हमने आपके डेटाबेस टोपोलॉजी में लोड बैलेंसर का उपयोग करने के लाभों का कई बार उल्लेख किया है। यह ट्रैफ़िक को स्वस्थ डेटाबेस नोड्स पर पुनर्निर्देशित करने, प्रदर्शन को बेहतर बनाने के लिए कई सर्वरों में ट्रैफ़िक वितरित करने, या आसान कॉन्फ़िगरेशन और फ़ेलओवर प्रक्रिया के लिए आपके एप्लिकेशन में केवल एक एंडपॉइंट कॉन्फ़िगर करने के लिए हो सकता है।
अब नए ClusterControl 1.7.6 संस्करण के साथ, आप न केवल अपने PostgreSQL क्लस्टर को सीधे क्लाउड में तैनात कर सकते हैं, बल्कि आप उसी कार्य में लोड बैलेंसर्स को भी तैनात कर सकते हैं। इसके लिए, ClusterControl क्लाउड प्रदाताओं के रूप में AWS, Google क्लाउड और Azure का समर्थन करता है। आइए इस नई सुविधा पर एक नज़र डालते हैं।
नया डेटाबेस क्लस्टर बनाना
इस उदाहरण के लिए, हम मान लेंगे कि आपके पास उल्लिखित समर्थित क्लाउड प्रदाताओं में से एक के साथ एक खाता है, और ClusterControl 1.7.6 स्थापना में आपके क्रेडेंशियल कॉन्फ़िगर किए गए हैं।
यदि आपने इसे कॉन्फ़िगर नहीं किया है, तो आपको ClusterControl -> Integrations -> Cloud Providers -> Add Cloud Credentials पर जाना होगा।

यहां, आपको क्लाउड प्रदाता चुनना होगा और संबंधित जानकारी जोड़नी होगी। 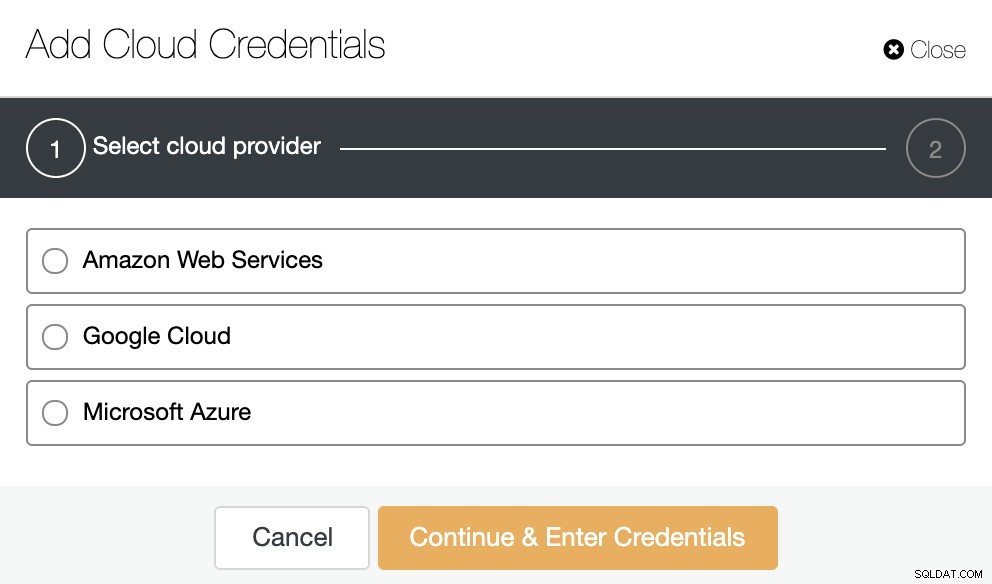
यह जानकारी स्वयं क्लाउड प्रदाता पर निर्भर करती है। अधिक जानकारी के लिए, आप हमारे आधिकारिक दस्तावेज देख सकते हैं।
कुछ भी बनाने के लिए आपको अपने क्लाउड प्रदाता प्रबंधन कंसोल तक पहुंचने की आवश्यकता नहीं है, आप अपने वर्चुअल मशीन, डेटाबेस और लोड बैलेंसर्स को सीधे ClusterControl से तैनात कर सकते हैं। डिप्लॉयमेंट सेक्शन में जाएं और "क्लाउड में डिप्लॉय करें" चुनें।
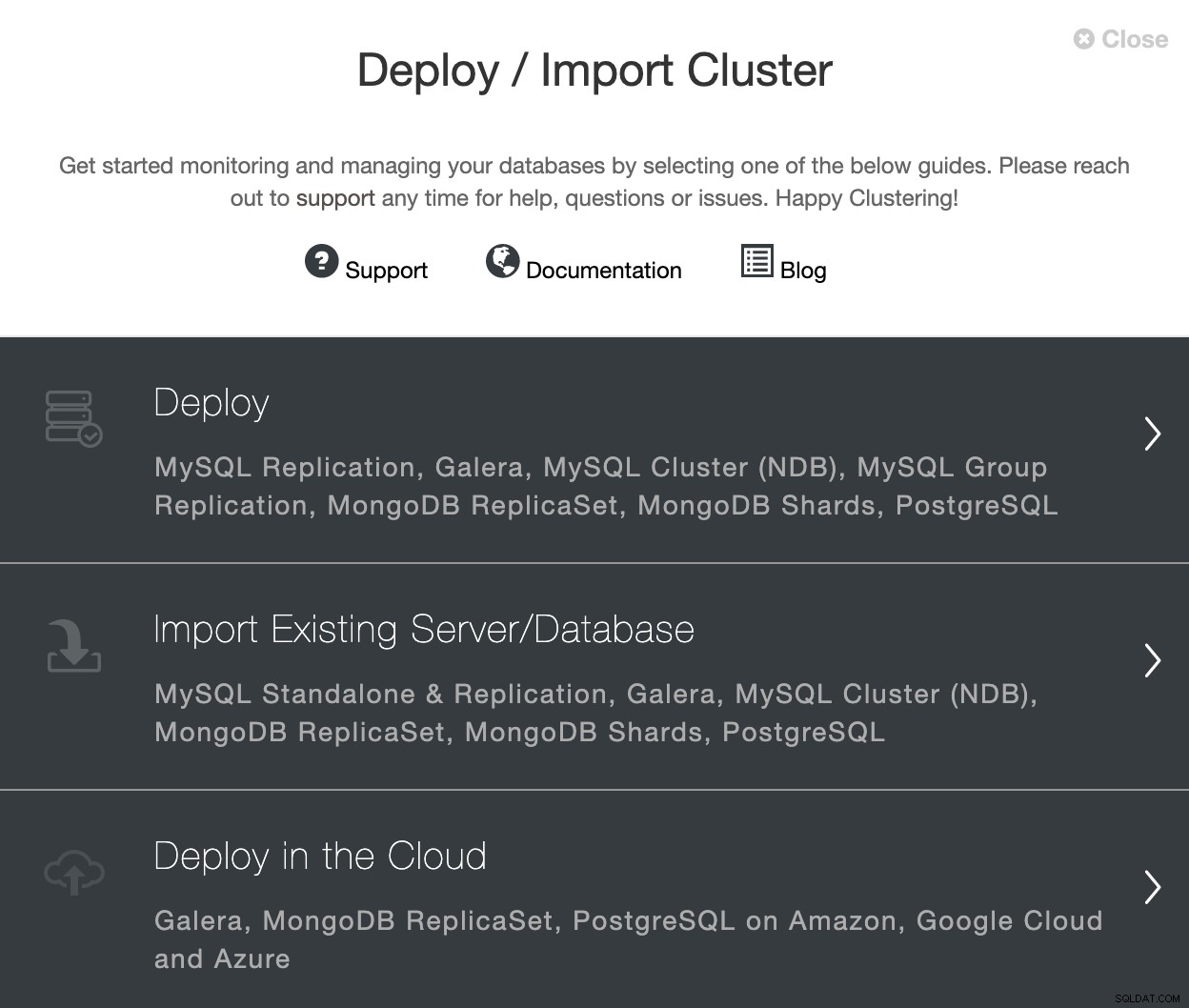
अपने नए डेटाबेस क्लस्टर के लिए विक्रेता और संस्करण निर्दिष्ट करें। इस मामले में, हम PostgreSQL 12 का उपयोग करेंगे।
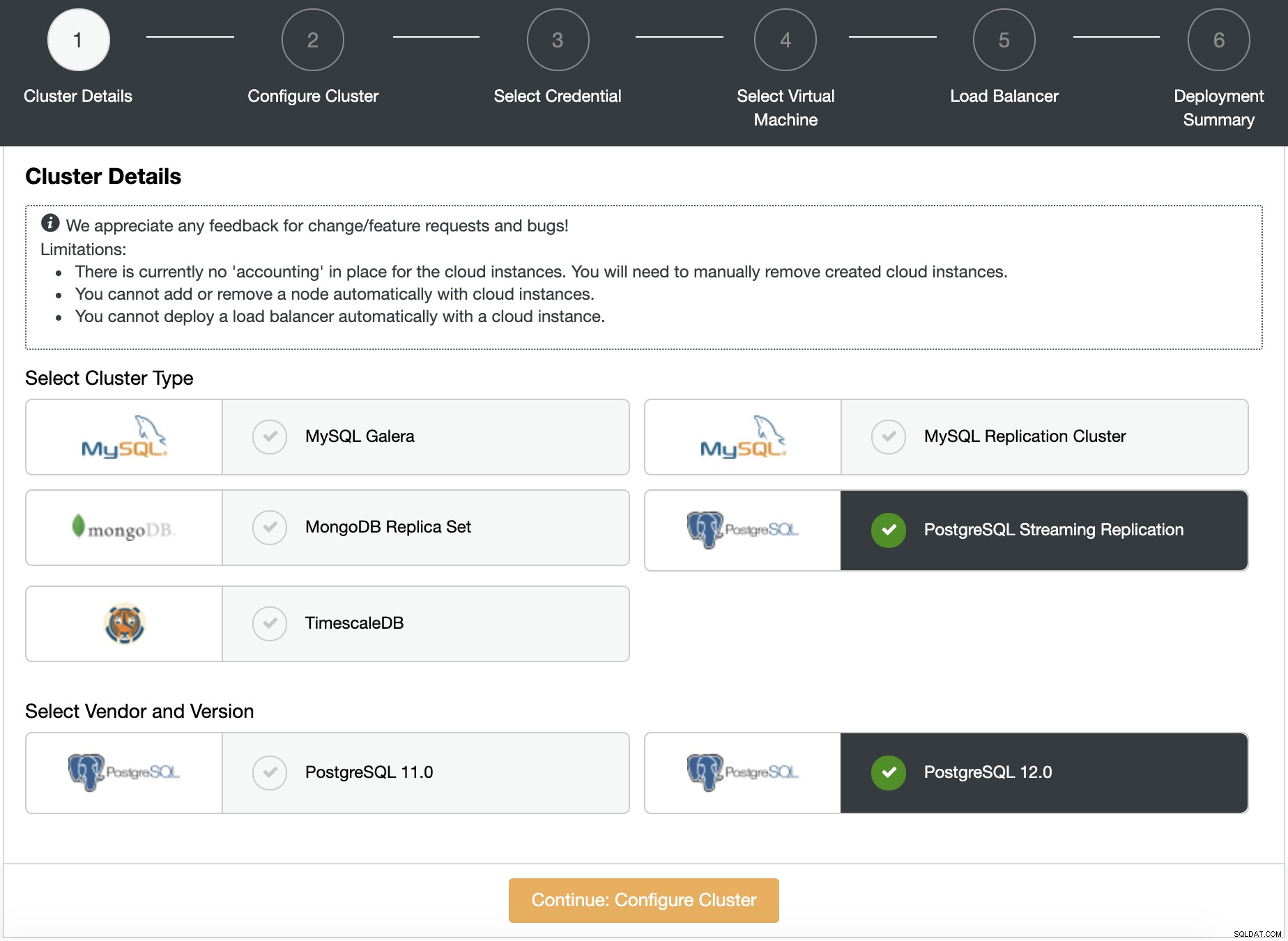
नोड्स की संख्या, क्लस्टर नाम और डेटाबेस जानकारी जैसे क्रेडेंशियल और सर्वर पोर्ट।
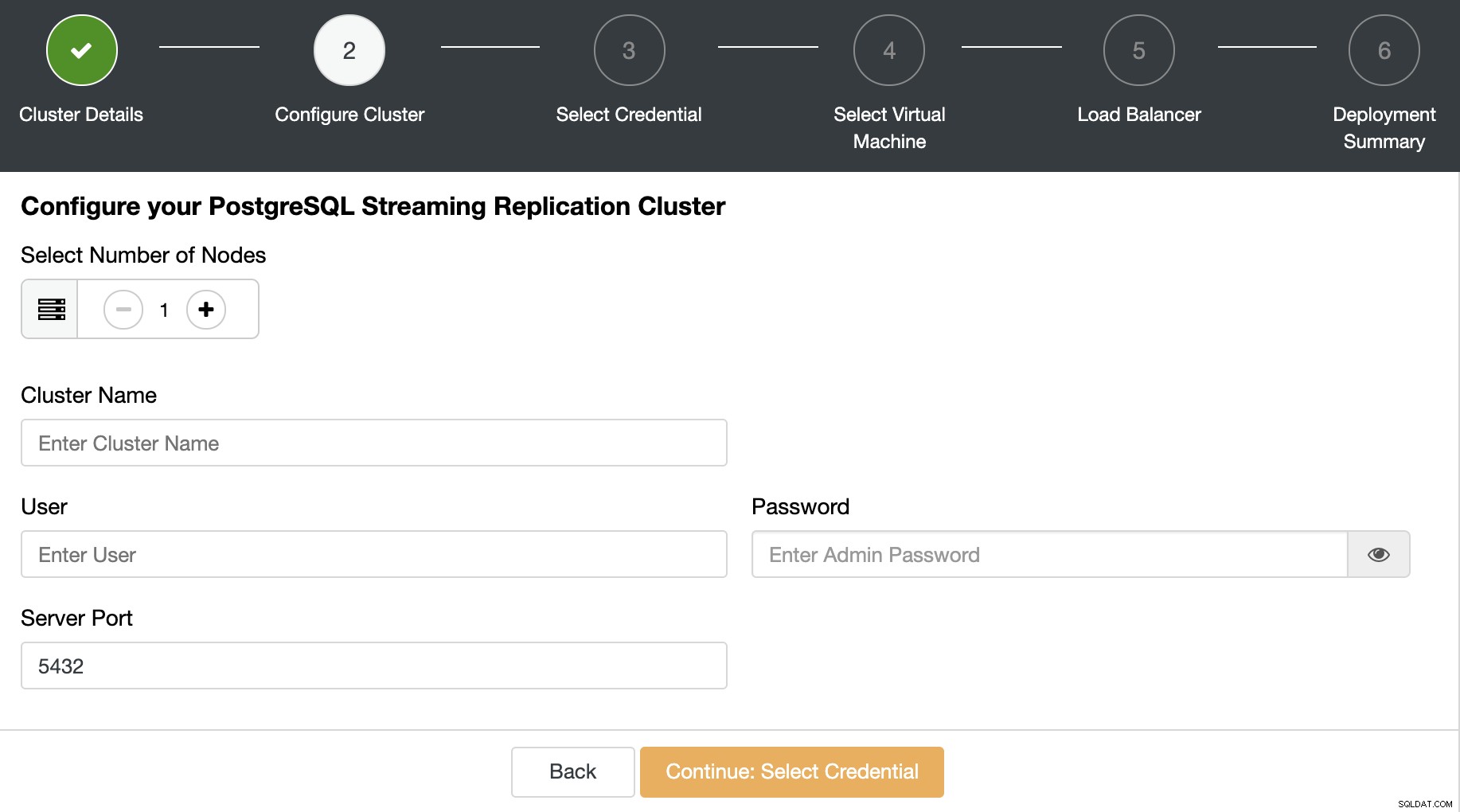
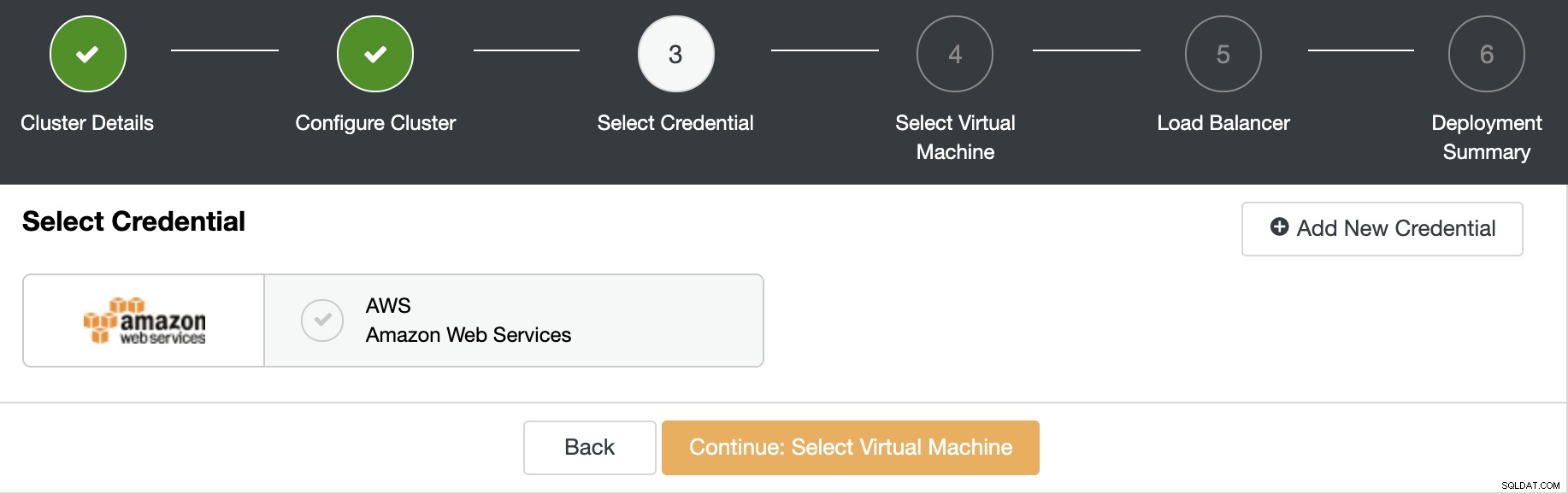
क्लाउड क्रेडेंशियल चुनें, इस मामले में, हम AWS का उपयोग करेंगे खाता। यदि आपने अभी तक अपना खाता ClusterControl में नहीं जोड़ा है, तो आप इस कार्य के लिए हमारे दस्तावेज़ों का पालन कर सकते हैं।
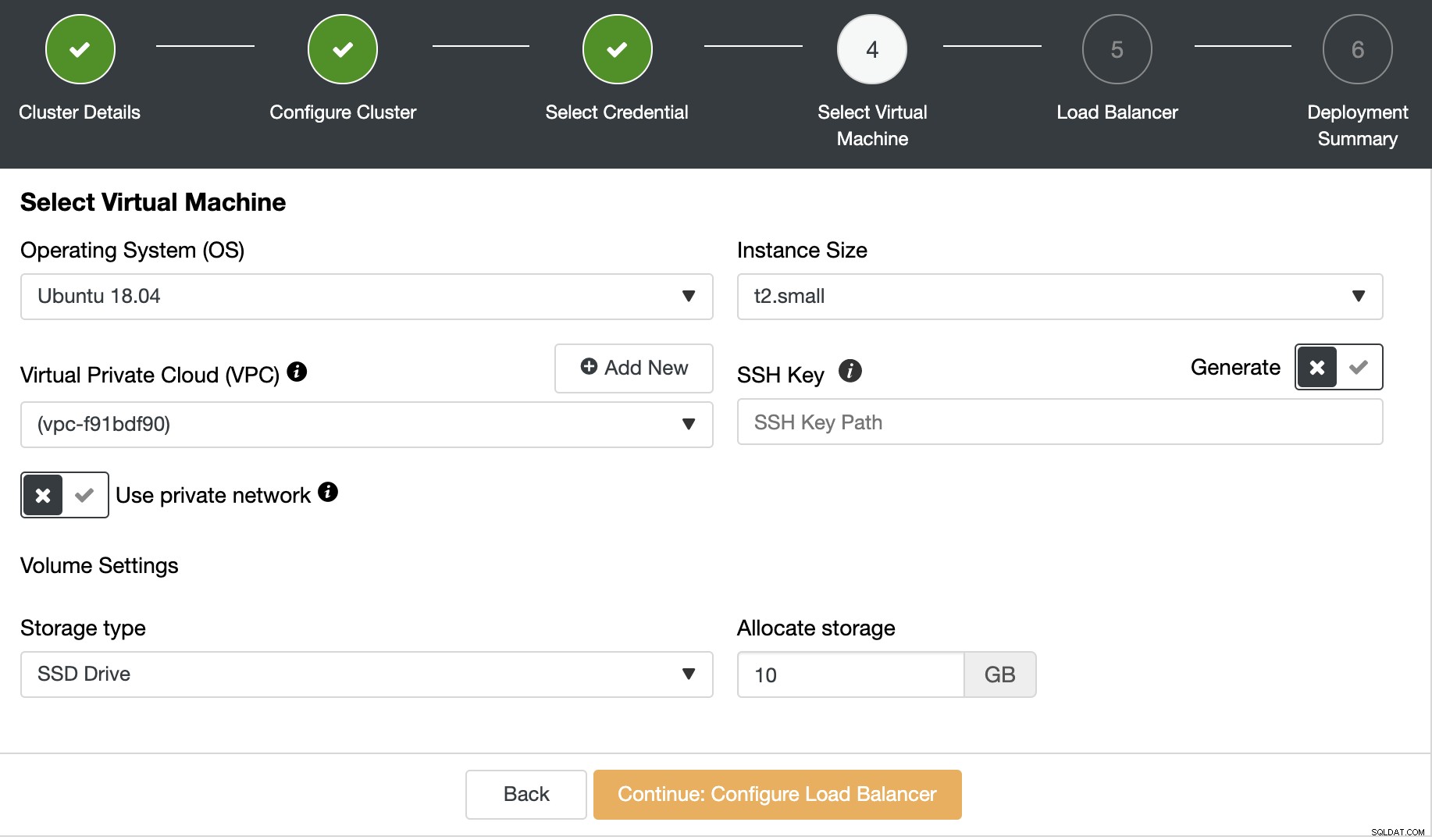
अब आपको वर्चुअल मशीन कॉन्फ़िगरेशन, जैसे ऑपरेटिंग सिस्टम, आकार, निर्दिष्ट करना होगा। और क्षेत्र।
अगले चरण में, आप अपने डेटाबेस क्लस्टर में लोड बैलेंसर्स जोड़ सकते हैं। PostgreSQL के लिए, ClusterControl लोड बैलेंसर के रूप में HAProxy का समर्थन करता है। आपको लोड बैलेंसर नोड्स की संख्या, इंस्टेंस आकार और लोड बैलेंसर जानकारी का चयन करने की आवश्यकता है।
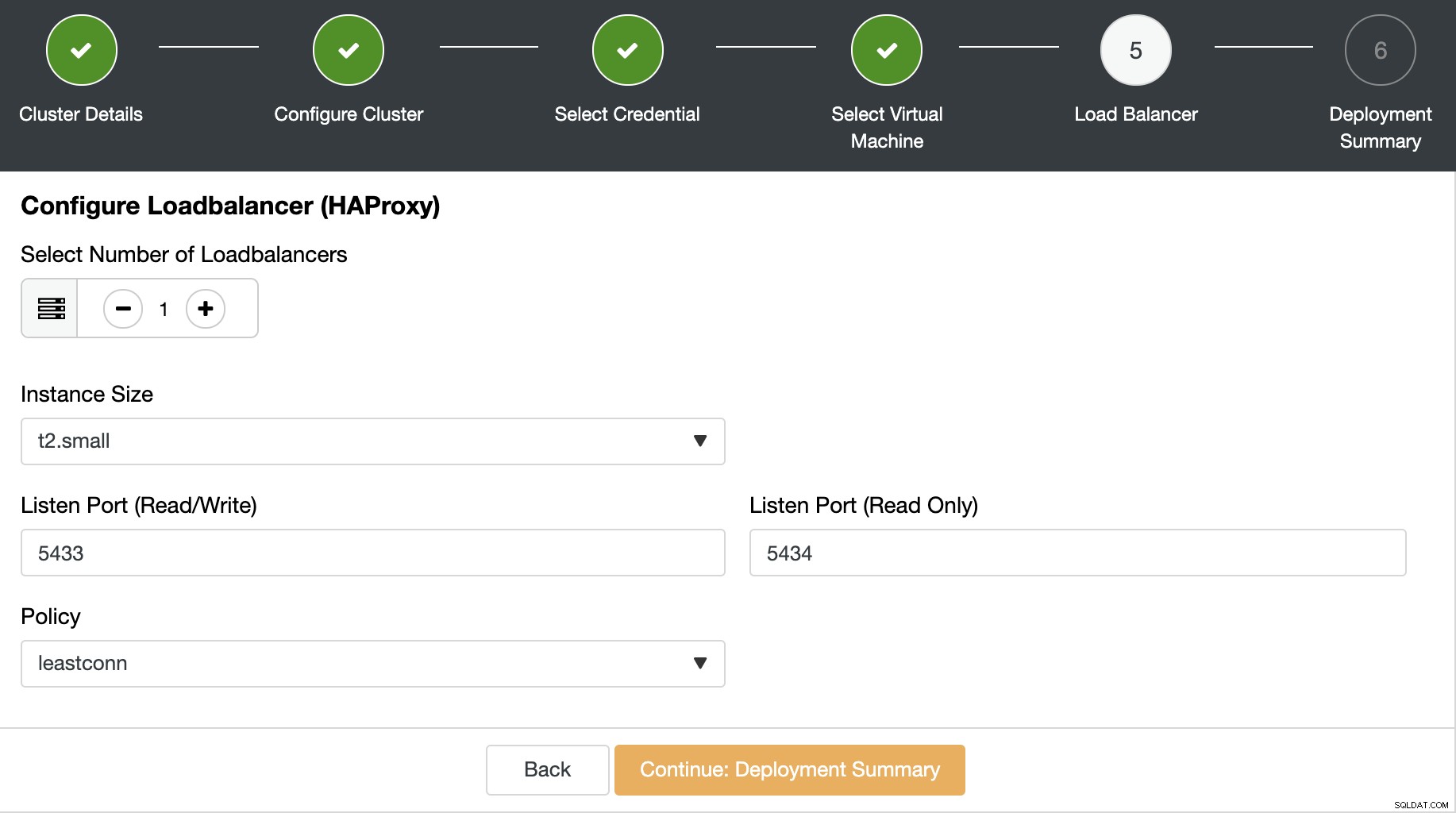
यह लोड बैलेंसर जानकारी है:
- सुनो पोर्ट (पढ़ें/लिखें):ट्रैफ़िक पढ़ने/लिखने के लिए पोर्ट।
- सुनो पोर्ट (केवल-पढ़ने के लिए):केवल-पढ़ने के लिए ट्रैफ़िक के लिए पोर्ट।
- नीति:यह हो सकता है:
- leastconn:सबसे कम कनेक्शन वाला सर्वर कनेक्शन प्राप्त करता है
- राउंडरोबिन:प्रत्येक सर्वर का उपयोग बारी-बारी से, उनके वजन के अनुसार किया जाता है
- स्रोत:स्रोत आईपी पता हैश किया गया है और चल रहे सर्वर के कुल भार से विभाजित किया गया है ताकि यह निर्दिष्ट किया जा सके कि कौन सा सर्वर अनुरोध प्राप्त करेगा
अब आप सारांश की समीक्षा कर सकते हैं और उसे परिनियोजित कर सकते हैं।
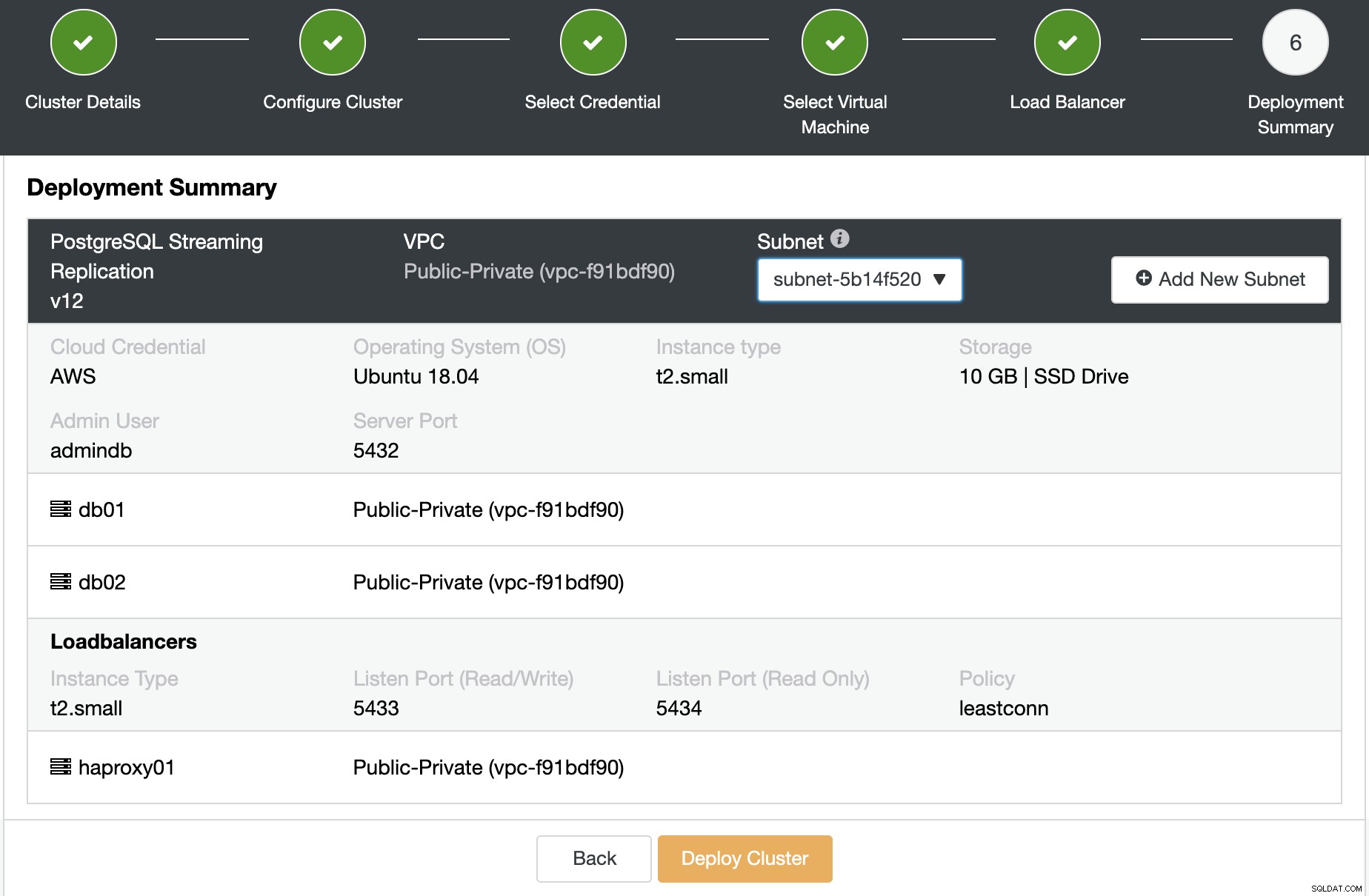
ClusterControl वर्चुअल मशीन बनाएगा, सॉफ्टवेयर इंस्टॉल करेगा और इसे कॉन्फिगर करेगा, सभी एक ही काम में और एक अप्राप्य तरीके से।
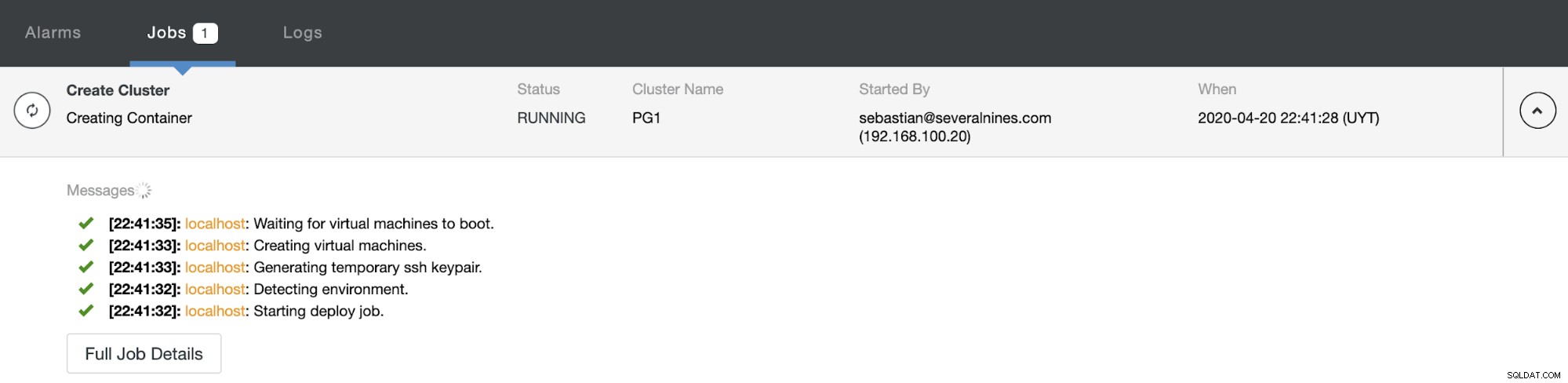
आप ClusterControl गतिविधि अनुभाग में निर्माण प्रक्रिया की निगरानी कर सकते हैं। जब यह समाप्त हो जाएगा, तो आप अपने नए क्लस्टर को ClusterControl मुख्य स्क्रीन में देखेंगे।

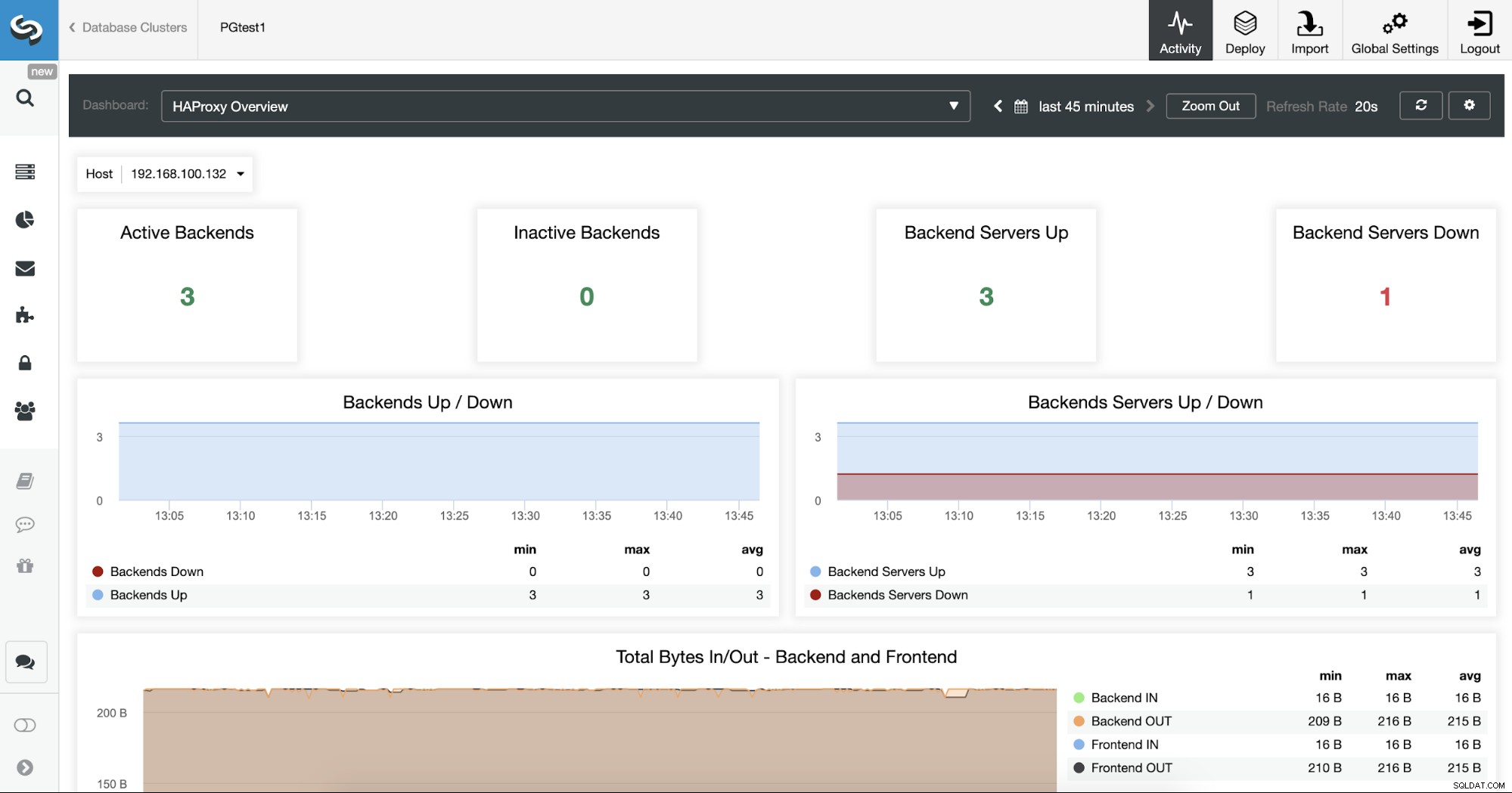
यदि आप लोड बैलेंसर्स नोड्स की जांच करना चाहते हैं, तो आप ClusterControl पर जा सकते हैं। -> नोड्स -> HAProxy नोड, और वर्तमान स्थिति की जाँच करें।
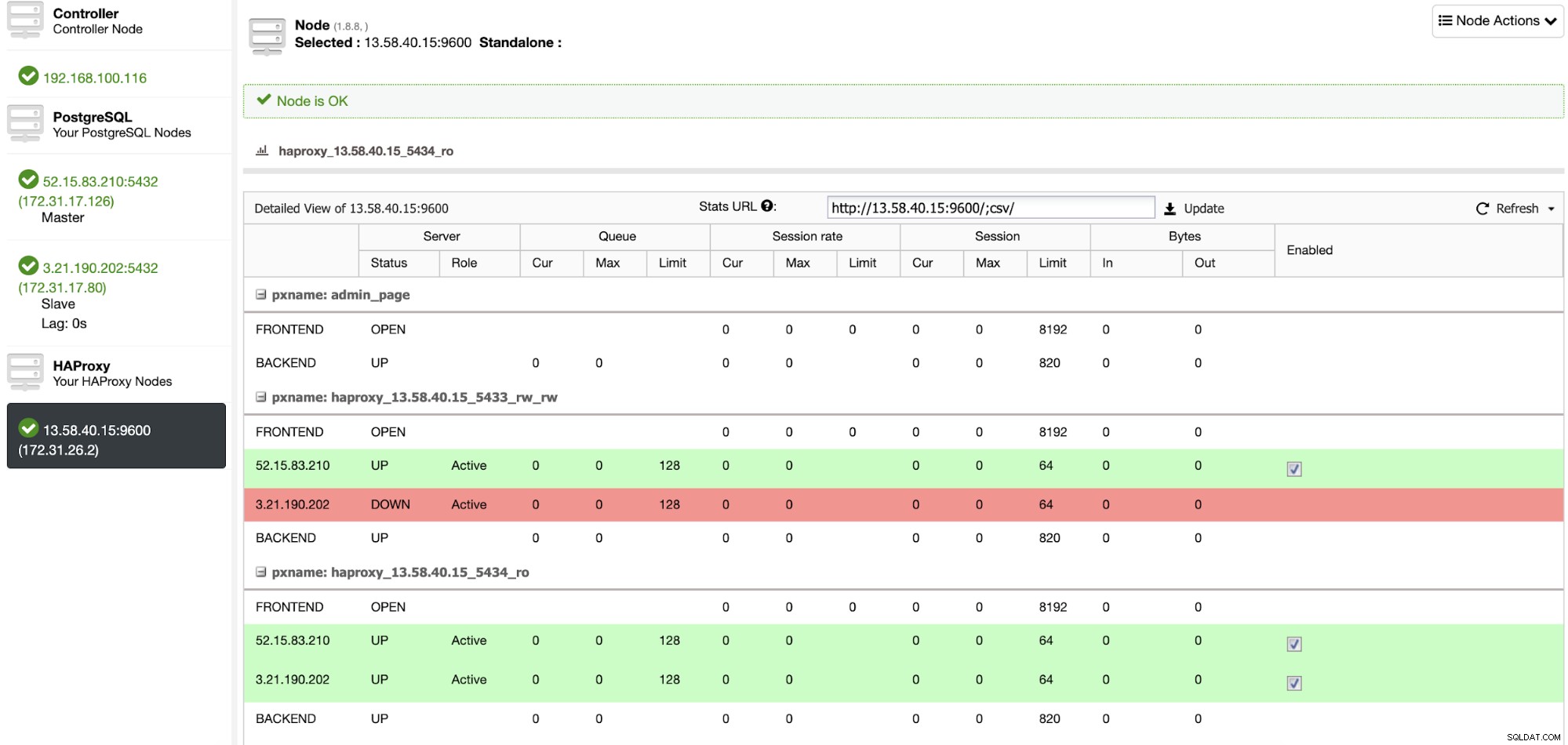
आप डैशबोर्ड सेक्शन को चेक करके क्लस्टरकंट्रोल से अपने HAProxy सर्वर की निगरानी भी कर सकते हैं।
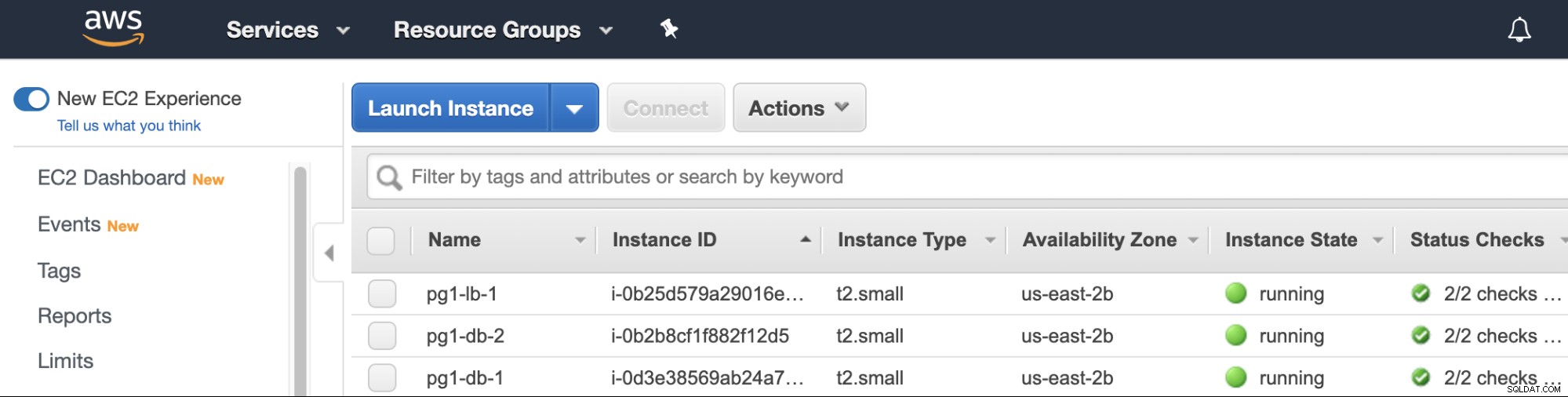
अब आपका काम हो गया, आप अपने क्लाउड प्रदाता प्रबंधन कंसोल की जांच कर सकते हैं, जहां आप अपने चुने हुए ClusterControl जॉब विकल्पों के अनुसार बनाई गई वर्चुअल मशीन पाएंगे।
निष्कर्ष
जैसा कि आप देख सकते हैं, क्लाउड में अपने PostgreSQL क्लस्टर के सामने एक लोड बैलेंसर रखना वास्तव में नई ClusterControl "डिप्लॉय इन द क्लाउड" सुविधा का उपयोग करना आसान है, जहां आप अपने डेटाबेस और लोड बैलेंसर नोड्स को एक ही काम में तैनात कर सकते हैं।