यह ब्लॉग पोस्ट MySQL में अनुक्रमणिका के बारे में ब्लॉग की श्रृंखला का तीसरा भाग है . MySQL इंडेक्स के बारे में ब्लॉग पोस्ट श्रृंखला के दूसरे भाग में, हमने इंडेक्स और स्टोरेज इंजन को कवर किया और कुछ प्राथमिक कुंजी विचारों को छुआ। चर्चा में कॉलम उपसर्ग का मिलान कैसे करें, कुछ FULLTEXT अनुक्रमणिका विचार, और आपको वाइल्डकार्ड के साथ B-Tree अनुक्रमणिका का उपयोग कैसे करना चाहिए और अपने प्रश्नों के प्रदर्शन की निगरानी के लिए ClusterControl का उपयोग कैसे करें, बाद में, अनुक्रमणिका शामिल हैं।
इस ब्लॉग पोस्ट में, हम MySQL में इंडेक्स के बारे में कुछ और विवरण में जाएंगे। :हम हैश इंडेक्स, इंडेक्स कार्डिनैलिटी, इंडेक्स सेलेक्टिविटी को कवर करेंगे, हम आपको इंडेक्स को कवर करने के बारे में दिलचस्प विवरण बताएंगे, और हम कुछ इंडेक्सिंग रणनीतियों से भी गुजरेंगे। और, निश्चित रूप से, हम ClusterControl को स्पर्श करेंगे। चलिए शुरू करते हैं, क्या हम?
MySQL में हैश इंडेक्स
MySQL DBA और MySQL के साथ काम करने वाले डेवलपर्स के पास भी अपनी आस्तीन में एक और चाल है जहां तक MySQL का संबंध है - हैश इंडेक्स भी एक विकल्प है। MySQL के मेमोरी इंजन में हैश इंडेक्स का अक्सर उपयोग किया जाता है - जैसा कि MySQL में बहुत अधिक सब कुछ के साथ, उन प्रकार के इंडेक्स के अपने अपसाइड और डाउनसाइड होते हैं। इस प्रकार के इंडेक्स का मुख्य पहलू यह है कि उनका उपयोग केवल समानता की तुलना के लिए किया जाता है जो =या <=> ऑपरेटरों का उपयोग करते हैं, जिसका अर्थ है कि वे वास्तव में उपयोगी नहीं हैं यदि आप मूल्यों की एक श्रृंखला की खोज करना चाहते हैं, लेकिन मुख्य उल्टा है कि लुकअप बहुत तेज हैं। कुछ और डाउनसाइड्स में यह तथ्य शामिल है कि डेवलपर्स पंक्तियों को खोजने के लिए कुंजी के किसी भी सबसे बाएं उपसर्ग का उपयोग नहीं कर सकते हैं (यदि आप ऐसा करना चाहते हैं, तो इसके बजाय बी-ट्री इंडेक्स का उपयोग करें), तथ्य यह है कि MySQL लगभग यह निर्धारित नहीं कर सकता है कि कितनी पंक्तियाँ हैं। दो मानों के बीच - यदि हैश इंडेक्स उपयोग में हैं, तो ऑप्टिमाइज़र ORDER BY संचालन को गति देने के लिए हैश इंडेक्स का उपयोग नहीं कर सकता है। ध्यान रखें कि हैश इंडेक्स केवल एक ही चीज नहीं है जो मेमोरी इंजन का समर्थन करता है - मेमोरी इंजन में बी-ट्री इंडेक्स भी हो सकते हैं।
MySQL में इंडेक्स कार्डिनैलिटी
जहां तक MySQL अनुक्रमणिका का संबंध है, आपने एक और शब्द भी सुना होगा - इस शब्द को अनुक्रमणिका कार्डिनैलिटी कहा जाता है। बहुत ही सरल शब्दों में, इंडेक्स कार्डिनैलिटी एक कॉलम में संग्रहीत मूल्यों की विशिष्टता को संदर्भित करता है जो एक इंडेक्स का उपयोग करता है। किसी विशिष्ट इंडेक्स की इंडेक्स कार्डिनैलिटी देखने के लिए, आप बस phpMyAdmin के स्ट्रक्चर टैब पर जा सकते हैं और वहां की जानकारी देख सकते हैं या आप SHOW INDEXES क्वेरी भी निष्पादित कर सकते हैं:
mysql> SHOW INDEXES FROM demo_table;
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| demo_table | 1 | demo | 1 | demo | A | 494573 | NULL | NULL | | BTREE | | |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)दिखाएँ इंडेक्स क्वेरी आउटपुट जो ऊपर देखा जा सकता है जैसा कि आप देख सकते हैं, इसमें बहुत सारे फ़ील्ड हैं, जिनमें से एक इंडेक्स कार्डिनैलिटी को दर्शाता है:यह फ़ील्ड इंडेक्स में अद्वितीय मानों की अनुमानित संख्या देता है - कार्डिनैलिटी जितनी अधिक होगी, क्वेरी ऑप्टिमाइज़र के लुकअप के लिए इंडेक्स का उपयोग करने की संभावना उतनी ही अधिक होगी। कहा जा रहा है कि, इंडेक्स कार्डिनैलिटी का एक भाई भी है - उसका नाम इंडेक्स सेलेक्टिविटी है।
MySQL में अनुक्रमणिका चयनात्मकता
सूचकांक चयनात्मकता तालिका में अभिलेखों की संख्या के संबंध में विशिष्ट मानों की संख्या है। सरल शब्दों में, इंडेक्स चयनात्मकता परिभाषित करती है कि डेटाबेस इंडेक्स कितनी मजबूती से MySQL को मूल्यों की खोज को कम करने में मदद करता है। एक आदर्श सूचकांक चयनात्मकता 1 का मान है। एक सूचकांक चयनात्मकता की गणना तालिका में अलग-अलग मानों को रिकॉर्ड की कुल संख्या से विभाजित करके की जाती है, उदाहरण के लिए, यदि आपकी तालिका में 1,000,000 रिकॉर्ड हैं, लेकिन उनमें से केवल 100,000 अलग मान हैं , आपकी अनुक्रमणिका चयनात्मकता 0.1 होगी। यदि आपकी तालिका में 10,000 रिकॉर्ड हैं और उनमें से 8,500 अलग-अलग मान हैं, तो आपकी अनुक्रमणिका चयनात्मकता 0.85 होगी। यह ज़्यादा बेहतर है। तुम समझ गए। आपकी अनुक्रमणिका चयनात्मकता जितनी अधिक होगी, उतना ही बेहतर होगा।
MySQL में अनुक्रमणिका को कवर करना
एक कवरिंग इंडेक्स InnoDB में एक विशेष प्रकार का इंडेक्स है। जब एक कवरिंग इंडेक्स उपयोग में होता है, तो एक क्वेरी के लिए सभी आवश्यक फ़ील्ड शामिल होते हैं, या इंडेक्स द्वारा "कवर" किया जाता है, जिसका अर्थ है कि आप डेटा के बजाय केवल इंडेक्स को पढ़ने के लाभों को प्राप्त कर सकते हैं। अगर कुछ और मदद नहीं करता है, तो बेहतर प्रदर्शन के लिए एक कवरिंग इंडेक्स आपका टिकट हो सकता है। कवरिंग इंडेक्स का उपयोग करने के कुछ लाभों में शामिल हैं:
-
मुख्य परिदृश्यों में से एक जहां कवरिंग इंडेक्स का उपयोग किया जा सकता है, इसमें अतिरिक्त I/O रीड्स के बिना प्रश्नों को प्रस्तुत करना शामिल है बड़ी मेजों पर।
-
MySQL भी कम डेटा तक पहुंच सकता है क्योंकि इंडेक्स प्रविष्टियां पंक्तियों के आकार से छोटी होती हैं।
-
अधिकांश स्टोरेज इंजन डेटा से बेहतर इंडेक्स को कैश करते हैं।
टेबल पर कवरिंग इंडेक्स बनाना बहुत आसान है - बस SELECT, WHERE और GROUP BY क्लॉज द्वारा एक्सेस किए गए फ़ील्ड को कवर करें:
ALTER TABLE demo_table ADD INDEX index_name(column_1, column_2, column_3);ध्यान रखें कि कवरिंग इंडेक्स के साथ काम करते समय, इंडेक्स में कॉलम का सही क्रम चुनना बहुत महत्वपूर्ण है। अपने कवरिंग इंडेक्स को प्रभावी बनाने के लिए, उन कॉलमों को रखें जिनका उपयोग आप पहले WHERE क्लॉज के साथ करते हैं, ORDER BY और GROUP BY अगले और SELECT क्लॉज के साथ उपयोग किए गए कॉलम अंतिम।
MySQL में अनुक्रमण रणनीतियां
MySQL में अनुक्रमणिका के बारे में ब्लॉग पोस्ट के इन तीन भागों में दी गई सलाह के बाद आपको वास्तव में एक अच्छी नींव मिल सकती है, लेकिन कुछ अनुक्रमण रणनीतियाँ भी हैं जिनका आप उपयोग करना चाहते हैं यदि आप चाहते हैं वास्तव में अपने MySQL आर्किटेक्चर में इंडेक्स की शक्ति में टैप करें। MySQL की सर्वोत्तम प्रथाओं का पालन करने के लिए आपकी अनुक्रमणिका के लिए, इस पर विचार करें:
-
उस कॉलम को अलग करना जिस पर आप इंडेक्स का उपयोग करते हैं - सामान्य तौर पर, MySQL इंडेक्स का उपयोग नहीं करता है यदि कॉलम वे पर उपयोग किया जाता है पृथक नहीं हैं। उदाहरण के लिए, ऐसी क्वेरी इंडेक्स का उपयोग नहीं करेगी क्योंकि यह अलग-थलग नहीं है:
SELECT demo_column FROM demo_table WHERE demo_id + 1 = 10;
हालांकि, इस तरह की एक क्वेरी होगी:
SELECT demo_column FROM demo_table WHERE demo_id = 10; -
आपके द्वारा इंडेक्स किए जाने वाले कॉलम पर इंडेक्स का उपयोग न करें। उदाहरण के लिए, इस तरह की क्वेरी का उपयोग करना बहुत अच्छा नहीं होगा, इसलिए बेहतर होगा कि आप ऐसे प्रश्नों से बचें, यदि आप:
SELECT demo_column FROM demo_table WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(column_date) <= 10; -
यदि आप अनुक्रमित स्तंभों के साथ LIKE क्वेरी का उपयोग करते हैं, तो खोज क्वेरी की शुरुआत में वाइल्डकार्ड डालने से बचें क्योंकि इस तरह MySQL किसी इंडेक्स का उपयोग नहीं करेगा। यानी इस तरह के प्रश्न लिखने के बजाय:
SELECT * FROM demo_table WHERE demo_column LIKE ‘%search query%’;
उन्हें इस तरह लिखने पर विचार करें:SELECT * FROM demo_table WHERE demo_column LIKE ‘search_query%’;
दूसरी क्वेरी बेहतर है क्योंकि MySQL जानता है कि कॉलम किससे शुरू होता है और इंडेक्स का अधिक प्रभावी ढंग से उपयोग कर सकता है। हालांकि हर चीज की तरह, यदि आप यह सुनिश्चित करना चाहते हैं कि आपकी अनुक्रमणिका वास्तव में MySQL द्वारा उपयोग की जाती है, तो EXPLAIN कथन बहुत मददगार हो सकता है।
अपनी क्वेरी को बेहतर बनाए रखने के लिए ClusterControl का उपयोग करना
यदि आप अपने MySQL प्रदर्शन में सुधार करना चाहते हैं, तो ऊपर दी गई सलाह आपको सही रास्ते पर ले जाएगी। अगर आपको लगता है कि आपको कुछ और चाहिए, तो MySQL के लिए ClusterControl पर विचार करें। प्रदर्शन प्रबंधन को शामिल करने में ClusterControl आपकी मदद कर सकता है - जैसा कि पिछले ब्लॉग पोस्ट में पहले ही उल्लेख किया गया है, ClusterControl आपके प्रश्नों को उनकी क्षमता के अनुसार हर समय सर्वश्रेष्ठ प्रदर्शन करने में आपकी मदद कर सकता है - ऐसा इसलिए है क्योंकि ClusterControl में एक क्वेरी भी शामिल है मॉनिटर की मदद से आप अपने प्रश्नों के प्रदर्शन की निगरानी कर सकते हैं, धीमी, लंबे समय तक चलने वाली क्वेरी देख सकते हैं और क्वेरी आउटलेयर भी देख सकते हैं जो आपके डेटाबेस के प्रदर्शन में संभावित बाधाओं के बारे में आपको सचेत कर सकते हैं, इससे पहले कि आप उन्हें स्वयं नोटिस कर सकें:
यदि कोई इंडेक्स एक व्यक्तिगत क्वेरी द्वारा उपयोग किया गया था या नहीं:
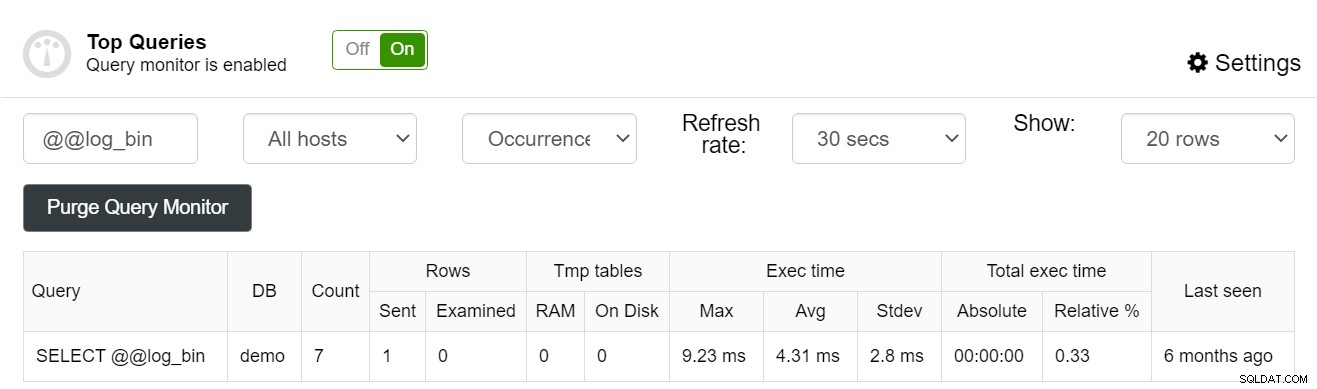
ClusterControl आपके डेटाबेस के प्रदर्शन को बेहतर बनाने के लिए एक बेहतरीन टूल हो सकता है और साथ ही रखरखाव की परेशानी को अपने हाथों से हटा सकता है। अपने MySQL इंस्टेंस के प्रदर्शन को बेहतर बनाने के लिए ClusterControl क्या कर सकता है, इस बारे में अधिक जानने के लिए, MySQL पृष्ठ के लिए ClusterControl पर एक नज़र डालने पर विचार करें।
सारांश
जैसा कि आप शायद अब तक बता सकते हैं, MySQL में इंडेक्स एक बहुत ही जटिल जानवर हैं। अपने MySQL इंस्टेंस के लिए सर्वश्रेष्ठ इंडेक्स चुनने के लिए, जानें कि इंडेक्स क्या हैं और वे क्या करते हैं, MySQL इंडेक्स के प्रकारों को जानें, उनके लाभ और कमियां जानें, खुद को शिक्षित करें कि MySQL इंडेक्स स्टोरेज इंजन के साथ कैसे इंटरैक्ट करते हैं, इसके लिए ClusterControl पर भी एक नज़र डालें। MySQL अगर आपको लगता है कि MySQL में इंडेक्स से संबंधित कुछ कार्यों को स्वचालित करने से आपका दिन आसान हो सकता है।