MySQL/MariaDB में अपने डेटाबेस स्कीमा परिवर्तनों की निगरानी करना एक बड़ी सहायता प्रदान करता है क्योंकि यह आपके डेटाबेस वृद्धि, तालिका परिभाषा परिवर्तन, डेटा आकार, अनुक्रमणिका आकार, या पंक्ति आकार का विश्लेषण करने में समय बचाता है। MySQL/MariaDB के लिए, info_schema को संदर्भित करने वाली क्वेरी को performance_schema के साथ चलाने से आपको आगे के विश्लेषण के लिए सामूहिक परिणाम मिलते हैं। sys स्कीमा आपको ऐसे दृश्य प्रदान करता है जो सामूहिक मीट्रिक के रूप में काम करते हैं जो डेटाबेस परिवर्तन या गतिविधि को ट्रैक करने के लिए बहुत उपयोगी होते हैं।
यदि आपके पास कई डेटाबेस सर्वर हैं, तो हर समय एक क्वेरी चलाना कठिन होगा। आपको उस परिणाम को अधिक पठनीय और समझने में आसान बनाने के लिए भी पचाना होगा।
इस ब्लॉग में, हम एक ऑटोमेशन बनाएंगे जो आपके उपयोगिता टूल के रूप में आपके मौजूदा डेटाबेस की निगरानी करने और डेटाबेस परिवर्तन या स्कीमा परिवर्तन संचालन से संबंधित मीट्रिक एकत्र करने में सहायक होगा।
डेटाबेस स्कीमा ऑब्जेक्ट चेक के लिए ऑटोमेशन बनाना
इस अभ्यास में, हम निम्नलिखित मीट्रिक की निगरानी करेंगे:
-
कोई प्राथमिक कुंजी तालिका नहीं
-
डुप्लिकेट अनुक्रमणिका
-
हमारे डेटाबेस स्कीमा में पंक्तियों की कुल संख्या के लिए एक ग्राफ़ जेनरेट करें
-
हमारे डेटाबेस स्कीमा के कुल आकार के लिए एक ग्राफ़ जेनरेट करें
यह अभ्यास आपको जानकारी देगा और आपके MySQL/MariaDB डेटाबेस से अधिक उन्नत मीट्रिक एकत्र करने के लिए संशोधित किया जा सकता है।
हमारे IaC और स्वचालन के लिए कठपुतली का उपयोग करना
यह अभ्यास कठपुतली का उपयोग स्वचालन प्रदान करने के लिए करेगा और उन मीट्रिक के आधार पर अपेक्षित परिणाम उत्पन्न करेगा जिनकी हम निगरानी करना चाहते हैं। हम सर्वर और क्लाइंट सहित कठपुतली के लिए इंस्टॉलेशन और सेटअप को कवर नहीं करेंगे, इसलिए मैं आपसे कठपुतली का उपयोग करने के बारे में जानना चाहता हूं। आप कठपुतली के साथ हमारे पुराने ब्लॉग MySQL Galera Cluster के स्वचालित परिनियोजन पर Amazon AWS पर जाना चाह सकते हैं, जो कठपुतली के सेटअप और स्थापना को कवर करता है।
हम इस अभ्यास में कठपुतली के नवीनतम संस्करण का उपयोग करेंगे लेकिन चूंकि हमारे कोड में मूल वाक्य रचना है, इसलिए यह कठपुतली के पुराने संस्करणों के लिए चलेगा।
पसंदीदा MySQL डेटाबेस सर्वर
इस अभ्यास में, हम Percona Server 8.0.22-13 का उपयोग करेंगे क्योंकि मैं Percona सर्वर को ज्यादातर परीक्षण और कुछ मामूली तैनाती या तो व्यावसायिक या व्यक्तिगत उपयोग के लिए पसंद करता हूं।
ग्राफ़िंग टूल
विशेष रूप से Linux वातावरण का उपयोग करने के लिए कई विकल्प हैं। इस ब्लॉग में, मैं सबसे आसान जो मुझे मिला और एक ओपनसोर्स टूल https://quickchart.io/ का उपयोग करूंगा।
चलो कठपुतली के साथ खेलते हैं
मैंने यहां जो धारणा बनाई है, वह यह है कि आपके पास पंजीकृत क्लाइंट के साथ सेटअप मास्टर सर्वर है जो स्वचालित तैनाती प्राप्त करने के लिए मास्टर सर्वर के साथ संचार करने के लिए तैयार है।
आगे बढ़ने से पहले, यह मेरी सर्वर जानकारी है:
मास्टर सर्वर:192.168.40.200
क्लाइंट/एजेंट सर्वर:192.168.40.160
इस ब्लॉग में, हमारा क्लाइंट/एजेंट सर्वर वह जगह है जहां हमारा डेटाबेस सर्वर चल रहा है। वास्तविक दुनिया के परिदृश्य में, यह विशेष रूप से निगरानी के लिए होना जरूरी नहीं है। जब तक यह लक्ष्य नोड में सुरक्षित रूप से संचार करने में सक्षम है, तब तक यह एक आदर्श सेटअप भी है।
मॉड्यूल और कोड सेटअप करें
-
मास्टर सर्वर पर जाएं और पथ में /etc/puppetlabs/code/environments/production/module, आइए इस अभ्यास के लिए आवश्यक निर्देशिकाएँ बनाएँ:
mkdir schema_change_mon/{files,manifests}
-
वे फ़ाइलें बनाएं जिनकी हमें आवश्यकता है
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
निम्न सामग्री के साथ init.pp स्क्रिप्ट भरें:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
graphing_gen.sh फ़ाइल भरें। यह स्क्रिप्ट लक्ष्य नोड पर चलेगी और हमारे डेटाबेस में पंक्तियों की कुल संख्या और हमारे डेटाबेस के कुल आकार के लिए ग्राफ़ उत्पन्न करेगी। इस स्क्रिप्ट के लिए, आइए इसे आसान बनाते हैं, और केवल MyISAM या InnoDB प्रकार के डेटाबेस की अनुमति देते हैं।
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
अंत में, मॉड्यूल पथ निर्देशिका या /etc/puppetlabs/code/environments पर जाएं / मेरे सेटअप में उत्पादन। आइए फ़ाइल बनाते हैं मैनिफ़ेस्ट/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
फिर फ़ाइल मेनिफ़ेस्ट/schema_change_mon.pp को निम्न सामग्री से भरें,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
यदि आप कर चुके हैं, तो आपके पास मेरी तरह ही निम्न वृक्ष संरचना होनी चाहिए,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppहमारा मॉड्यूल क्या करता है?
हमारा मॉड्यूल जिसे schema_change_mon कहा जाता है, निम्नलिखित एकत्र करता है,
exec { "mysql-without-primary-key" :...
जो एक mysql कमांड निष्पादित करता है और प्राथमिक कुंजी के बिना तालिकाओं को पुनः प्राप्त करने के लिए एक क्वेरी चलाता है। फिर,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :जो डेटाबेस टेबल में मौजूद डुप्लीकेट इंडेक्स को इकट्ठा करता है।
इसके बाद, लाइनें एकत्रित मीट्रिक के आधार पर ग्राफ़ उत्पन्न करती हैं। ये निम्नलिखित पंक्तियाँ हैं,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…एक बार क्वेरी के सफलतापूर्वक चलने के बाद, यह ग्राफ़ उत्पन्न करता है, जो https://quickchart.io/ द्वारा प्रदान किए गए API पर निर्भर करता है।
यहां ग्राफ़ के निम्नलिखित परिणाम दिए गए हैं:
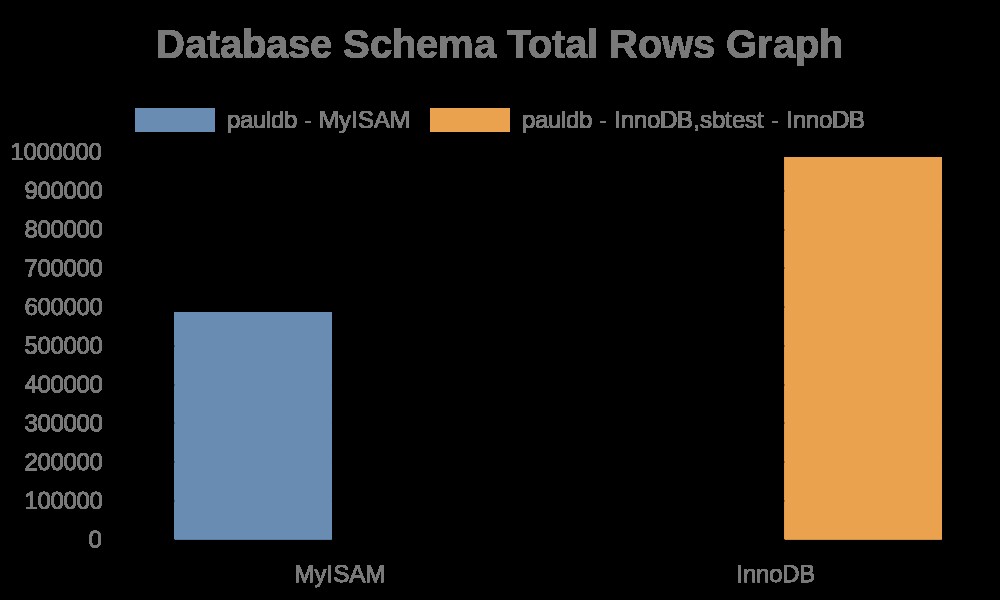
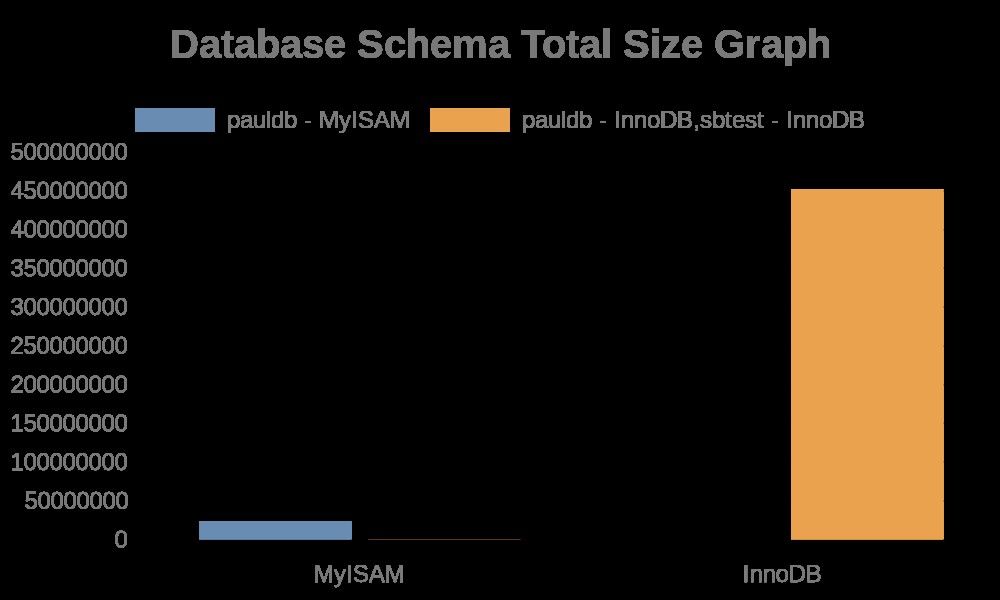
जबकि फ़ाइल लॉग में केवल इसके टेबल नाम, इंडेक्स नामों के साथ स्ट्रिंग्स होते हैं। परिणाम नीचे देखें,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBClusterControl का उपयोग क्यों न करें?
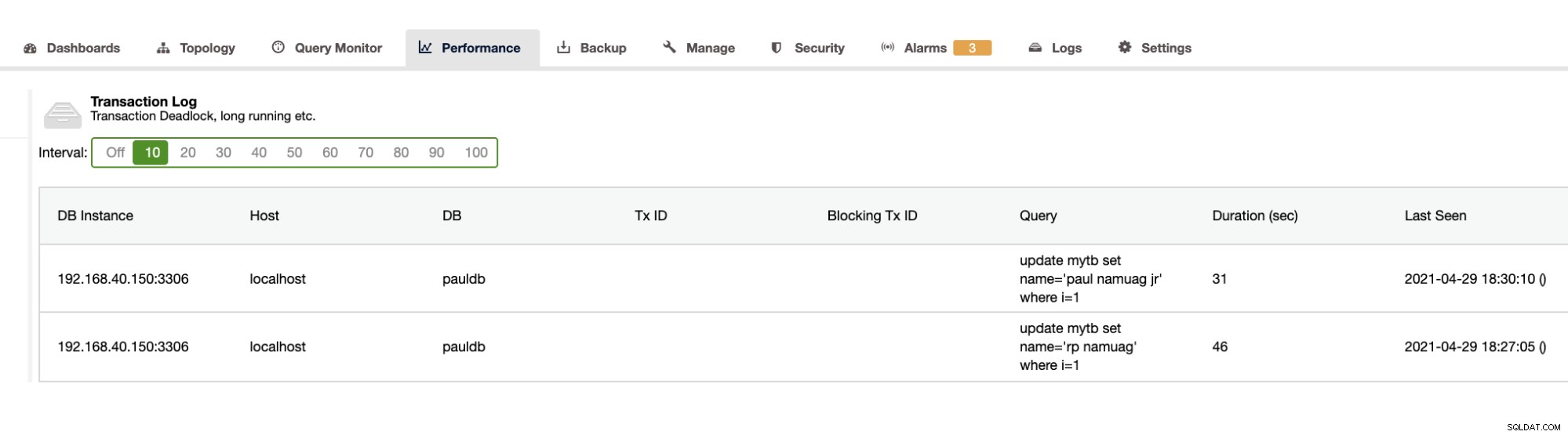
जैसा कि हमारा अभ्यास स्वचालन दिखाता है और परिवर्तन या संचालन जैसे डेटाबेस स्कीमा आंकड़े प्राप्त करता है, ClusterControl इसे भी प्रदान करता है। इसके अलावा अन्य विशेषताएं भी हैं और आपको पहिया को फिर से शुरू करने की आवश्यकता नहीं है। ClusterControl लेन-देन लॉग प्रदान कर सकता है जैसे कि ऊपर दिखाए गए गतिरोध, या नीचे दिखाए गए लंबे समय तक चलने वाले प्रश्न:
ClusterControl नीचे दिखाए गए अनुसार DB वृद्धि को भी दर्शाता है,
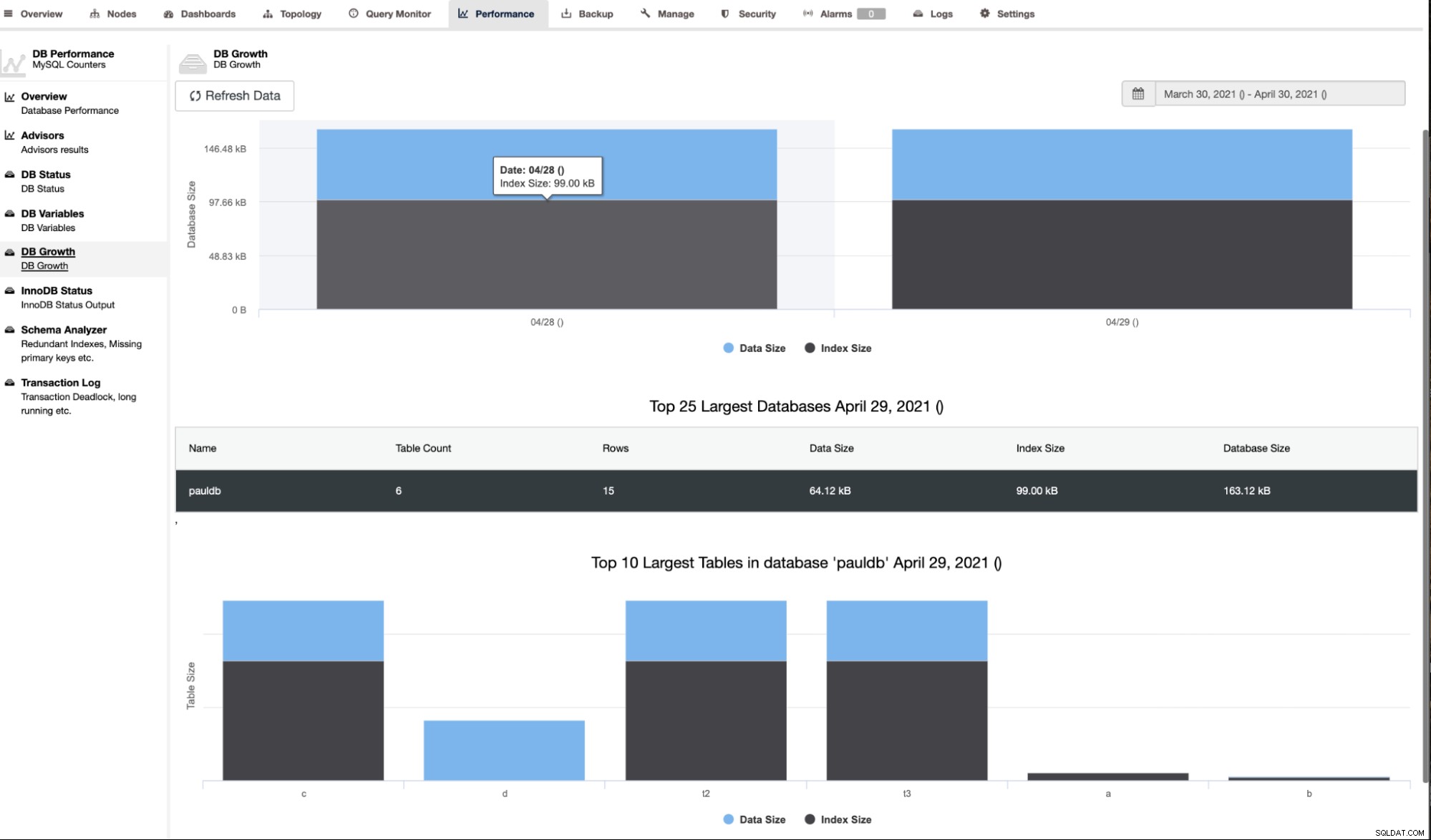
ClusterControl अतिरिक्त जानकारी भी देता है जैसे पंक्तियों की संख्या, डिस्क आकार, अनुक्रमणिका आकार और कुल आकार।
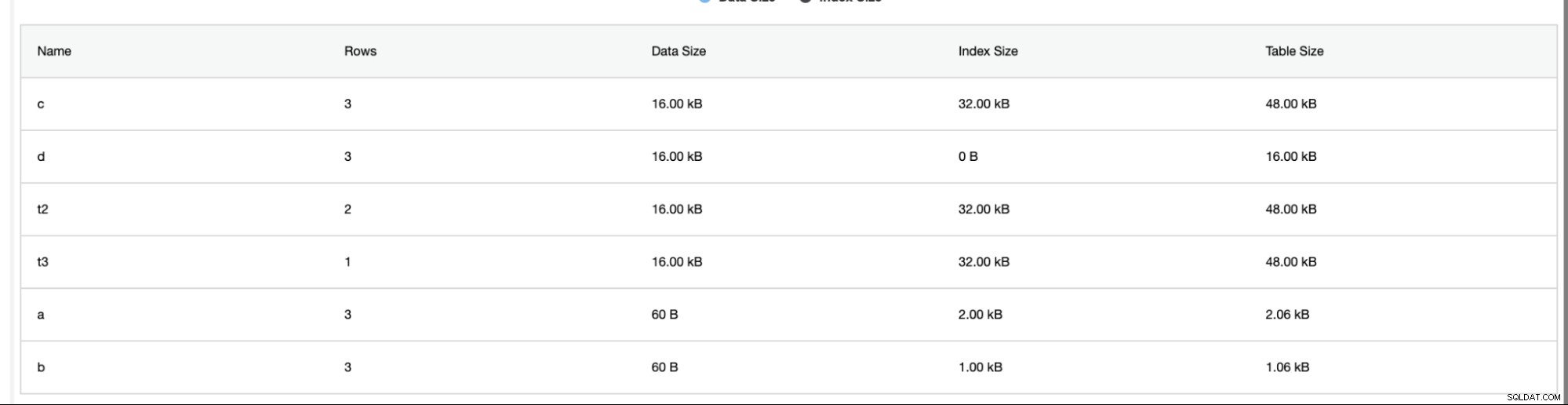
प्रदर्शन टैब के अंतर्गत स्कीमा विश्लेषक -> स्कीमा विश्लेषक बहुत उपयोगी है। यह बिना प्राथमिक कुंजी, MyISAM टेबल और डुप्लीकेट इंडेक्स वाली टेबल उपलब्ध कराता है,

यह उन मामलों में भी अलार्म प्रदान करता है जहां प्राथमिक के बिना डुप्लीकेट इंडेक्स या टेबल पाए जाते हैं कुंजियाँ जैसे नीचे,

आप हमारे उत्पाद के पेज पर ClusterControl और इसकी अन्य विशेषताओं के बारे में अधिक जानकारी देख सकते हैं।
निष्कर्ष
आपके डेटाबेस परिवर्तन या किसी भी स्कीमा आँकड़े जैसे कि राइट, डुप्लिकेट इंडेक्स, ऑपरेशन अपडेट जैसे DDL परिवर्तन, और कई डेटाबेस गतिविधियों की निगरानी के लिए स्वचालन प्रदान करना DBA के लिए बहुत फायदेमंद है। यह कमजोर कड़ियों और समस्याग्रस्त प्रश्नों की शीघ्रता से पहचान करने में मदद करता है जो आपको खराब प्रश्नों के संभावित कारण का एक सिंहावलोकन देगा जो आपके डेटाबेस को लॉक कर देगा या आपके डेटाबेस को खराब कर देगा।