पिछली ब्लॉग पोस्ट में, हमने स्केलिंग की मूल बातें कवर की हैं - यह क्या है, इसके प्रकार क्या हैं, यदि हम स्केल करना चाहते हैं तो क्या होना चाहिए। यह ब्लॉग पोस्ट चुनौतियों और उन तरीकों पर ध्यान केंद्रित करेगा जिनसे हम आगे बढ़ सकते हैं।
स्केलिंग आउट की चुनौती
डेटाबेस को स्केल करना कई कारणों से सबसे आसान काम नहीं है। आइए आपके डेटाबेस के बुनियादी ढांचे को बढ़ाने से संबंधित चुनौतियों पर थोड़ा ध्यान दें।
स्टेटफुल सर्विस
हम दो अलग-अलग प्रकार की सेवाओं में अंतर कर सकते हैं:स्टेटलेस और स्टेटफुल। स्टेटलेस सेवाएं वे हैं, जो किसी भी तरह के मौजूदा डेटा पर निर्भर नहीं करती हैं। आप बस आगे बढ़ सकते हैं, ऐसी सेवा शुरू करें और यह खुशी से काम करेगी। आपको डेटा की स्थिति और न ही सेवा के बारे में चिंता करने की ज़रूरत नहीं है। यदि यह चालू है, तो यह ठीक से काम करेगा और आप केवल मौजूदा वीएम, कंटेनरों या इसी तरह के अधिक क्लोन या प्रतियां जोड़कर आसानी से कई सेवा उदाहरणों में ट्रैफ़िक फैला सकते हैं। इस तरह की सेवा का एक उदाहरण एक वेब एप्लिकेशन हो सकता है - रेपो से तैनात, एक उचित रूप से कॉन्फ़िगर किया गया वेब सर्वर होने पर, ऐसी सेवा अभी शुरू होगी और ठीक से काम करेगी।
डेटाबेस के साथ समस्या यह है कि डेटाबेस सब कुछ है लेकिन स्टेटलेस है। डेटा को डेटाबेस में डाला जाना है, इसे संसाधित और जारी रखना है। डेटाबेस की छवि केवल ओएस छवि पर स्थापित कुछ पैकेजों से ज्यादा कुछ नहीं है और डेटा और उचित कॉन्फ़िगरेशन के बिना, यह बेकार है। यह डेटाबेस स्केलिंग की जटिलता को जोड़ता है। स्टेटलेस सेवाओं के लिए यह केवल उन्हें तैनात करने और कार्यभार में नए उदाहरणों को शामिल करने के लिए कुछ लोडबैलेंसरों को कॉन्फ़िगर करने के लिए है। डेटाबेस को परिनियोजित करने वाले डेटाबेस के लिए, उदाहरण केवल प्रारंभिक बिंदु है। आगे लेन डेटा प्रबंधन है - आपको अपने मौजूदा डेटाबेस इंस्टेंस से डेटा को नए में स्थानांतरित करना होगा। यह समस्या का एक महत्वपूर्ण हिस्सा हो सकता है और नए उदाहरणों के लिए यातायात को संभालना शुरू करने के लिए आवश्यक समय हो सकता है। डेटा स्थानांतरित होने के बाद ही हम मौजूदा प्रतिकृति टोपोलॉजी का हिस्सा बनने के लिए नए नोड्स सेट कर सकते हैं - अन्य नोड्स तक पहुंचने वाले ट्रैफ़िक के आधार पर डेटा को वास्तविक समय में अपडेट करना होगा।
बढ़ाने में लगने वाला समय
तथ्य यह है कि डेटाबेस स्टेटफुल सेवाएं हैं, दूसरी चुनौती का एक सीधा कारण है जिसका सामना हम तब करते हैं जब हम डेटाबेस इन्फ्रास्ट्रक्चर को बढ़ाना चाहते हैं। स्टेटलेस सेवाएं - आप बस उन्हें शुरू करें और बस। यह काफी तेज प्रक्रिया है। डेटाबेस के लिए, आपको डेटा ट्रांसफर करना होगा। इसमें कितना समय लगेगा, यह कई कारकों पर निर्भर करता है। डेटा सेट कितना बड़ा है? भंडारण कितना तेज है? नेटवर्क कितना तेज है? नए नोड को ताज़ा डेटा के साथ प्रोविज़न करने के लिए और क्या कदम उठाने होंगे? क्या इस प्रक्रिया में डेटा कंप्रेस्ड/डिकंप्रेस्ड या एन्क्रिप्टेड/डिक्रिप्टेड है? वास्तविक दुनिया में, नए नोड पर डेटा का प्रावधान करने में मिनटों से लेकर कई घंटों तक का समय लग सकता है। यह उन मामलों को गंभीरता से सीमित करता है जहां आप अपने डेटाबेस वातावरण को बढ़ा सकते हैं। लोड के अचानक, अस्थायी स्पाइक्स? वास्तव में नहीं, आप अतिरिक्त डेटाबेस नोड्स शुरू करने में सक्षम होने से पहले वे लंबे समय तक चले जा सकते हैं। अचानक और लगातार लोड बढ़ जाना? हां, अधिक नोड्स जोड़कर इससे निपटना संभव होगा लेकिन उन्हें लाने में और मौजूदा डेटाबेस नोड्स से ट्रैफ़िक लेने में घंटों भी लग सकते हैं।
स्केल अप प्रक्रिया के कारण अतिरिक्त भार
यह ध्यान रखना बहुत महत्वपूर्ण है कि वृद्धि के लिए आवश्यक समय समस्या का केवल एक पक्ष है। दूसरा पक्ष स्केलिंग प्रक्रिया के कारण होने वाला भार है। जैसा कि हमने पहले उल्लेख किया है, आपको पूरे डेटा सेट को नए जोड़े गए नोड्स में स्थानांतरित करना होगा। यह ऐसा कुछ नहीं है जिसे आप अनदेखा कर सकते हैं, आखिरकार, यह डिस्क से डेटा पढ़ने, इसे नेटवर्क पर भेजने और इसे एक नए स्थान पर संग्रहीत करने की एक घंटे की लंबी प्रक्रिया हो सकती है। यदि दाता, जिस नोड से आप डेटा पढ़ते हैं, अतिभारित है, तो आपको यह विचार करने की आवश्यकता है कि यदि उसे अतिरिक्त भारी I/O गतिविधि करने के लिए मजबूर किया जाएगा तो यह कैसे व्यवहार करेगा? यदि आपका क्लस्टर पहले से ही भारी दबाव में है और पतला फैला हुआ है तो क्या आपका क्लस्टर अतिरिक्त काम का बोझ उठाने में सक्षम होगा? उत्तर प्राप्त करना आसान नहीं हो सकता है क्योंकि नोड्स पर भार विभिन्न रूपों में आ सकता है। सीपीयू-बाउंड लोड सबसे अच्छा मामला होगा क्योंकि I/O गतिविधि कम होनी चाहिए और अतिरिक्त डिस्क संचालन प्रबंधनीय होगा। दूसरी ओर, I/O-बाउंड लोड, डेटा स्थानांतरण को महत्वपूर्ण रूप से धीमा कर सकता है, जिससे क्लस्टर की स्केल करने की क्षमता गंभीर रूप से प्रभावित हो सकती है।
स्केलिंग लिखें
जिस स्केल आउट प्रक्रिया का हमने पहले उल्लेख किया था, वह काफी हद तक स्केलिंग रीड तक सीमित है। यह समझना सर्वोपरि है कि स्केलिंग राइट एक पूरी तरह से अलग कहानी है। आप केवल अधिक नोड्स जोड़कर और अधिक बैकएंड नोड्स में रीड्स को फैलाकर रीड्स को स्केल कर सकते हैं। लेखन को मापना इतना आसान नहीं है। शुरुआत के लिए, आप इस तरह से लिखने का पैमाना नहीं बना सकते। प्रत्येक नोड जिसमें संपूर्ण डेटा सेट होता है, जाहिर है, क्लस्टर में कहीं भी किए गए सभी लेखन को संभालने की आवश्यकता होती है क्योंकि केवल डेटा सेट में सभी संशोधनों को लागू करने से यह स्थिरता बनाए रख सकता है। इसलिए, जब आप इसके बारे में सोचते हैं, इससे कोई फर्क नहीं पड़ता कि आप अपने क्लस्टर को कैसे डिज़ाइन करते हैं और आप किस तकनीक का उपयोग करते हैं, क्लस्टर के प्रत्येक सदस्य को प्रत्येक लेखन को निष्पादित करना होता है। चाहे वह एक प्रतिकृति हो, गैलेरा या इनो डीबी क्लस्टर जैसे मल्टी-मास्टर क्लस्टर में अपने मास्टर या नोड से सभी लेखन की प्रतिलिपि बनाना, क्लस्टर के अन्य सभी नोड्स पर किए गए डेटा सेट में सभी परिवर्तनों को निष्पादित करना, परिणाम समान है। केवल क्लस्टर में अधिक नोड जोड़ने से लेखन का दायरा नहीं बढ़ता है।
हम डेटाबेस को कैसे बढ़ा सकते हैं?
इसलिए, हम जानते हैं कि हम किस तरह की चुनौतियों का सामना कर रहे हैं। हमारे पास क्या विकल्प हैं? हम डेटाबेस को कैसे बढ़ा सकते हैं?
प्रतिकृति जोड़कर
सबसे पहले और सबसे महत्वपूर्ण, हम और अधिक नोड्स जोड़कर आसानी से विस्तार करेंगे। निश्चित रूप से, इसमें समय लगेगा और निश्चित रूप से, यह ऐसी प्रक्रिया नहीं है जिसकी आप तुरंत उम्मीद कर सकते हैं। ज़रूर, आप इस तरह के लेखन को स्केल नहीं कर पाएंगे। दूसरी ओर, आप जिस सबसे विशिष्ट समस्या का सामना कर रहे हैं, वह है सेलेक्ट प्रश्नों के कारण सीपीयू लोड और, जैसा कि हमने चर्चा की, क्लस्टर में केवल अधिक नोड्स जोड़कर रीड्स को बढ़ाया जा सकता है। पढ़ने के लिए अधिक नोड्स का मतलब है कि उनमें से प्रत्येक पर भार कम हो जाएगा। जब आप अपने आवेदन के जीवन चक्र में अपनी यात्रा की शुरुआत में हों, तो बस यह मान लें कि यह वही है जिससे आप निपटेंगे। सीपीयू लोड, कुशल प्रश्न नहीं। यह बहुत कम संभावना है कि आपको जीवन चक्र में आगे तक लिखने की आवश्यकता होगी, जब आपका आवेदन पहले ही परिपक्व हो चुका हो और आपको ग्राहकों की संख्या से निपटना पड़े।
शार्डिंग करके
नोड्स जोड़ने से लिखने की समस्या का समाधान नहीं होगा, यही हमने स्थापित किया है। इसके बजाय आपको जो करना है वह है शार्डिंग - क्लस्टर में डेटा सेट को विभाजित करना। इस मामले में प्रत्येक नोड में डेटा का केवल एक हिस्सा होता है, सबकुछ नहीं। यह हमें अंततः लेखन स्केलिंग शुरू करने की अनुमति देता है। मान लें कि हमारे पास चार नोड हैं, जिनमें से प्रत्येक में आधा डेटा सेट है।
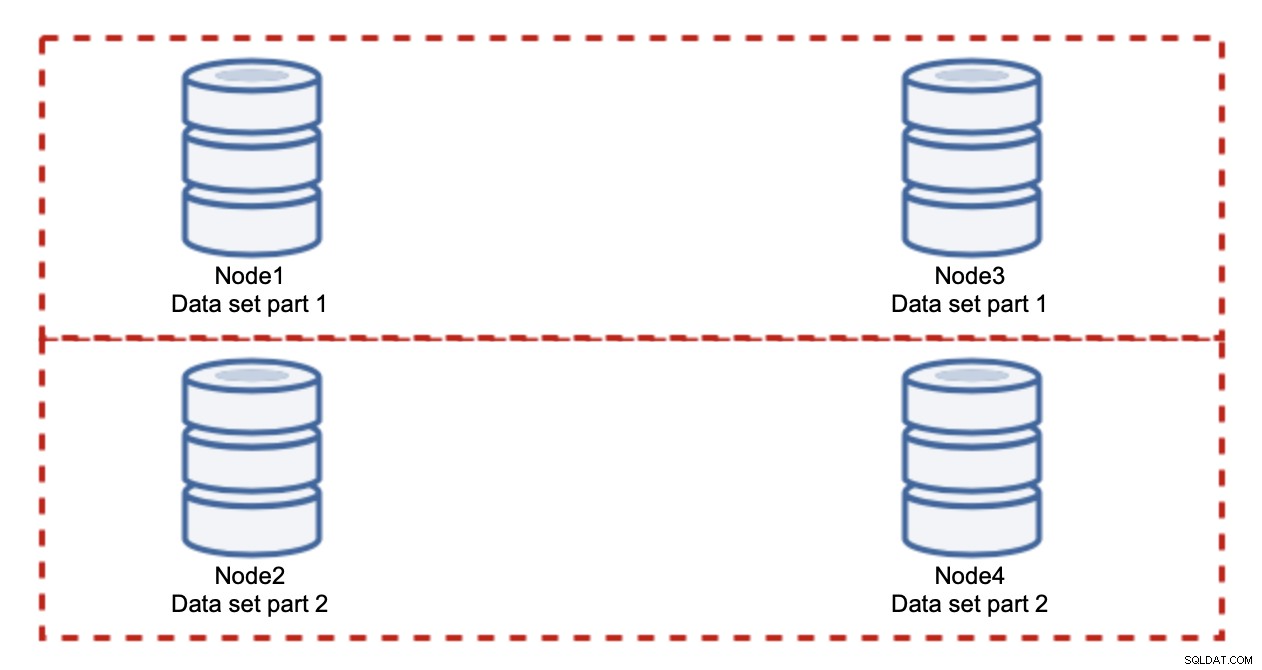
जैसा कि आप देख सकते हैं, विचार सरल है। यदि लेखन डेटा सेट के भाग 1 से संबंधित है, तो इसे नोड 1 और नोड 3 पर निष्पादित किया जाएगा। यदि यह डेटा सेट के भाग 2 से संबंधित है, तो इसे नोड 2 और नोड 4 पर निष्पादित किया जाएगा। आप डेटाबेस नोड्स को RAID में डिस्क के रूप में सोच सकते हैं। यहाँ हमारे पास अतिरेक के लिए RAID10, दर्पण के दो जोड़े का एक उदाहरण है। वास्तविक कार्यान्वयन में यह अधिक जटिल हो सकता है, आपके पास बेहतर उच्च उपलब्धता के लिए डेटा की एक से अधिक प्रतिकृति हो सकती है। सार यह है कि, डेटा का पूरी तरह से उचित विभाजन मानते हुए, आधे लेखन नोड 1 और नोड 3 और अन्य आधे नोड्स 2 और 4 हिट करेंगे। यदि आप लोड को और भी विभाजित करना चाहते हैं, तो आप नोड्स की तीसरी जोड़ी पेश कर सकते हैं:
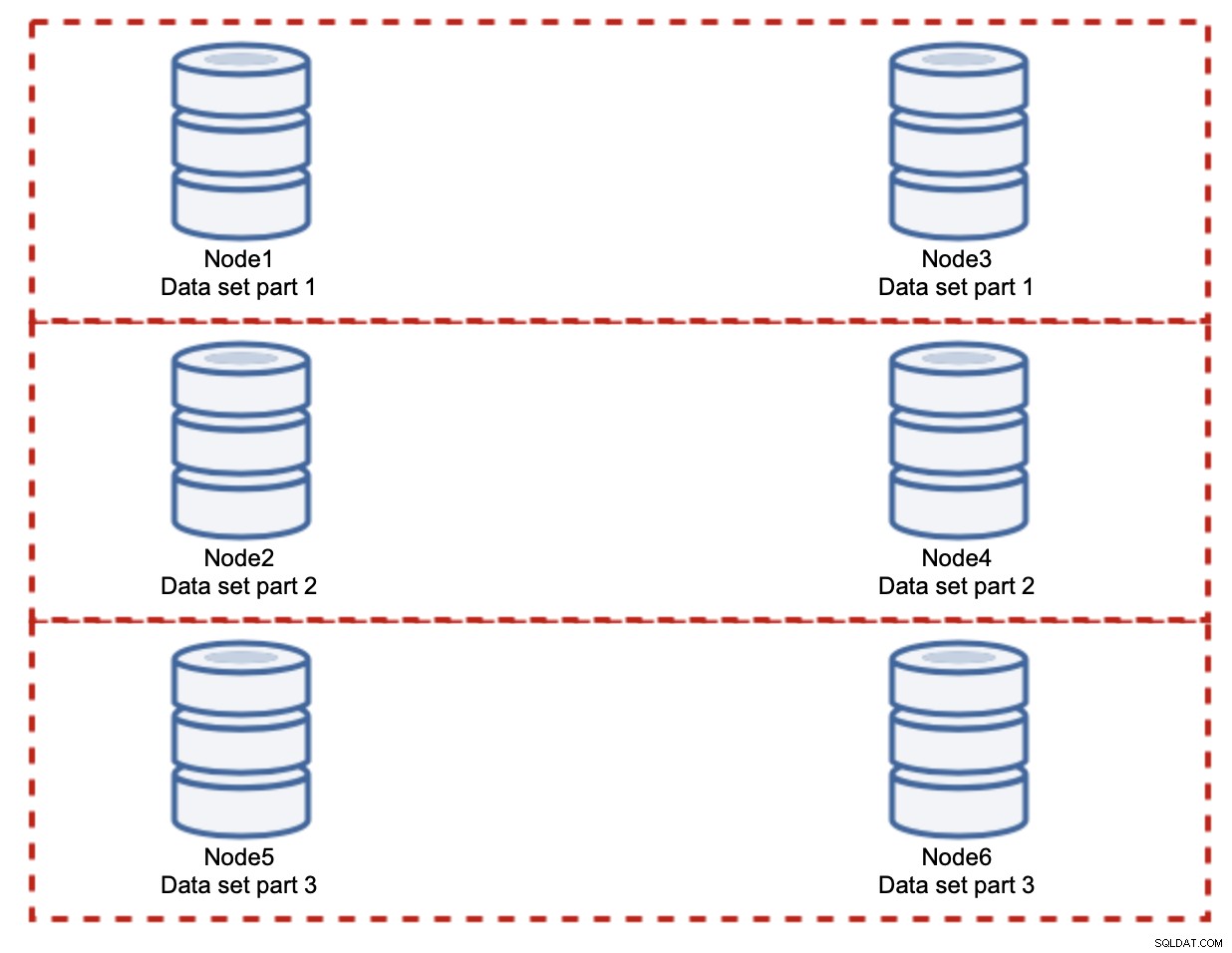
इस मामले में, फिर से, पूरी तरह से निष्पक्ष विभाजन मानते हुए, प्रत्येक जोड़ी क्लस्टर को लिखे जाने वाले सभी 33% के लिए जिम्मेदार होंगे।
यह काफी हद तक शार्डिंग के विचार का सार है। हमारे उदाहरण में, अधिक शार्क जोड़कर, हम डेटाबेस नोड्स पर लिखने की गतिविधि को मूल I/O लोड के 33% तक कम कर सकते हैं। जैसा कि आप कल्पना कर सकते हैं, यह कमियों के बिना नहीं आता है।
मैं कैसे पता लगाऊंगा कि मेरा डेटा किस शार्ड पर स्थित है? विवरण इस कॉल के दायरे से बाहर हैं लेकिन संक्षेप में, आप या तो किसी दिए गए कॉलम पर किसी प्रकार के फ़ंक्शन को लागू कर सकते हैं (मॉड्यूलो या 'आईडी' कॉलम पर हैश) या आप एक अलग मेटाडेटाबेस बना सकते हैं जहां आप विवरण स्टोर करेंगे डेटा कैसे वितरित किया जाता है।
हम आशा करते हैं कि आपको यह लघु ब्लॉग श्रृंखला जानकारीपूर्ण लगी होगी और जब हम डेटाबेस परिवेश का विस्तार करना चाहते हैं, तो आपको हमारे सामने आने वाली विभिन्न चुनौतियों के बारे में बेहतर समझ मिली होगी। यदि इस विषय पर आपकी कोई टिप्पणी या सुझाव है, तो कृपया बेझिझक इस पोस्ट के नीचे टिप्पणी करें और अपना अनुभव साझा करें