अपग्रेड हमेशा एक कठिन और समय लेने वाला कार्य होता है। सबसे पहले, आपको परीक्षण वातावरण में अपने आवेदन का परीक्षण करना चाहिए, इसलिए, आदर्श रूप से, आपको इसके लिए अपने वर्तमान उत्पादन वातावरण को क्लोन करना होगा। फिर, आपको अपग्रेड करने के लिए एक योजना बनाने की आवश्यकता है, जो व्यवसाय के आधार पर, शून्य डाउनटाइम (या लगभग शून्य) के साथ हो सकता है, या यह सुनिश्चित करने के लिए एक रखरखाव विंडो भी शेड्यूल कर सकता है कि अगर कुछ गलत हो जाता है, तो यह उतना ही प्रभावित होगा जितना संभव हो।
यदि आप इन सभी चीजों को मैन्युअल रूप से करना चाहते हैं, तो मानवीय त्रुटि की एक बड़ी संभावना है और प्रक्रिया धीमी हो जाएगी। इस ब्लॉग में, हम देखेंगे कि ClusterControl का उपयोग करके अपने MySQL, MariaDB, या Percona सर्वर डेटाबेस को अपग्रेड करने के लिए परीक्षण को स्वचालित कैसे करें।
उन्नयन के प्रकार
उन्नयन दो प्रकार के होते हैं:लघु उन्नयन और प्रमुख उन्नयन।
मामूली अपग्रेड
पहला वाला, माइनर अपग्रेड, सबसे आम और सुरक्षित अपग्रेड है, और ज्यादातर मामलों में, यह जगह पर किया जाता है। जैसा कि कुछ भी 100% सुरक्षित नहीं है, आपके पास हमेशा बैकअप और प्रतिकृति दास नोड होना चाहिए, इसलिए यदि अपग्रेड में कुछ गलत हो जाता है और किसी कारण से आप रोलबैक/डाउनग्रेड नहीं कर सकते हैं, तो आप एक दास नोड को बढ़ावा दे सकते हैं, और आपके सिस्टम अभी भी कर सकते हैं बिना किसी रुकावट के काम करें।
आप ClusterControl का उपयोग करके इस प्रकार का अपग्रेड कर सकते हैं। इसके लिए, ClusterControl पर जाएँ -> क्लस्टर चुनें -> मैनेज करें -> अपग्रेड करें।
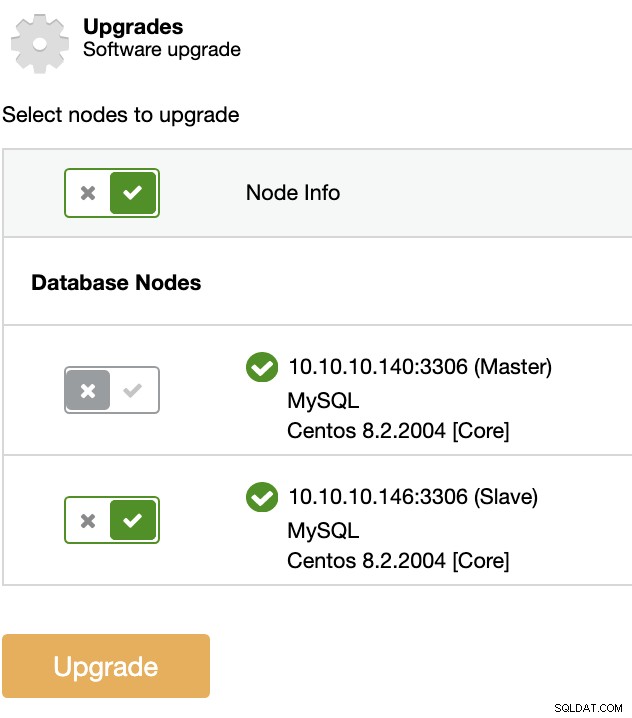
प्रत्येक चयनित नोड पर, अपग्रेड प्रक्रिया होगी:
-
स्टॉप नोड
-
नोड अपग्रेड करें
-
स्टार्ट नोड
प्रतिकृति टोपोलॉजी में मास्टर नोड को अपग्रेड नहीं किया जाएगा। मास्टर को अपग्रेड करने के लिए, पहले नए मास्टर बनने के लिए दूसरे नोड को बढ़ावा दिया जाना चाहिए।
प्रमुख अपग्रेड
प्रमुख अपग्रेड के लिए, इन-प्लेस अपग्रेड की अनुशंसा नहीं की जाती है, क्योंकि उत्पादन परिवेश के लिए कुछ गलत होने का जोखिम बहुत अधिक होता है। इसके बजाय, आप अपने वर्तमान डेटाबेस क्लस्टर को क्लोन कर सकते हैं और वहां अपने एप्लिकेशन का परीक्षण कर सकते हैं, और जब आप समाप्त कर लेते हैं, तो आप इसे फिर से बना सकते हैं या नए संस्करण में एक नया क्लस्टर भी बना सकते हैं और ट्रैफ़िक तैयार होने पर स्विच कर सकते हैं। इन उन्नयन के लिए अलग-अलग दृष्टिकोण हैं। आप नोड्स को एक-एक करके अपग्रेड कर सकते हैं, या वर्तमान से ट्रैफ़िक की नकल करते हुए एक अलग क्लस्टर बना सकते हैं, आप उच्च उपलब्धता और अधिक विकल्पों को बेहतर बनाने के लिए लोड बैलेंसर्स का भी उपयोग कर सकते हैं। सबसे अच्छा तरीका डाउनटाइम टॉलरेंस और रिकवरी टाइम ऑब्जेक्टिव (आरटीओ) पर निर्भर करता है।
आप सीधे ClusterControl के साथ प्रमुख अपग्रेड नहीं कर सकते, क्योंकि, जैसा कि हमने उल्लेख किया है, आपको यह सुनिश्चित करने के लिए पहले सब कुछ परीक्षण करने की आवश्यकता है, यह सुनिश्चित करने के लिए कि अपग्रेड सुरक्षित है, लेकिन आप इसे बनाने के लिए विभिन्न ClusterControl सुविधाओं का उपयोग कर सकते हैं। यह कार्य आसान। तो आइए देखते हैं इनमें से कुछ विशेषताएं।
बैकअप
किसी भी अपग्रेड से पहले बैकअप जरूरी है। एक अच्छी बैकअप पॉलिसी व्यवसाय के लिए बड़े मुद्दों से बच सकती है। तो, आइए देखें कि ClusterControl इसे कैसे स्वचालित कर सकता है।
बैकअप बनाना
ClusterControl पर जाएं -> क्लस्टर चुनें -> बैकअप -> बैकअप बनाएं।
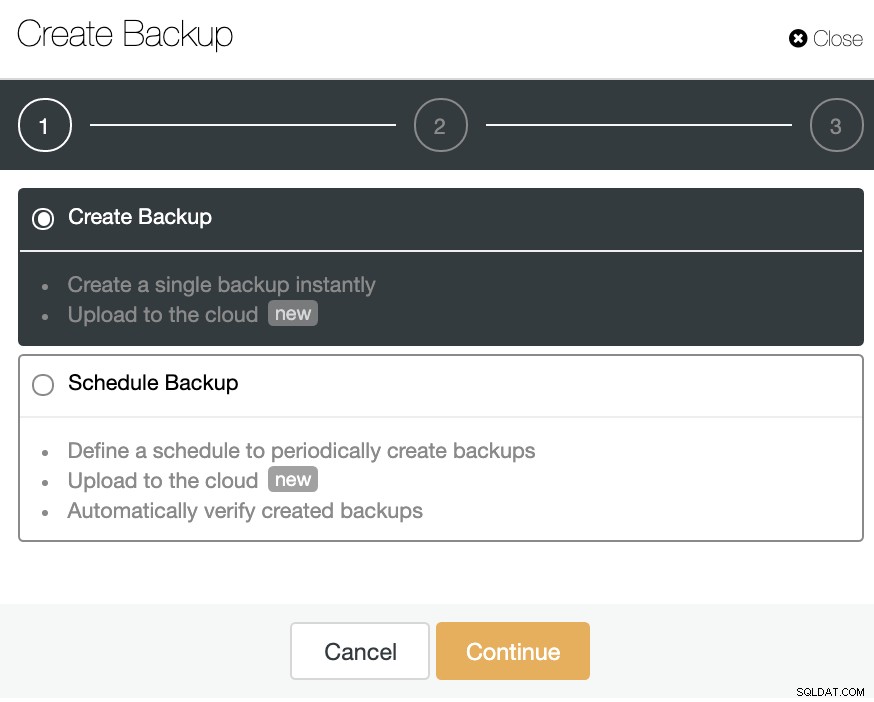
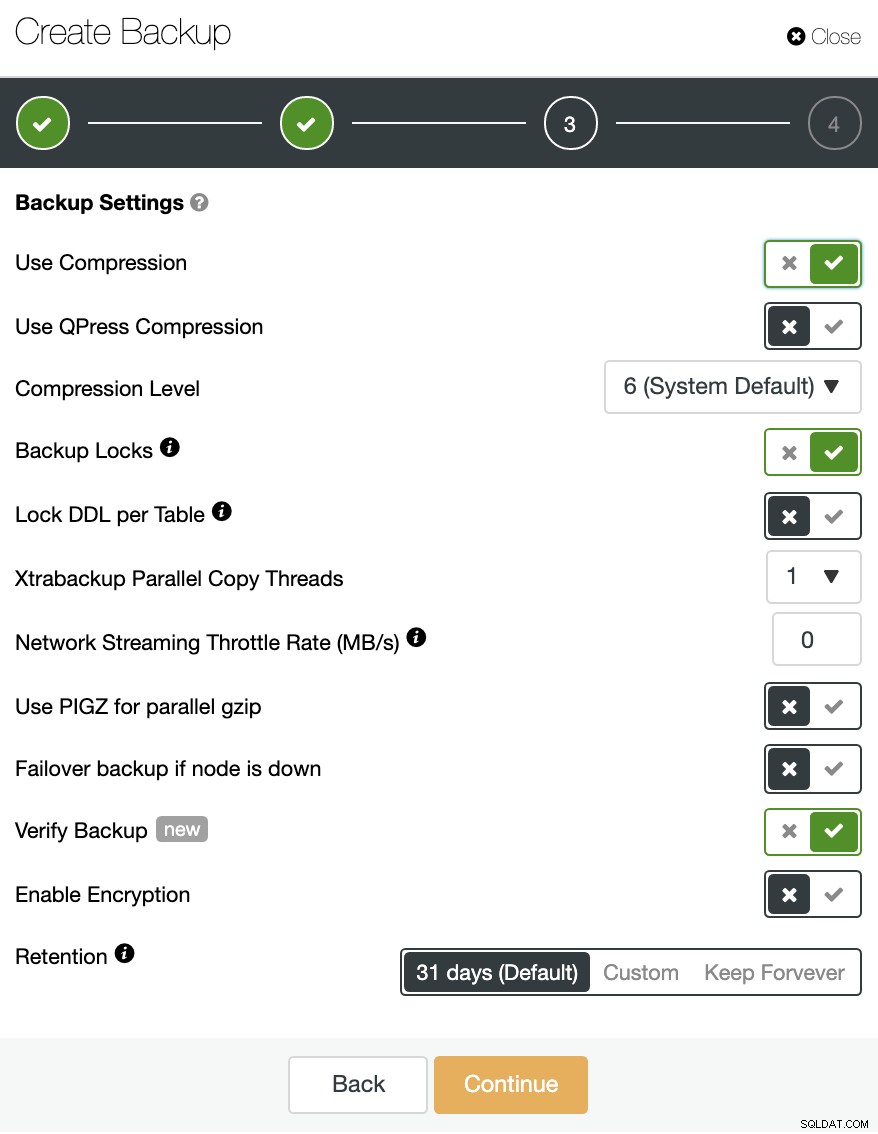
आप एक नया बैकअप बना सकते हैं या शेड्यूल किए गए बैकअप को कॉन्फ़िगर कर सकते हैं।
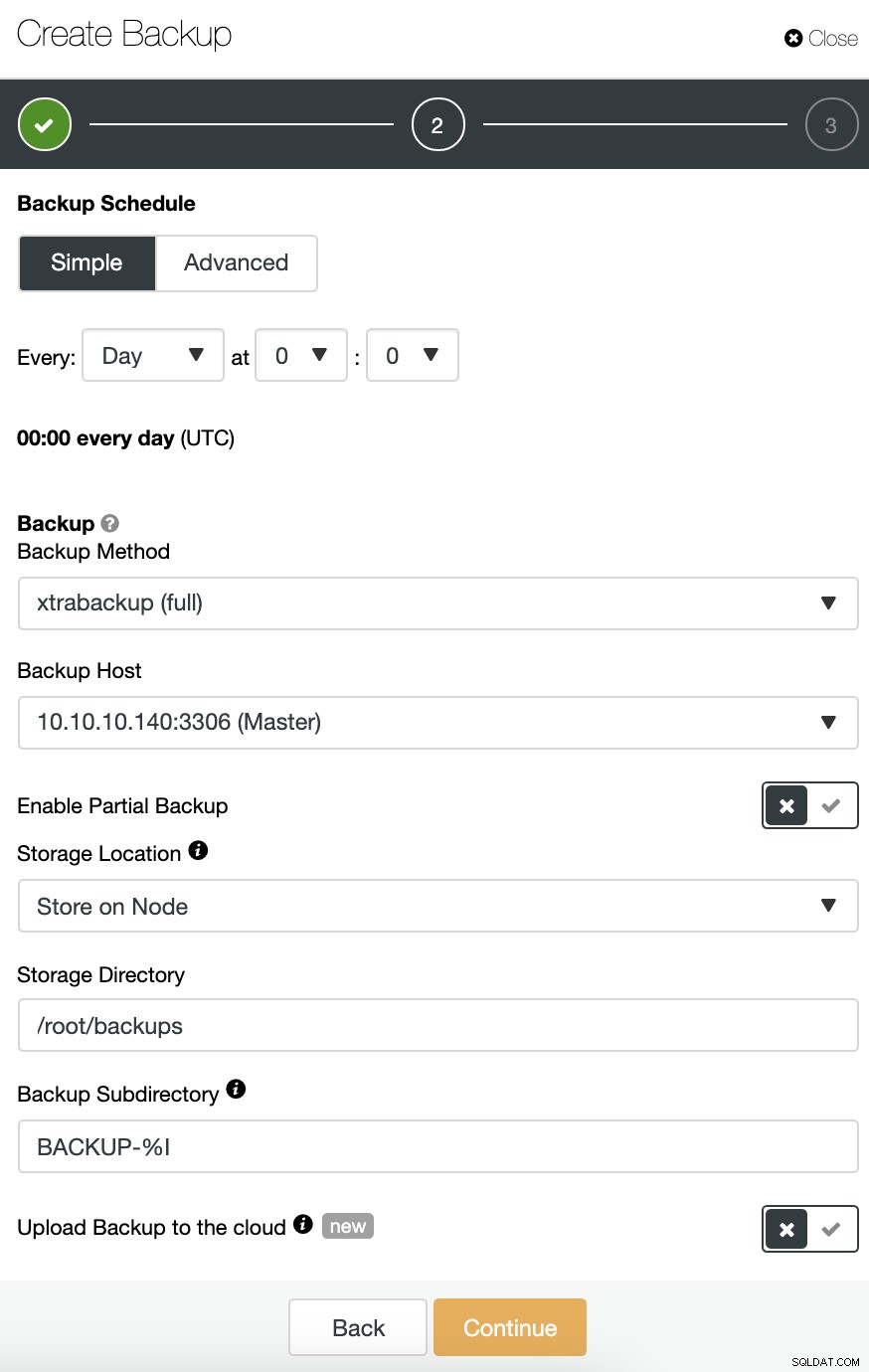
आप डेटाबेस प्रौद्योगिकी के आधार पर विभिन्न बैकअप विधियों का चयन कर सकते हैं, और, उसी अनुभाग में, आप उस सर्वर का चयन कर सकते हैं जिससे बैकअप लेना है, जहां आप बैकअप संग्रहीत करना चाहते हैं, और यदि आप उसी कार्य में बैकअप को क्लाउड (AWS, Azure, या Google Cloud) पर अपलोड करना चाहते हैं।
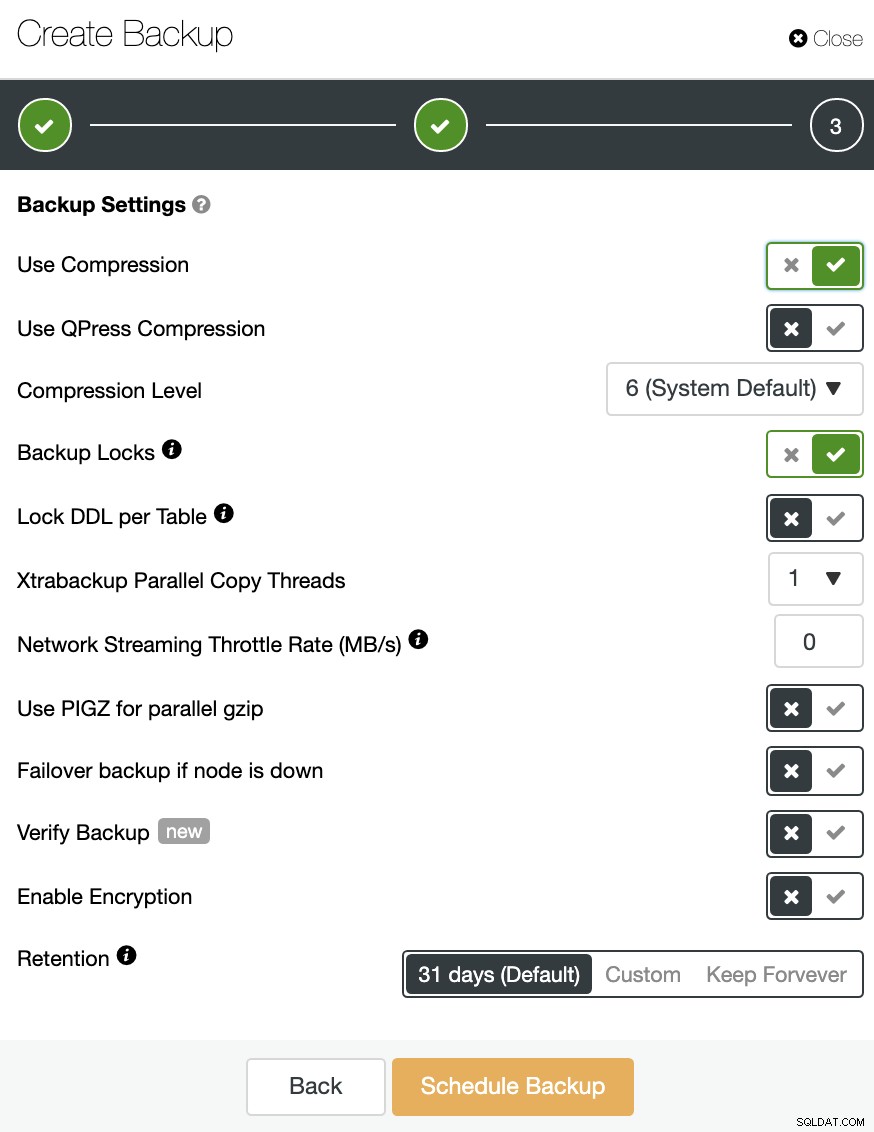
आप अपने बैकअप को संपीड़ित और एन्क्रिप्ट भी कर सकते हैं, और अन्य विकल्पों के साथ अवधारण अवधि निर्दिष्ट कर सकते हैं।
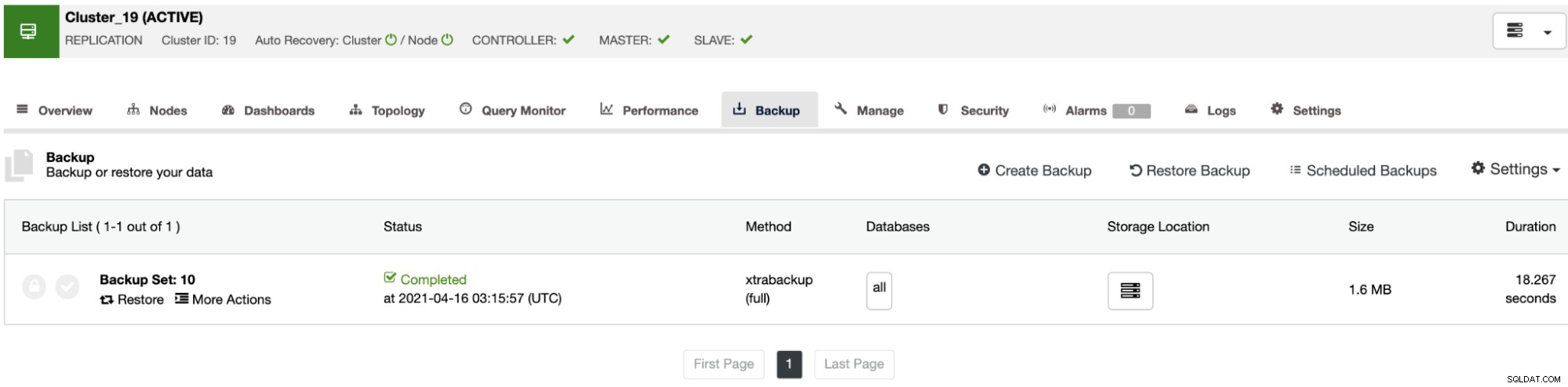
बैकअप अनुभाग पर, आप बैकअप की प्रगति और विधि, आकार, स्थान आदि जैसी जानकारी देख सकते हैं।
एक परीक्षण वातावरण परिनियोजित करना
इसके लिए, आपको शुरुआत से ही सब कुछ बनाने की ज़रूरत नहीं है। इसके बजाय, आप इसे मैन्युअल या स्वचालित तरीके से करने के लिए ClusterControl का उपयोग कर सकते हैं।
स्टैंडअलोन होस्ट पर बैकअप पुनर्स्थापित करें
बैकअप अनुभाग में, आप एक अलग नोड में बैकअप को पुनर्स्थापित करने के लिए "स्टैंडअलोन होस्ट पर पुनर्स्थापित और सत्यापित करें" विकल्प चुन सकते हैं।
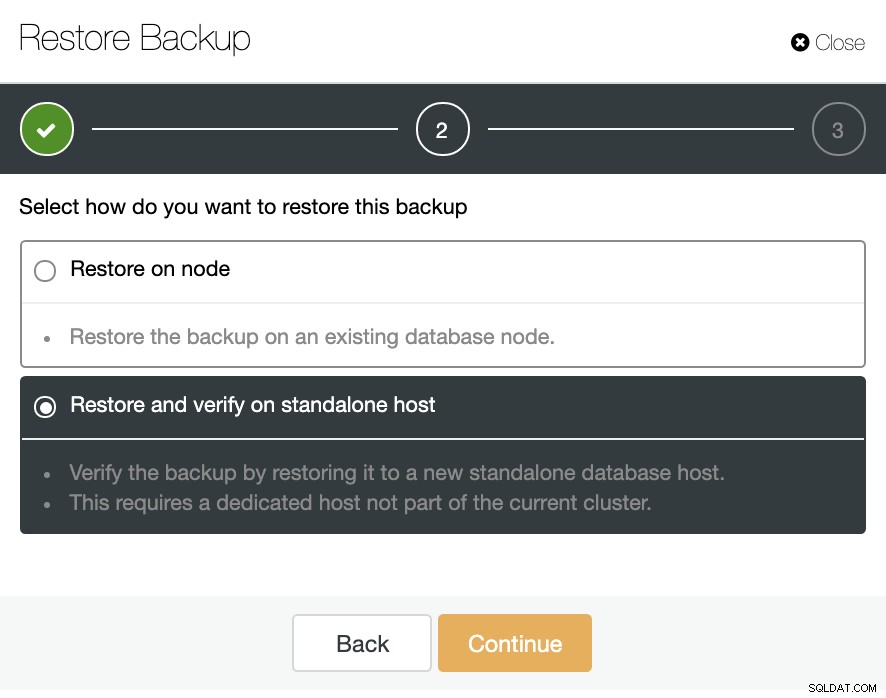
यहां आप निर्दिष्ट कर सकते हैं कि क्या आप चाहते हैं कि ClusterControl नए नोड में सॉफ़्टवेयर स्थापित करे, और फ़ायरवॉल या AppArmor/SELinux (OS के आधार पर) को अक्षम करें। इसके लिए, आपको एक समर्पित होस्ट (या VM) की आवश्यकता है जो क्लस्टर का हिस्सा नहीं है।
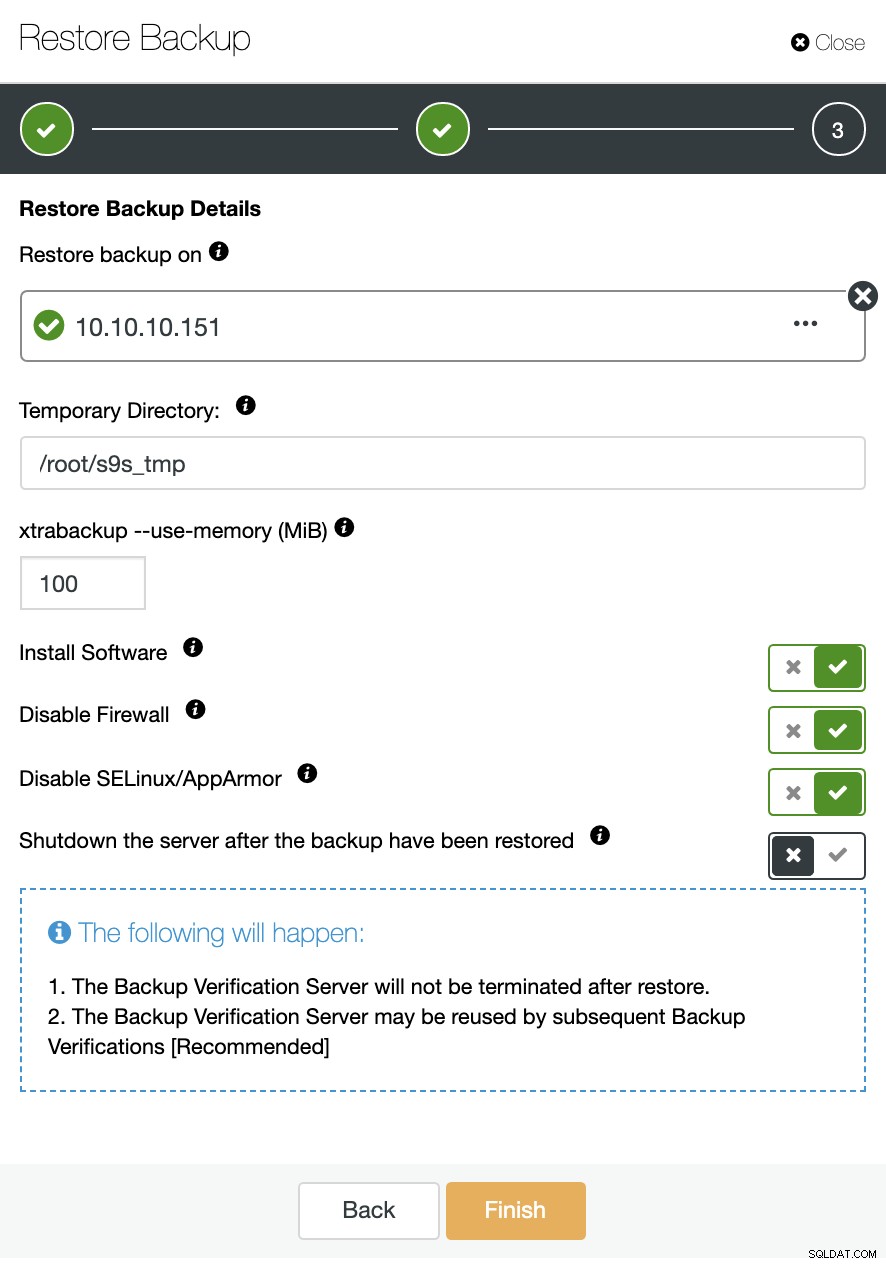
आप नोड को ऊपर और चालू रख सकते हैं, या ClusterControl अगली पुनर्स्थापना कार्य तक डेटाबेस सेवा को बंद कर सकता है। जब यह समाप्त हो जाता है, तो आप बैकअप सूची में एक टिक के साथ चिह्नित/पुनर्स्थापित/सत्यापित बैकअप देखेंगे।
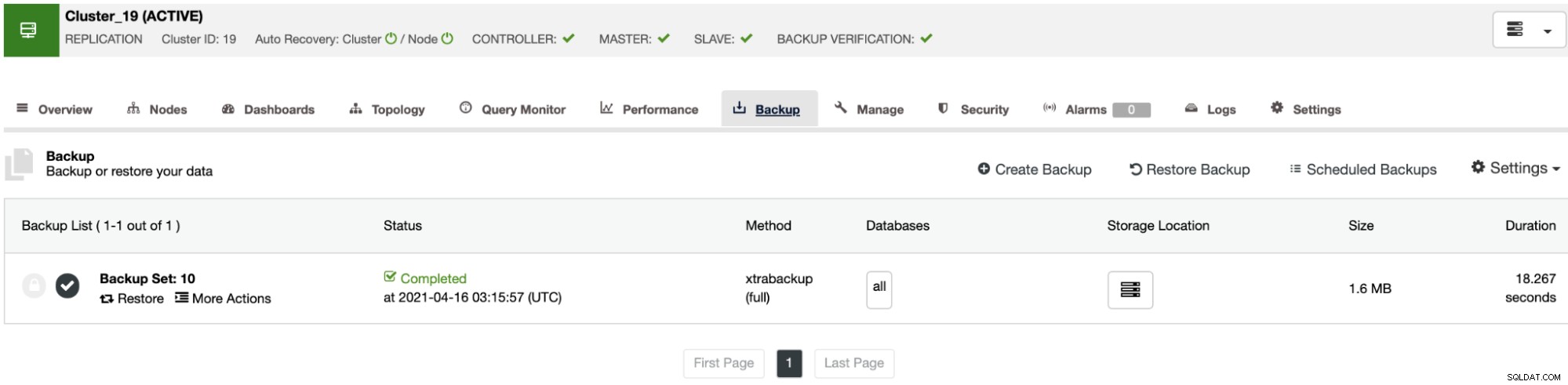
यदि आप इस कार्य को मैन्युअल रूप से नहीं करना चाहते हैं, तो आप बैकअप कार्य में इस कार्य को समय-समय पर दोहराने के लिए, बैकअप सत्यापित करें सुविधा का उपयोग करके इस प्रक्रिया को शेड्यूल कर सकते हैं। यह कैसे करना है, हम अगले भाग में देखेंगे।
स्वचालित क्लस्टर नियंत्रण बैकअप सत्यापन
इस कार्य को स्वचालित करने के लिए, ClusterControl पर जाएं -> अपना क्लस्टर चुनें -> बैकअप -> बैकअप बनाएं, और अनुसूचित बैकअप विकल्प चुनें।
स्वचालित बैकअप सत्यापित करें सुविधा केवल अनुसूचित बैकअप के लिए उपलब्ध है, और प्रक्रिया वही है जिसका वर्णन हमने पिछले अनुभाग में किया था। दूसरे चरण में, सुनिश्चित करें कि आपने बैकअप सत्यापित करें विकल्प को सक्षम किया है, और आवश्यक जानकारी को पूरा करें।
कार्य समाप्त होने पर, आप क्लस्टरकंट्रोल बैकअप अनुभाग में सत्यापन आइकन देख सकते हैं, वही जो आपको मैन्युअल तरीके से सत्यापन करने से होगा, उस अंतर के साथ जिसकी आपको आवश्यकता नहीं है मरम्मत कार्य को लेकर चिंतित हैं। ClusterControl हर बार स्वचालित रूप से बैकअप को पुनर्स्थापित करेगा, और आप नवीनतम डेटा के साथ अपने एप्लिकेशन का परीक्षण कर सकते हैं।
स्वतः पुनर्प्राप्ति और विफलता
स्वतः पुनर्प्राप्ति सुविधा सक्षम होने पर, विफलता के मामले में, ClusterControl सबसे उन्नत स्लेव नोड को मास्टर करने के लिए बढ़ावा देगा और साथ ही आपको समस्या के बारे में सूचित करेगा। यह नए मास्टर सर्वर से दोहराने के लिए बाकी स्लेव नोड्स पर भी विफल रहता है।
यदि टोपोलॉजी में लोड बैलेंसर हैं, तो ClusterControl उन्हें टोपोलॉजी परिवर्तनों को लागू करने के लिए पुन:कॉन्फ़िगर करेगा।
यदि आवश्यक हो तो आप मैन्युअल रूप से एक विफलता भी चला सकते हैं। ClusterControl पर जाएँ -> क्लस्टर चुनें -> नोड्स -> प्रचारित किए जाने वाले नोड का चयन करें -> नोड क्रियाएँ -> स्लेव को बढ़ावा दें।
इस तरह, अगर अपग्रेड के दौरान कुछ गलत हो जाता है, तो आप इसे जल्द से जल्द ठीक करने के लिए ClusterControl का उपयोग कर सकते हैं।
ClusterControl CLI के साथ चीजों को स्वचालित करना
ClusterControl CLI, जिसे s9s के रूप में भी जाना जाता है, ClusterControl संस्करण 1.4.1 में क्लस्टर कंट्रोल सिस्टम का उपयोग करके डेटाबेस क्लस्टर्स को इंटरैक्ट करने, नियंत्रित करने और प्रबंधित करने के लिए एक कमांड-लाइन टूल है। ClusterControl CLI क्लस्टर ऑटोमेशन के लिए एक द्वार खोलता है जहाँ आप इसे मौजूदा परिनियोजन ऑटोमेशन टूल जैसे Ansible, Puppet, Chef, आदि के साथ आसानी से एकीकृत कर सकते हैं। आइए अब इस टूल के कुछ उदाहरण देखें।
अपग्रेड करें
$ s9s cluster --cluster-id=19 \
--check-pkg-upgrades \
--log
$ s9s cluster --cluster-id=19 \
--available-upgrades \
--nodes='10.10.10.146' \
--log \
--print-json
$ s9s cluster --cluster-id=19 \
--upgrade-cluster \
--nodes='10.10.10.146' \
--logबैकअप बनाएं
$ s9s backup --create \
--backup-method=mysqldump \
--cluster-id=2 \
--nodes=10.10.10.146:3306 \
--on-controller \
--backup-directory=/storage/backups
--logबैकअप बहाल करें
$ s9s backup --restore \
--cluster-id=19 \
--backup-id=3 \
--waitबैकअप सत्यापित करें
$ s9s backup --verify \
--backup-id=3 \
--test-server=10.10.10.151 \
--cluster-id=19 \
--logस्लेव नोड को बढ़ावा दें
$ s9s cluster --promote-slave \
--cluster-id=19 \
--nodes='10.10.10.146' \
--logनिष्कर्ष
अपग्रेड आवश्यक हैं लेकिन समय लेने वाले कार्य हैं। हर बार जब आपको अपग्रेड करने की आवश्यकता होती है तो एक परीक्षण वातावरण को तैनात करना एक बुरा सपना हो सकता है, और बिना किसी स्वचालित उपकरण के इसे अप-टू-डेट बनाए रखना कठिन है।
ClusterControl आपको अपग्रेड कार्य को आसान और सुरक्षित बनाने के लिए मामूली अपग्रेड करने या यहां तक कि परीक्षण वातावरण को परिनियोजित करने की अनुमति देता है। आप इसे विभिन्न ऑटोमेशन टूल जैसे Ansible, Puppet, आदि के साथ भी एकीकृत कर सकते हैं।