एक ही क्वेरी में कई जॉइन करें
एकाधिक जॉइन आम तौर पर एकाधिक संग्रहों से जुड़े होते हैं, लेकिन आपको इनर जॉइन कैसे काम करता है इसकी बुनियादी समझ होनी चाहिए (इस विषय पर मेरी पिछली पोस्ट देखें)। हमारे पास पहले के दो संग्रहों के अलावा; इकाइयों और छात्रों, आइए एक तीसरा संग्रह जोड़ें और इसे खेल का नाम दें। नीचे दिए गए डेटा के साथ खेल संग्रह को पॉप्युलेट करें:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}हम चाहते हैं, उदाहरण के लिए, 1 के बराबर _id फ़ील्ड मान वाले छात्र के लिए सभी डेटा वापस करने के लिए। आम तौर पर, हम छात्रों के संग्रह से _id फ़ील्ड मान प्राप्त करने के लिए एक क्वेरी लिखेंगे, फिर क्वेरी के लिए दिए गए मान का उपयोग करें अन्य दो संग्रहों में डेटा। नतीजतन, यह सबसे अच्छा विकल्प नहीं होगा, खासकर अगर दस्तावेजों का एक बड़ा सेट शामिल है। Studio3T प्रोग्राम SQL फीचर का उपयोग करने के लिए एक बेहतर तरीका होगा। हम अपने MongoDB को सामान्य SQL अवधारणा के साथ क्वेरी कर सकते हैं और फिर हमारे विनिर्देश के अनुरूप परिणामी Mongo शेल कोड को मोटे तौर पर ट्यून करने का प्रयास कर सकते हैं। उदाहरण के लिए, आइए सभी संग्रहों से _id के बराबर 1 के साथ सभी डेटा प्राप्त करें:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;परिणामी दस्तावेज़ होगा:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}क्वेरी कोड टैब से, संवाददाता MongoDB कोड होगा:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);लौटाए गए दस्तावेज़ को देखते हुए, व्यक्तिगत रूप से मैं विशेष रूप से एम्बेडेड दस्तावेज़ों के साथ डेटा संरचना से बहुत खुश नहीं हूं। जैसा कि आप देख सकते हैं, _id फ़ील्ड वापस आ गए हैं और इकाइयों के लिए हमें ग्रेड फ़ील्ड को इकाइयों के अंदर एम्बेड करने की आवश्यकता नहीं हो सकती है।
हम चाहते हैं कि एक इकाई क्षेत्र एम्बेडेड इकाइयों के साथ हो, न कि कोई अन्य क्षेत्र। यह हमें मोटे धुन वाले हिस्से की ओर ले जाता है। पिछली पोस्ट की तरह, प्रदान किए गए कॉपी आइकन का उपयोग करके कोड को कॉपी करें और एकत्रीकरण फलक पर जाएं, पेस्ट आइकन का उपयोग करके सामग्री पेस्ट करें।
सबसे पहले चीज़ें, $match ऑपरेटर पहला चरण होना चाहिए, इसलिए इसे पहले स्थान पर ले जाएं और कुछ इस तरह रखें:
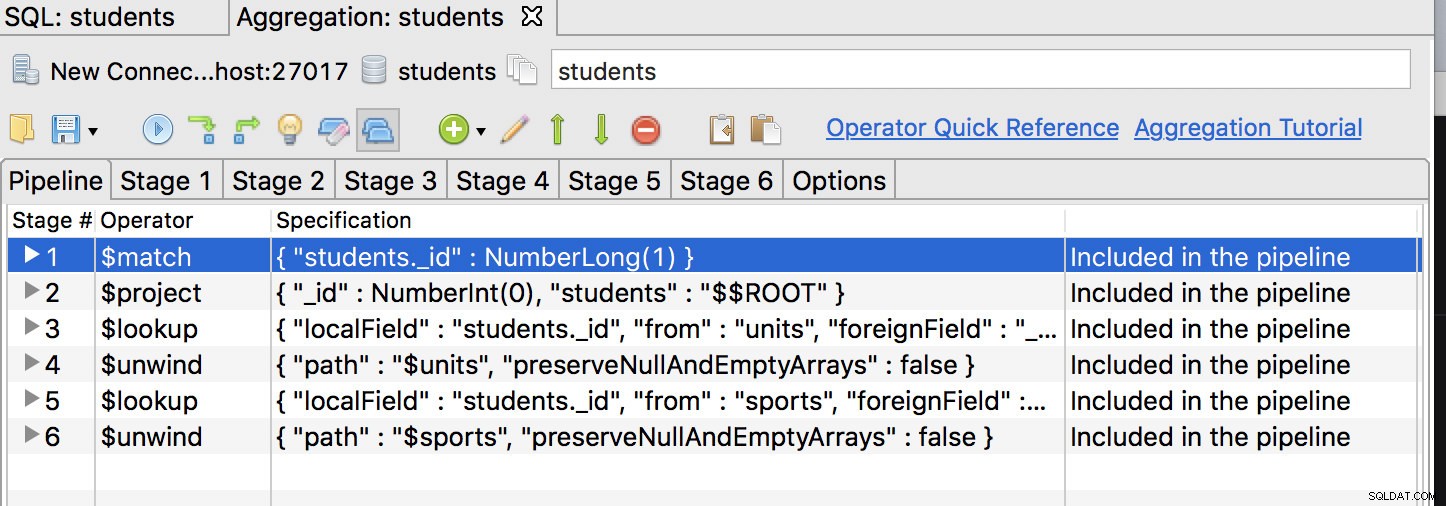
प्रथम चरण टैब पर क्लिक करें और क्वेरी को इसमें संशोधित करें:
{
"_id" : NumberLong(1)
}फिर हमें अपने डेटा के कई एम्बेडिंग चरणों को हटाने के लिए क्वेरी को और संशोधित करने की आवश्यकता है। ऐसा करने के लिए, हम उन क्षेत्रों के लिए डेटा कैप्चर करने के लिए नए फ़ील्ड जोड़ते हैं जिन्हें हम खत्म करना चाहते हैं यानी:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);जैसा कि आप देख सकते हैं, फाइन ट्यूनिंग प्रक्रिया में हमने नई फील्ड इकाइयाँ पेश की हैं जो एक एम्बेडेड फ़ील्ड के रूप में ग्रेड के साथ पिछली एकत्रीकरण पाइपलाइन की सामग्री को अधिलेखित कर देंगी। इसके अलावा, हमने यह इंगित करने के लिए एक _id फ़ील्ड बनाया है कि डेटा समान मूल्य वाले संग्रह में किसी दस्तावेज़ के संबंध में था। अंतिम $प्रोजेक्ट चरण खेल दस्तावेज़ में _id फ़ील्ड को हटाना है, ताकि हमारे पास नीचे दिए गए डेटा को बड़े करीने से प्रस्तुत किया जा सके।
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}हम यह भी प्रतिबंधित कर सकते हैं कि SQL के दृष्टिकोण से किन क्षेत्रों को वापस किया जाना चाहिए। उदाहरण के लिए हम छात्र का नाम, इस छात्र द्वारा की जा रही इकाइयाँ और नीचे दिए गए कोड के साथ कई JOINS का उपयोग करके खेले जाने वाले टूर्नामेंटों की संख्या वापस कर सकते हैं:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;यह हमें सबसे उपयुक्त परिणाम नहीं देता है। तो हमेशा की तरह, इसे कॉपी करें और एग्रीगेशन पेन में पेस्ट करें। हम उचित परिणाम प्राप्त करने के लिए नीचे दिए गए कोड के साथ तालमेल बिठाते हैं।
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);एसक्यूएल जॉइन अवधारणा से यह एकत्रीकरण परिणाम हमें नीचे दिखाया गया एक साफ और प्रस्तुत करने योग्य डेटा संरचना देता है।
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}बहुत आसान है, है ना? डेटा काफी प्रस्तुत करने योग्य है जैसे कि इसे एकल संग्रह में एकल दस्तावेज़ के रूप में संग्रहीत किया गया था।
बाएं बाहरी शामिल हों
LEFT OUTER JOIN आमतौर पर उन दस्तावेज़ों को दिखाने के लिए उपयोग किया जाता है जो सबसे अधिक चित्रित संबंधों के अनुरूप नहीं होते हैं। LEFT OUTER जॉइन के परिणामी सेट में दोनों संग्रहों की सभी पंक्तियाँ होती हैं जो WHERE क्लॉज मानदंड को पूरा करती हैं, जो कि INNER JOIN परिणाम सेट के समान है। इसके अलावा, बाएं संग्रह से कोई भी दस्तावेज़ जिसमें सही संग्रह में मेल खाने वाले दस्तावेज़ नहीं हैं, उन्हें भी परिणाम सेट में शामिल किया जाएगा। दाईं ओर की तालिका से चुने जा रहे फ़ील्ड NULL मान लौटाएंगे। हालाँकि, दाएँ संग्रह में कोई भी दस्तावेज़, जिसमें बाएँ संग्रह से मेल खाने वाले मानदंड नहीं हैं, वापस नहीं किए जाते हैं।
इन दो संग्रहों पर एक नज़र डालें:
विद्यार्थी
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}इकाइयां
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}छात्र संग्रह में हमारे पास _id फ़ील्ड मान 3 पर सेट नहीं है, लेकिन हमारे पास इकाइयों के संग्रह में है। इसी तरह, यूनिट संग्रह में कोई _id फ़ील्ड मान 4 नहीं है। यदि हम नीचे दिए गए प्रश्न के साथ जॉइन दृष्टिकोण में छात्रों के संग्रह को हमारे बाएं विकल्प के रूप में उपयोग करते हैं:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idइस कोड से हमें निम्नलिखित परिणाम प्राप्त होंगे:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}दूसरे दस्तावेज़ में इकाइयाँ फ़ील्ड नहीं है क्योंकि इकाइयों के संग्रह में कोई मेल खाने वाला दस्तावेज़ नहीं था। इस SQL क्वेरी के लिए, संवाददाता मोंगो कोड होगा
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);बेशक हमने फ़ाइन-ट्यूनिंग के बारे में सीखा है, इसलिए आप आगे बढ़ सकते हैं और अपने इच्छित अंतिम परिणाम के अनुरूप एकत्रीकरण पाइपलाइन का पुनर्गठन कर सकते हैं। जहाँ तक डेटाबेस प्रबंधन का संबंध है SQL एक बहुत ही शक्तिशाली उपकरण है। यह अपने आप में एक व्यापक विषय है, आप MongoDB के लिए संवाददाता कोड प्राप्त करने के लिए IN और GROUP BY क्लॉज का उपयोग करने का प्रयास कर सकते हैं और देख सकते हैं कि यह कैसे काम करता है।
निष्कर्ष
आप जिस तकनीक के साथ काम करने के आदी हैं, उसके अलावा एक नई (डेटाबेस) तकनीक के अभ्यस्त होने में बहुत समय लग सकता है। गैर-संबंधपरक डेटाबेस की तुलना में संबंधपरक डेटाबेस अभी भी अधिक सामान्य हैं। फिर भी, MongoDB की शुरुआत के साथ, चीजें बदल गई हैं और लोग इसके संबद्ध शक्तिशाली प्रदर्शन के कारण इसे जितनी जल्दी हो सके सीखना चाहेंगे।
शुरू से MongoDB सीखना थोड़ा थकाऊ हो सकता है, लेकिन हम MongoDB में डेटा में हेरफेर करने के लिए SQL के ज्ञान का उपयोग कर सकते हैं, संबंधित MongoDB कोड प्राप्त कर सकते हैं और सबसे उपयुक्त परिणाम प्राप्त करने के लिए इसे ठीक कर सकते हैं। इसे बढ़ाने के लिए उपलब्ध उपकरणों में से एक स्टूडियो 3T है। यह दो महत्वपूर्ण विशेषताएं प्रदान करता है जो जटिल डेटा के संचालन की सुविधा प्रदान करता है, वह है:SQL क्वेरी सुविधा और एकत्रीकरण संपादक। फ़ाइन ट्यूनिंग क्वेरीज़ न केवल आपको सर्वोत्तम परिणाम सुनिश्चित करेंगी बल्कि समय की बचत के मामले में प्रदर्शन में भी सुधार करेंगी।



