यह पोस्ट पंक्ति लक्ष्यों के बारे में लेखों की एक श्रृंखला का हिस्सा है। आप यहां पहला भाग पा सकते हैं:
- भाग 1:पंक्ति लक्ष्य निर्धारित करना और उनकी पहचान करना
यह अपेक्षाकृत सर्वविदित है कि TOP . का उपयोग करना या एक FAST n क्वेरी संकेत एक निष्पादन योजना में एक पंक्ति लक्ष्य निर्धारित कर सकता है (यदि आपको पंक्ति लक्ष्यों और उनके कारणों पर एक पुनश्चर्या की आवश्यकता है तो निष्पादन योजनाओं में पंक्ति लक्ष्य निर्धारित करना और पहचानना देखें)। यह आमतौर पर कम सराहा जाता है कि सेमी जॉइन (और एंटी जॉइन) एक पंक्ति लक्ष्य भी पेश कर सकते हैं, हालांकि यह TOP के मामले की तुलना में कुछ कम है। , FAST , और SET ROWCOUNT ।
यह लेख आपको यह समझने में मदद करेगा कि कब और क्यों, एक सेमी जॉइन ऑप्टिमाइज़र के पंक्ति लक्ष्य तर्क को लागू करता है।
सेमी जॉइन
सेमी जॉइन एक जॉइन इनपुट (ए) से एक पंक्ति लौटाता है यदि कम से कम एक . है दूसरे जॉइन इनपुट (बी) पर मेल खाने वाली पंक्ति।
सेमी जॉइन और रेगुलर जॉइन के बीच आवश्यक अंतर हैं:
- सेमी जॉइन या तो इनपुट ए से प्रत्येक पंक्ति लौटाता है, या नहीं। कोई पंक्ति दोहराव नहीं हो सकता है।
- यदि जॉइन प्रेडिकेट में एक से अधिक मैच हैं तो नियमित रूप से डुप्लीकेट पंक्तियों में शामिल हों।
- सेमी जॉइन को केवल इनपुट ए से कॉलम वापस करने के लिए परिभाषित किया गया है।
- नियमित जॉइन या तो (या दोनों) जॉइन इनपुट से कॉलम लौटा सकता है।
T-SQL में वर्तमान में FROM A SEMI JOIN B ON A.x = B.y जैसे डायरेक्ट सिंटैक्स के लिए समर्थन का अभाव है। , इसलिए हमें अप्रत्यक्ष रूपों जैसे EXISTS . का उपयोग करने की आवश्यकता है , SOME/ANY (समकक्ष शॉर्टहैंड IN . सहित) समानता तुलना के लिए), और INTERSECT . सेट करें ।
ऊपर दिए गए सेमी जॉइन का विवरण स्वाभाविक रूप से एक पंक्ति लक्ष्य के अनुप्रयोग पर संकेत देता है, क्योंकि हम किसी भी मिलान पंक्ति को खोजने में रुचि रखते हैं। B में, ऐसी सभी पंक्तियां . नहीं . फिर भी, टी-एसक्यूएल में व्यक्त एक तार्किक अर्ध जुड़ाव कई कारणों से एक पंक्ति लक्ष्य का उपयोग करके निष्पादन योजना नहीं बना सकता है, जिसे हम आगे खोल देंगे।
रूपांतरण और सरलीकरण
क्वेरी संकलन और अनुकूलन के दौरान एक तार्किक अर्ध जुड़ाव को सरल बनाया जा सकता है या किसी अन्य चीज़ से बदला जा सकता है। नीचे दिया गया एडवेंचरवर्क्स उदाहरण एक विश्वसनीय विदेशी कुंजी संबंध के कारण अर्ध जुड़ाव को पूरी तरह से हटाता हुआ दिखाता है:
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
विदेशी कुंजी सुनिश्चित करती है कि Product प्रत्येक इतिहास पंक्ति के लिए पंक्तियाँ हमेशा मौजूद रहेंगी। परिणामस्वरूप, निष्पादन योजना केवल TransactionHistory . तक पहुंचती है टेबल:
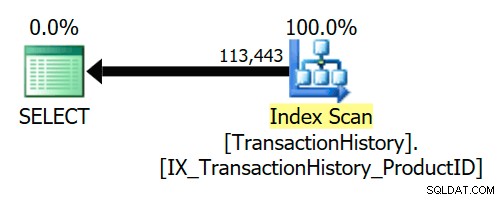
एक अधिक सामान्य उदाहरण तब देखा जाता है जब सेमी जॉइन को इनर जॉइन में बदला जा सकता है। उदाहरण के लिए:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
निष्पादन योजना से पता चलता है कि अनुकूलक ने एक समग्र (INV.ProductID . पर समूहीकरण) प्रस्तुत किया है ) यह सुनिश्चित करने के लिए कि आंतरिक जुड़ाव केवल Product लौटा सकता है पंक्तियाँ एक बार, या बिल्कुल नहीं (जैसा कि सेमी जॉइन सेमेन्टिक्स को संरक्षित करने के लिए आवश्यक है):
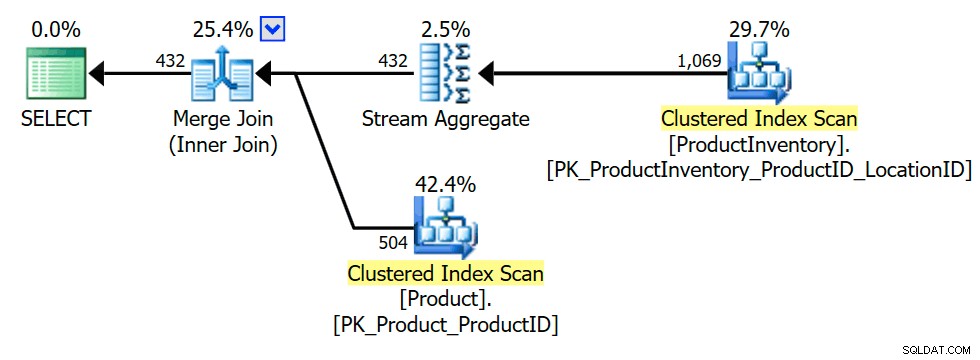
इनर जॉइन में परिवर्तन की जल्दी खोज की जाती है क्योंकि ऑप्टिमाइज़र सेमी जॉइन की तुलना में इनर इक्विजॉइन के लिए अधिक ट्रिक्स जानता है, संभावित रूप से अधिक ऑप्टिमाइज़ेशन अवसरों की ओर ले जाता है। स्वाभाविक रूप से, अंतिम योजना विकल्प अभी भी खोजे गए विकल्पों में से एक लागत-आधारित निर्णय है।
प्रारंभिक अनुकूलन
हालांकि टी-एसक्यूएल में प्रत्यक्ष SEMI JOIN का अभाव है सिंटैक्स, ऑप्टिमाइज़र मूल रूप से सेमी जॉइन के बारे में सब कुछ जानता है, और उन्हें सीधे हेरफेर कर सकता है। सामान्य वर्कअराउंड सेमी जॉइन सिंटैक्स को क्वेरी संकलन प्रक्रिया में "वास्तविक" आंतरिक सेमी जॉइन में बदल दिया जाता है (अच्छी तरह से एक तुच्छ योजना पर विचार करने से पहले)।
दो मुख्य वर्कअराउंड सिंटैक्स समूह हैं EXISTS/INTERSECT , और ANY/SOME/IN . EXISTS और INTERSECT मामले केवल इस मायने में भिन्न होते हैं कि बाद वाला एक अंतर्निहित DISTINCT . के साथ आता है (सभी अनुमानित स्तंभों पर समूहीकरण)। दोनों EXISTS और INTERSECT EXISTS . के रूप में पार्स किया जाता है सहसंबद्ध सबक्वेरी के साथ। ANY/SOME/IN अभ्यावेदन सभी को कुछ ऑपरेशन के रूप में व्याख्यायित किया जाता है। हम कुछ गैर-दस्तावेज ट्रेस फ़्लैग के साथ इस अनुकूलन गतिविधि को जल्दी खोज सकते हैं, जो SSMS संदेश टैब पर अनुकूलक गतिविधि के बारे में जानकारी भेजते हैं।
उदाहरण के लिए, अब तक हम जिस सेमी जॉइन का उपयोग कर रहे हैं, उसे IN . का उपयोग करके भी लिखा जा सकता है :
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); ऑप्टिमाइज़र इनपुट ट्री इस प्रकार है:

अदिश संचालिका ScaOp_SomeComp SOME है ऊपर उल्लिखित तुलना। 2 एक समानता परीक्षण के लिए कोड है, क्योंकि IN = SOME . के बराबर है . यदि आप रुचि रखते हैं, तो 1 से 6 तक के कोड हैं जो क्रमशः (<, =, <=,>, !=,>=) तुलना ऑपरेटरों का प्रतिनिधित्व करते हैं।
EXISTS पर वापस लौट रहे हैं सिंटैक्स जिसे मैं अप्रत्यक्ष रूप से अर्ध जुड़ने के लिए सबसे अधिक बार उपयोग करना पसंद करता हूं:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); अनुकूलक इनपुट ट्री है:

वह पेड़ क्वेरी टेक्स्ट का एक बहुत ही सीधा अनुवाद है; हालांकि ध्यान दें कि SELECT * पहले से ही निरंतर पूर्णांक मान 1 के प्रक्षेपण द्वारा प्रतिस्थापित किया गया है (पाठ की अंतिम पंक्ति देखें)।
अगली चीज़ जो ऑप्टिमाइज़र करता है वह है नियम RemoveSubqInSel का उपयोग करके संबंधपरक चयन (=फ़िल्टर) में सबक्वेरी को अननेस्ट करना . ऑप्टिमाइज़र हमेशा ऐसा करता है, क्योंकि यह सीधे सबक्वेरी पर काम नहीं कर सकता है। परिणाम एक लागू करें . है (a.k.a सहसंबद्ध या पार्श्व जोड़):

(समान सबक्वेरी-निष्कासन नियम SOME . के लिए समान आउटपुट उत्पन्न करता है इनपुट ट्री भी)।
अगला चरण ApplyHandler . का उपयोग करके नियमित जुड़ाव के रूप में आवेदन को फिर से लिखना है शासन परिवार। यह कुछ ऐसा है जो ऑप्टिमाइज़र हमेशा करने की कोशिश करता है, क्योंकि इसमें जुड़ने के लिए अधिक अन्वेषण नियम लागू होते हैं। प्रत्येक आवेदन को शामिल होने के रूप में फिर से नहीं लिखा जा सकता है, लेकिन वर्तमान उदाहरण सीधा है और सफल होता है:

ध्यान दें कि जुड़ने का प्रकार अर्ध छोड़ दिया गया है। वास्तव में, यह ठीक वही पेड़ है जो हमें तुरंत मिलेगा यदि टी-एसक्यूएल समर्थित सिंटैक्स जैसे:
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID; यह अच्छा होगा कि मैं इस तरह से और अधिक सीधे प्रश्नों को व्यक्त कर सकूं। वैसे भी, इच्छुक पाठक को इस सेमी जॉइन को टी-एसक्यूएल में लिखने के अन्य तार्किक-समतुल्य तरीकों के साथ उपरोक्त सरलीकरण गतिविधियों का पता लगाने के लिए प्रोत्साहित किया जाता है।
इस स्तर पर महत्वपूर्ण निष्कर्ष यह है कि अनुकूलक हमेशा उपश्रेणियों को हटा देता है , उन्हें एक आवेदन के साथ बदलना। यह फिर एक अच्छी योजना खोजने की संभावना को अधिकतम करने के लिए नियमित रूप से शामिल होने के रूप में आवेदन को फिर से लिखने का प्रयास करता है। याद रखें कि सभी पूर्ववर्ती एक छोटी सी योजना पर विचार करने से पहले होते हैं। लागत-आधारित अनुकूलन के दौरान, अनुकूलक एक लागू करने के लिए परिवर्तन में शामिल होने पर भी विचार कर सकता है।
हैश एंड मर्ज सेमी जॉइन
SQL सर्वर में लॉजिकल सेमी जॉइन के लिए तीन मुख्य भौतिक कार्यान्वयन विकल्प उपलब्ध हैं। जब तक एक इक्विजॉइन विधेय मौजूद है, हैश और मर्ज जॉइन उपलब्ध हैं; दोनों लेफ्ट और राइट-सेमी जॉइन मोड में काम कर सकते हैं। नेस्टेड लूप जॉइन केवल लेफ्ट (राइट नहीं) सेमी जॉइन को सपोर्ट करता है, लेकिन इसके लिए इक्विजॉइन विधेय की आवश्यकता नहीं होती है। आइए हैश को देखें और हमारी उदाहरण क्वेरी के लिए भौतिक विकल्पों को मर्ज करें (इस बार सेट प्रतिच्छेद के रूप में लिखा गया है):
SELECT P.ProductID FROM Production.Product AS P INTERSECT SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
ऑप्टिमाइज़र इस क्वेरी के लिए (बाएं/दाएं) और (हैश/मर्ज) सेमी जॉइन के सभी चार संयोजनों के लिए एक योजना ढूंढ सकता है:
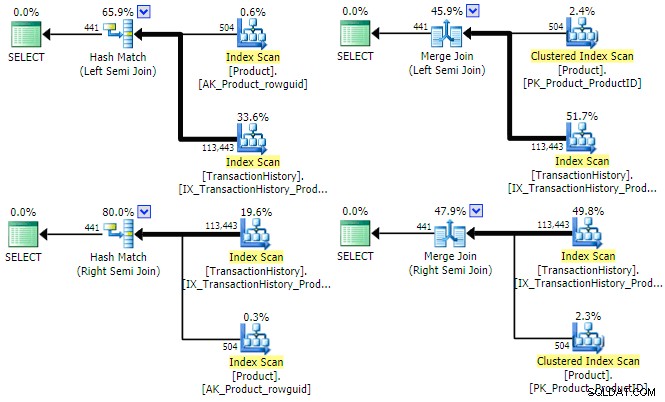
यह संक्षेप में ध्यान देने योग्य है कि क्यों ऑप्टिमाइज़र प्रत्येक प्रकार के जुड़ने के लिए बाएँ और दाएँ अर्ध-जुड़ने पर विचार कर सकता है। हैश सेमी जॉइन के लिए, एक प्रमुख लागत विचार हैश टेबल का अनुमानित आकार है, जो हमेशा शुरू में बाएं (ऊपरी) इनपुट होता है। मर्ज सेमी जॉइन के लिए, प्रत्येक इनपुट के गुण यह निर्धारित करते हैं कि वर्कटेबल के साथ एक से कई या कम कुशल कई से कई मर्ज का उपयोग किया जाएगा या नहीं।
उपरोक्त निष्पादन योजनाओं से यह स्पष्ट हो सकता है कि न तो हैश और न ही मर्ज सेमी जॉइन को एक पंक्ति लक्ष्य निर्धारित करने से लाभ होगा . दोनों जॉइन प्रकार हमेशा जॉइन प्रेडिकेट का परीक्षण करते हैं, और एक पूर्ण परिणाम सेट वापस करने के लिए दोनों इनपुट से सभी पंक्तियों का उपभोग करने का लक्ष्य रखते हैं। इसका मतलब यह नहीं है कि सामान्य रूप से हैश और मर्ज में शामिल होने के लिए प्रदर्शन अनुकूलन मौजूद नहीं हैं - उदाहरण के लिए, दोनों शामिल होने तक पंक्तियों की संख्या को कम करने के लिए बिटमैप का उपयोग कर सकते हैं। इसके बजाय, मुद्दा यह है कि किसी भी इनपुट पर एक पंक्ति लक्ष्य हैश या मर्ज सेमी जॉइन को अधिक कुशल नहीं बना देगा।
नेस्टेड लूप्स और सेमी जॉइन लागू करें
शेष भौतिक जुड़ाव प्रकार नेस्टेड लूप है, जो दो स्वादों में आता है:नियमित (असंबद्ध) नेस्टेड लूप और लागू करें नेस्टेड लूप (कभी-कभी इसे सहसंबद्ध . भी कहा जाता है) या पार्श्व शामिल हों)।
नियमित नेस्टेड लूप जॉइन हैश और मर्ज जॉइन के समान है जिसमें जॉइन विधेय का मूल्यांकन जॉइन पर किया जाता है। पहले की तरह, इसका मतलब है कि किसी भी इनपुट पर एक पंक्ति लक्ष्य निर्धारित करने का कोई मूल्य नहीं है। बाएं (ऊपरी) इनपुट हमेशा पूरी तरह से उपभोग किया जाएगा, और आंतरिक इनपुट के पास यह निर्धारित करने का कोई तरीका नहीं है कि कौन सी पंक्ति (पंक्तियों) को प्राथमिकता दी जानी चाहिए, क्योंकि हम यह नहीं जान सकते कि कोई पंक्ति शामिल होगी या नहीं जब तक कि शामिल होने पर विधेय का परीक्षण नहीं किया जाता है ।
इसके विपरीत, लागू नेस्टेड लूप जॉइन में एक या अधिक बाहरी संदर्भ . होते हैं (सहसंबद्ध पैरामीटर) जॉइन पर, जॉइन विधेय को नीचे धकेल दिया . के साथ जुड़ने का भीतरी (निचला) पक्ष। यह एक पंक्ति लक्ष्य के उपयोगी अनुप्रयोग के लिए एक अवसर बनाता है। याद रखें कि एक सेमी जॉइन के लिए हमें केवल जॉइन इनपुट बी पर एक पंक्ति के अस्तित्व की जांच करने की आवश्यकता होती है जो जॉइन इनपुट ए पर वर्तमान पंक्ति से मेल खाती है (सिर्फ नेस्टेड लूप्स जॉइन स्ट्रैटेजी के बारे में सोचते हुए)।
दूसरे शब्दों में, एक आवेदन के प्रत्येक पुनरावृत्ति पर, जैसे ही पहला मैच मिलता है, हम इनपुट बी को देखना बंद कर सकते हैं, पुश-डाउन जॉइन विधेय का उपयोग करके। यह ठीक उसी तरह की चीज है जिसके लिए एक पंक्ति लक्ष्य अच्छा है:पहली n मिलान पंक्तियों को जल्दी से वापस करने के लिए अनुकूलित योजना का हिस्सा बनाना (जहां n = 1 यहाँ)।
बेशक, परिस्थितियों के आधार पर एक पंक्ति लक्ष्य एक अच्छी बात हो सकती है या नहीं। उस संबंध में सेमी जॉइन रो गोल के बारे में कुछ खास नहीं है। ऐसी स्थिति पर विचार करें जहां सेमी जॉइन का आंतरिक भाग एक साधारण टेबल एक्सेस की तुलना में अधिक जटिल है, शायद एक मल्टी-टेबल जॉइन। पंक्ति लक्ष्य निर्धारित करने से ऑप्टिमाइज़र को केवल उस विशेष सबट्री के लिए एक कुशल नेविगेशनल रणनीति चुनने में मदद मिल सकती है , नेस्टेड लूप जॉइन और इंडेक्स की तलाश के माध्यम से सेमी जॉइन को संतुष्ट करने के लिए पहली मिलान पंक्ति खोजना। पंक्ति लक्ष्य के बिना, अनुकूलक स्वाभाविक रूप से हैश का चयन कर सकता है या सभी संभावित पंक्तियों को वापस करने की अपेक्षित लागत को कम करने के लिए प्रकार के साथ जुड़ सकता है। ध्यान दें कि यहां एक धारणा है, अर्थात् लोग आम तौर पर इस उम्मीद के साथ अर्ध जुड़ते हैं कि खोज की स्थिति से मेल खाने वाली एक पंक्ति वास्तव में मौजूद है। यह मेरे लिए काफी उचित धारणा है।
भले ही, इस स्तर पर महत्वपूर्ण बिंदु यह है:केवल लागू करें नेस्टेड लूप जॉइन का एक पंक्ति लक्ष्य होता है ऑप्टिमाइज़र द्वारा लागू किया जाता है (याद रखें, नेस्टेड लूप जॉइन लागू करने के लिए एक पंक्ति लक्ष्य केवल तभी जोड़ा जाता है जब पंक्ति लक्ष्य इसके बिना अनुमान से कम हो)। उम्मीद है कि यह सब आगे स्पष्ट करने के लिए हम कुछ काम किए गए उदाहरणों को देखेंगे।
नेस्टेड लूप्स सेमी जॉइन उदाहरण
निम्न स्क्रिप्ट दो ढेर अस्थायी तालिकाएँ बनाती है। पहले में 1 से 20 तक की संख्याएँ शामिल हैं; दूसरे के पास पहली तालिका में प्रत्येक संख्या की 10 प्रतियां हैं:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200; कोई अनुक्रमणिका और पंक्तियों की अपेक्षाकृत कम संख्या के साथ, ऑप्टिमाइज़र निम्नलिखित सेमी जॉइन क्वेरी के लिए नेस्टेड लूप (हैश या मर्ज के बजाय) कार्यान्वयन चुनता है। गैर-दस्तावेजी ट्रेस फ़्लैग हमें ऑप्टिमाइज़र आउटपुट ट्री और पंक्ति लक्ष्य जानकारी देखने की अनुमति देते हैं:
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
अनुमानित निष्पादन योजना में एक सेमी जॉइन नेस्टेड लूप जॉइन की सुविधा है, जिसमें प्रति पूर्ण स्कैन 200 पंक्तियाँ हैं #E2 . लूप के 20 पुनरावृत्तियों से कुल 4,000 पंक्तियों का अनुमान मिलता है:
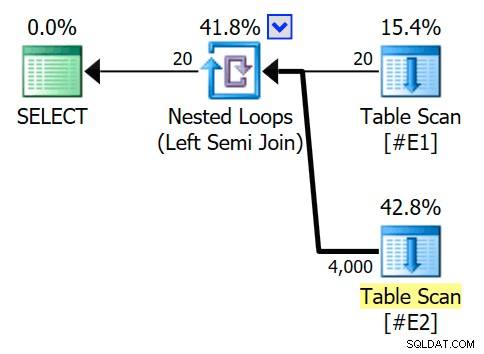
नेस्टेड लूप ऑपरेटर के गुण बताते हैं कि विधेय को शामिल होने पर लागू किया जाता है मतलब यह एक असंबद्ध नेस्टेड लूप जॉइन है :
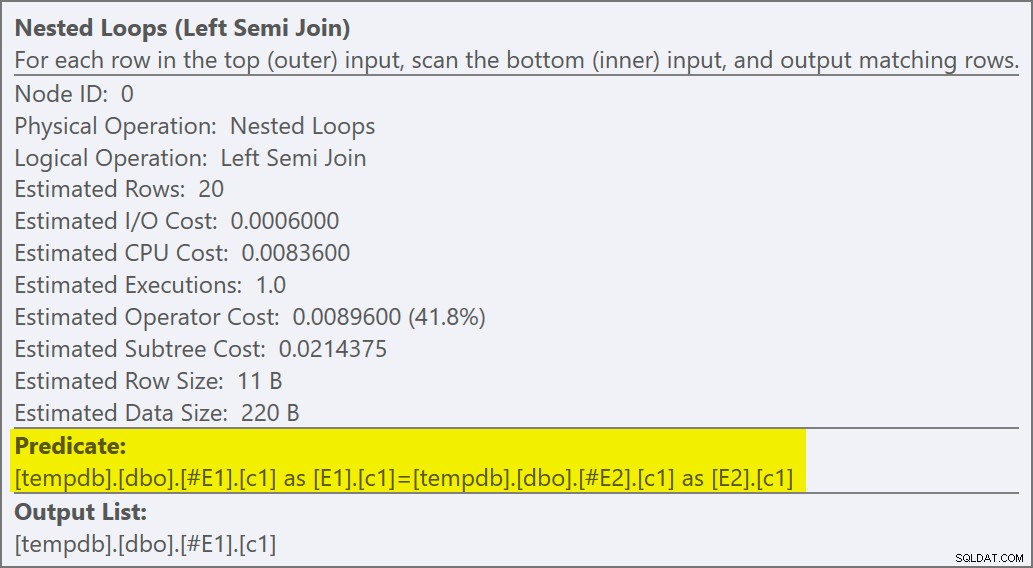
ट्रेस फ़्लैग आउटपुट (SSMS संदेश टैब पर) एक नेस्टेड लूप्स सेमी जॉइन और नो रो गोल (RowGoal 0) दिखाता है:

ध्यान दें कि इस टॉय क्वेरी के लिए निष्पादन के बाद की योजना तालिका #E2 से पढ़ी गई 4,000 पंक्तियों को कुल मिलाकर नहीं दिखाएगी। नेस्टेड लूप सेमी जॉइन (सहसंबद्ध या नहीं) जैसे ही वर्तमान बाहरी पंक्ति के लिए पहला मैच सामने आता है, आंतरिक पक्ष (प्रति पुनरावृत्ति) पर अधिक पंक्तियों की तलाश करना बंद कर देगा। अब, प्रत्येक पुनरावृत्ति पर #E2 के हीप स्कैन से प्राप्त पंक्तियों का क्रम गैर-नियतात्मक है (और प्रत्येक पुनरावृत्ति पर भिन्न हो सकता है), इसलिए सिद्धांत रूप में प्रत्येक पुनरावृत्ति पर लगभग सभी पंक्तियों का परीक्षण किया जा सकता है, इस घटना में कि मिलान पंक्ति जितनी देर हो सके (या वास्तव में, कोई मिलान पंक्ति नहीं होने की स्थिति में)।
उदाहरण के लिए, यदि हम एक रनटाइम कार्यान्वयन मानते हैं जहां पंक्तियों को उसी क्रम में स्कैन किया जाता है (उदाहरण के लिए "सम्मिलन आदेश"), तो इस खिलौना उदाहरण में स्कैन की गई पंक्तियों की कुल संख्या पहले पुनरावृत्ति पर 20 पंक्तियां होगी, 1 पंक्ति दूसरे पुनरावृत्ति पर, तीसरे पुनरावृत्ति पर 2 पंक्तियाँ, और इसी तरह कुल 20 + 1 + 2 + (...) + 19 =210 पंक्तियों के लिए। वास्तव में आप इस कुल का निरीक्षण करने की काफी संभावना रखते हैं, जो कि सरल प्रदर्शन कोड की सीमाओं के बारे में और कुछ भी बताता है। एक अनियंत्रित पहुंच विधि से लौटाए गए पंक्तियों के क्रम पर कोई भरोसा नहीं कर सकता है, कोई भी शीर्ष-स्तर ORDER BY के बिना किसी क्वेरी से स्पष्ट रूप से ऑर्डर किए गए आउटपुट पर भरोसा कर सकता है। खंड।
सेमी जॉइन अप्लाई करें
अब हम बड़े टेबल पर एक गैर-क्लस्टर इंडेक्स बनाते हैं (ऑप्टिमाइज़र को एक सेमी जॉइन लागू करने के लिए प्रोत्साहित करने के लिए) और फिर से क्वेरी चलाते हैं:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); निष्पादन योजना में अब एक लागू सेमी जॉइन की सुविधा है, जिसमें 1 पंक्ति प्रति इंडेक्स सीक (और पहले की तरह 20 पुनरावृत्तियां) हैं:
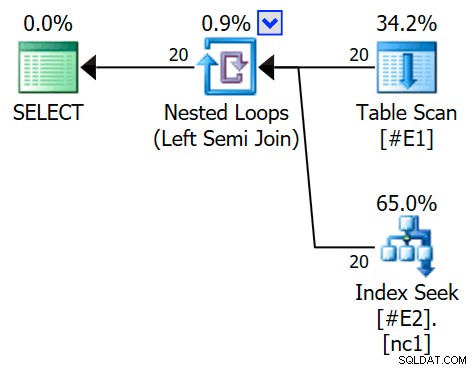
हम बता सकते हैं कि यह एक अर्ध जुड़ाव लागू करें . है क्योंकि जुड़ने के गुण बाहरी संदर्भ . दिखाते हैं विधेय में शामिल होने के बजाय:
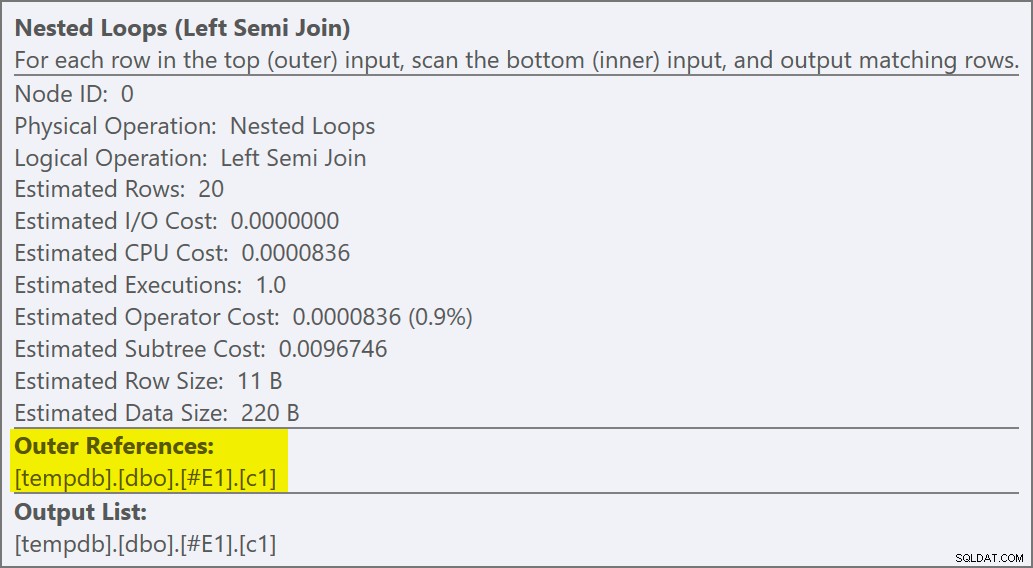
शामिल होने का अनुमान नीचे धकेल दिया गया है आवेदन का आंतरिक भाग, और नई अनुक्रमणिका से मेल खाता है:
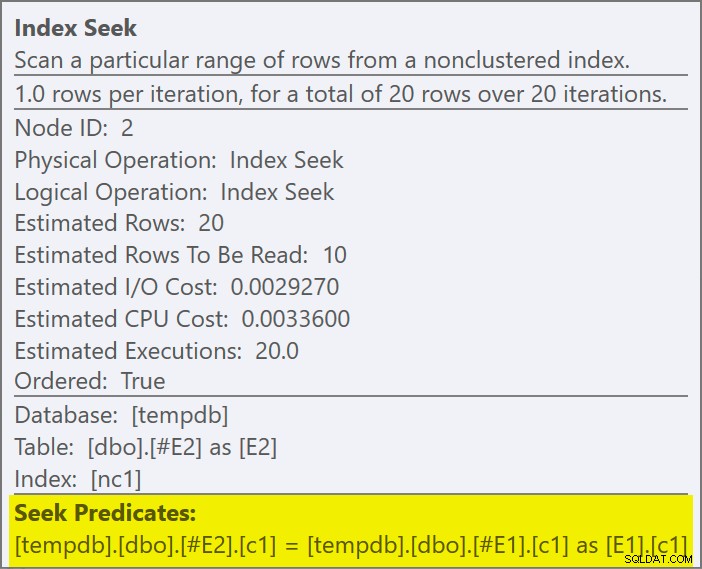
प्रत्येक खोज से 1 पंक्ति वापस आने की उम्मीद है, इस तथ्य के बावजूद कि प्रत्येक मान उस तालिका में 10 बार दोहराया गया है; यह पंक्ति लक्ष्य . का प्रभाव है . EstimateRowsWithoutRowGoal को एक्सपोज़ करने वाले SQL सर्वर बिल्ड पर पंक्ति लक्ष्य को पहचानना आसान होगा योजना विशेषता (लेखन के समय SQL सर्वर 2017 CU3)। प्लान एक्सप्लोरर के आगामी संस्करण में, यह प्रासंगिक ऑपरेटरों के लिए टूलटिप्स पर भी प्रदर्शित किया जाएगा:

ट्रेस फ्लैग आउटपुट है:
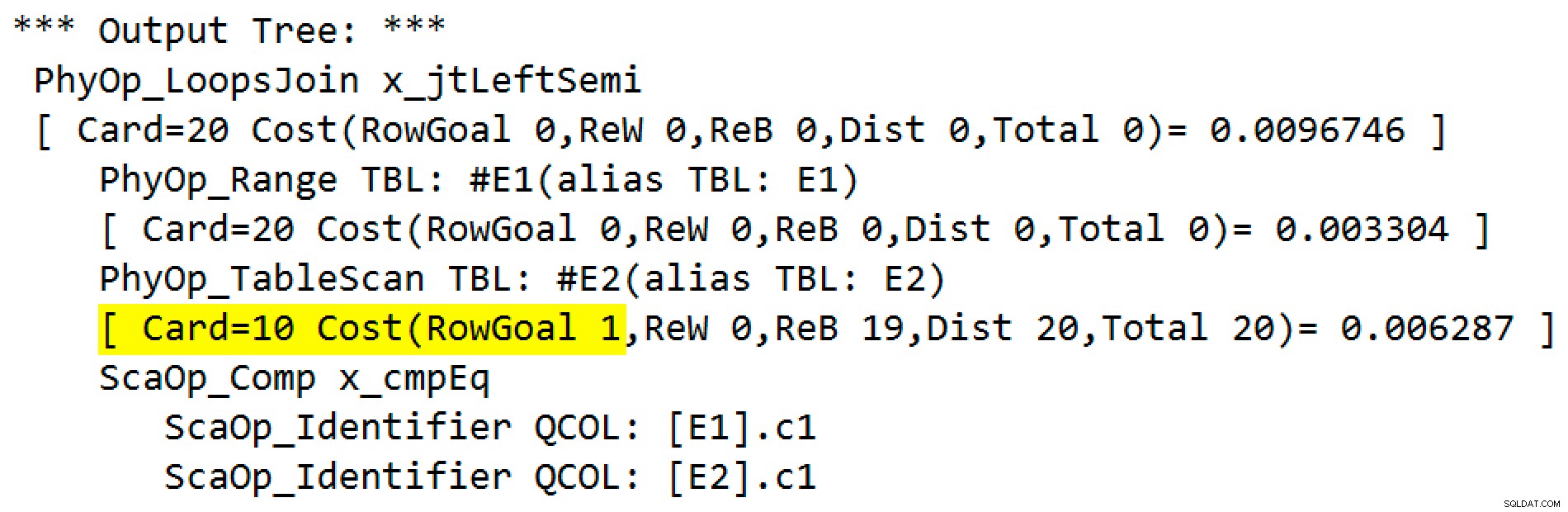
फिजिकल ऑपरेटर को लूप जॉइन से लेफ्ट सेमी जॉइन मोड में चल रहे एप्लिकेशन में बदल दिया गया है। टेबल तक पहुंच #E2 1 का एक पंक्ति लक्ष्य प्राप्त कर लिया है (पंक्ति लक्ष्य के बिना कार्डिनैलिटी को 10 के रूप में दिखाया गया है)। इस मामले में पंक्ति लक्ष्य कोई बड़ी बात नहीं है क्योंकि अनुमानित दस पंक्तियों को प्रति खोज प्राप्त करने की लागत एक पंक्ति से बहुत अधिक नहीं है। इस क्वेरी के लिए पंक्ति लक्ष्य अक्षम करना (ट्रेस फ़्लैग 4138 या DISABLE_OPTIMIZER_ROWGOAL का उपयोग करके) क्वेरी संकेत) योजना के आकार को नहीं बदलेगा।
फिर भी, अधिक यथार्थवादी प्रश्नों में, आंतरिक-पक्ष पंक्ति लक्ष्य के कारण लागत में कमी प्रतिस्पर्धी कार्यान्वयन विकल्पों के बीच अंतर कर सकती है। उदाहरण के लिए, पंक्ति लक्ष्य को अक्षम करने से ऑप्टिमाइज़र इसके बजाय हैश या मर्ज सेमी जॉइन चुन सकता है, या क्वेरी के लिए विचार किए गए कई अन्य विकल्पों में से कोई एक हो सकता है। यदि और कुछ नहीं, तो यहां पंक्ति लक्ष्य सटीक रूप से इस तथ्य को दर्शाता है कि एक लागू सेमी जॉइन पहला मैच मिलते ही आंतरिक पक्ष को खोजना बंद कर देगा, और अगली बाहरी साइड पंक्ति पर आगे बढ़ जाएगा।
ध्यान दें कि डुप्लिकेट तालिका में बनाए गए थे #E2 ताकि लागू सेमी जॉइन रो लक्ष्य (1) सामान्य अनुमान (सांख्यिकी घनत्व जानकारी से 10) से कम हो। यदि कोई डुप्लीकेट नहीं थे, तो प्रत्येक के लिए पंक्ति अनुमान #E2 . में खोजते हैं 1 पंक्ति भी होगी, इसलिए 1 का एक पंक्ति लक्ष्य लागू नहीं किया जाएगा (इस बारे में सामान्य नियम याद रखें!)
पंक्ति लक्ष्य बनाम शीर्ष
यह देखते हुए कि निष्पादन योजनाएँ SQL सर्वर 2017 CU3 से पहले एक पंक्ति लक्ष्य की उपस्थिति का संकेत नहीं देती हैं, कोई सोच सकता है कि एक पंक्ति लक्ष्य जैसी छिपी संपत्ति के बजाय एक स्पष्ट शीर्ष ऑपरेटर का उपयोग करके इस अनुकूलन को लागू करना अधिक स्पष्ट होगा। विचार यह होगा कि जॉइन पर ही एक पंक्ति लक्ष्य निर्धारित करने के बजाय एक लागू सेमी/एंटी जॉइन के अंदरूनी हिस्से पर एक शीर्ष (1) ऑपरेटर को रखा जाए।
इस तरह से एक शीर्ष ऑपरेटर का उपयोग करना पूरी तरह से मिसाल के बिना नहीं होता। उदाहरण के लिए, पहले से ही शीर्ष का एक विशेष संस्करण है जिसे पंक्ति गणना शीर्ष के रूप में जाना जाता है जिसे डेटा संशोधन निष्पादन योजनाओं में देखा जाता है जब एक गैर-शून्य SET ROWCOUNT प्रभाव में है (ध्यान दें कि इस विशिष्ट उपयोग को 2005 से हटा दिया गया है, हालांकि SQL सर्वर 2017 में अभी भी इसकी अनुमति है)। रो काउंट टॉप इम्प्लीमेंटेशन इस मायने में थोड़ा क्लिंकी है कि शीर्ष ऑपरेटर को हमेशा निष्पादन योजना में टॉप (0) के रूप में दिखाया जाता है, भले ही वास्तविक रो काउंट लिमिट प्रभावी हो।
ऐसा कोई ठोस कारण नहीं है कि लागू सेमी जॉइन रो लक्ष्य को स्पष्ट शीर्ष (1) ऑपरेटर से क्यों नहीं बदला जा सकता था। उस ने कहा, पसंद करने . के कुछ कारण हैं ऐसा न करें:
- एक स्पष्ट शीर्ष (1) जोड़ने के लिए एक पंक्ति लक्ष्य जोड़ने की तुलना में अधिक अनुकूलक कोडिंग प्रयास और परीक्षण की आवश्यकता होती है (जो पहले से ही अन्य चीजों के लिए उपयोग किया जाता है)।
- टॉप एक रिलेशनल ऑपरेटर नहीं है; इसके बारे में तर्क करने के लिए अनुकूलक के पास बहुत कम समर्थन है। यह एक क्वेरी योजना के कुछ हिस्सों को बदलने के लिए अनुकूलक की क्षमता को सीमित करके योजना की गुणवत्ता को नकारात्मक रूप से प्रभावित कर सकता है। समुच्चय, संघों, फ़िल्टरों और जॉइन को इधर-उधर घुमाकर।
- यह सेमी जॉइन और शीर्ष के लागू कार्यान्वयन के बीच एक तंग युग्मन का परिचय देगा। विशेष मामले और तंग युग्मन बग पेश करने और भविष्य के परिवर्तनों को और अधिक कठिन और त्रुटि-प्रवण बनाने के शानदार तरीके हैं।
- शीर्ष (1) तार्किक रूप से बेमानी होगा, और केवल इसके पंक्ति लक्ष्य दुष्प्रभाव के लिए उपस्थित होगा।
वह अंतिम बिंदु एक उदाहरण के साथ विस्तार करने लायक है:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
TOP (1) ऑप्टिमाइज़र द्वारा मौजूद सबक्वेरी को सरल बनाया जाता है, जिससे एक साधारण सेमी जॉइन एक्ज़ीक्यूशन प्लान मिलता है:
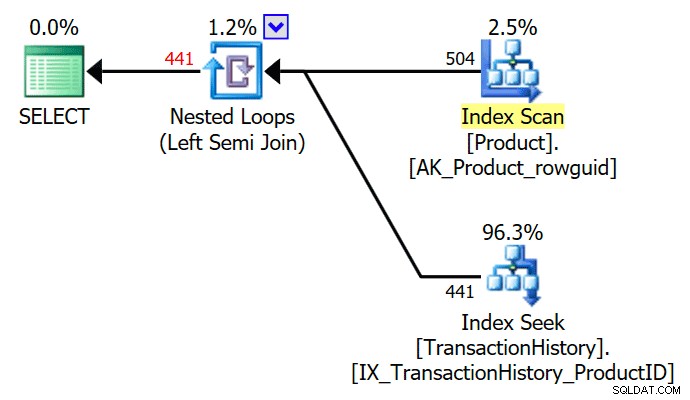
अनुकूलक अनावश्यक DISTINCT . को भी हटा सकता है या GROUP BY सबक्वेरी में। निम्नलिखित सभी उपरोक्त के समान योजना तैयार करते हैं:
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); सारांश और अंतिम विचार
केवल लागू करें नेस्टेड लूप सेमी जॉइन में ऑप्टिमाइज़र द्वारा निर्धारित एक पंक्ति लक्ष्य हो सकता है। यह एकमात्र जॉइन प्रकार है जो जॉइन प्रेडिकेट को जॉइन से नीचे धकेलता है, जिससे मैच के अस्तित्व के लिए परीक्षण जल्दी किया जा सकता है। . असंबद्ध नेस्टेड लूप अर्ध जुड़ते हैं लगभग कभी नहीं* एक पंक्ति लक्ष्य निर्धारित करता है, और न ही हैश या अर्ध में शामिल होता है। नेस्टेड लूप लागू करें बाहरी संदर्भों की उपस्थिति से जुड़े हुए असंबद्ध नेस्टेड लूप से अलग किया जा सकता है (एक विधेय के बजाय) नेस्टेड लूप पर एक आवेदन के लिए ऑपरेटर से जुड़ें।
अंतिम निष्पादन योजना में लागू अर्ध-जुड़ाव देखने की संभावना कुछ हद तक प्रारंभिक अनुकूलन गतिविधि पर निर्भर करती है। प्रत्यक्ष टी-एसक्यूएल सिंटैक्स की कमी के कारण, हमें अप्रत्यक्ष शब्दों में अर्ध-जुड़ावों को व्यक्त करना पड़ता है। इन्हें एक तार्किक ट्री में पार्स किया जाता है जिसमें एक सबक्वेरी होती है, जो प्रारंभिक अनुकूलक गतिविधि को एक लागू में बदल देती है, और फिर जहां संभव हो वहां एक असंबद्ध सेमी जॉइन में बदल जाती है।
यह सरलीकरण गतिविधि निर्धारित करती है कि लागत-आधारित अनुकूलक को एक लागू या नियमित अर्ध जुड़ाव के रूप में एक तार्किक अर्ध जुड़ाव प्रस्तुत किया जाता है या नहीं। तार्किक के रूप में प्रस्तुत किए जाने पर लागू करें सेमी जॉइन, सीबीओ एक अंतिम निष्पादन योजना तैयार करने के लिए लगभग निश्चित है जिसमें भौतिक लागू नेस्टेड लूप (और इसलिए एक पंक्ति लक्ष्य निर्धारित करना) शामिल है। जब एक असंबद्ध सेमी जॉइन के साथ प्रस्तुत किया जाता है, तो सीबीओ मई एक लागू करने के लिए परिवर्तन पर विचार करें (या यह नहीं हो सकता है)। योजना का अंतिम विकल्प हमेशा की तरह लागत-आधारित निर्णयों की एक श्रृंखला है।
सभी पंक्ति लक्ष्यों की तरह, सेमी जॉइन रो लक्ष्य प्रदर्शन के लिए अच्छी या बुरी बात हो सकती है। यह जानते हुए कि एक लागू सेमी जॉइन एक पंक्ति लक्ष्य निर्धारित करता है, कम से कम लोगों को समस्या होने पर कारण को पहचानने और उसका समाधान करने में मदद करेगा। समाधान हमेशा (या आमतौर पर भी) क्वेरी के लिए पंक्ति लक्ष्यों को अक्षम नहीं करेगा। पहली मिलान पंक्ति का पता लगाने के लिए एक प्रभावी तरीका प्रदान करने के लिए अक्सर अनुक्रमण (और/या क्वेरी) में सुधार किया जा सकता है।
पंक्ति लक्ष्यों की श्रृंखला को जारी रखते हुए, मैं एक अलग लेख में अर्ध-विरोधी जोड़ों को कवर करूंगा।
* अपवाद एक असंबद्ध नेस्टेड लूप है जो बिना किसी जॉइन विधेय (एक असामान्य दृश्य) के साथ सेमी जॉइन करता है। यह एक पंक्ति लक्ष्य निर्धारित करता है।



