Sysadmins और Developers के रूप में, हम अपना बहुत समय एक टर्मिनल में बिताते हैं। इसलिए हम s9s नामक अपने कमांड लाइन इंटरफ़ेस टूल के साथ ClusterControl को टर्मिनल पर लाए। s9s ClusterControl RPC v2 API को एक आसान इंटरफ़ेस प्रदान करता है। बड़े पैमाने पर तैनाती के साथ काम करते समय आपको यह बहुत उपयोगी लगेगा, क्योंकि सीएलआई आपको अधिक जटिल सुविधाओं और वर्कफ़्लोज़ को डिज़ाइन करने की अनुमति देगा।
यह ब्लॉग पोस्ट दिखाता है कि MySQL या MariaDB के लिए गैलेरा क्लस्टर के प्रबंधन को स्वचालित करने के लिए s9s का उपयोग कैसे करें, साथ ही साथ एक साधारण मास्टर-स्लेव प्रतिकृति सेटअप।
सेटअप
आप प्रलेखन में अपने विशेष ओएस के लिए स्थापना निर्देश पा सकते हैं। यह नोट करना महत्वपूर्ण है कि यदि आप GitHub के नवीनतम s9s-tools का उपयोग करते हैं, तो आपके द्वारा उपयोगकर्ता बनाने के तरीके में थोड़ा बदलाव होता है। निम्न आदेश ठीक काम करेगा:
s9s user --create --generate-key --controller="https://localhost:9501" dbaसामान्य तौर पर, यदि आप CLI को स्थानीय रूप से ClusterControl होस्ट पर कॉन्फ़िगर करना चाहते हैं, तो दो चरणों की आवश्यकता होती है। सबसे पहले, आपको एक उपयोगकर्ता बनाने और फिर कॉन्फ़िगरेशन फ़ाइल में कुछ बदलाव करने की आवश्यकता है - सभी चरणों को दस्तावेज़ीकरण में शामिल किया गया है।
तैनाती
एक बार जब सीएलआई सही ढंग से कॉन्फ़िगर किया गया है और आपके लक्षित डेटाबेस होस्ट तक एसएसएच पहुंच है, तो आप परिनियोजन प्रक्रिया शुरू कर सकते हैं। लेखन के समय, आप MySQL, MariaDB और PostgreSQL क्लस्टर्स को परिनियोजित करने के लिए CLI का उपयोग कर सकते हैं। आइए एक उदाहरण के साथ शुरू करें कि Percona XtraDB क्लस्टर 5.7 को कैसे परिनियोजित किया जाए। ऐसा करने के लिए एक ही कमांड की आवश्यकता होती है।
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitअंतिम विकल्प "--प्रतीक्षा" का अर्थ है कि आदेश कार्य पूरा होने तक प्रतीक्षा करेगा, अपनी प्रगति दिखा रहा है। यदि आप चाहें तो इसे छोड़ सकते हैं - उस स्थिति में, s9s कमांड cmon में एक नई नौकरी दर्ज करने के तुरंत बाद शेल में वापस आ जाएगी। यह पूरी तरह से ठीक है क्योंकि सीमोन वह प्रक्रिया है जो कार्य को स्वयं संभालती है। आप किसी भी कार्य की प्रगति की अलग से जांच कर सकते हैं:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1आइए एक और उदाहरण देखें। इस बार हम एक नया क्लस्टर बनाएंगे, MySQL प्रतिकृति:सिंपल मास्टर-स्लेव पेयर। फिर से, एक ही कमांड काफी है:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdअब हम सत्यापित कर सकते हैं कि दोनों क्लस्टर सक्रिय हैं और चल रहे हैं:
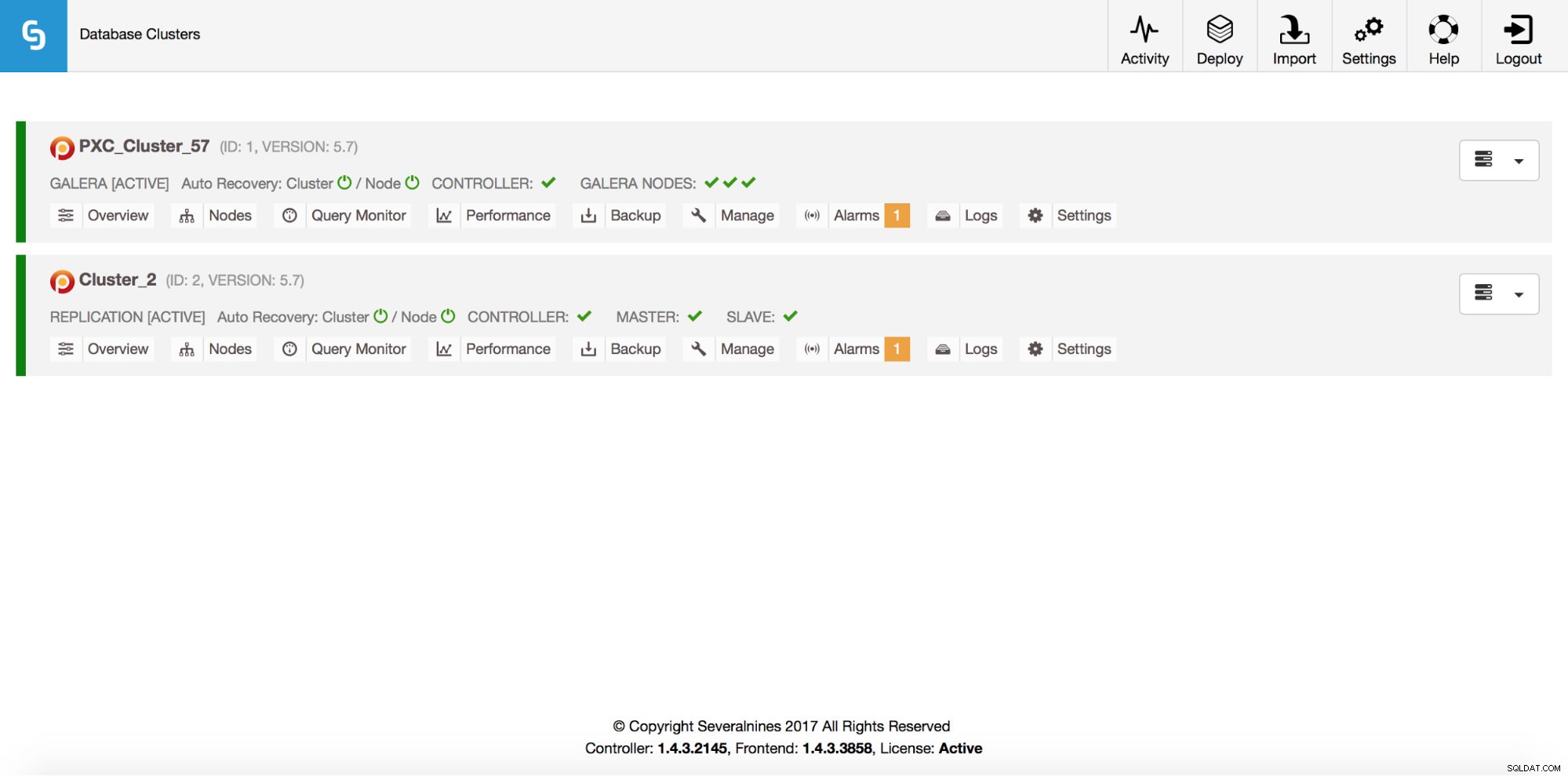
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2बेशक, यह सब GUI के माध्यम से भी दिखाई देता है:
अब, एक ProxySQL लोडबैलेंसर जोड़ें:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.इस बार हमने '--wait' विकल्प का उपयोग नहीं किया है, इसलिए यदि हम प्रगति की जांच करना चाहते हैं, तो हमें इसे स्वयं करना होगा। कृपया ध्यान दें कि हम एक जॉब आईडी का उपयोग कर रहे हैं जो पिछले कमांड द्वारा लौटाया गया था, इसलिए हम केवल इस विशेष कार्य के बारे में जानकारी प्राप्त करेंगे:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7स्केलिंग आउट
हमारे गैलेरा क्लस्टर में नोड्स को एक कमांड के माध्यम से जोड़ा जा सकता है:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8कुछ गलत हो गया। हम जांच सकते हैं कि वास्तव में क्या हुआ:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.ठीक है, वह आईपी पहले से ही हमारे प्रतिकृति सर्वर के लिए उपयोग किया जाता है। हमें एक और मुफ्त आईपी इस्तेमाल करना चाहिए था। आइए इसे आजमाएं:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9प्रबंधन
मान लीजिए कि हम अपने प्रतिकृति मास्टर का बैकअप लेना चाहते हैं। हम जीयूआई से ऐसा कर सकते हैं लेकिन कभी-कभी हमें इसे बाहरी स्क्रिप्ट के साथ एकीकृत करने की आवश्यकता हो सकती है। ClusterControl CLI ऐसे मामले के लिए एकदम उपयुक्त होगा। आइए देखें कि हमारे पास कौन से क्लस्टर हैं:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2फिर, हमारे प्रतिकृति क्लस्टर में मेजबानों की जाँच करें, क्लस्टर आईडी 2 के साथ:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningजैसा कि हम देख सकते हैं, तीन होस्ट हैं जिनके बारे में ClusterControl जानता है - उनमें से दो MySQL होस्ट (10.0.0.229 और 10.0.0.230) हैं, तीसरा क्लस्टरकंट्रोल इंस्टेंस ही है। आइए केवल प्रासंगिक MySQL होस्ट को प्रिंट करें:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3"STAT" कॉलम में आप वहां कुछ वर्ण देख सकते हैं। अधिक जानकारी के लिए, हम s9s-नोड्स (मैन s9s-नोड्स) के लिए मैनुअल पेज देखने का सुझाव देंगे। यहां हम सबसे महत्वपूर्ण बिट्स को संक्षेप में प्रस्तुत करेंगे। पहला अक्षर हमें नोड के प्रकार के बारे में बताता है:"s" का अर्थ है कि यह नियमित MySQL नोड है, "c" - ClusterControl कंट्रोलर। दूसरा वर्ण नोड की स्थिति का वर्णन करता है:"ओ" हमें बताता है कि यह ऑनलाइन है। तीसरा चरित्र - नोड की भूमिका। यहाँ "M" एक मास्टर और "S" - एक गुलाम का वर्णन करता है जबकि "C" नियंत्रक के लिए है। अंतिम, चौथा वर्ण हमें बताता है कि नोड रखरखाव मोड में है या नहीं। "-" का अर्थ है कि कोई रखरखाव निर्धारित नहीं है। अन्यथा हम यहाँ "M" देखेंगे। तो, इस डेटा से हम देख सकते हैं कि हमारा मास्टर IP:10.0.0.229 के साथ एक होस्ट है। आइए इसका बैकअप लें और इसे कंट्रोलर पर स्टोर करें।
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okहम तब सत्यापित कर सकते हैं कि क्या यह वास्तव में ठीक है। कृपया "--बैकअप-प्रारूप" विकल्प पर ध्यान दें जो आपको यह परिभाषित करने की अनुमति देता है कि कौन सी जानकारी मुद्रित की जानी चाहिए:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1निगरानी
सभी डेटाबेस की निगरानी की जानी है। ClusterControl MySQL और ऑपरेटिंग सिस्टम दोनों पर कुछ मेट्रिक्स देखने के लिए सलाहकारों का उपयोग करता है। जब कोई शर्त पूरी होती है, तो एक सूचना भेजी जाती है। ClusterControl पोस्ट-मॉर्टम या क्षमता नियोजन के लिए वास्तविक समय के साथ-साथ ऐतिहासिक ग्राफ का एक व्यापक सेट भी प्रदान करता है। कभी-कभी जीयूआई के माध्यम से जाने के बिना उनमें से कुछ मीट्रिक तक पहुंच प्राप्त करना बहुत अच्छा होगा। ClusterControl CLI इसे s9s-node कमांड के माध्यम से संभव बनाता है। यह कैसे करना है इसकी जानकारी s9s-node के मैनुअल पेज में मिल सकती है। हम कुछ उदाहरण दिखाएंगे कि आप सीएलआई के साथ क्या कर सकते हैं।
सबसे पहले, "--नोड-प्रारूप" विकल्प पर "s9s नोड" कमांड पर एक नज़र डालते हैं। जैसा कि आप देख सकते हैं, दिलचस्प सामग्री को प्रिंट करने के लिए बहुत सारे विकल्प हैं।
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningहमने यहां जो दिखाया है, उससे आप शायद ऑटोमेशन के कुछ मामलों की कल्पना कर सकते हैं। उदाहरण के लिए, आप नोड्स के CPU उपयोग को देख सकते हैं और यदि यह कुछ सीमा तक पहुंच जाता है, तो आप गैलेरा क्लस्टर में एक नया नोड स्पिन करने के लिए एक और s9s जॉब निष्पादित कर सकते हैं। उदाहरण के लिए, आप स्मृति उपयोग की निगरानी भी कर सकते हैं और अगर यह कुछ सीमा पार कर जाता है तो अलर्ट भेज सकते हैं।
सीएलआई इससे कहीं अधिक कर सकता है। सबसे पहले, कमांड लाइन के भीतर से रेखांकन की जांच करना संभव है। बेशक, वे जीयूआई में ग्राफ़ के रूप में फीचर-समृद्ध नहीं हैं, लेकिन कभी-कभी एक अप्रत्याशित पैटर्न खोजने और यह तय करने के लिए कि क्या यह आगे की जांच के लायक है, ग्राफ़ को देखने के लिए पर्याप्त है।
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231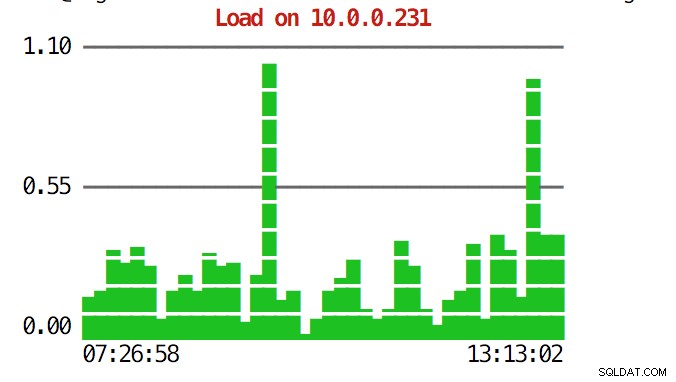
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231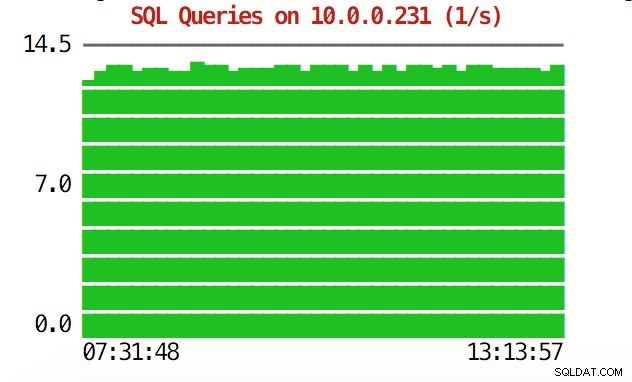
आपातकालीन स्थितियों के दौरान, आप क्लस्टर में संसाधन उपयोग की जांच करना चाह सकते हैं। आप एक शीर्ष जैसा आउटपुट बना सकते हैं जो सभी क्लस्टर नोड्स के डेटा को जोड़ता है:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1Hजब आप शीर्ष पर एक नज़र डालते हैं, तो आप पूरे क्लस्टर में एकत्रित CPU और मेमोरी आंकड़े देखेंगे।
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,नीचे आप क्लस्टर में सभी नोड्स से प्रक्रियाओं की सूची पा सकते हैं।
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldयह बेहद उपयोगी हो सकता है यदि आपको यह पता लगाने की आवश्यकता है कि लोड का कारण क्या है और कौन सा नोड सबसे अधिक प्रभावित है।
उम्मीद है, CLI टूल आपके लिए ClusterControl को बाहरी स्क्रिप्ट और इंफ्रास्ट्रक्चर ऑर्केस्ट्रेशन टूल के साथ एकीकृत करना आसान बनाता है। हम आशा करते हैं कि आपको इस टूल का उपयोग करने में मज़ा आएगा और यदि आपके पास इसे सुधारने के बारे में कोई प्रतिक्रिया है, तो बेझिझक हमें बताएं।