सिस्टम के प्रदर्शन को बढ़ाने के लिए, विशेष रूप से कंप्यूटर संरचनाओं के लिए, प्रदर्शन का एक अच्छा अवलोकन प्राप्त करने की प्रक्रिया की आवश्यकता होती है। इस प्रक्रिया को आम तौर पर निगरानी कहा जाता है। निगरानी डेटाबेस प्रबंधन का एक अनिवार्य हिस्सा है और आपके MongoDB की विस्तृत प्रदर्शन जानकारी न केवल आपको इसकी कार्यात्मक स्थिति का आकलन करने में मदद करेगी; लेकिन विसंगतियों पर एक सुराग भी दें, जो रखरखाव करते समय सहायक होता है। असामान्य व्यवहारों की पहचान करना और उन्हें और अधिक गंभीर विफलताओं में बदलने से पहले उन्हें ठीक करना आवश्यक है।
कुछ प्रकार की विफलताएं उत्पन्न हो सकती हैं...
- अंतराल या मंदी
- संसाधन अपर्याप्तता
- सिस्टम हिचकी
निगरानी अक्सर मेट्रिक्स के विश्लेषण पर केंद्रित होती है। कुछ प्रमुख मीट्रिक जिन पर आप नज़र रखना चाहेंगे उनमें शामिल हैं...
- डेटाबेस का प्रदर्शन
- संसाधनों का उपयोग (सीपीयू उपयोग, उपलब्ध मेमोरी और नेटवर्क उपयोग)
- उभरते झटके
- संसाधनों की संतृप्ति और सीमा
- थ्रूपुट संचालन
इस ब्लॉग में हम इन मेट्रिक्स पर विस्तार से चर्चा करने जा रहे हैं और MongoDB (जैसे उपयोगिताओं और कमांड) से उपलब्ध टूल को देखेंगे। हम अन्य सॉफ़्टवेयर टूल जैसे पेंडोरा, एफएमएस ओपन सोर्स और रोबो 3 टी को भी देखेंगे। सरलता के लिए, हम इस लेख में मेट्रिक्स प्रदर्शित करने के लिए रोबो 3T सॉफ़्टवेयर का उपयोग करने जा रहे हैं।
डेटाबेस का प्रदर्शन
डेटाबेस पर जांच करने वाली पहली और महत्वपूर्ण बात इसका सामान्य प्रदर्शन है, उदाहरण के लिए, सर्वर सक्रिय है या नहीं। यदि आप Robo 3T में डेटाबेस पर यह आदेश db.serverStatus() चलाते हैं, तो आपको अपने सर्वर की स्थिति दिखाते हुए यह जानकारी प्रस्तुत की जाएगी।
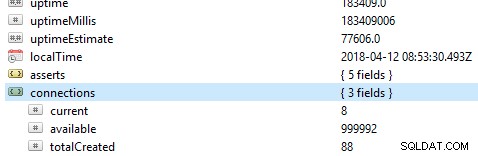

प्रतिकृति सेट
रेप्लिका सेट मोंगॉड प्रक्रियाओं का एक समूह है जो समान डेटा सेट को बनाए रखता है। यदि आप विशेष रूप से उत्पादन मोड में प्रतिकृति सेट का उपयोग कर रहे हैं, तो ऑपरेशन लॉग प्रतिकृति प्रक्रिया के लिए एक आधार प्रदान करेगा। सभी लेखन कार्यों को नोड्स का उपयोग करके ट्रैक किया जाता है, जो कि एक प्राथमिक नोड और एक द्वितीयक नोड है, जो एक सीमित आकार के संग्रह को संग्रहीत करता है। प्राथमिक नोड पर, लेखन कार्यों को लागू और संसाधित किया जाता है। हालांकि, यदि ऑपरेशन लॉग में कॉपी करने से पहले प्राथमिक नोड विफल हो जाता है, तो द्वितीयक लेखन किया जाता है लेकिन इस मामले में डेटा को दोहराया नहीं जा सकता है।
नज़र रखने के लिए मुख्य मीट्रिक...
प्रतिकृति अंतराल
यह परिभाषित करता है कि प्राथमिक नोड के पीछे द्वितीयक नोड कितनी दूर है। एक इष्टतम स्थिति के लिए आवश्यक है कि अंतराल जितना संभव हो उतना मिनट हो। एक सामान्य ऑपरेटिंग सिस्टम पर, यह अंतराल 0 होने का अनुमान है। यदि अंतराल बहुत अधिक है तो द्वितीयक नोड को प्राथमिक में पदोन्नत करने के बाद डेटा अखंडता से समझौता किया जाएगा। इस मामले में आप एक थ्रेशोल्ड सेट कर सकते हैं, उदाहरण के लिए 1 मिनट, और यदि यह पार हो जाता है तो अलर्ट सेट किया जाता है। व्यापक प्रतिकृति अंतराल के सामान्य कारणों में शामिल हैं...
- शार्ड्स में अपर्याप्त लेखन क्षमता हो सकती है जो अक्सर संसाधनों की संतृप्ति से जुड़ी होती है।
- द्वितीयक नोड प्राथमिक नोड की तुलना में धीमी गति से डेटा प्रदान कर रहा है।
- नोड्स को किसी तरह से संचार करने से भी रोका जा सकता है, संभवत:खराब नेटवर्क के कारण।
- प्राथमिक नोड पर संचालन भी धीमा हो सकता है, जिससे प्रतिकृति अवरुद्ध हो सकती है। यदि ऐसा होता है तो आप निम्न आदेश चला सकते हैं:
- db.getProfilingLevel():यदि आपको 0 का मान मिलता है, तो आपके डीबी संचालन इष्टतम हैं।
यदि मान 1 है, तो यह धीमे संचालन से मेल खाता है, जिसके परिणामस्वरूप धीमी क्वेरी के कारण हो सकता है। - db.getProfilingStatus():इस मामले में हम धीमी गति के मूल्य की जांच करते हैं, डिफ़ॉल्ट रूप से यह 100ms है। यदि मान इससे बड़ा है, तो हो सकता है कि आप प्राथमिक या द्वितीयक पर अपर्याप्त संसाधनों पर भारी लेखन कार्य कर रहे हों। इसे हल करने के लिए, आप सेकेंडरी को स्केल कर सकते हैं ताकि उसके पास उतने ही संसाधन हों जितने कि प्राथमिक।
- db.getProfilingLevel():यदि आपको 0 का मान मिलता है, तो आपके डीबी संचालन इष्टतम हैं।
कर्सर
यदि आप उदाहरण के लिए पढ़ने का अनुरोध करते हैं, तो आपको एक कर्सर प्रदान किया जाएगा जो परिणाम के डेटा सेट का सूचक है। यदि आप इस कमांड को चलाते हैं db.serverStatus() और मेट्रिक्स ऑब्जेक्ट और फिर कर्सर पर नेविगेट करते हैं, तो आप इसे देखेंगे…

इस स्थिति में, कर्सर.टाइमऑट गुण को वृद्धिशील रूप से 9 तक अद्यतन किया गया था क्योंकि 9 कनेक्शन थे जो कर्सर को बंद किए बिना मर गए थे। परिणाम यह है कि यह सर्वर पर खुला रहेगा और इसलिए मेमोरी की खपत करेगा, जब तक कि इसे डिफ़ॉल्ट MongoDB सेटिंग द्वारा काटा नहीं जाता है। स्मृति को बचाने के लिए आपके लिए एक चेतावनी गैर-सक्रिय कर्सर की पहचान करना और उन्हें काटना चाहिए। आप गैर-टाइमआउट कर्सर से भी बच सकते हैं क्योंकि वे अक्सर संसाधनों पर पकड़ रखते हैं, जिससे आंतरिक सिस्टम प्रदर्शन धीमा हो जाता है। यह कर्सर.open.noTimeout प्रॉपर्टी के मान को 0 के मान पर सेट करके हासिल किया जा सकता है।
जर्नलिंग
WiredTiger स्टोरेज इंजन को ध्यान में रखते हुए, डेटा रिकॉर्ड करने से पहले, इसे पहले डिस्क फ़ाइलों में लिखा जाता है। इसे जर्नलिंग कहा जाता है। जर्नलिंग विफलता की स्थिति में डेटा की उपलब्धता और स्थायित्व सुनिश्चित करती है जिससे पुनर्प्राप्ति की जा सकती है।
पुनर्प्राप्ति के उद्देश्य के लिए, हम अक्सर अंतिम चेकपॉइंट से पुनर्प्राप्त करने के लिए चौकियों (विशेषकर WiredTiger भंडारण प्रणाली के लिए) का उपयोग करते हैं। हालांकि, अगर MongoDB अप्रत्याशित रूप से बंद हो जाता है, तो हम अंतिम चेकपॉइंट के बाद संसाधित या प्रदान किए गए किसी भी डेटा को पुनर्प्राप्त करने के लिए जर्नलिंग तकनीक का उपयोग करते हैं।
पहले मामले में जर्नलिंग को बंद नहीं किया जाना चाहिए, क्योंकि एक नया चेकपॉइंट बनाने में केवल 60 सेकंड लगते हैं। इसलिए यदि कोई विफलता होती है, तो MongoDB इन सेकंडों में खोए हुए डेटा को पुनर्प्राप्त करने के लिए जर्नल को फिर से चला सकता है।
जर्नलिंग आम तौर पर उस समय अंतराल को कम करता है जब डेटा को मेमोरी पर लागू किया जाता है जब तक कि यह डिस्क पर टिकाऊ न हो। स्टोरेज.जर्नल ऑब्जेक्ट में एक गुण होता है जो कमिटिंग फ़्रीक्वेंसी का वर्णन करता है, अर्थात, कमिटइंटरवलएम जो अक्सर वायर्ड टाइगर के लिए 100ms के मान पर सेट होता है। इसे कम मूल्य पर ट्यून करने से लिखने की लगातार रिकॉर्डिंग में वृद्धि होगी जिससे डेटा हानि की घटनाएं कम हो जाएंगी।
प्रदर्शन लॉक करना
यह कई क्लाइंट से कई पढ़ने और लिखने के अनुरोधों के कारण हो सकता है। जब ऐसा होता है तो निरंतरता बनाए रखने और लेखन संघर्षों से बचने की आवश्यकता होती है। इसे प्राप्त करने के लिए MongoDB मल्टी-ग्रैन्युलैरिटी-लॉकिंग का उपयोग करता है जो लॉकिंग ऑपरेशन को विभिन्न स्तरों, जैसे वैश्विक, डेटाबेस या संग्रह स्तर पर होने देता है।
यदि आपके पास खराब स्कीमा डिज़ाइन पैटर्न हैं, तो आप लंबे समय तक लॉक होने के लिए असुरक्षित होंगे। एक दूसरे को अवरुद्ध करने के परिणामस्वरूप, एक ही संग्रह में एक ही दस्तावेज़ में दो या दो से अधिक अलग-अलग लेखन संचालन करते समय अक्सर इसका अनुभव होता है। WiredTiger भंडारण इंजन के लिए हम टिकट प्रणाली का उपयोग कर सकते हैं जहां पढ़ने या लिखने के अनुरोध कतार या धागे जैसी किसी चीज से आते हैं।
डिफ़ॉल्ट रूप से पढ़ने और लिखने के संचालन की समवर्ती संख्या को पैरामीटर WiredTigerConcurrentWriteTransactions और WiredTigerConcurrentReadTransactions द्वारा परिभाषित किया गया है जो दोनों 128 के मान पर सेट हैं।
यदि आप इस मान को बहुत अधिक बढ़ाते हैं तो आप CPU संसाधनों द्वारा सीमित हो जाएंगे। थ्रूपुट संचालन को बढ़ाने के लिए, अधिक शार्प प्रदान करके क्षैतिज रूप से स्केल करने की सलाह दी जाएगी।
मोंगोडीबी डीबीए बनें - मोंगोडीबी को प्रोडक्शन में लाना सीखें कि मोंगोडीबी को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानने की जरूरत है मुफ्त में डाउनलोड करेंसंसाधनों का उपयोग
यह आम तौर पर उपलब्ध संसाधनों जैसे सीपीयू क्षमता/प्रसंस्करण दर और रैम के उपयोग का वर्णन करता है। प्रदर्शन, विशेष रूप से सीपीयू के लिए असामान्य यातायात भार के अनुसार काफी बदल सकता है। जांच करने के लिए चीजें शामिल हैं...
- कनेक्शन की संख्या
- भंडारण
- कैश
कनेक्शन की संख्या
यदि कनेक्शन की संख्या डेटाबेस सिस्टम की तुलना में अधिक है तो बहुत अधिक कतार होगी। नतीजतन, यह डेटाबेस के प्रदर्शन को प्रभावित करेगा और आपके सेटअप को धीरे-धीरे चलाएगा। इस नंबर के परिणामस्वरूप ड्राइवर को समस्या हो सकती है या आपके आवेदन में जटिलताएं भी हो सकती हैं।
यदि आप कुछ अवधि के लिए कनेक्शन की एक निश्चित संख्या की निगरानी करते हैं और फिर देखते हैं कि वह मान चरम पर है, तो कनेक्शन इस संख्या से अधिक होने पर अलर्ट सेट करना हमेशा एक अच्छा अभ्यास है।
यदि संख्या बहुत अधिक हो रही है तो आप इस वृद्धि को पूरा करने के लिए अपना पैमाना बढ़ा सकते हैं। ऐसा करने के लिए आपको एक निश्चित अवधि के भीतर उपलब्ध कनेक्शनों की संख्या जाननी होगी, अन्यथा, यदि उपलब्ध कनेक्शन पर्याप्त नहीं हैं, तो अनुरोधों को समय पर हैंडल नहीं किया जाएगा।
डिफ़ॉल्ट रूप से MongoDB 1 मिलियन कनेक्शन तक समर्थन प्रदान करता है। अपनी निगरानी के साथ, हमेशा सुनिश्चित करें कि वर्तमान कनेक्शन कभी भी इस मूल्य के बहुत करीब न हों। आप कनेक्शन ऑब्जेक्ट में मान की जांच कर सकते हैं।

संग्रहण
MongoDB में प्रत्येक पंक्ति और डेटा रिकॉर्ड को एक दस्तावेज़ के रूप में संदर्भित किया जाता है। दस्तावेज़ डेटा बीएसओएन प्रारूप में है। किसी दिए गए डेटाबेस पर, यदि आप db.stats() कमांड चलाते हैं, तो आपको यह डेटा प्रस्तुत किया जाएगा।
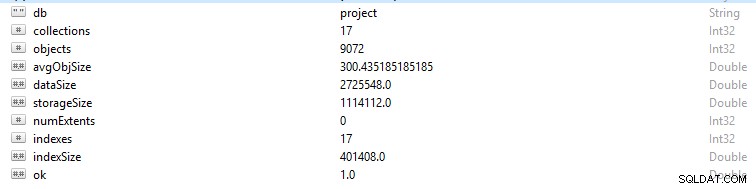
- StorageSize डेटाबेस में सभी डेटा विस्तार के आकार को परिभाषित करता है।
- IndexSize उस डेटाबेस में बनाए गए सभी इंडेक्स के आकार की रूपरेखा तैयार करता है।
- डेटासाइज़ डेटाबेस में दस्तावेज़ों द्वारा लिए गए कुल स्थान का माप है।
आप कभी-कभी स्मृति में बदलाव देख सकते हैं, खासकर यदि बहुत सारा डेटा हटा दिया गया हो। इस मामले में आपको यह सुनिश्चित करने के लिए अलर्ट सेट करना चाहिए कि यह दुर्भावनापूर्ण गतिविधि के कारण नहीं है।
कभी-कभी, डेटाबेस ट्रैफ़िक ग्राफ़ स्थिर होने पर समग्र संग्रहण आकार बढ़ सकता है और इस मामले में, यदि आवश्यक न हो तो डुप्लिकेट होने से बचने के लिए आपको अपने एप्लिकेशन या डेटाबेस संरचना की जांच करनी चाहिए।
कंप्यूटर की सामान्य मेमोरी की तरह, MongoDB में भी कैश होता है जिसमें सक्रिय डेटा अस्थायी रूप से संग्रहीत होता है। हालांकि, एक ऑपरेशन डेटा के लिए अनुरोध कर सकता है जो इस सक्रिय मेमोरी में नहीं है, इसलिए मुख्य डिस्क स्टोरेज से अनुरोध कर रहा है। इस अनुरोध या स्थिति को पृष्ठ दोष कहा जाता है। पृष्ठ दोष अनुरोध निष्पादित करने में अधिक समय लेने की सीमा के साथ आते हैं, और जब वे बार-बार होते हैं तो हानिकारक हो सकते हैं। इस परिदृश्य से बचने के लिए, सुनिश्चित करें कि आपके RAM का आकार हमेशा आपके द्वारा काम कर रहे डेटा सेट को पूरा करने के लिए पर्याप्त है। आपको यह भी सुनिश्चित करना चाहिए कि आपके पास कोई स्कीमा अतिरेक या अनावश्यक सूचकांक नहीं है।
कैश
कैश अक्सर एक्सेस किए गए डेटा के लिए एक अस्थायी डेटा संग्रहण आइटम है। WiredTiger में फाइल सिस्टम कैशे और स्टोरेज इंजन कैश को अक्सर नियोजित किया जाता है। हमेशा सुनिश्चित करें कि आपका काम करने वाला सेट उपलब्ध कैश से आगे नहीं बढ़ता है, अन्यथा, कुछ प्रदर्शन समस्याओं के कारण पृष्ठ दोष संख्या में वृद्धि होगी।
कुछ बिंदु पर आप अपने लगातार संचालन को संशोधित करने का निर्णय ले सकते हैं, लेकिन कभी-कभी परिवर्तन कैश में परिलक्षित नहीं होते हैं। इस असंशोधित डेटा को "डर्टी डेटा" कहा जाता है। यह मौजूद है क्योंकि इसे अभी तक डिस्क पर फ़्लश नहीं किया गया है। यदि "डर्टी डेटा" की मात्रा डिस्क पर धीमी गति से लिखने से परिभाषित कुछ औसत मान तक बढ़ जाती है, तो अड़चनें आएंगी। अधिक शार्क जोड़ने से इस संख्या को कम करने में मदद मिलेगी।
CPU उपयोग
अनुचित अनुक्रमण, खराब स्कीमा संरचना और अमित्र रूप से डिज़ाइन किए गए प्रश्नों के लिए अधिक CPU ध्यान देने की आवश्यकता होगी इसलिए स्पष्ट रूप से इसके उपयोग में वृद्धि होगी।
थ्रूपुट संचालन
काफी हद तक इन ऑपरेशनों के बारे में पर्याप्त जानकारी प्राप्त करने से कोई भी परिणामी असफलताओं जैसे त्रुटियों, संसाधनों की संतृप्ति और कार्यात्मक जटिलताओं से बचने में सक्षम हो सकता है।
आपको हमेशा डेटाबेस में पढ़ने और लिखने के संचालन की संख्या पर ध्यान देना चाहिए, यानी क्लस्टर की गतिविधियों का एक उच्च-स्तरीय दृश्य। अनुरोधों के लिए उत्पन्न संचालन की संख्या जानने से आप उस भार की गणना करने में सक्षम होंगे जिसे डेटाबेस से संभालने की उम्मीद है। तब लोड को या तो आपके डेटाबेस को स्केलिंग या स्केलिंग आउट किया जा सकता है; आपके पास मौजूद संसाधनों के प्रकार पर निर्भर करता है। यह आपको भागफल अनुपात को आसानी से मापने की अनुमति देता है जिसमें अनुरोध उस दर पर जमा हो रहे हैं जिस पर उन्हें संसाधित किया जा रहा है। इसके अलावा, आप प्रदर्शन को बेहतर बनाने के लिए अपने प्रश्नों को उचित रूप से अनुकूलित कर सकते हैं।
पढ़ने और लिखने के संचालन की संख्या की जाँच करने के लिए, इस कमांड को चलाएँ db.serverStatus(), फिर locks.global ऑब्जेक्ट पर नेविगेट करें, गुण r के लिए मान पढ़ने के अनुरोधों की संख्या और w लिखने की संख्या का प्रतिनिधित्व करता है। 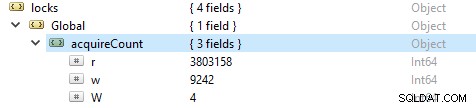
अधिक बार रीड ऑपरेशंस राइट ऑपरेशंस से अधिक होते हैं। ग्लोबल लॉक के तहत सक्रिय क्लाइंट मेट्रिक्स की रिपोर्ट की जाती है।
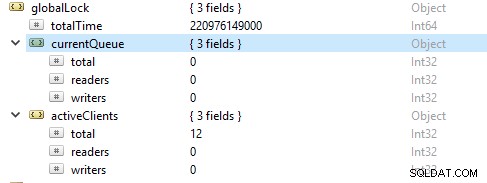
संसाधनों की संतृप्ति और सीमा
कभी-कभी डेटाबेस लिखने और पढ़ने की दर के साथ तालमेल बिठाने में विफल हो सकता है, जैसा कि कतारबद्ध अनुरोधों की बढ़ती संख्या द्वारा दर्शाया गया है। इस मामले में, आपको मोंगोडीबी को अनुरोधों को तेजी से पूरा करने में सक्षम करने के लिए और अधिक शार्क प्रदान करके अपने डेटाबेस को बढ़ाना होगा।
उभरते झटके
MongoDB लॉग फ़ाइलें हमेशा दिए गए मुखर अपवादों पर एक सामान्य अवलोकन देती हैं। यह परिणाम आपको त्रुटियों के संभावित कारणों के बारे में एक सुराग देगा। यदि आप कमांड चलाते हैं, db.serverStatus(), कुछ त्रुटि अलर्ट जो आप नोट करेंगे उनमें शामिल हैं:

- नियमित अभिकथन:ये एक ऑपरेशन विफलता के परिणामस्वरूप होते हैं। उदाहरण के लिए एक स्कीमा में यदि एक पूर्णांक फ़ील्ड को एक स्ट्रिंग मान प्रदान किया जाता है जिसके परिणामस्वरूप बीएसओएन दस्तावेज़ पढ़ने में विफलता होती है।
- चेतावनी का दावा:ये अक्सर किसी न किसी मुद्दे पर अलर्ट होते हैं लेकिन इसके संचालन पर अधिक प्रभाव नहीं डालते हैं। उदाहरण के लिए जब आप अपने MongoDB को अपग्रेड करते हैं तो आपको बहिष्कृत कार्यों का उपयोग करके सतर्क किया जा सकता है।
- संदेश दावा करता है:वे आंतरिक सर्वर अपवादों के परिणामस्वरूप होते हैं जैसे धीमा नेटवर्क या यदि सर्वर सक्रिय नहीं है।
- उपयोगकर्ता का दावा:नियमित अभिकथनों की तरह, ये त्रुटियां कमांड निष्पादित करते समय उत्पन्न होती हैं लेकिन वे अक्सर क्लाइंट को वापस कर दी जाती हैं। उदाहरण के लिए यदि डुप्लिकेट कुंजियाँ हैं, अपर्याप्त डिस्क स्थान या डेटाबेस में लिखने के लिए कोई पहुँच नहीं है। आप इन त्रुटियों को ठीक करने के लिए अपने आवेदन की जांच करने का विकल्प चुनेंगे।



