यदि आपने इसे नहीं देखा है, तो हमने अभी-अभी ClusterControl 1.7.5 को बड़े सुधारों और नई उपयोगी सुविधाओं के साथ जारी किया है। कुछ विशेषताओं में क्लस्टर वाइड रखरखाव, संस्करण CentOS 8 और डेबियन 10 के लिए समर्थन, PostgreSQL 12 समर्थन, MongoDB 4.2 और Percona MongoDB v4.0 समर्थन, साथ ही साथ नया MySQL फ़्रीज़ फ़्रेम शामिल हैं।
रुको, लेकिन MySQL फ़्रीज़ फ़्रेम क्या है? क्या यह MySQL के लिए कुछ नया है?
वैसे यह MySQL कर्नेल में ही कुछ नया नहीं है। यह एक नई सुविधा है जिसे हमने ClusterControl 1.7.5 में जोड़ा है जो MySQL डेटाबेस के लिए विशिष्ट है। ClusterControl 1.7.5 में MySQL फ़्रीज़ फ़्रेम में निम्नलिखित चीज़ें शामिल होंगी:
- क्लस्टर विफलता से पहले MySQL स्थिति का स्नैपशॉट लें।
- स्नैपशॉट MySQL प्रक्रिया सूची क्लस्टर विफलता से पहले (जल्द ही आ रहा है)।
- संचालन रिपोर्ट में या s9s कमांड लाइन टूल से क्लस्टर घटनाओं का निरीक्षण करें।
ये जानकारी के मूल्यवान सेट हैं जो बग का पता लगाने में मदद कर सकते हैं और जब चीजें दक्षिण की ओर जाती हैं तो आपके MySQL/MariaDB क्लस्टर को ठीक कर सकती हैं। भविष्य में, हम SHOW ENGINE InnoDB स्थिति मानों के स्नैपशॉट भी शामिल करने की योजना बना रहे हैं। तो कृपया हमारी भविष्य की रिलीज़ के लिए बने रहें।
ध्यान दें कि यह सुविधा अभी भी बीटा अवस्था में है, हम अपने उपयोगकर्ताओं के साथ काम करते हुए और अधिक डेटासेट एकत्र करने की अपेक्षा करते हैं। इस ब्लॉग में, हम आपको दिखाएंगे कि इस सुविधा का लाभ कैसे उठाया जाए, खासकर जब आपको अपने MySQL/MariaDB क्लस्टर का निदान करते समय अधिक जानकारी की आवश्यकता हो।
क्लस्टर विफलता से निपटने पर क्लस्टर नियंत्रण
क्लस्टर विफलताओं के लिए, ClusterControl तब तक कुछ नहीं करता जब तक कि ऑटो रिकवरी (क्लस्टर/नोड) नीचे की तरह सक्षम न हो:

एक बार सक्षम हो जाने पर, ClusterControl नोड को पुनर्प्राप्त करने या क्लस्टर को पुनर्प्राप्त करने का प्रयास करेगा संपूर्ण क्लस्टर टोपोलॉजी ला रहा है।
MySQL के लिए, उदाहरण के लिए मास्टर-स्लेव प्रतिकृति में, किसी भी समय उपलब्ध दासों की संख्या पर ध्यान दिए बिना, इसमें कम से कम एक मास्टर जीवित होना चाहिए। ClusterControl प्रतिकृति क्लस्टर के लिए कम से कम एक बार टोपोलॉजी को सही करने का प्रयास करता है, लेकिन NDB क्लस्टर और गैलेरा क्लस्टर जैसे मल्टी-मास्टर प्रतिकृति के लिए अधिक पुन:प्रयास प्रदान करता है। नोड पुनर्प्राप्ति विफल डेटाबेस नोड को पुनर्प्राप्त करने का प्रयास करता है, उदा। जब प्रक्रिया समाप्त हो गई (असामान्य शटडाउन), या प्रक्रिया को OOM (आउट-ऑफ-मेमोरी) का सामना करना पड़ा। ClusterControl SSH के माध्यम से नोड से कनेक्ट होगा और MySQL को लाने का प्रयास करेगा। हमने पहले इस बारे में ब्लॉग किया है कि कैसे ClusterControl स्वचालित डेटाबेस पुनर्प्राप्ति और विफलता को निष्पादित करता है, इसलिए ClusterControl स्वत:पुनर्प्राप्ति के लिए योजना के बारे में अधिक जानने के लिए कृपया उस लेख पर जाएँ।
ClusterControl के पिछले संस्करण में <1.7.5, पुनर्प्राप्ति का प्रयास करने वालों ने अलार्म ट्रिगर किया। लेकिन एक बात जो हमारे ग्राहकों ने याद की, वह थी क्लस्टर विफलता से ठीक पहले राज्य की जानकारी के साथ एक अधिक संपूर्ण घटना रिपोर्ट। जब तक हमें इस कमी का एहसास नहीं हुआ और हमने इस सुविधा को ClusterControl 1.7.5 में जोड़ा। हमने इसे "MySQL फ्रीज फ्रेम" कहा। MySQL फ़्रीज़ फ़्रेम, इस लेखन के रूप में, दुर्घटना से ठीक पहले क्लस्टर स्थिति में बदलाव की घटनाओं का एक संक्षिप्त सारांश प्रदान करता है। सबसे महत्वपूर्ण बात यह है कि इसमें रिपोर्ट के अंत में मेजबानों की सूची और उनके MySQL वैश्विक स्थिति चर और मान शामिल हैं।
MySQL फ़्रीज़ फ़्रेम स्वतः पुनर्प्राप्ति के साथ कैसे भिन्न होता है?
MySQL फ़्रीज़ फ़्रेम, ClusterControl की स्वतः पुनर्प्राप्ति का भाग नहीं है। चाहे ऑटो रिकवरी अक्षम हो या सक्षम, MySQL फ़्रीज़ फ़्रेम हमेशा अपना काम करेगा जब तक कि क्लस्टर या नोड विफलता का पता चला है।
MySQL फ्रीज फ्रेम कैसे काम करता है?
ClusterControl में, कुछ ऐसे राज्य हैं जिन्हें हम विभिन्न प्रकार की क्लस्टर स्थिति के रूप में वर्गीकृत करते हैं। इन दो राज्यों के ट्रिगर होने पर MySQL फ़्रीज़ फ़्रेम एक घटना रिपोर्ट जनरेट करेगा:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
ClusterControl में, एक CLUSTER_DEGRADED तब होता है जब आप किसी क्लस्टर को लिख सकते हैं, लेकिन एक या अधिक नोड्स डाउन हो जाते हैं। जब ऐसा होता है, तो ClusterControl घटना रिपोर्ट जनरेट करेगा।
CLUSTER_FAILURE के लिए, हालांकि इसका नामकरण स्वयं की व्याख्या करता है, यह वह स्थिति है जहां आपका क्लस्टर विफल हो जाता है और अब पढ़ने या लिखने को संसाधित करने में सक्षम नहीं है। तो वह एक CLUSTER_FAILURE स्थिति है। भले ही कोई स्वत:पुनर्प्राप्ति प्रक्रिया समस्या को ठीक करने का प्रयास कर रही हो या उसे अक्षम कर दिया गया हो, ClusterControl घटना रिपोर्ट जनरेट करेगा।
आप MySQL फ़्रीज़ फ़्रेम को कैसे सक्षम करते हैं?
ClusterControl का MySQL फ़्रीज़ फ़्रेम डिफ़ॉल्ट रूप से सक्षम है और केवल तभी एक घटना रिपोर्ट उत्पन्न करता है जब CLUSTER_DEGRADED या CLUSTER_FAILURE स्थितियाँ ट्रिगर या सामने आती हैं। इसलिए उपयोगकर्ता की ओर से किसी भी ClusterControl कॉन्फ़िगरेशन सेटिंग को सेट करने की कोई आवश्यकता नहीं है, ClusterControl इसे आपके लिए स्वचालित रूप से करेगा।
MySQL फ्रीज फ्रेम घटना रिपोर्ट का पता लगाना
इस लेखन के समय, घटना रिपोर्ट का पता लगाने के चार तरीके हैं। इन्हें नीचे दिए गए अनुभागों को करके पाया जा सकता है।
ऑपरेशनल रिपोर्ट टैब का उपयोग करना
पिछले संस्करणों की परिचालन रिपोर्ट का उपयोग केवल उपयोगकर्ताओं द्वारा तैयार की गई परिचालन रिपोर्ट बनाने, शेड्यूल करने या सूचीबद्ध करने के लिए किया जाता है। संस्करण 1.7.5 के बाद से, हमने अपने MySQL फ़्रीज़ फ़्रेम फ़ीचर द्वारा उत्पन्न घटना रिपोर्ट को शामिल किया है। नीचे दिया गया उदाहरण देखें:
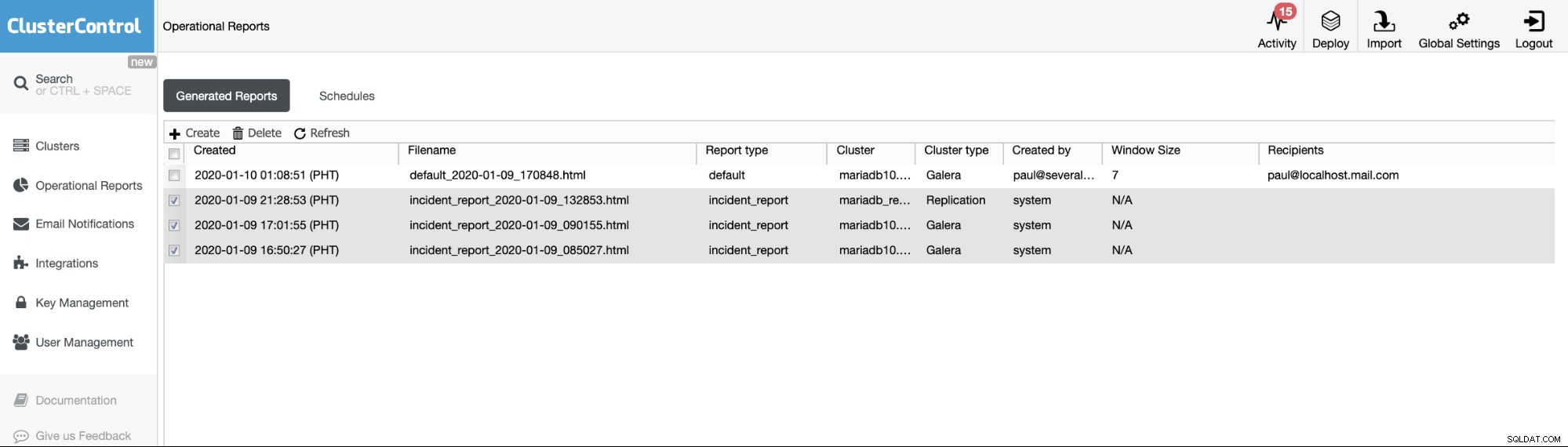
रिपोर्ट प्रकार के साथ चेक किए गए आइटम या आइटम ==घटना_रिपोर्ट, घटना हैं ClusterControl में MySQL फ़्रीज़ फ़्रेम सुविधा द्वारा उत्पन्न रिपोर्ट।
त्रुटि रिपोर्ट का उपयोग करना
क्लस्टर का चयन करके और एक त्रुटि रिपोर्ट तैयार करके, यानी इस प्रक्रिया से गुजरना:<क्लस्टर का चयन करें> → लॉग्स → त्रुटि रिपोर्ट → त्रुटि रिपोर्ट बनाएं। इसमें ClusterControl होस्ट के अंतर्गत घटना रिपोर्ट शामिल होगी।
s9s CLI कमांड लाइन का उपयोग करना
एक उत्पन्न घटना रिपोर्ट पर, इसमें निर्देश या संकेत शामिल होते हैं कि आप इसे s9s CLI कमांड के साथ कैसे उपयोग कर सकते हैं। घटना रिपोर्ट में जो दिखाया गया है वह नीचे दिया गया है:
संकेत! s9s CLI टूल का उपयोग करके आप इस रिपोर्ट में डेटा को आसानी से ग्रीप कर सकते हैं, जैसे:
s9s report --list --long
s9s report --cat --report-id=Nइसलिए यदि आप एक त्रुटि रिपोर्ट का पता लगाना और उत्पन्न करना चाहते हैं, तो आप इस दृष्टिकोण का उपयोग कर सकते हैं:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident Reportयदि मैं किसी विशिष्ट होस्ट पर wsrep_* चर को grep करना चाहता हूं, तो मैं निम्नलिखित कार्य कर सकता हूं:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |सिस्टम फ़ाइल पथ के माध्यम से मैन्युअल रूप से पता लगाना
ClusterControl इन घटना रिपोर्ट को उस होस्ट में जनरेट करता है जहां ClusterControl चलता है। यदि आप रूट सिस्टम उपयोगकर्ता का उपयोग कर रहे हैं तो ClusterControl /home/
क्या MySQL फ़्रीज़ फ़्रेम का उपयोग करते समय कोई ख़तरा या चेतावनी है?
ClusterControl आपके MySQL नोड्स या क्लस्टर में कुछ भी नहीं बदलता है और न ही संशोधित करता है। MySQL फ़्रीज़ फ़्रेम रिकॉर्ड्स को सहेजने के लिए विशिष्ट अंतराल पर SHOW GLOBAL STATUS (इस समय के अनुसार) पढ़ेगा क्योंकि हम MySQL नोड या क्लस्टर की स्थिति का अनुमान नहीं लगा सकते हैं जब यह क्रैश हो सकता है या जब इसमें हार्डवेयर या डिस्क समस्याएँ हो सकती हैं। इसकी भविष्यवाणी करना संभव नहीं है, इसलिए हम मानों को सहेजते हैं और इसलिए किसी विशेष नोड के नीचे जाने की स्थिति में हम एक घटना रिपोर्ट तैयार कर सकते हैं। ऐसे में इसके होने का खतरा किसी के भी करीब नहीं है। यह सैद्धांतिक रूप से सर्वर पर क्लाइंट अनुरोधों की एक श्रृंखला जोड़ सकता है यदि MySQL के भीतर कुछ ताले हैं, लेकिन हमने अभी तक इस पर ध्यान नहीं दिया है। परीक्षणों की श्रृंखला यह नहीं दिखाती है इसलिए हमें खुशी होगी यदि आप अनुमति दे सकते हैं समस्या होने पर हम जानते हैं या समर्थन टिकट दाखिल करते हैं।
ऐसी कुछ स्थितियां हैं जहां एक घटना रिपोर्ट वैश्विक स्थिति चर एकत्र करने में सक्षम नहीं हो सकती है यदि क्लस्टर नियंत्रण से पहले डेटा एकत्र करने के लिए एक विशिष्ट फ्रेम को फ्रीज करने से पहले नेटवर्क समस्या समस्या थी। यह पूरी तरह से उचित है क्योंकि आगे निदान के लिए क्लस्टर कंट्रोल डेटा एकत्र करने का कोई तरीका नहीं है क्योंकि पहली जगह में नोड से कोई संबंध नहीं है।
अंत में, आपको आश्चर्य हो सकता है कि सभी चर वैश्विक स्थिति अनुभाग में क्यों नहीं दिखाए जाते हैं? इस बीच, हम एक फ़िल्टर सेट करते हैं जहां घटना रिपोर्ट में खाली या 0 मान शामिल नहीं होते हैं। कारण यह है कि हम कुछ डिस्क स्थान बचाना चाहते हैं। एक बार जब इन घटनाओं की रिपोर्ट की आवश्यकता नहीं रह जाती है, तो आप इसे ऑपरेशनल रिपोर्ट टैब के माध्यम से हटा सकते हैं।
MySQL फ़्रीज़ फ़्रेम फ़ीचर का परीक्षण
हमारा मानना है कि आप इसे आजमाने के लिए उत्सुक हैं और देखते हैं कि यह कैसे काम करता है। लेकिन कृपया, सुनिश्चित करें कि आप इसे लाइव या उत्पादन परिवेश में नहीं चला रहे हैं या इसका परीक्षण नहीं कर रहे हैं। हम MySQL/MariaDB में परिदृश्य के 2-चरणों को कवर करेंगे, एक मास्टर-स्लेव सेटअप के लिए और दूसरा गैलेरा-टाइप सेटअप के लिए।
मास्टर-स्लेव सेटअप परीक्षण परिदृश्य
एक मास्टर-स्लेव (एस) सेटअप में, कोशिश करना आसान और आसान है।
एक कदम
सुनिश्चित करें कि आपने नीचे की तरह स्वतः पुनर्प्राप्ति मोड (क्लस्टर और नोड) को अक्षम कर दिया है:

इसलिए यह परीक्षण परिदृश्य को ठीक करने का प्रयास या प्रयास नहीं करेगा।
दूसरा चरण
अपने मास्टर नोड पर जाएं और केवल-पढ़ने के लिए सेटिंग का प्रयास करें:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)तीसरा चरण
इस बार, एक अलार्म बजाया गया और इसलिए एक घटना की रिपोर्ट तैयार की गई। नीचे देखें कि मेरा क्लस्टर कैसा दिखता है:

और अलार्म चालू हो गया:

और घटना की रिपोर्ट तैयार की गई:

गैलेरा क्लस्टर सेटअप परीक्षण परिदृश्य
गैलेरा-आधारित सेटअप के लिए, हमें यह सुनिश्चित करने की आवश्यकता है कि क्लस्टर अब उपलब्ध नहीं रहेगा, अर्थात, क्लस्टर-व्यापी विफलता। मास्टर-स्लेव टेस्ट के विपरीत, आप ऑटो रिकवरी को सक्षम होने दे सकते हैं क्योंकि हम नेटवर्क इंटरफेस के साथ खेलेंगे।
ध्यान दें:इस सेटअप के लिए, सुनिश्चित करें कि आपके पास एक से अधिक इंटरफ़ेस हैं यदि आप एक दूरस्थ उदाहरण में नोड्स का परीक्षण कर रहे हैं क्योंकि आप इंटरफ़ेस को ऊपर नहीं ला सकते हैं जब आप उस इंटरफ़ेस को नीचे ला सकते हैं जहाँ आप जुड़े हुए हैं।
एक कदम
एक 3-नोड गैलेरा क्लस्टर बनाएं (उदाहरण के लिए योनि का उपयोग करके)
दूसरा चरण
नेटवर्क समस्या का अनुकरण करने के लिए कमांड जारी करें (बिल्कुल नीचे की तरह) और इसे सभी नोड्स में करें
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.तीसरा चरण
अब, इसने मेरे क्लस्टर को नीचे ले लिया और यह स्थिति है:

एक अलार्म उठाया,

और यह एक घटना रिपोर्ट तैयार करता है:

एक नमूना घटना रिपोर्ट के लिए, आप इस कच्ची फ़ाइल का उपयोग कर सकते हैं और इसे सहेज सकते हैं एचटीएमएल के रूप में।
कोशिश करना काफी आसान है लेकिन फिर से, कृपया इसे केवल एक गैर-जीवित और गैर-उत्पाद वातावरण में करें।
निष्कर्ष
ClusterControl में MySQL फ़्रीज़ फ़्रेम क्रैश का निदान करते समय सहायक हो सकता है। समस्या निवारण करते समय, कारण निर्धारित करने के लिए आपको बहुत सारी जानकारी की आवश्यकता होती है और ठीक यही MySQL फ़्रीज़ फ़्रेम प्रदान करता है।



