ClusterControl को आपके डेटाबेस सिस्टम को प्रभावित करने वाली विभिन्न प्रकार की सामान्य विफलताओं का स्वचालित रूप से जवाब देने के लिए कई पुनर्प्राप्ति एल्गोरिदम के साथ प्रोग्राम किया गया है। यह क्लस्टर को पुनर्प्राप्त करने का सबसे अच्छा तरीका निर्धारित करने में आपकी मदद करने के लिए विभिन्न प्रकार के डेटाबेस टोपोलॉजी और डेटाबेस से संबंधित प्रक्रिया प्रबंधन को समझता है। एक तरह से, ClusterControl आपके डेटाबेस की उपलब्धता में सुधार करता है।
कुछ टोपोलॉजी मैनेजर केवल क्लस्टर रिकवरी जैसे एमएचए, ऑर्केस्ट्रेटर और माइस्क्लफेलओवर को कवर करते हैं, लेकिन आपको नोड रिकवरी को स्वयं संभालना होगा। ClusterControl क्लस्टर और नोड दोनों स्तरों पर पुनर्प्राप्ति का समर्थन करता है।
कॉन्फ़िगरेशन विकल्प
ClusterControl द्वारा समर्थित दो पुनर्प्राप्ति घटक हैं, अर्थात्:
- क्लस्टर - क्लस्टर को चालू स्थिति में वापस लाने का प्रयास
- नोड - किसी नोड को चालू स्थिति में वापस लाने का प्रयास
यह सुनिश्चित करने के लिए कि सेवा की उपलब्धता यथासंभव अधिक है, ये दो घटक सबसे महत्वपूर्ण चीजें हैं। यदि आपके पास पहले से ही ClusterControl के शीर्ष पर एक टोपोलॉजी प्रबंधक है, तो आप स्वचालित पुनर्प्राप्ति सुविधा को अक्षम कर सकते हैं और अन्य टोपोलॉजी प्रबंधक को इसे आपके लिए संभालने दे सकते हैं। आपके पास ClusterControl के साथ सभी संभावनाएं हैं।
स्वचालित पुनर्प्राप्ति सुविधा को एक साधारण टॉगल ON/OFF के साथ सक्षम और अक्षम किया जा सकता है, और यह क्लस्टर या नोड पुनर्प्राप्ति के लिए काम करता है। हरे रंग के चिह्न का अर्थ है सक्षम और लाल चिह्न का अर्थ अक्षम है। निम्न स्क्रीनशॉट दिखाता है कि आप इसे डेटाबेस क्लस्टर सूची में कहां पा सकते हैं:
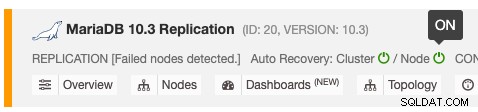
3 ClusterControl पैरामीटर हैं जिनका उपयोग पुनर्प्राप्ति व्यवहार को नियंत्रित करने के लिए किया जा सकता है। सभी पैरामीटर डिफ़ॉल्ट रूप से सही हैं (बूलियन पूर्णांक 0 या 1 के साथ सेट):
- enable_autorecovery - क्लस्टर और नोड पुनर्प्राप्ति सक्षम करें। यह पैरामीटर enable_cluster_recovery और enable_node_recovery का सुपरसेट है। अगर यह 0 पर सेट है, तो सबसेट पैरामीटर बंद कर दिए जाएंगे।
- enable_cluster_recovery - सक्षम होने पर ClusterControl क्लस्टर रिकवरी करेगा।
- enable_node_recovery - सक्षम होने पर ClusterControl नोड रिकवरी करेगा।
क्लस्टर पुनर्प्राप्ति में संपूर्ण क्लस्टर टोपोलॉजी लाने का पुनर्प्राप्ति प्रयास शामिल है। उदाहरण के लिए, एक मास्टर-दास प्रतिकृति में किसी भी समय कम से कम एक मास्टर जीवित होना चाहिए, चाहे उपलब्ध दासों की संख्या कुछ भी हो। क्लस्टरकंट्रोल प्रतिकृति क्लस्टर के लिए कम से कम एक बार टोपोलॉजी को सही करने का प्रयास करता है, लेकिन एनडीबी क्लस्टर और गैलेरा क्लस्टर जैसे मल्टी-मास्टर प्रतिकृति के लिए असीम रूप से।
नोड पुनर्प्राप्ति नोड पुनर्प्राप्ति समस्या को कवर करती है जैसे कि यदि किसी नोड को ClusterControl ज्ञान के बिना रोका जा रहा था, उदाहरण के लिए, SSH कंसोल से सिस्टम स्टॉप कमांड के माध्यम से या OOM प्रक्रिया द्वारा मारा जा रहा है।
नोड पुनर्प्राप्ति
ClusterControl प्रक्रिया की निगरानी और डेटाबेस नोड्स से कनेक्टिविटी द्वारा आंतरायिक विफलता के मामले में डेटाबेस नोड को पुनर्प्राप्त करने में सक्षम है। प्रक्रिया के लिए, यह सिस्टमड के समान काम करता है, जहां यह सुनिश्चित करेगा कि MySQL सेवा शुरू हो गई है और चल रही है जब तक कि आप जानबूझकर इसे ClusterControl UI के माध्यम से रोक नहीं देते।
यदि नोड ऑनलाइन वापस आता है, तो ClusterControl डेटाबेस नोड से एक कनेक्शन स्थापित करेगा और आवश्यक कार्रवाई करेगा। नोड को पुनर्प्राप्त करने के लिए क्लस्टरकंट्रोल निम्न कार्य करेगा:
- यह सिस्टमd/chkconfig/init के 30 सेकंड के लिए मॉनिटर की गई सेवाओं/प्रक्रियाओं को शुरू करने की प्रतीक्षा करेगा
- यदि निगरानी की गई सेवाएं/प्रक्रियाएं अभी भी बंद हैं, तो ClusterControl डेटाबेस सेवा को स्वचालित रूप से प्रारंभ करने का प्रयास करेगा।
- यदि ClusterControl निगरानी की गई सेवाओं/प्रक्रियाओं को पुनर्प्राप्त करने में असमर्थ है, तो एक अलार्म बजाया जाएगा।
ध्यान दें कि यदि उपयोगकर्ता द्वारा डेटाबेस शटडाउन शुरू किया जाता है, तो ClusterControl विशेष नोड को पुनर्प्राप्त करने का प्रयास नहीं करेगा। यह उम्मीद करता है कि उपयोगकर्ता नोड -> नोड क्रिया -> नोड प्रारंभ करें या स्पष्ट रूप से ओएस कमांड का उपयोग करके क्लस्टरकंट्रोल यूआई के माध्यम से इसे वापस शुरू करेगा।
पुनर्प्राप्ति में डेटाबेस से संबंधित सभी सेवाएं जैसे ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus निर्यातक और garbd शामिल हैं। प्रोमेथियस निर्यातकों पर विशेष ध्यान जहां ClusterControl निर्यातक प्रक्रिया को निष्क्रिय करने के लिए "डेमॉन" नामक प्रोग्राम का उपयोग करता है। ClusterControl स्वास्थ्य जांच और सत्यापन के लिए निर्यातक के लिसनिंग पोर्ट से जुड़ने का प्रयास करेगा। इस प्रकार, यह सुनिश्चित करने के लिए कि पुनर्प्राप्ति के दौरान कोई झूठा अलार्म नहीं है, यह सुनिश्चित करने के लिए ClusterControl और Prometheus सर्वर से निर्यातक पोर्ट खोलने की अनुशंसा की जाती है।
क्लस्टर पुनर्प्राप्ति
ClusterControl डेटाबेस टोपोलॉजी को समझता है और पुनर्प्राप्ति करने में सर्वोत्तम प्रथाओं का पालन करता है। एक डेटाबेस क्लस्टर के लिए जो गैलेरा क्लस्टर, एनडीबी क्लस्टर और मोंगोडीबी रेप्लिकसेट जैसे बिल्ट-इन फॉल्ट टॉलरेंस के साथ आता है, फेलओवर प्रक्रिया डेटाबेस सर्वर द्वारा कोरम गणना, दिल की धड़कन और रोल स्विचिंग (यदि कोई हो) के माध्यम से स्वचालित रूप से की जाएगी। ClusterControl प्रक्रिया की निगरानी करता है और विज़ुअलाइज़ेशन में आवश्यक समायोजन करता है जैसे कि टोपोलॉजी दृश्य के तहत परिवर्तनों को प्रतिबिंबित करना और नई भूमिका के लिए निगरानी और प्रबंधन घटक को समायोजित करना, जैसे, प्रतिकृति सेट में नया प्राथमिक नोड।
उन डेटाबेस प्रौद्योगिकियों के लिए जिनमें MySQL/MariaDB प्रतिकृति और PostgreSQL/TimescaleDB स्ट्रीमिंग प्रतिकृति जैसे स्वचालित पुनर्प्राप्ति के साथ अंतर्निहित दोष सहिष्णुता नहीं है, ClusterControl द्वारा प्रदान की गई सर्वोत्तम प्रथाओं का पालन करके पुनर्प्राप्ति प्रक्रियाओं को निष्पादित करेगा। डेटाबेस विक्रेता। यदि पुनर्प्राप्ति विफल हो जाती है, तो उपयोगकर्ता के हस्तक्षेप की आवश्यकता होती है, और निश्चित रूप से आपको इसके बारे में एक अलार्म सूचना मिलेगी।
मिश्रित/हाइब्रिड टोपोलॉजी में, उदाहरण के लिए एक एसिंक्रोनस स्लेव जो गैलेरा क्लस्टर या एनडीबी क्लस्टर से जुड़ा होता है, क्लस्टर रिकवरी सक्षम होने पर नोड को क्लस्टर कंट्रोल द्वारा पुनर्प्राप्त किया जाएगा।
क्लस्टर पुनर्प्राप्ति स्टैंडअलोन MySQL सर्वर पर लागू नहीं होती है। हालांकि, इस क्लस्टर प्रकार के लिए ClusterControl UI में नोड और क्लस्टर पुनर्प्राप्ति दोनों को चालू करने की अनुशंसा की जाती है।
MySQL/MariaDB प्रतिकृति
ClusterControl निम्नलिखित MySQL/MariaDB प्रतिकृति सेटअप की पुनर्प्राप्ति का समर्थन करता है:
- MySQL GTID के साथ मास्टर-स्लेव
- MariaDB GTID के साथ मास्टर-स्लेव
- बिना GTID वाले मास्टर-स्लेव (MySQL और MariaDB दोनों)
- MySQL GTID के साथ मास्टर-मास्टर
- MariaDB GTID के साथ मास्टर-मास्टर
- गैलेरा क्लस्टर से जुड़े एसिंक्रोनस स्लेव
क्लस्टर नियंत्रण करते समय क्लस्टर नियंत्रण निम्नलिखित मापदंडों का सम्मान करेगा:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filament_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
प्रत्येक पैरामीटर के बारे में अधिक जानकारी के लिए, दस्तावेज़ीकरण पृष्ठ देखें।
मास्टर-स्लेव प्रतिकृति की निगरानी और प्रबंधन करते समय ClusterControl निम्नलिखित नियमों का पालन करेगा:
- सभी नोड्स read_only=ON और super_read_only=ON (इसकी भूमिका कुछ भी हो) के साथ शुरू होंगे।
- किसी भी समय केवल एक मास्टर (read_only=OFF) को काम करने की अनुमति है।
- टोपोलॉजी को मैप करने के लिए MySQL वेरिएबल रिपोर्ट_होस्ट पर भरोसा करें।
- यदि दो या दो से अधिक नोड हैं जिनमें एक समय में read_only=OFF है, तो ClusterControl स्वचालित रूप से दोनों मास्टर्स पर read_only=ON सेट कर देगा, ताकि उन्हें आकस्मिक लेखन से बचाया जा सके। केवल-पढ़ने के लिए अक्षम करके वास्तविक मास्टर को चुनने के लिए उपयोगकर्ता के हस्तक्षेप की आवश्यकता होती है। Nodes -> Node क्रियाएँ -> केवल पढ़ने के लिए अक्षम करें पर जाएँ।
यदि सक्रिय मास्टर नीचे चला जाता है, तो ClusterControl निम्नलिखित क्रम में मास्टर फ़ेलओवर करने का प्रयास करेगा:
- मास्टर पहुंच से बाहर होने के 3 सेकंड के बाद, ClusterControl अलार्म बजाएगा।
- दास की उपलब्धता की जांच करें, कम से कम एक गुलाम को ClusterControl द्वारा उपलब्ध कराया जाना चाहिए।
- स्वामी बनने के लिए दास को उम्मीदवार के रूप में चुनें।
- ClusterControl GTID सक्षम होने पर गलत लेनदेन की संभावना की गणना करेगा।
- यदि कोई गलत लेन-देन नहीं पाया जाता है, तो चुने गए को नए मास्टर के रूप में पदोन्नत किया जाएगा।
- गुलामों द्वारा उपयोग किए जाने वाले प्रतिकृति उपयोगकर्ता बनाएं और प्रदान करें।
- उन सभी दासों के लिए मास्टर बदलें जो पुराने मास्टर को नए पदोन्नत मास्टर की ओर इशारा कर रहे थे।
- स्लेव प्रारंभ करें और केवल पढ़ने के लिए सक्षम करें।
- सभी नोड्स पर लॉग फ्लश करें।
- यदि स्लेव प्रमोशन विफल हो जाता है, तो ClusterControl पुनर्प्राप्ति कार्य को रोक देगा। पुनर्प्राप्ति कार्य को फिर से ट्रिगर करने के लिए उपयोगकर्ता के हस्तक्षेप या एक सीमोन सेवा पुनरारंभ की आवश्यकता है।
- जब पुराना मास्टर फिर से उपलब्ध होगा, तो इसे केवल-पढ़ने के लिए शुरू किया जाएगा और प्रतिकृति का हिस्सा नहीं होगा। उपयोगकर्ता के हस्तक्षेप की आवश्यकता है।
उसी समय, निम्नलिखित अलार्म उठाए जाएंगे:
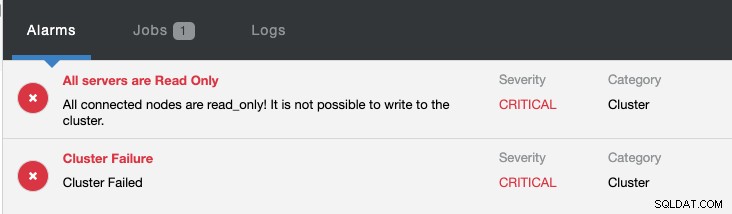
MySQL प्रतिकृति के लिए विफलता का परिचय देखें - 101 ब्लॉग और MySQL प्रतिकृति का स्वचालित विफलता - ClusterControl 1.4 में नया, ClusterControl के साथ MySQL प्रतिकृति विफलता को कॉन्फ़िगर और प्रबंधित करने के तरीके के बारे में अधिक जानकारी प्राप्त करने के लिए।
PostgreSQL/TimescaleDB स्ट्रीमिंग प्रतिकृति
ClusterControl निम्नलिखित PostgreSQL प्रतिकृति सेटअप की पुनर्प्राप्ति का समर्थन करता है:
- PostgreSQL स्ट्रीमिंग प्रतिकृति
- TimescaleDB स्ट्रीमिंग प्रतिकृति
क्लस्टर नियंत्रण करते समय क्लस्टर नियंत्रण निम्नलिखित मापदंडों का सम्मान करेगा:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
प्रत्येक पैरामीटर के बारे में अधिक जानकारी के लिए, दस्तावेज़ीकरण पृष्ठ देखें।
ClusterControl एक PostgreSQL स्ट्रीमिंग प्रतिकृति सेटअप के प्रबंधन और निगरानी के लिए निम्नलिखित नियमों का पालन करेगा:
- wal_level "प्रतिकृति" (या PostgreSQL संस्करण के आधार पर "hot_standby") पर सेट है।
- वैरिएबल आर्काइव_मोड मास्टर पर ON पर सेट है।
- स्लेव नोड्स पर पुनर्प्राप्ति.conf फ़ाइल सेट करें, जो नोड को केवल-पढ़ने के लिए सक्षम के साथ एक हॉट स्टैंडबाय में बदल देती है।
यदि सक्रिय मास्टर नीचे चला जाता है, तो ClusterControl निम्नलिखित क्रम में क्लस्टर पुनर्प्राप्ति करने का प्रयास करेगा:
- मास्टर तक पहुंचने के 10 सेकंड के बाद, ClusterControl अलार्म बजाएगा।
- 10 सेकंड के शानदार वेटिंग टाइमआउट के बाद, ClusterControl मास्टर फेलओवर जॉब शुरू करेगा।
- सबसे उन्नत नोड का निर्धारण करने के लिए सभी उपलब्ध नोड्स पर रिप्लेलोकेशन और रिसीवलोकेशन का नमूना लें।
- नए मास्टर के रूप में सबसे उन्नत नोड का प्रचार करें।
- गुलाम बंद करो।
- pg_rewind के साथ सिंक्रोनाइज़ेशन स्थिति सत्यापित करें।
- नए मास्टर के साथ दासों को फिर से शुरू करना।
- यदि स्लेव प्रमोशन विफल हो जाता है, तो ClusterControl पुनर्प्राप्ति कार्य को रोक देगा। पुनर्प्राप्ति कार्य को फिर से ट्रिगर करने के लिए उपयोगकर्ता के हस्तक्षेप या एक सीमोन सेवा पुनरारंभ की आवश्यकता है।
- जब पुराना मास्टर फिर से उपलब्ध होगा, तो उसे बंद करने के लिए बाध्य किया जाएगा और वह प्रतिकृति का हिस्सा नहीं होगा। उपयोगकर्ता के हस्तक्षेप की आवश्यकता है। आगे नीचे देखें।
जब पुराना मास्टर ऑनलाइन वापस आता है, यदि PostgreSQL सेवा चल रही है, तो ClusterControl PostgreSQL सेवा को बंद करने के लिए बाध्य करेगा। यह सर्वर को आकस्मिक लेखन से बचाने के लिए है, क्योंकि यह पुनर्प्राप्ति फ़ाइल (recovery.conf) के बिना प्रारंभ किया जाएगा, जिसका अर्थ है कि यह लिखने योग्य होगा। आपको उम्मीद करनी चाहिए कि निम्न पंक्तियाँ postgresql-{day}.log में दिखाई देंगी:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downपोस्टग्रेएसक्यूएल सर्वर के 05:06:10 के आसपास वापस ऑनलाइन होने के बाद शुरू किया गया था, लेकिन क्लस्टरकंट्रोल उसके 17 सेकंड बाद 05:06:27 के आसपास तेजी से शटडाउन करता है। यदि यह ऐसा कुछ है जो आप नहीं चाहते हैं, तो आप इस क्लस्टर के लिए नोड पुनर्प्राप्ति को क्षण भर के लिए अक्षम कर सकते हैं।
ClusterControl के साथ PostgreSQL प्रतिकृति विफलता को कॉन्फ़िगर और प्रबंधित करने के तरीके के बारे में अधिक जानकारी प्राप्त करने के लिए PostgreSQL प्रतिकृति 101 के लिए पोस्टग्रेज़ प्रतिकृति और विफलता के स्वचालित विफलता की जाँच करें।
निष्कर्ष
ClusterControl स्वचालित पुनर्प्राप्ति डेटाबेस क्लस्टर टोपोलॉजी को समझता है और एक डाउन या डिग्रेडेड क्लस्टर को पूरी तरह से परिचालन क्लस्टर में पुनर्प्राप्त करने में सक्षम है जो डेटाबेस सेवा अपटाइम में जबरदस्त सुधार करेगा। अभी ClusterControl का प्रयास करें और SLA और डेटाबेस उपलब्धता में अपने नाइन प्राप्त करें। अपने नौ नहीं जानते? इस कूल नाइन कैलकुलेटर को देखें।



