किसी भी डेटाबेस को कुशलतापूर्वक संचालित करने के लिए, आपको डेटाबेस के प्रदर्शन में अंतर्दृष्टि की आवश्यकता होती है। यह स्पष्ट नहीं हो सकता है जब सब कुछ ठीक चल रहा हो, लेकिन जैसे ही कुछ गलत हो जाता है, सूचना तक पहुंच समस्या का शीघ्र और सही निदान करने में सहायक हो सकती है।
सभी डेटाबेस अपने कुछ आंतरिक स्थिति डेटा उपयोगकर्ताओं को उपलब्ध कराते हैं। MySQL में, आप इस डेटा को ज्यादातर 'शो स्टेटस' और 'शो ग्लोबल स्टेटस' चलाकर, 'शो इंजन INNODB STATUS' निष्पादित करके, info_schema टेबल्स की जाँच करके और नए संस्करणों में, performance_schema टेबल्स को क्वेरी करके प्राप्त कर सकते हैं।

ये विधियां दिन-प्रतिदिन के संचालन में सुविधाजनक नहीं हैं, इसलिए विभिन्न निगरानी और ट्रेंडिंग समाधानों की लोकप्रियता। Nagios/Icinga जैसे उपकरण मेजबानों/सेवाओं को देखने के लिए डिज़ाइन किए गए हैं, और जब कोई सेवा स्वीकार्य सीमा से बाहर हो जाती है तो सतर्क हो जाती है। कैक्टि और मुनिन जैसे अन्य उपकरण मेजबान/सेवा की जानकारी पर एक ग्राफिकल रूप प्रदान करते हैं, और प्रदर्शन और उपयोग के लिए ऐतिहासिक संदर्भ देते हैं। ClusterControl इन दो प्रकार की निगरानी को जोड़ती है, इसलिए हम उस जानकारी पर एक नज़र डालेंगे जो यह प्रस्तुत करती है, और हमें इसकी व्याख्या कैसे करनी चाहिए।
यदि आप गैलेरा क्लस्टर (MySQL Galera Cluster by Codership या MariaDB क्लस्टर या Percona XtraDB Cluster) का उपयोग कर रहे हैं, तो आपने ClusterControl के "अवलोकन" टैब में निम्न अनुभाग पर ध्यान दिया होगा:
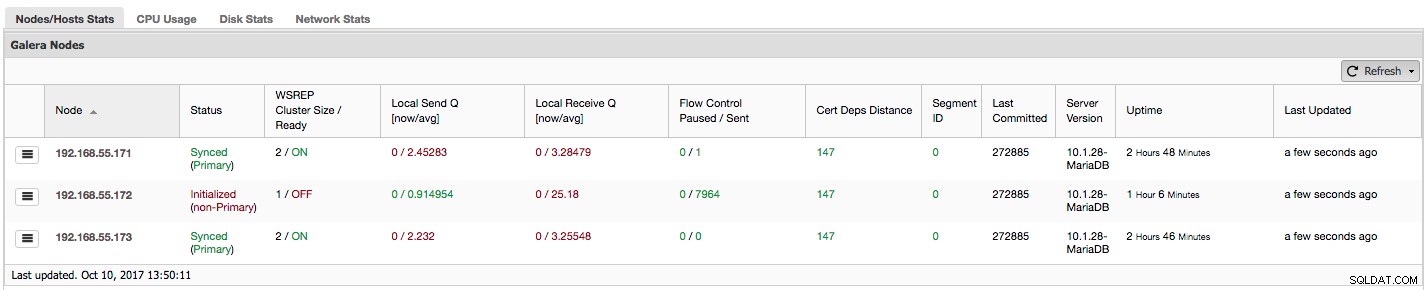
आइए देखें, चरण दर चरण, हमारे पास यहां किस प्रकार का डेटा है।
पहले कॉलम में उनके आईपी पते के साथ नोड्स की सूची है - इसके बारे में कहने के लिए और कुछ नहीं है।
दूसरा कॉलम अधिक दिलचस्प है - यह नोड स्थिति का वर्णन करता है (wsrep_local_state_comment स्थिति)। एक नोड विभिन्न अवस्थाओं में हो सकता है:
- आरंभिक - नोड ऊपर और चल रहा है, लेकिन यह क्लस्टर का हिस्सा नहीं है। यह, उदाहरण के लिए, नेटवर्क समस्याओं के कारण हो सकता है;
- शामिल होना - नोड क्लस्टर में शामिल होने की प्रक्रिया में है और यह या तो प्राप्त कर रहा है या किसी अन्य नोड से राज्य हस्तांतरण का अनुरोध कर रहा है;
- दाता/डिसिंक्ड - नोड किसी अन्य नोड के लिए दाता के रूप में कार्य करता है जो क्लस्टर में शामिल हो रहा है;
- शामिल हो गया - नोड क्लस्टर में शामिल हो गया है लेकिन यह प्रतिबद्ध लेखन सेटों को पकड़ने में व्यस्त है;
- समन्वयित - नोड सामान्य रूप से काम कर रहा है।
ब्रैकेट के भीतर एक ही कॉलम में क्लस्टर स्थिति है (wsrep_cluster_status स्थिति)। इसके तीन अलग-अलग राज्य हो सकते हैं:
- प्राथमिक - नोड्स के बीच संचार काम कर रहा है और कोरम मौजूद है (अधिकांश नोड्स उपलब्ध हैं)
- गैर-प्राथमिक - नोड क्लस्टर का एक हिस्सा था, लेकिन किसी कारण से, बाकी क्लस्टर के साथ संपर्क टूट गया। परिणामस्वरूप, इस नोड को निष्क्रिय माना जाता है और यह प्रश्नों को स्वीकार नहीं करेगा
- डिस्कनेक्टेड - नोड समूह संचार स्थापित नहीं कर सका।
"WSREP क्लस्टर आकार / तैयार" हमें क्लस्टर आकार के बारे में बताता है क्योंकि नोड इसे देखता है, और क्या नोड प्रश्नों को स्वीकार करने के लिए तैयार है। गैर-प्राथमिक घटक 1 के आकार के साथ एक क्लस्टर बनाते हैं और wsrep तैयारी बंद है।
आइए ऊपर दिए गए स्क्रीनशॉट पर एक नज़र डालें, और देखें कि यह हमें गैलेरा के बारे में क्या बता रहा है। हम तीन नोड्स देख सकते हैं। उनमें से दो (192.168.55.171 और 192.168.55.173) पूरी तरह से ठीक हैं, वे दोनों "सिंक" हैं और क्लस्टर "प्राथमिक" स्थिति में है। क्लस्टर में वर्तमान में दो नोड होते हैं। नोड 192.168.55.172 "आरंभिक" है और यह "गैर-प्राथमिक" घटक बनाता है। इसका मतलब है कि इस नोड ने क्लस्टर के साथ कनेक्शन खो दिया है - सबसे अधिक संभावना है कि किसी प्रकार की नेटवर्क समस्याएँ (वास्तव में, हमने 192.168.55.171 और 192.168.55.173 दोनों से इस नोड पर ट्रैफ़िक को अवरुद्ध करने के लिए iptables का उपयोग किया था)।
इस समय हमें थोड़ा रुकना होगा और वर्णन करना होगा कि गैलेरा क्लस्टर आंतरिक रूप से कैसे काम करता है। हम बहुत अधिक विवरण में नहीं जाएंगे क्योंकि यह इस ब्लॉग पोस्ट के दायरे में नहीं है, लेकिन अगले कॉलम में प्रस्तुत डेटा के महत्व को समझने के लिए कुछ ज्ञान की आवश्यकता है।
गैलेरा एक "वस्तुतः" सिंक्रोनस, मल्टी-मास्टर क्लस्टर है। इसका मतलब है कि आपको डेटा को एक ही समय में "वस्तुतः" नोड्स में स्थानांतरित करने की अपेक्षा करनी चाहिए (पिछड़े हुए दासों के साथ कोई और कष्टप्रद समस्या नहीं) और आप क्लस्टर में किसी भी नोड को लिख सकते हैं (दास को मास्टर को बढ़ावा देने के साथ कोई और कष्टप्रद समस्या नहीं है) ) इसे पूरा करने के लिए, गैलेरा राइटसेट का उपयोग करता है - परिवर्तनों का परमाणु सेट जो पूरे क्लस्टर में दोहराया जाता है। एक राइटसेट में कई पंक्ति परिवर्तन और लॉकिंग के संबंध में डेटा जैसी अतिरिक्त आवश्यक जानकारी हो सकती है।
एक बार क्लाइंट COMMIT जारी करता है, लेकिन इससे पहले कि MySQL वास्तव में कुछ भी करता है, एक राइटसेट बनाया जाता है और प्रमाणन के लिए क्लस्टर में सभी नोड्स को भेजा जाता है। सभी नोड्स जांचते हैं कि परिवर्तन करना संभव है या नहीं (क्योंकि परिवर्तन अन्य निष्पादित किए गए लेखन में हस्तक्षेप कर सकते हैं, इस बीच, सीधे दूसरे नोड पर)। यदि हाँ, डेटा वास्तव में MySQL द्वारा प्रतिबद्ध है, यदि नहीं, तो रोलबैक निष्पादित किया जाता है।
यह याद रखना महत्वपूर्ण है कि नियमित प्रतिकृति में दासों के समान नोड्स अलग-अलग प्रदर्शन कर सकते हैं - कुछ में दूसरों की तुलना में बेहतर हार्डवेयर हो सकते हैं, कुछ दूसरों की तुलना में अधिक लोड हो सकते हैं। फिर भी "वर्चुअल" सिंक्रोनाइज़ेशन को बनाए रखने के लिए, गैलेरा को उन्हें संक्षिप्त और त्वरित तरीके से राइटसेट को संसाधित करने की आवश्यकता होती है। एक ऐसा तंत्र होना चाहिए जो प्रतिकृति को थ्रॉटल कर सके और धीमी नोड्स को बाकी क्लस्टर के साथ बनाए रखने की अनुमति दे सके।
आइए "लोकल सेंड क्यू [अब/औसत]" और "लोकल रिसीव क्यू [अब/औसत]" कॉलम पर एक नज़र डालते हैं। प्रत्येक नोड में राइटसेट भेजने और प्राप्त करने के लिए एक स्थानीय कतार होती है। यह कुछ लिखने और कतार डेटा को समानांतर करने की अनुमति देता है जिसे एक बार में संसाधित नहीं किया जा सकता है यदि नोड यातायात के साथ नहीं रख सकता है। SHOW GLOBAL STATUS में हम दोनों कतारों का वर्णन करने वाले आठ काउंटर, प्रति कतार चार काउंटर पा सकते हैं:
- wsrep_local_send_queue - भेजें कतार की वर्तमान स्थिति
- wsrep_local_send_queue_min - फ्लश स्थिति के बाद से न्यूनतम
- wsrep_local_send_queue_max - फ्लश स्थिति के बाद से अधिकतम
- wsrep_local_send_queue_avg - फ्लश स्थिति के बाद से औसत
- wsrep_local_recv_queue - प्राप्त कतार की वर्तमान स्थिति
- wsrep_local_recv_queue_min - फ्लश स्थिति के बाद से न्यूनतम
- wsrep_local_recv_queue_max - फ्लश स्थिति के बाद से अधिकतम
- wsrep_local_recv_queue_avg - फ्लश स्थिति के बाद से औसत
उपरोक्त मेट्रिक्स क्लस्टरकंट्रोल -> प्रदर्शन -> डीबी स्थिति के तहत नोड्स में एकीकृत हैं:
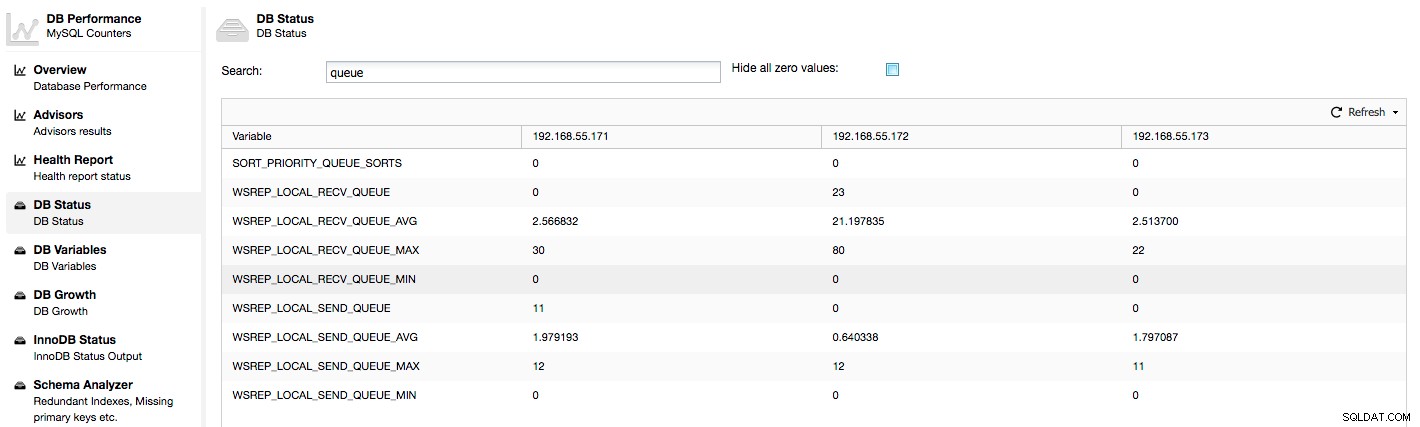
ClusterControl "अभी" और "औसत" काउंटर प्रदर्शित करता है, क्योंकि वे एकल संख्या के रूप में सबसे अधिक सार्थक हैं (आप कतारों की वर्तमान स्थिति का वर्णन करने वाले चर के आधार पर कस्टम ग्राफ़ भी बना सकते हैं)। जब हम देखते हैं कि कतारों में से एक बढ़ रहा है, तो इसका मतलब है कि नोड प्रतिकृति के साथ नहीं रह सकता है और अन्य नोड्स को इसे पकड़ने की अनुमति देने के लिए धीमा करना होगा। हम उस दिए गए नोड के कार्यभार की जांच करने की अनुशंसा करते हैं - कुछ लंबे समय तक चलने वाले प्रश्नों के लिए प्रक्रिया सूची की जांच करें, CPU उपयोग और I / O कार्यभार जैसे OS आँकड़े देखें। हो सकता है कि उस नोड से कुछ ट्रैफ़िक को बाकी क्लस्टर में पुनर्वितरित करना भी संभव हो।
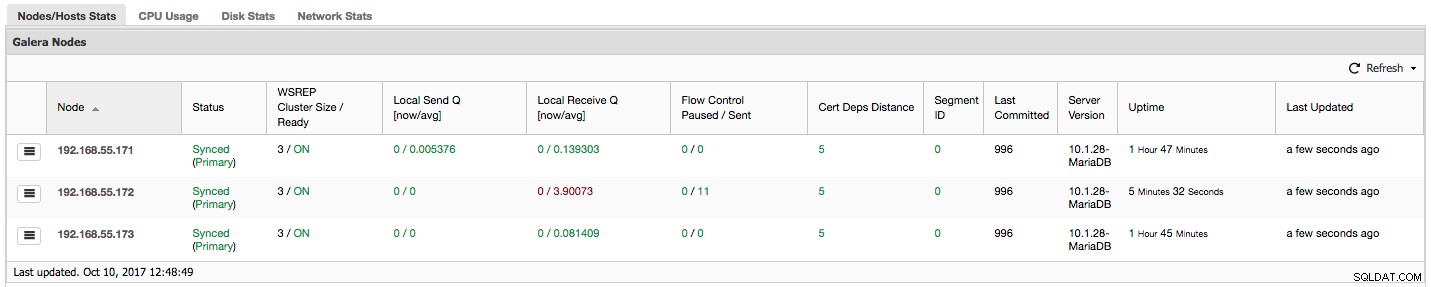
"फ्लो कंट्रोल पॉज़्ड" उस समय के प्रतिशत के बारे में जानकारी दिखाता है जब किसी दिए गए नोड को बहुत अधिक भार के कारण इसकी प्रतिकृति को रोकना पड़ा। जब एक नोड कार्यभार के साथ नहीं रह सकता है तो यह अन्य नोड्स को फ्लो कंट्रोल पैकेट भेजता है, उन्हें सूचित करता है कि उन्हें राइटसेट भेजने पर थ्रॉटल करना चाहिए। हमारे स्क्रीनशॉट में, हमारे पास नोड 192.168.55.172 के लिए '0.30' का मान है। इसका मतलब यह है कि लगभग 30% बार इस नोड को प्रतिकृति को रोकना पड़ा क्योंकि यह अन्य नोड्स के लिए आवश्यक राइटसेट प्रमाणन दर को बनाए रखने में सक्षम नहीं था (या सरल, बहुत सारे राइट्स ने इसे मारा!) जैसा कि हम देख सकते हैं, यह "लोकल रिसीव क्यू [औसत]" हमें इस तथ्य की ओर भी इशारा करता है।
अगला कॉलम, "फ्लो कंट्रोल भेजा गया" हमें इस बारे में जानकारी देता है कि क्लस्टर को दिए गए नोड में कितने फ्लो कंट्रोल पैकेट भेजे गए हैं। फिर से, हम देखते हैं कि यह नोड 192.168.55.172 है जो क्लस्टर को धीमा कर रहा है।
हम इस जानकारी के साथ क्या कर सकते हैं? अधिकतर, हमें जांच करनी चाहिए कि धीमे नोड में क्या हो रहा है। CPU उपयोग की जाँच करें, I/O प्रदर्शन और नेटवर्क आँकड़े जाँचें। यह पहला कदम यह आकलन करने में मदद करता है कि हम किस तरह की समस्या का सामना कर रहे हैं।
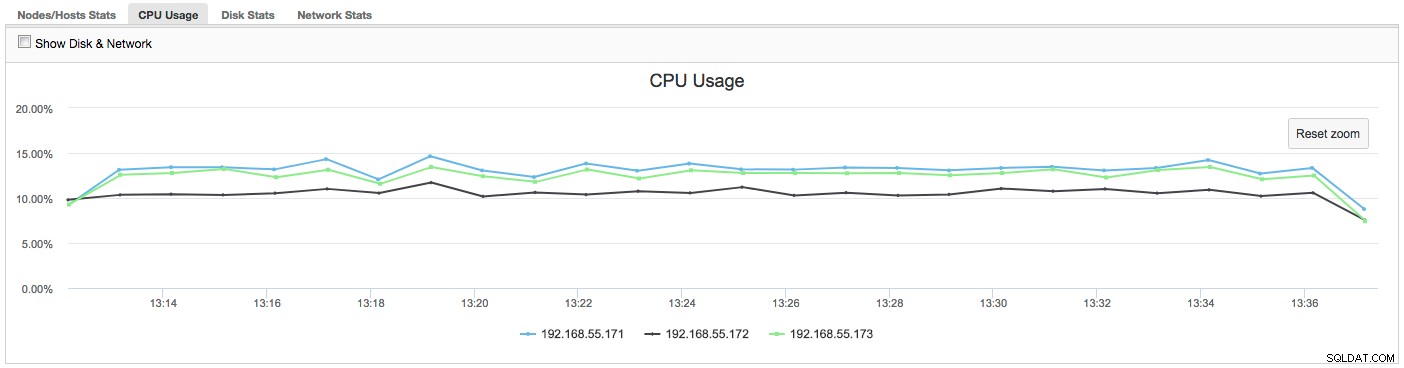
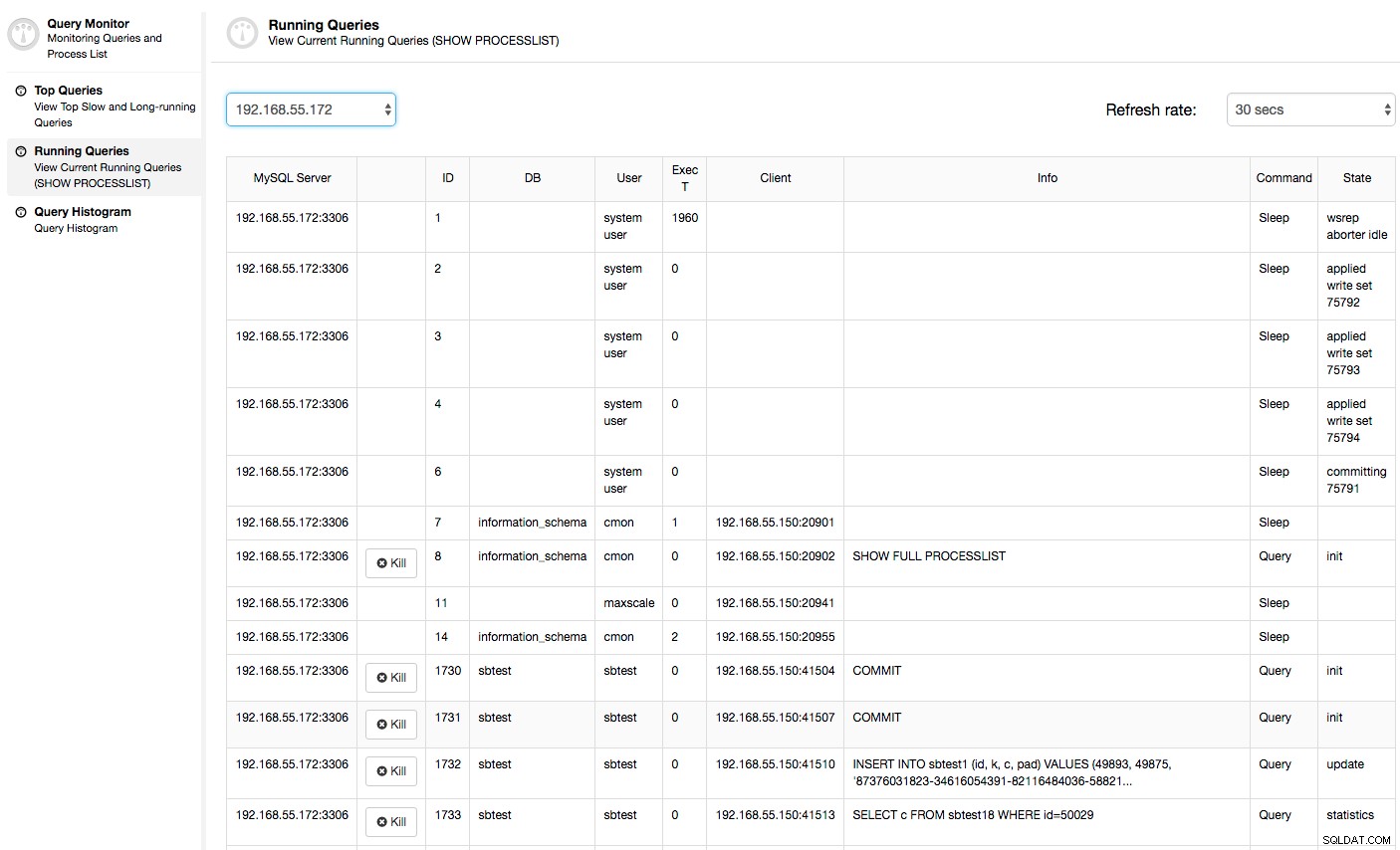
इस मामले में, एक बार जब हम CPU उपयोग टैब पर स्विच करते हैं, तो यह स्पष्ट हो जाता है कि व्यापक CPU उपयोग हमारे मुद्दों का कारण बन रहा है। अगला कदम यह होगा कि आपत्तिजनक प्रश्नों की जांच के लिए PROCESSLIST (क्वेरी मॉनिटर -> रनिंग क्वेरी -> 192.168.55.172 तक फिल्टर) को देखकर अपराधी की पहचान की जाए:
या, ऑपरेटिंग सिस्टम की ओर से नोड पर प्रक्रियाओं की जांच करें (नोड्स -> 192.168.55.172 -> शीर्ष) यह देखने के लिए कि लोड गैलेरा/माईएसक्यूएल के बाहर किसी चीज के कारण तो नहीं है।
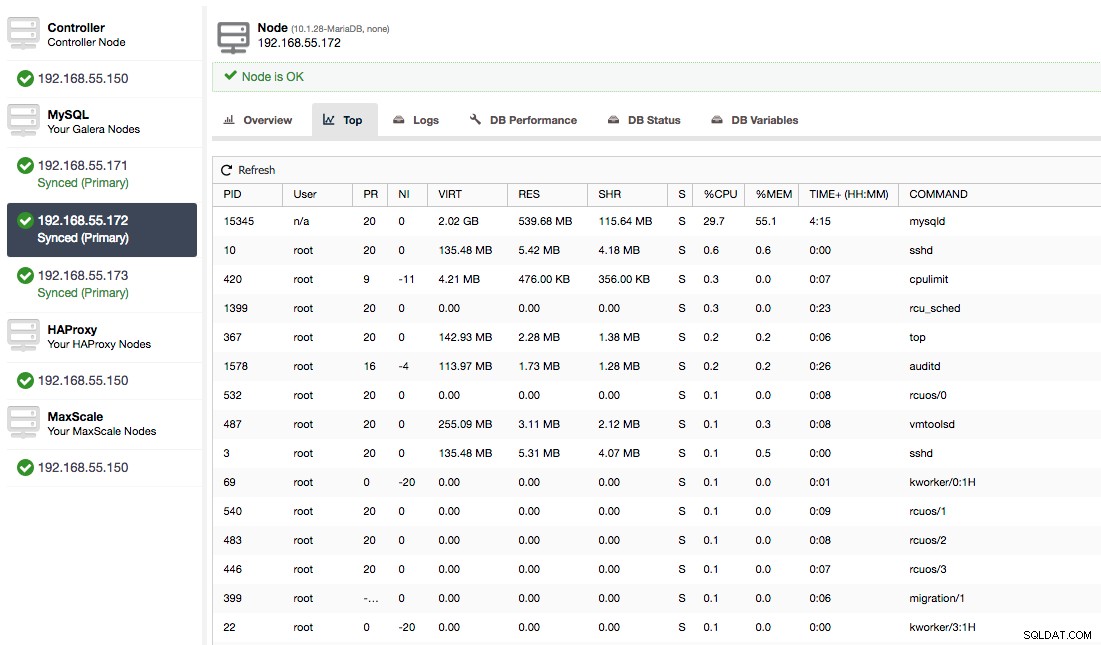
इस मामले में, हमने cpulimit के माध्यम से mysqld कमांड को निष्पादित किया है, विशेष रूप से mysqld प्रक्रिया के लिए धीमी CPU उपयोग को अनुकरण करने के लिए इसे 400% उपलब्ध CPU (सर्वर में 4 कोर) में से 30% तक सीमित करके।
"सर्ट डिप्स डिस्टेंस" कॉलम हमें इस बारे में जानकारी देता है कि औसतन कितने राइटसेट समानांतर में लागू किए जा सकते हैं। राइटसेट, कभी-कभी, एक ही समय में निष्पादित किए जा सकते हैं - गैलेरा कई wsrep_slave_threads का उपयोग करके इसका लाभ उठाता है राइटसेट लागू करने के लिए। यह कॉलम आपको कुछ विचार देता है कि आप अपने कार्यभार पर कितने दास धागे का उपयोग कर सकते हैं। यह ध्यान देने योग्य है कि wsrep_slave_threads को सेट करने का कोई मतलब नहीं है इस कॉलम में या wsrep_cert_deps_distance में आपके द्वारा देखे जाने वाले मानों से अधिक के लिए परिवर्तनशील स्थिति चर, जिस पर "सर्टिफिकेट डिप्स डिस्टेंस" कॉलम आधारित है। एक और महत्वपूर्ण नोट - wsrep_slave_threads . को सेट करने का कोई मतलब नहीं है आपके CPU में जितने कोर हैं, उससे अधिक के लिए परिवर्तनशील।
"सेगमेंट आईडी" - इस कॉलम में कुछ और स्पष्टीकरण की आवश्यकता होगी। सेगमेंट गैलेरा 3.0 में जोड़ी गई एक नई सुविधा है। इस संस्करण से पहले, सभी नोड्स के बीच राइटसेट का आदान-प्रदान किया जाता था। मान लें कि हमारे पास दो डेटासेंटर हैं:
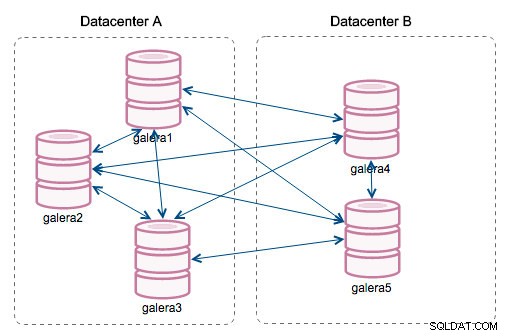
इस तरह की बकवास स्थानीय नेटवर्क पर ठीक काम करती है लेकिन WAN एक अलग कहानी है - बढ़ी हुई विलंबता के कारण प्रमाणन धीमा हो जाता है, क्लस्टर के प्रत्येक सदस्य के बीच राइटसेट को स्थानांतरित करने के लिए उपयोग किए जाने वाले नेटवर्क बैंडविड्थ के कारण अतिरिक्त लागत उत्पन्न होती है।
"सेगमेंट" की शुरुआत के साथ, चीजें बदल गईं। आप wsrep_provider_options को संशोधित करके किसी सेगमेंट को नोड असाइन कर सकते हैं चर और इसमें "gmcast.segment=x" (0, 1, 2) जोड़ना। समान खंड संख्या वाले नोड्स को उसी डेटासेंटर में माना जाता है, जो स्थानीय नेटवर्क से जुड़ा होता है। हमारा ग्राफ तब अलग हो जाता है:
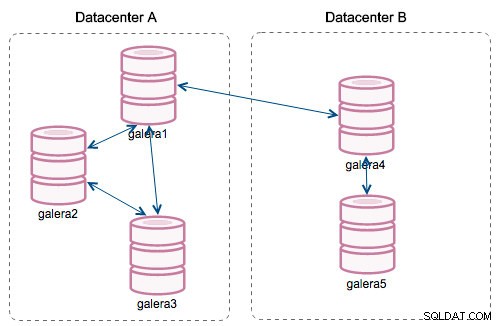
मुख्य अंतर यह है कि यह अब सभी के लिए संचार नहीं है। प्रत्येक खंड के भीतर, हाँ - यह अभी भी एक ही तंत्र है लेकिन दोनों खंड केवल दो चुने हुए नोड्स के बीच एक ही कनेक्शन के माध्यम से संवाद करते हैं। डाउनटाइम के मामले में, यह कनेक्शन स्वचालित रूप से विफल हो जाएगा। नतीजतन, हमें कम नेटवर्क चैटर और रिमोट डेटासेंटर के बीच कम बैंडविड्थ उपयोग मिलता है। तो, मूल रूप से, "सेगमेंट आईडी" कॉलम हमें बताता है कि नोड किस सेगमेंट को सौंपा गया है।
"अंतिम प्रतिबद्ध" कॉलम हमें उस राइटसेट की अनुक्रम संख्या के बारे में जानकारी देता है जिसे किसी दिए गए नोड पर अंतिम बार निष्पादित किया गया था। यह निर्धारित करने में उपयोगी हो सकता है कि क्लस्टर को बूटस्ट्रैप करने की आवश्यकता होने पर कौन सा नोड सबसे वर्तमान है।
शेष कॉलम स्व-व्याख्यात्मक हैं:सर्वर संस्करण, नोड का अपटाइम और जब स्थिति अपडेट की गई थी।
जैसा कि आप देख सकते हैं, "अवलोकन" टैब में "नोड्स/होस्ट आँकड़े" का "गैलेरा नोड्स" खंड आपको क्लस्टर के स्वास्थ्य की बहुत अच्छी समझ देता है - चाहे वह "प्राथमिक" घटक बनाता हो, कितने नोड स्वस्थ हैं , क्या कुछ नोड्स के साथ कोई प्रदर्शन समस्या है और यदि हां, तो कौन सा नोड क्लस्टर को धीमा कर रहा है।
जब आप अपने गैलेरा क्लस्टर को संचालित करते हैं तो डेटा का यह सेट बहुत काम आता है, इसलिए उम्मीद है कि अब कोई और उड़ान अंधा नहीं होगा :-)