पिछले ब्लॉग पोस्ट में, मैंने संक्षेप में बताया था कि कैसे हमने pglogic घोषणा में प्रदर्शन संख्या प्रकाशित की। इस ब्लॉग पोस्ट में मैं सामान्य रूप से तार्किक प्रतिकृति समाधानों की प्रदर्शन सीमाओं पर चर्चा करना चाहता हूं, और यह भी कि वे pglogic पर कैसे लागू होते हैं।
भौतिक प्रतिकृति
सबसे पहले, आइए देखें कि भौतिक प्रतिकृति (संस्करण 9.0 के बाद से PostgreSQL में निर्मित) कैसे काम करती है। दो सिर्फ दो नोड्स के साथ कुछ हद तक सरलीकृत आंकड़ा इस तरह दिखता है:
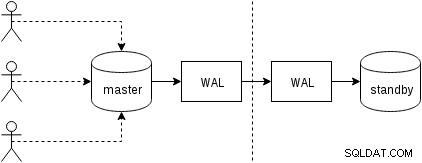
ग्राहक मास्टर नोड पर प्रश्नों को निष्पादित करते हैं, परिवर्तन लेनदेन लॉग (वाल) में लिखे जाते हैं और स्टैंडबाय नोड पर नेटवर्क पर वाल पर कॉपी किए जाते हैं। स्टैंडबाय पर स्टैंडबाय प्रक्रिया पर पुनर्प्राप्ति तब WAL से परिवर्तनों को पढ़ती है और उन्हें पुनर्प्राप्ति के दौरान डेटा फ़ाइलों पर लागू करती है। यदि स्टैंडबाय "हॉट_स्टैंडबाय" मोड में है, तो ऐसा होने पर क्लाइंट नोड पर केवल-पढ़ने के लिए क्वेरी जारी कर सकते हैं।
यह बहुत ही कुशल है क्योंकि बहुत कम अतिरिक्त प्रसंस्करण है - परिवर्तन स्थानांतरित किए जाते हैं और स्टैंडबाय को एक अपारदर्शी बाइनरी ब्लॉब के रूप में लिखा जाता है। बेशक, पुनर्प्राप्ति मुफ़्त नहीं है (CPU और I/O दोनों के संदर्भ में), लेकिन इससे अधिक कुशल होना मुश्किल है।
भौतिक प्रतिकृति के साथ स्पष्ट संभावित बाधाएं नेटवर्क बैंडविड्थ (वाल को मास्टर से स्टैंडबाय में स्थानांतरित करना) और स्टैंडबाय पर I/O भी हैं, जो पुनर्प्राप्ति प्रक्रिया से संतृप्त हो सकती हैं जो अक्सर बहुत सारे यादृच्छिक I/O अनुरोध जारी करती है ( कुछ मामलों में गुरु से अधिक, लेकिन आइए उस पर ध्यान न दें)।
तार्किक प्रतिकृति
तार्किक प्रतिकृति थोड़ी अधिक जटिल है, क्योंकि यह अपारदर्शी बाइनरी वाल स्ट्रीम से नहीं निपटती है, लेकिन "तार्किक" परिवर्तनों की एक धारा है (कल्पना करें INSERT, UPDATE या DELETE कथन, हालांकि यह पूरी तरह से सही नहीं है क्योंकि हम संरचित प्रतिनिधित्व के साथ काम कर रहे हैं आंकड़ा)। तार्किक परिवर्तन होने से संघर्ष समाधान जैसी दिलचस्प चीजें करने की अनुमति मिलती है, केवल चयनित तालिकाओं को एक अलग स्कीमा में या विभिन्न संस्करणों (या यहां तक कि विभिन्न डेटाबेस) के बीच दोहराना।
परिवर्तन प्राप्त करने के विभिन्न तरीके हैं - पारंपरिक दृष्टिकोण एक तालिका में परिवर्तनों को रिकॉर्ड करने वाले ट्रिगर्स का उपयोग करना है, और एक कस्टम प्रक्रिया को उन परिवर्तनों को लगातार पढ़ने दें और SQL क्वेरी चलाकर उन्हें स्टैंडबाय पर लागू करें। और यह सब एक बाहरी डेमॉन प्रक्रिया (या संभवतः दोनों नोड्स पर चलने वाली कई प्रक्रियाओं) द्वारा संचालित होता है, जैसा कि अगले आंकड़े में दिखाया गया है

यह वही है जो स्लोनी या लोंडिस्ट करते हैं, और जब यह काफी अच्छी तरह से काम करता है, तो इसका मतलब बहुत अधिक ओवरहेड होता है - उदाहरण के लिए इसे डेटा परिवर्तनों को कैप्चर करने और डेटा को कई बार लिखने की आवश्यकता होती है (मूल तालिका में और "लॉग" तालिका में, और उन दोनों तालिकाओं के लिए वाल को भी)। हम बाद में ओवरहेड के अन्य स्रोतों पर चर्चा करेंगे। जबकि pglogic को समान लक्ष्यों को प्राप्त करने की आवश्यकता होती है, यह उन्हें अलग तरह से प्राप्त करता है, हाल ही के PostgreSQL संस्करणों में जोड़े गए कई विशेषताओं के लिए धन्यवाद (इस प्रकार जब अन्य उपकरण लागू किए गए थे तब वापस उपलब्ध नहीं थे):

यही है, परिवर्तनों के एक अलग लॉग को बनाए रखने के बजाय, pglogic WAL पर निर्भर करता है - यह PostgreSQL 9.4 में उपलब्ध तार्किक डिकोडिंग के लिए संभव है, जो WAL लॉग से तार्किक परिवर्तन निकालने की अनुमति देता है। इसके लिए धन्यवाद pglogic को किसी महंगे ट्रिगर की आवश्यकता नहीं है और आमतौर पर मास्टर पर डेटा को दो बार लिखने से बच सकते हैं (बड़े लेनदेन को छोड़कर जो डिस्क पर फैल सकते हैं)।
प्रत्येक लेनदेन को डीकोड करने के बाद, इसे स्टैंडबाय में स्थानांतरित कर दिया जाता है और लागू प्रक्रिया स्टैंडबाय डेटाबेस में इसके परिवर्तनों को लागू करती है। pglogic नियमित SQL क्वेरी चलाकर परिवर्तनों को लागू नहीं करता है, लेकिन निचले स्तर पर, SQL क्वेरीज़ को पार्स करने और योजना बनाने से जुड़े ओवरहेड को दरकिनार कर देता है। यह pglogic को मौजूदा समाधानों पर एक महत्वपूर्ण लाभ देता है जो सभी SQL परत से गुजरते हैं (इस प्रकार पार्सिंग और योजना का भुगतान करते हैं)।
संभावित अड़चनें
स्पष्ट रूप से, तार्किक प्रतिकृति भौतिक प्रतिकृति के समान बाधाओं के लिए अतिसंवेदनशील है, अर्थात परिवर्तनों को स्थानांतरित करते समय नेटवर्क को संतृप्त करना संभव है, और I/O को स्टैंडबाय पर लागू करते समय स्टैंडबाय पर। भौतिक प्रतिकृति में अतिरिक्त चरण मौजूद नहीं होने के कारण उचित मात्रा में ओवरहेड भी होता है।
हमें किसी तरह तार्किक परिवर्तनों को एकत्र करने की आवश्यकता है, जबकि भौतिक प्रतिकृति केवल WAL को बाइट्स की धारा के रूप में आगे बढ़ाती है। जैसा कि पहले ही उल्लेख किया गया है, मौजूदा समाधान आमतौर पर "लॉग" तालिका में परिवर्तन लिखने वाले ट्रिगर पर निर्भर करते हैं। इसके बजाय pglogic एक ही चीज़ को प्राप्त करने के लिए राइट-फ़ॉरवर्ड लॉग (WAL) और लॉजिकल डिकोडिंग पर निर्भर करता है, जो ट्रिगर्स से सस्ता है और साथ ही अधिकांश मामलों में डेटा को दो बार लिखने की आवश्यकता नहीं है (अतिरिक्त बोनस के साथ कि हम स्वचालित रूप से परिवर्तन लागू करते हैं) प्रतिबद्ध क्रम में)।
इसका मतलब यह नहीं है कि अतिरिक्त सुधार के लिए कोई अवसर नहीं हैं - उदाहरण के लिए डिकोडिंग वर्तमान में केवल एक बार लेन-देन करने के बाद होती है, इसलिए बड़े लेनदेन के साथ यह प्रतिकृति अंतराल को बढ़ा सकता है। भौतिक प्रतिकृति केवल WAL परिवर्तनों को दूसरे नोड में प्रवाहित करती है और इस प्रकार यह सीमा नहीं होती है। बड़े लेन-देन डिस्क पर भी फैल सकते हैं, जिससे डुप्लिकेट लेखन हो सकता है, क्योंकि अपस्ट्रीम को उन्हें तब तक स्टोर करना होता है जब तक कि वे प्रतिबद्ध नहीं हो जाते और उन्हें डाउनस्ट्रीम में भेजा जा सकता है।
भविष्य के काम की योजना है ताकि pglogic बड़े लेनदेन की स्ट्रीमिंग शुरू कर सके, जबकि वे अभी भी अपस्ट्रीम पर प्रगति पर हैं, अपस्ट्रीम कमिट और डाउनस्ट्रीम कमिट के बीच विलंबता को कम करते हैं और अपस्ट्रीम राइट एम्पलीफिकेशन को कम करते हैं।
परिवर्तनों को स्टैंडबाय में स्थानांतरित करने के बाद, लागू प्रक्रिया को वास्तव में उन्हें किसी तरह लागू करने की आवश्यकता होती है। जैसा कि पिछले अनुभाग में बताया गया है, मौजूदा समाधानों ने SQL कमांड को बनाकर और निष्पादित करके ऐसा किया है, जबकि pglogic SQL लेयर और संबंधित ओवरहेड को पूरी तरह से बायपास करता है।
फिर भी, यह आवेदन को पूरी तरह से मुक्त नहीं बनाता है क्योंकि इसे अभी भी प्राथमिक कुंजी लुकअप, अपडेट इंडेक्स, ट्रिगर निष्पादित करने और कई अन्य जांच करने जैसी चीजों को करने की आवश्यकता है। लेकिन यह SQL- आधारित दृष्टिकोण से काफी सस्ता है। एक मायने में यह बहुत कुछ कॉपी की तरह काम करता है और विशेष रूप से बिना किसी ट्रिगर, विदेशी कुंजी आदि के सरल टेबल पर तेज़ होता है।
सभी तार्किक प्रतिकृति समाधानों में उनमें से प्रत्येक चरण (डिकोडिंग और लागू) एक ही प्रक्रिया में होता है, इसलिए CPU समय की काफी सीमित मात्रा होती है। यह शायद सभी मौजूदा समाधानों में सबसे अधिक दबाव वाली बाधा है, क्योंकि आपके पास दसियों या यहां तक कि सैकड़ों क्लाइंट समानांतर में क्वेरी चलाने वाली काफी मजबूत मशीन हो सकती है, लेकिन उन सभी को उन परिवर्तनों को डीकोड करने के लिए एक ही प्रक्रिया से गुजरना होगा (पर मास्टर) और उन परिवर्तनों को लागू करने वाली एक प्रक्रिया (स्टैंडबाय पर)।
अलग डेटाबेस का उपयोग करके "एकल प्रक्रिया" सीमा को कुछ हद तक कम किया जा सकता है, क्योंकि प्रत्येक डेटाबेस को एक अलग प्रक्रिया द्वारा नियंत्रित किया जाता है। जब एकल डेटाबेस की बात आती है, तो इस अड़चन को कम करने के लिए बैकग्राउंड वर्कर्स के एक पूल के माध्यम से आवेदन को समानांतर करने के लिए भविष्य के काम की योजना बनाई गई है।