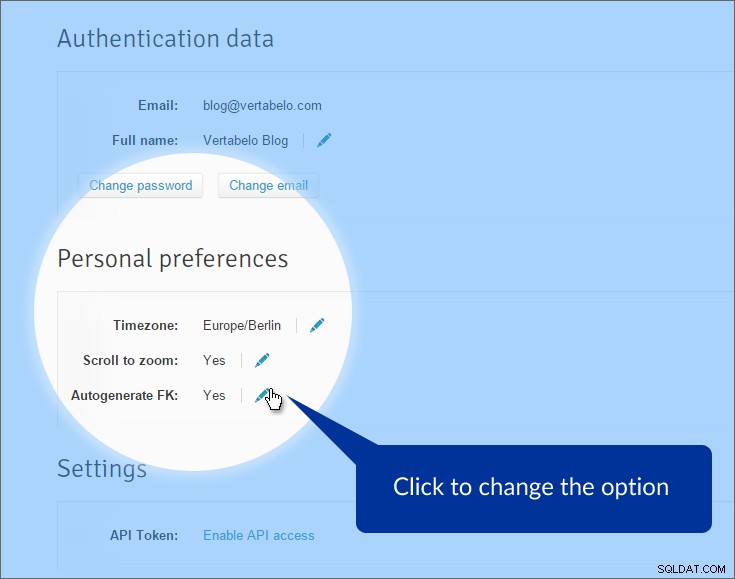
विकल्प बंद है। अब, जब हम तालिकाओं के बीच एक संदर्भ रेखा खींचते हैं, तो रेखा बन जाती है - लेकिन हमें यह निर्दिष्ट करना होगा कि प्राथमिक और विदेशी दोनों पक्षों पर कौन सी विशेषताओं का उपयोग किया जाता है।
चरण 2. विषय क्षेत्रों के साथ समूह उपसर्ग तालिकाएं
अगला, आइए कुछ तालिकाओं को समूहित करें। हम इसे विषय क्षेत्र . का उपयोग करके करेंगे उपकरण जो चयनित मानदंडों के आधार पर तालिकाओं को संबद्ध करने देता है। हमारे मामले में, हम उन तालिकाओं की पहचान करने का प्रयास कर रहे हैं जो या तो संबंधित हैं या उसी प्रक्रिया का हिस्सा हैं। इसके परिणामस्वरूप "कॉल", "मीटिंग" और "अभियान" जैसे समूह होंगे।
हम “नया क्षेत्र जोड़ें” . क्लिक करके विषय क्षेत्र बना सकते हैं टूलबॉक्स में आइकन:
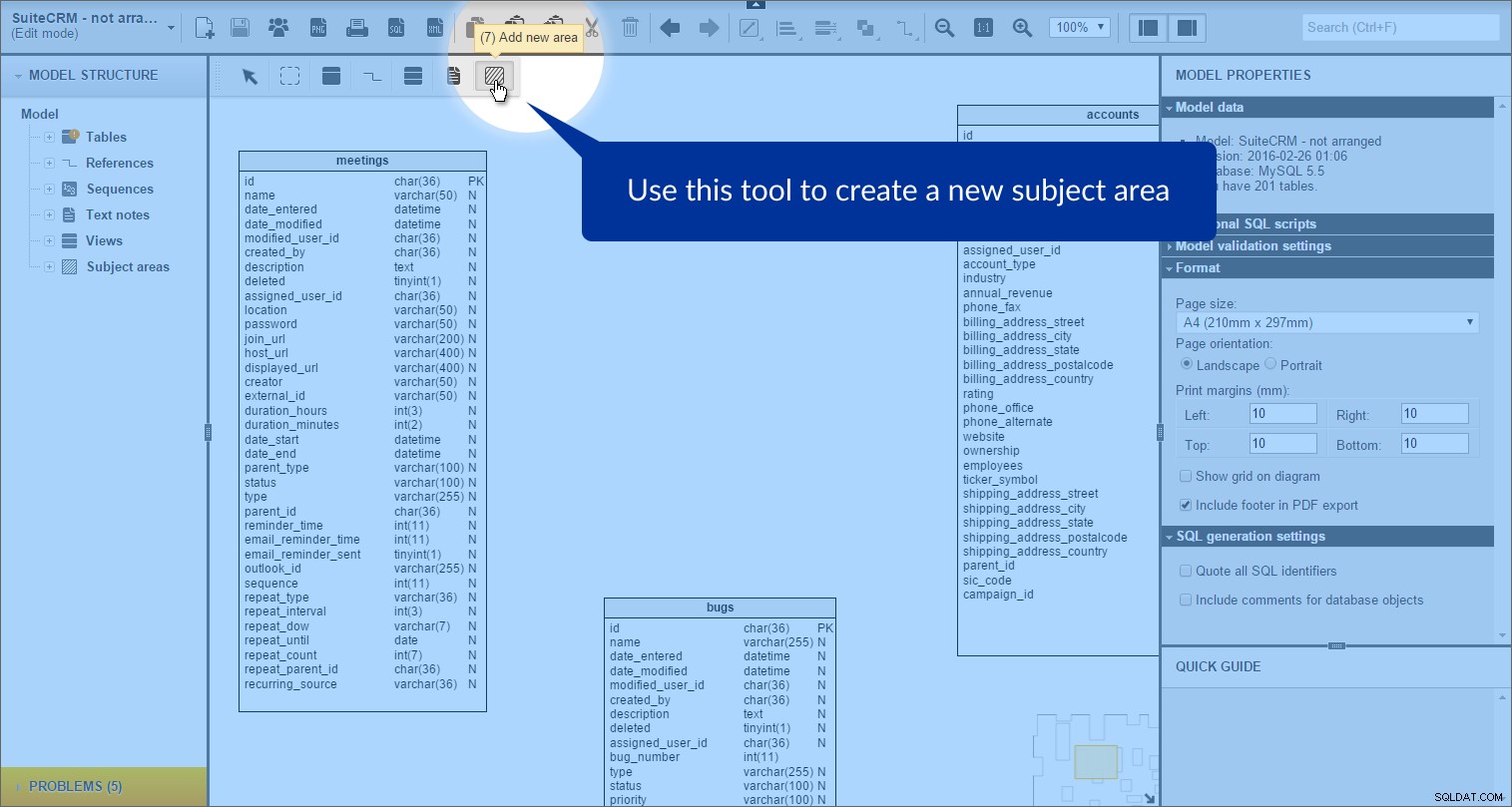
और फिर हमारे मॉडल पर एक आयत बनाना:
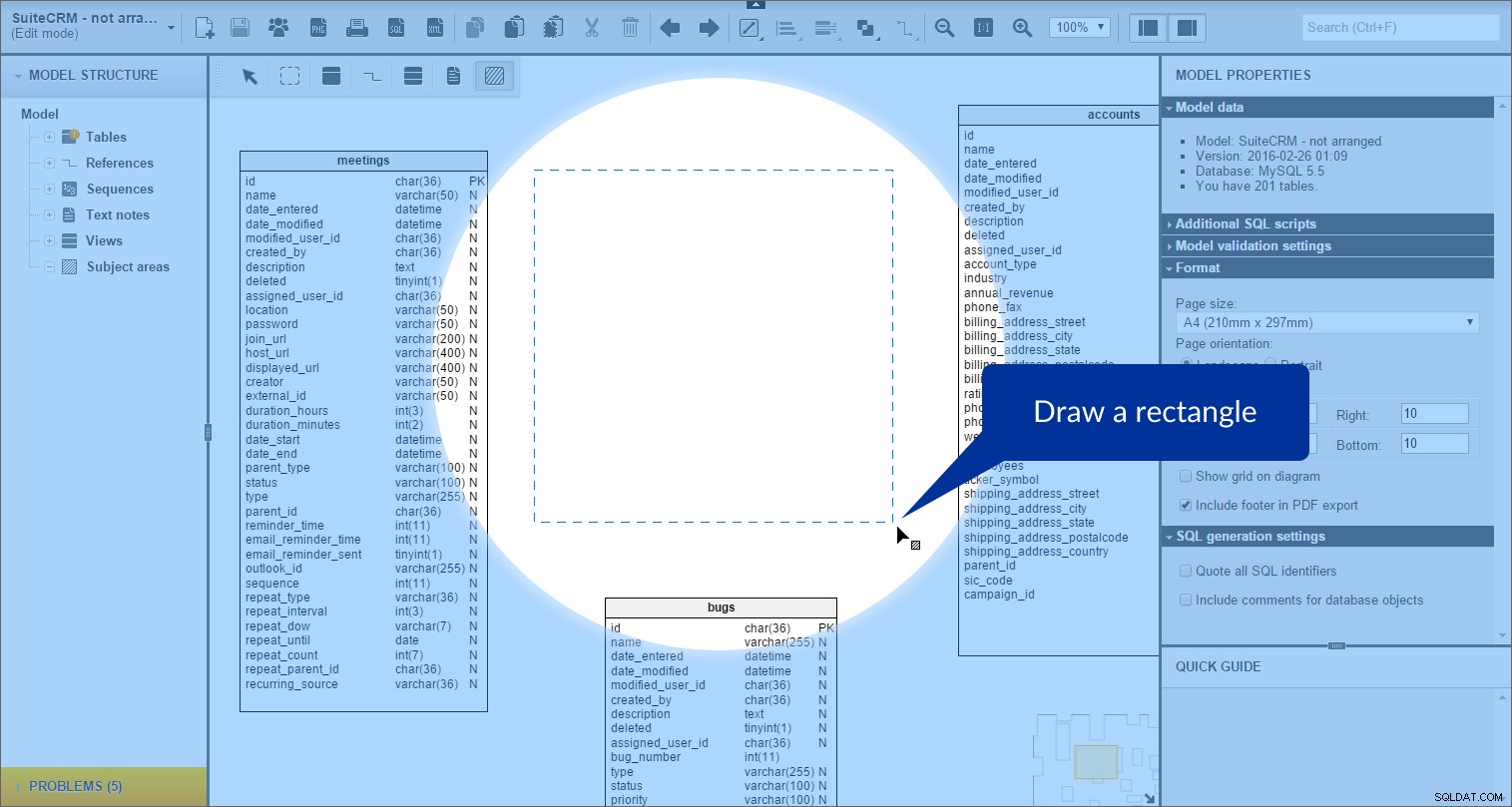
विषय क्षेत्र बनाया गया है। हम इसे “मॉडल संरचना” . में देख सकते हैं बाईं ओर पैनल:
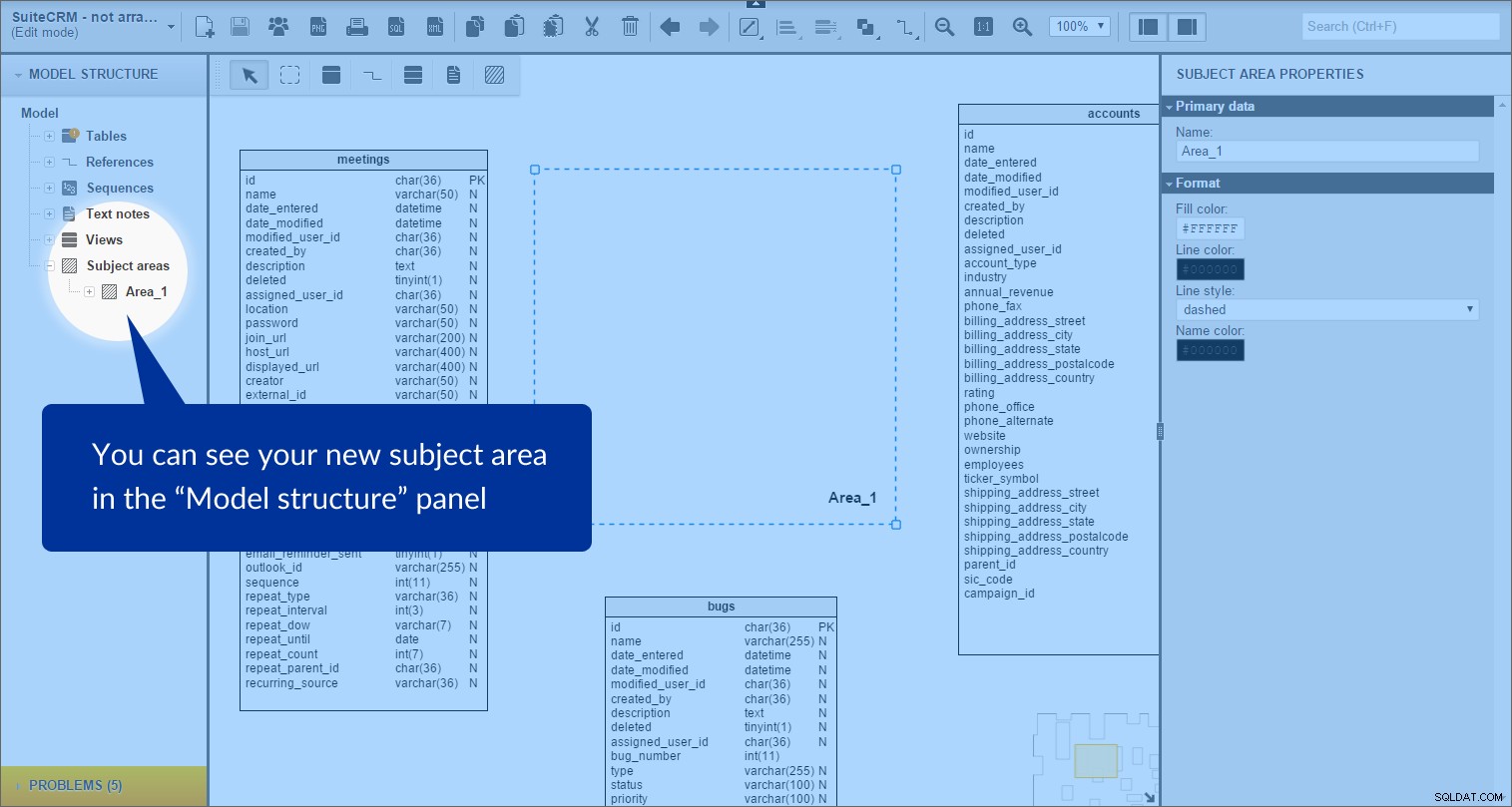
प्रत्येक विषय क्षेत्र में उन सभी वस्तुओं की एक सूची होती है जो इसकी सीमाओं के अंदर होती हैं; इस मामले में, ये टेबल और संदर्भ प्रकार हैं।
सुइटसीआरएम में, कई टेबल हैं जो एक सामान्य उपसर्ग साझा करते हैं। इसलिए, मैंने उपसर्ग वाली तालिकाओं को एक साथ समूहीकृत करना शुरू कर दिया। एक उदाहरण के रूप में "एसीएल" तालिकाओं पर एक नज़र डालें। “मॉडल संरचना” पैनल में, मुझे वे सभी तालिकाएँ मिलीं जिनके नाम “acl_” से शुरू हुए थे:
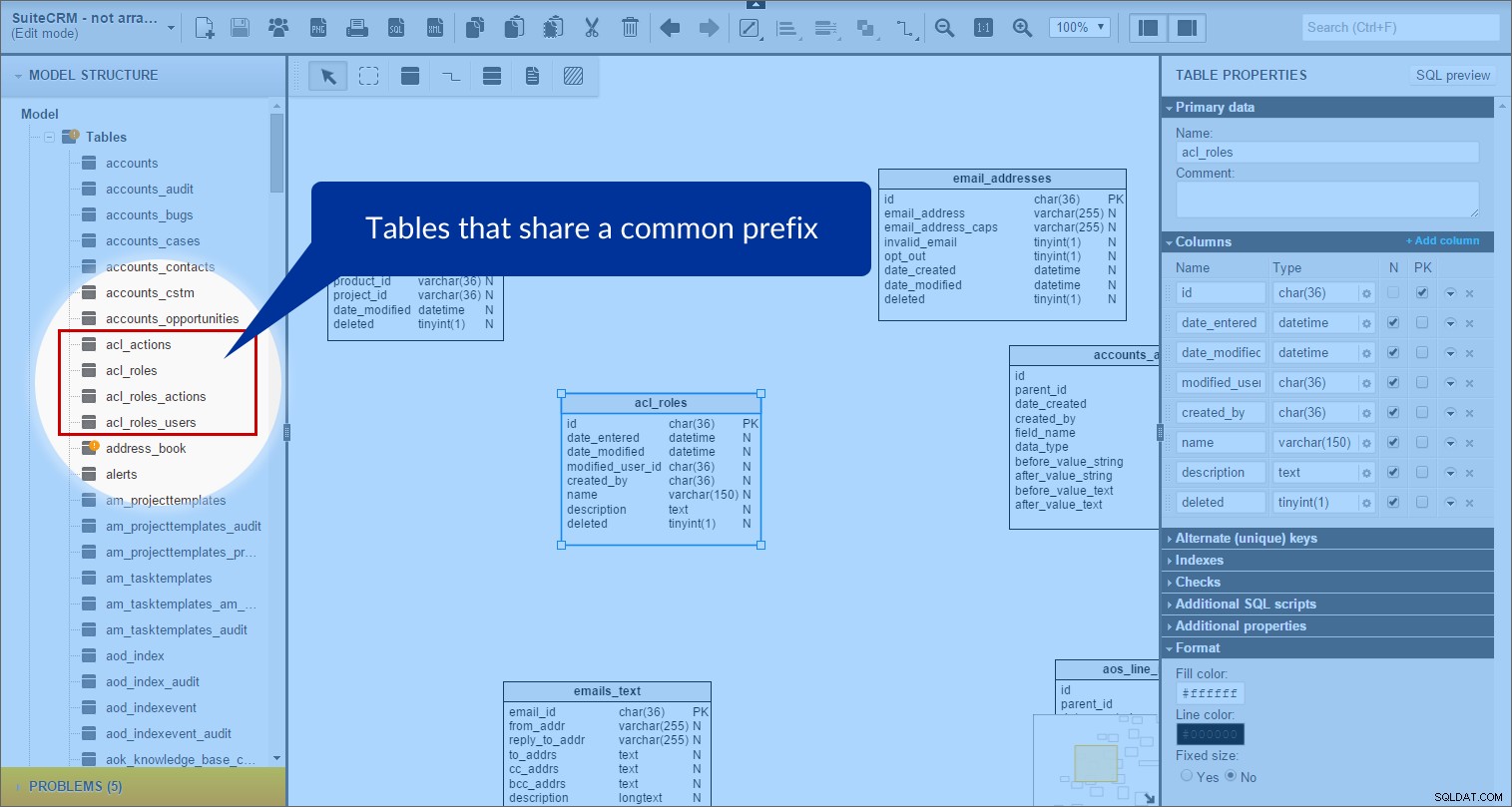
फिर मैंने मॉडल में "एसीएल" विषय क्षेत्र बनाया और उसमें सभी उपयुक्त तालिकाओं को खींच लिया। (बेहतर दृश्यता के लिए, मैंने पृष्ठभूमि का रंग बैंगनी पर सेट किया है।)
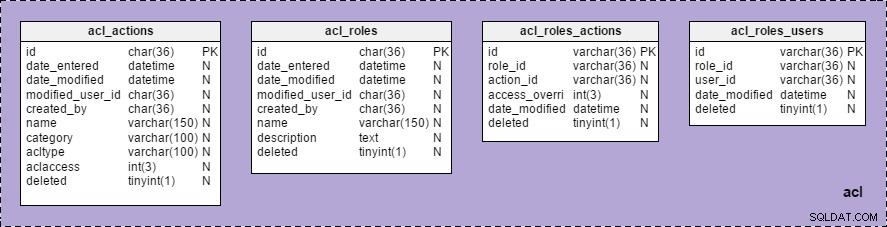
अब, अब हम “विषय क्षेत्र” के अंतर्गत, “एसीएल” समूह को, उससे संबंधित सभी तालिकाओं की सूची के साथ देख सकते हैं “मॉडल संरचना” . में :
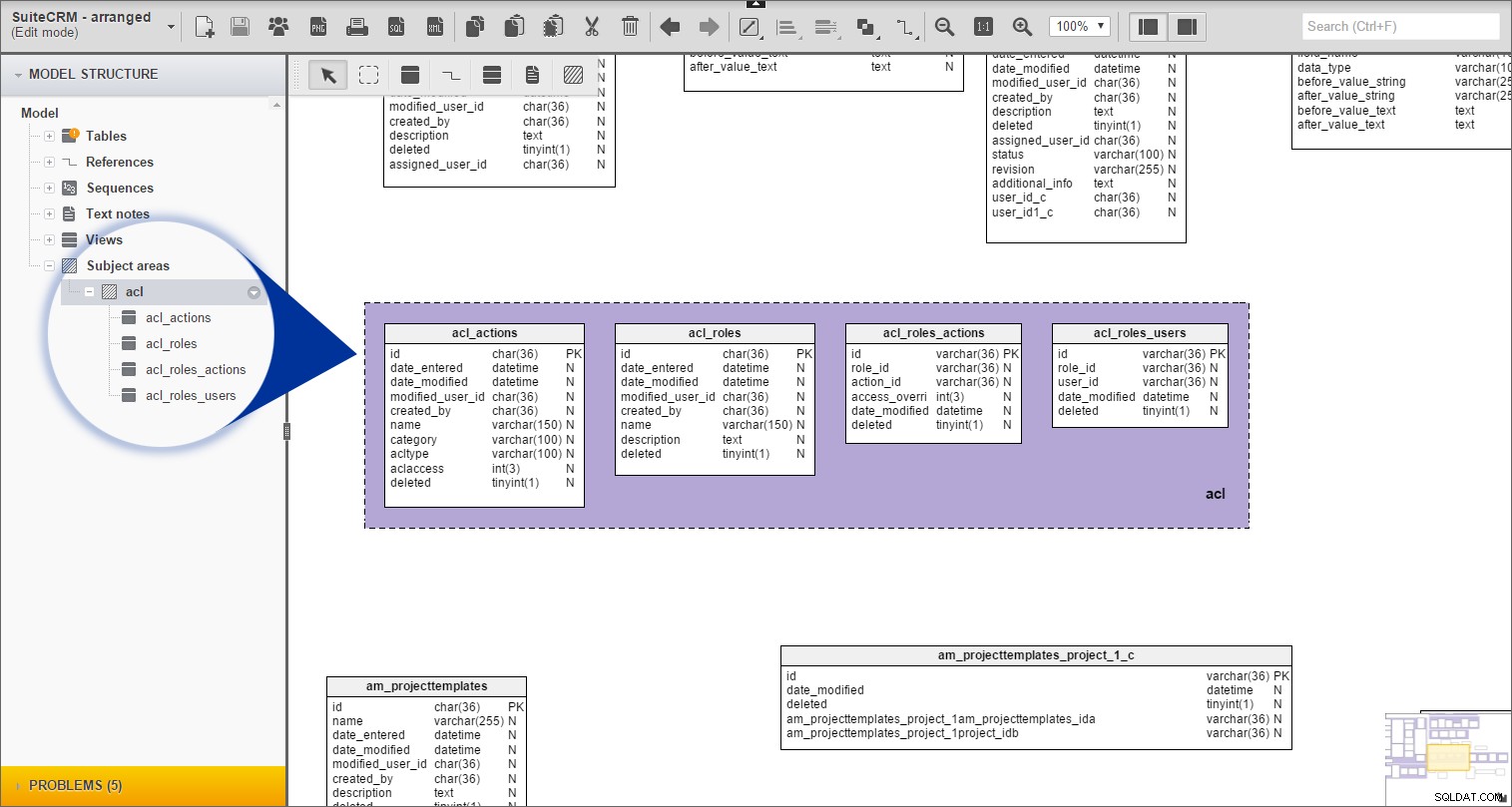
मैंने बाकी सभी प्रीफिक्स्ड टेबल के लिए भी यही प्रक्रिया दोहराई है।
चरण 3:शेष तालिकाओं को व्यवस्थित करें।
आरेख में एक ही तालिका दो बार? टेबल शॉर्टकट!
लगभग 80 प्रीफिक्स्ड टेबल हैं। उन्हें समूहबद्ध करने के बाद, मेरे पास लगभग 120 'जंगली' टेबल रह गए। ये अर्थपूर्ण हैं:वे उपयोगकर्ताओं, क्लाइंट्स, कॉल्स, मीटिंग्स और अन्य CRM सामानों के बारे में जानकारी संग्रहीत करते हैं। बड़े पैमाने पर रहने के लिए यह बहुत सारी जानकारी है, तो चलिए इन तालिकाओं को क्रमबद्ध करते हैं।
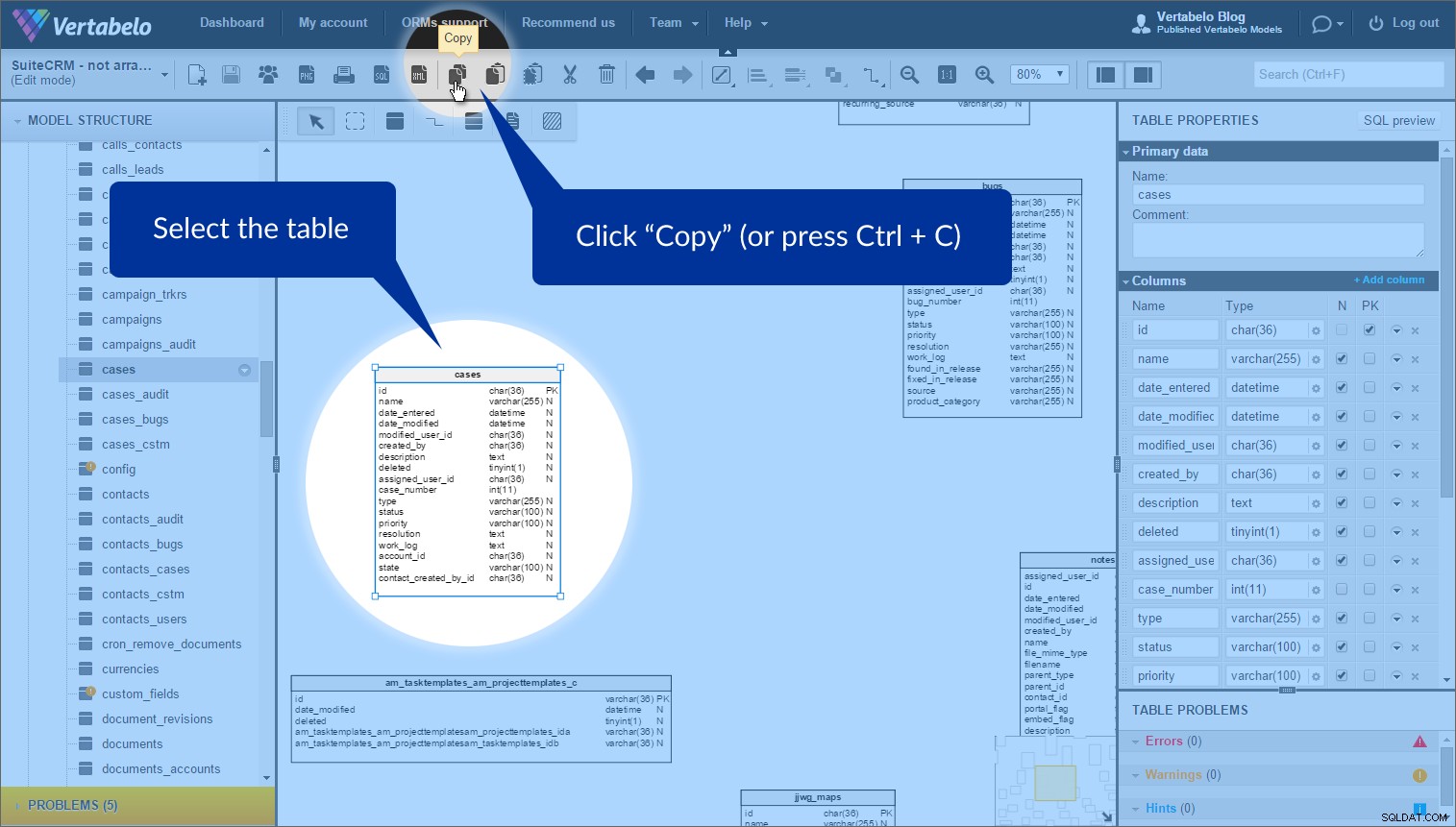
इन तालिकाओं को व्यवस्थित करने के लिए मुझे जो विशेषता सबसे उपयोगी लगी, उसे तालिका शॉर्टकट . कहा जाता है . कभी-कभी आप एक मॉडल में एक से अधिक बार एक ही टेबल का उपयोग करना चाहते हैं। (क्यों? मॉडल को समतल करने और ओवरलैपिंग से बचने के लिए।) हम “कॉपी” का उपयोग करके आसानी से ऐसा कर सकते हैं और “शॉर्टकट के रूप में पेस्ट करें” बटन।
बस उस तालिका का चयन करें जिसके लिए आप एक शॉर्टकट बनाना चाहते हैं और “कॉपी करें” . पर क्लिक करें शीर्ष टूलबार में (या Ctrl + C दबाएं) ):
शॉर्टकट बनाने के लिए, “शॉर्टकट के रूप में चिपकाएं” . क्लिक करें (या Ctrl + K press दबाएं ) उसके बाद, बिंदीदार रूपरेखा वाली एक नई तालिका दिखाई देगी:
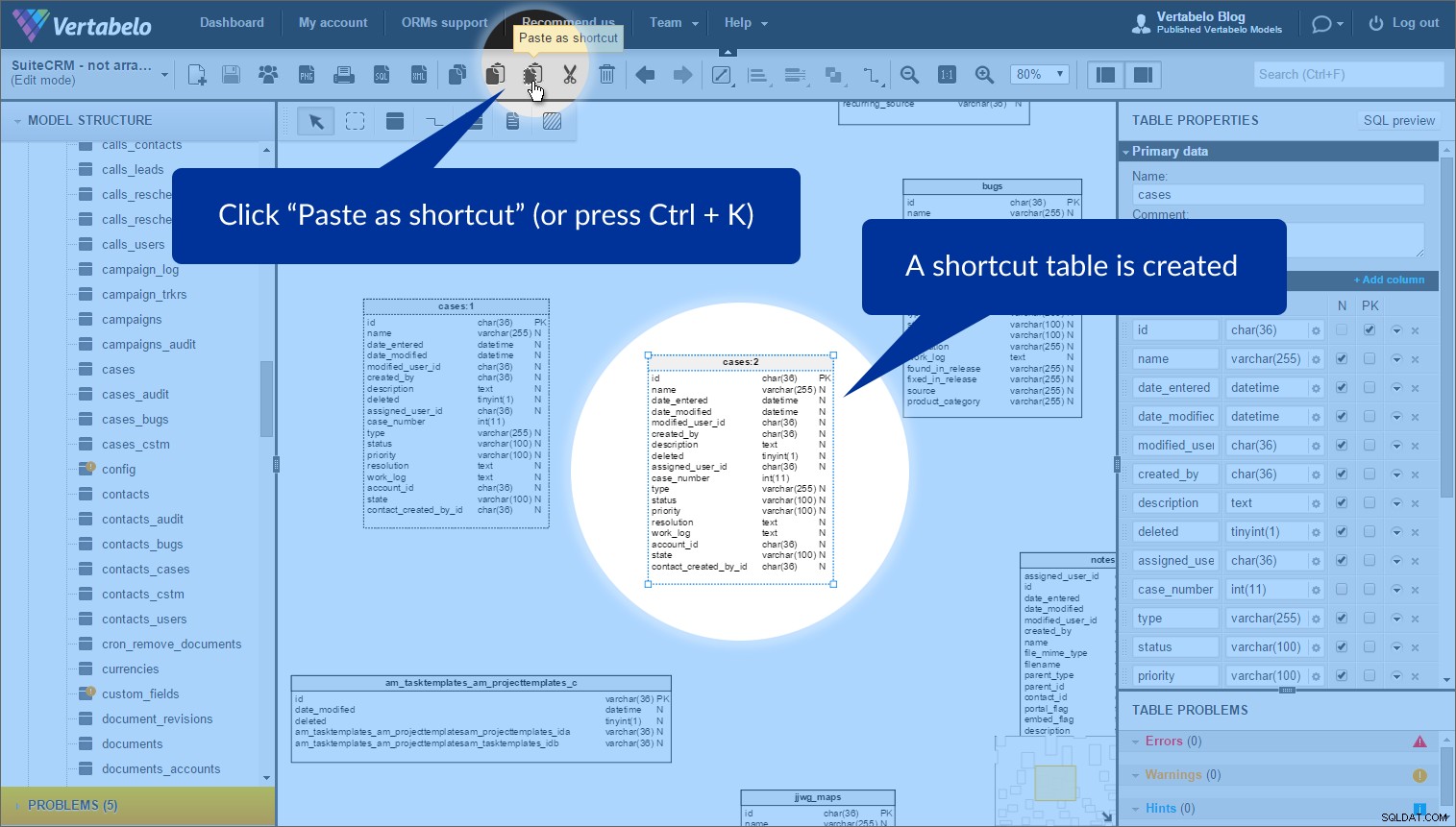
यह नहीं है तालिका की एक प्रति, लेकिन मूल तालिका का एक और उदाहरण। हम इसे अपने मॉडल में कहीं भी रख सकते हैं। अतिव्यापी संदर्भों से बचने के लिए मैंने विभिन्न विषय क्षेत्रों में एक ही तालिका के उदाहरणों का उपयोग किया। यह उल्लेख करने योग्य है कि प्रत्येक तालिका उदाहरण में एक निर्दिष्ट विषय क्षेत्र का नाम (उसके नाम के आगे) होता है, जबकि वह उस विषय क्षेत्र के अंदर होता है।
यह कैसे काम करता है इसका एक अच्छा उदाहरण है users टेबल। यह "उपयोगकर्ता और खाते", "भूमिकाएं", "दस्तावेज़" और अन्य विषय क्षेत्रों में पाया जा सकता है। हम इसे बाद में मॉडल में देखेंगे।
टेबल के बीच स्थापित संबंधों के साथ विषय क्षेत्र बनाते समय मैं टेबल शॉर्टकट का व्यापक रूप से उपयोग करता हूं। यह कैसे काम करता है यह देखने के लिए, नीचे दिए गए "अवसर" विषय क्षेत्र को देखें। ध्यान दें कि उस विषय क्षेत्र में सभी तालिकाओं का नाम इस नियम के अनुसार रखा गया है:{तालिका नाम} :{विषय क्षेत्र का नाम} ।
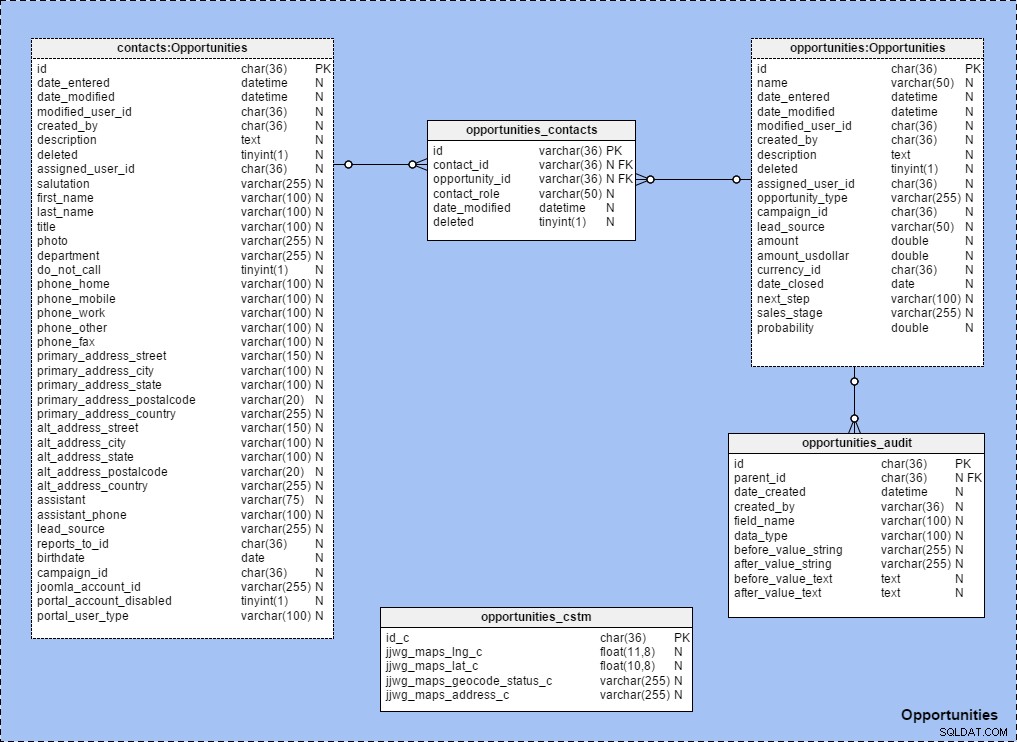
जब हम {विषय क्षेत्र का नाम} . का विस्तार करते हैं "मॉडल संरचना" पैनल में, हम स्पष्ट रूप से देख सकते हैं कि इसमें टेबल और संदर्भ शामिल हैं:
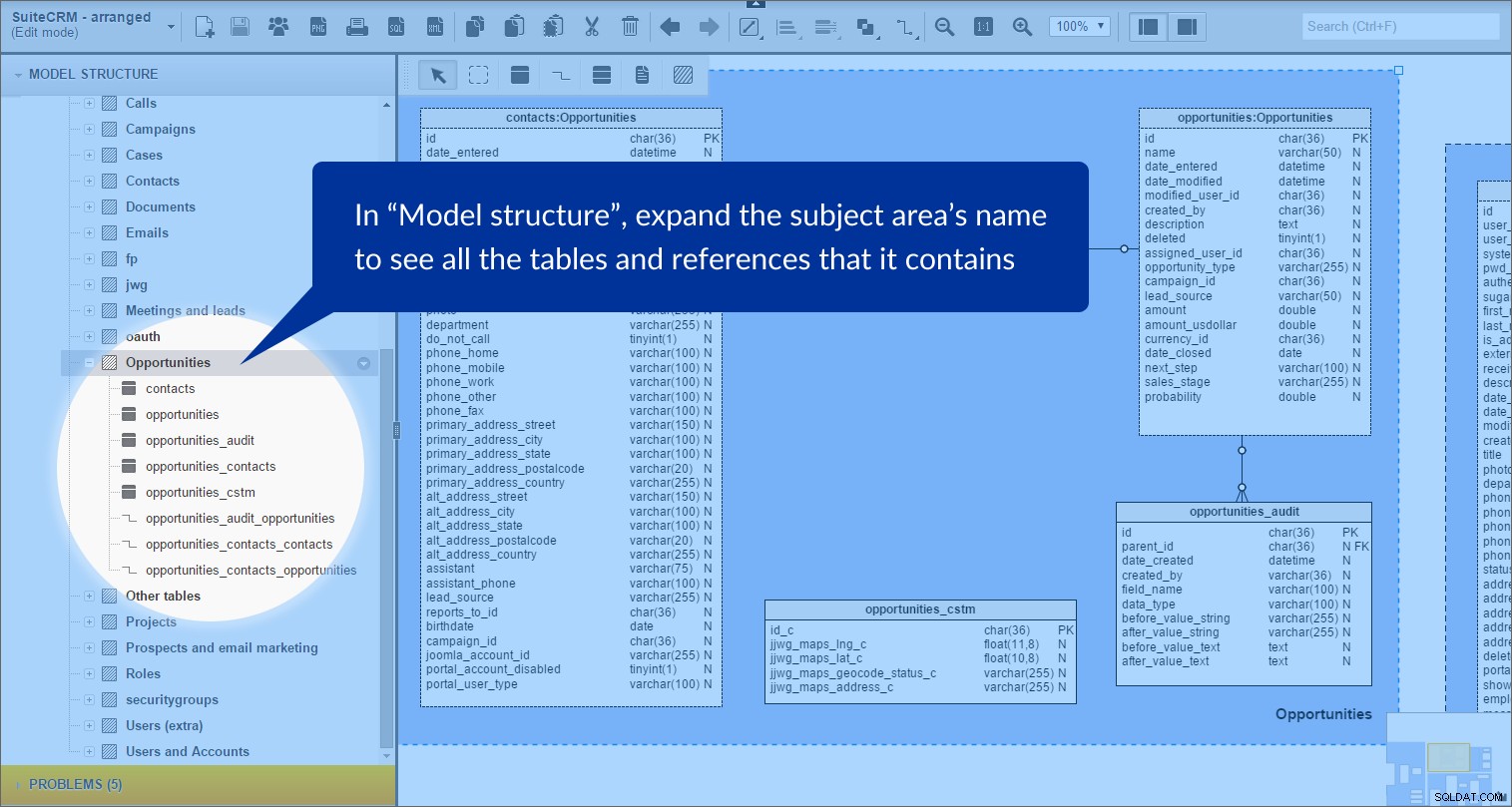
मैंने इसे निम्नलिखित विषय क्षेत्रों के लिए किया:"कॉल", "मामले", "अभियान", "संपर्क", "दस्तावेज़", "मीटिंग और लीड्स", "ओथ", "प्रोजेक्ट्स", "संभावनाएं और ईमेल मार्केटिंग", "भूमिकाएं", और "उपयोगकर्ता और खाते"। इन सभी क्षेत्रों की पृष्ठभूमि हल्के नीले रंग की है।
शेष तालिकाओं को उनके नाम और अनुमानित अर्थ के आधार पर समूहीकृत किया जाता है:"ईमेल", "उपयोगकर्ता (अतिरिक्त)", और "अन्य टेबल"। इन समूहों की पृष्ठभूमि का रंग हल्का लाल पर सेट है।
जब आप नेविगेशन ट्री में किसी तालिका के नाम पर डबल-क्लिक करते हैं, तो दृश्य मॉडल में उस तालिका पर ज़ूम करके उसका चयन करेगा। जब आप माउस व्हील को घुमाकर ज़ूम इन करते हैं, तो दृश्य माउस पॉइंटर की दिशा में ज़ूम इन करेगा।व्यवस्थित मॉडल
मैंने तालिकाओं को तार्किक रूप से समूहीकृत करते हुए जितना संभव हो सके मॉडल को समतल करने के लिए पहले वर्णित विकल्पों का उपयोग किया। परिणाम 26 विषय क्षेत्र हैं, जिनमें से कुछ में केवल टेबल हैं जबकि अन्य में टेबल और संबंध हैं। आइए प्रत्येक श्रेणी की त्वरित समीक्षा करें:
विषय क्षेत्र जिनमें टेबल और संबंध शामिल हैं:
"कॉल", "अभियान", "मामले", "संपर्क", "दस्तावेज़", "मीटिंग्स और लीड्स", "अवसर", "प्रोजेक्ट्स", "संभावनाएं और ईमेल मार्केटिंग", "भूमिकाएं", "उपयोगकर्ता और खाते"
सभी संबंध गैर-अनिवार्य के रूप में सेट हैं। यह जानकारी रखता है कि ये तालिकाएँ संबंधित हैं और किस विशेषता के माध्यम से।
विषय क्षेत्र जिनमें केवल तालिकाएं हैं:
"एसीएल", "एम", "एओडी", "ओक", "एओपी", "एओआर", "एओएस", "ओओ", "ईमेल", "एफपी", "जेडब्ल्यूजी", "ओथ", "सिक्योरिटी_ग्रुप्स" ”, “उपयोगकर्ता अतिरिक्त”
इसका मतलब यह नहीं है कि यहां संबंध नहीं हैं; उन पर जोर नहीं दिया जा रहा है।
"अन्य टेबल" विषय क्षेत्र उन तालिकाओं के लिए है जो वास्तव में एक विशिष्ट समूह में फिट नहीं होती हैं।
मॉडल कैसा दिखता है?
पुनर्व्यवस्थित मॉडल इस तरह दिखता है:
जाहिर है एक नामकरण सम्मेलन का इस्तेमाल किया गया है। हमारे द्वारा अनुसरण किए गए दिशानिर्देशों का अवलोकन यहां दिया गया है:
- तालिका नाम अधिकतर बहुवचन हैं:
users,contracts,folders,roles,tasks. कुछ टेबल नाम एकवचन होते हैं, जैसेproject। - अधिकांश तालिकाओं में प्राथमिक कुंजी को केवल
idकहा जाता है और एक char(36) प्रकार है। - जब एक-से-अनेक संबंध होता है, तो विदेशी कुंजी को आमतौर पर
parent_idनाम दिया जाता है . (उदाहरण:contacts_audit.parent_idcontacts.id. का संदर्भ है ।) - अनेक-से-अनेक संबंधों में, “
parent_id"कई स्तंभों के लिए नाम के रूप में उपयोग नहीं किया जा सकता है। इसके बजाय, प्रत्यय "_id" के साथ एक विलक्षण तालिका नाम का उपयोग किया जाता है। (उदाहरण:contacts_bugs.bug_idbug.id. का संदर्भ है ।) - ऐसी स्थितियाँ होती हैं जब एक ही कॉलम का उपयोग कई तालिकाओं के लिए विदेशी कुंजी के रूप में किया जाता है। (उदाहरण:
calls.parent_idनिम्नलिखित तालिकाओं में से प्रत्येक में आईडी कॉलम को संदर्भित किया जाता है:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. मैंने डेटाबेस में मानों की जाँच नहीं की है, लेकिन मेरा अनुमान है कि इन तालिकाओं में समान कुंजी मान नहीं हैं। चूंकि सभी चार(36) प्रकार के होते हैं, शायद टेबल नाम और ऑटोइनक्रिकमेंट के कुछ संयोजन का उपयोग किया जाता है। हम आगामी लेखों में इसकी जांच करेंगे।) - हम उन स्तंभों के लिए समान नामों का उपयोग करते हैं जिनका अलग-अलग तालिकाओं में समान अर्थ होता है। (उदाहरण:
modified_user_id,created_byऔरassigned_user_idमॉडल में कई तालिकाओं में पाया जा सकता है। वे सभीusers.id. के संदर्भ में हैं ।)
आगे क्या है?
आने वाले लेखों में, हम SuiteCRM GUI का उपयोग करेंगे और उन परिवर्तनों पर नज़र रखेंगे जो डेटाबेस में इसके कारण होते हैं। उस जानकारी के साथ, हम मॉडल में बदलाव करने, विषय क्षेत्रों को पुनर्व्यवस्थित करने और जहां आवश्यक हो वहां कनेक्शन स्थापित करने का प्रयास करेंगे। साथ ही, हम अन्य सुइटसीआरएम-विशिष्ट नियमों की तलाश करेंगे, जैसे कि प्राथमिक कुंजियां कैसे बनाई जाती हैं।
बड़े डेटाबेस आरेखों को संभालना कभी आसान काम नहीं होता है। जैसे घर के लिए एक अच्छी नींव बनाना, बुनियादी बातों पर अधिक समय बिताना बाद में लाभ लाएगा। यदि हम सुइटसीआरएम के पीछे वाले मॉडल का विश्लेषण करना चाहते हैं, तो मॉडल संरचना को व्यवस्थित करने से पहले विश्लेषण करना और तालिका संबंधों को परिभाषित करना इसे सिसिफस-शैली कर रहा है।