इंडेक्सिंग क्या है?
डेटाबेस की दुनिया में अनुक्रमण एक महत्वपूर्ण अवधारणा है। किसी भी क्षेत्र में सूचकांक बनाने का मुख्य लाभ डेटा की तेज पहुंच है। यह डेटाबेस खोज और एक्सेस करने की प्रक्रिया को अनुकूलित करता है। इसे समझने के लिए इस उदाहरण पर विचार करें।
जब कोई उपयोगकर्ता डेटाबेस से एक विशिष्ट पंक्ति के लिए पूछता है, तो डीबी सिस्टम क्या करेगा? यह पहली पंक्ति से शुरू होगा और जांच करेगा कि क्या यह वह पंक्ति है जो उपयोगकर्ता चाहता है? यदि हाँ, तो उस पंक्ति को वापस कर दें, अन्यथा पंक्ति को अंत तक खोजना जारी रखें।
आम तौर पर, जब आप किसी विशेष फ़ील्ड पर एक इंडेक्स को परिभाषित करते हैं, तो डीबी सिस्टम उस फ़ील्ड के मूल्य की एक ऑर्डर की गई सूची तैयार करेगा और इसे एक अलग तालिका में संग्रहीत करेगा। इस तालिका की प्रत्येक प्रविष्टि मूल तालिका में संबंधित मानों को इंगित करेगी। इसलिए जब उपयोगकर्ता किसी भी पंक्ति को खोजने का प्रयास करता है, तो वह पहले बाइनरी सर्च एल्गोरिथम का उपयोग करके इंडेक्स टेबल में मान की खोज करेगा और मूल तालिका से संबंधित मान लौटाएगा। इस प्रक्रिया में कम समय लगेगा क्योंकि हम रैखिक खोज के बजाय बाइनरी खोज का उपयोग कर रहे हैं।
इस लेख में, हम MongoDB अनुक्रमण पर ध्यान केंद्रित करेंगे और समझेंगे कि MongoDB में अनुक्रमणिका कैसे बनाएं और उपयोग करें।
MongoDB संग्रह में अनुक्रमणिका कैसे बनाएं?
Mongo शेल का उपयोग करके अनुक्रमणिका बनाने के लिए, आप इस सिंटैक्स का उपयोग कर सकते हैं:
db.collection.createIndex( <key and index type specification>, <options> )उदाहरण:
myColl संग्रह में नाम फ़ील्ड पर अनुक्रमणिका बनाने के लिए:
db.myColl.createIndex( { name: -1 } )MongoDB इंडेक्स के प्रकार
-
डिफ़ॉल्ट _id अनुक्रमणिका
जब आप एक नया संग्रह बनाते हैं तो यह डिफ़ॉल्ट अनुक्रमणिका है जो MongoDB द्वारा बनाई जाएगी। यदि आप इस फ़ील्ड के लिए कोई मान निर्दिष्ट नहीं करते हैं, तो _id आपके संग्रह के लिए डिफ़ॉल्ट रूप से प्राथमिक कुंजी होगी ताकि उपयोगकर्ता समान _id फ़ील्ड मानों वाले दो दस्तावेज़ सम्मिलित न कर सके। आप इस अनुक्रमणिका को _id फ़ील्ड से नहीं निकाल सकते।
-
एकल फ़ील्ड इंडेक्स
जब आप _id फ़ील्ड के अलावा किसी अन्य फ़ील्ड पर एक नई अनुक्रमणिका बनाना चाहते हैं तो आप इस अनुक्रमणिका प्रकार का उपयोग कर सकते हैं।
उदाहरण:
db.myColl.createIndex( { name: 1 } )यह myColl संग्रह में नाम फ़ील्ड पर एकल कुंजी आरोही अनुक्रमणिका बनाएगा
-
यौगिक अनुक्रमणिका
आप कंपाउंड इंडेक्स का उपयोग करके कई फ़ील्ड पर एक इंडेक्स भी बना सकते हैं। इस सूचकांक के लिए, उन क्षेत्रों का क्रम जिनमें उन्हें सूचकांक में परिभाषित किया गया है, मायने रखता है। इस उदाहरण पर विचार करें:
db.myColl.createIndex({ name: 1, score: -1 })यह अनुक्रमणिका पहले संग्रह को आरोही क्रम में नाम से क्रमबद्ध करेगी और फिर प्रत्येक नाम मान के लिए, यह अवरोही क्रम में स्कोर मानों के आधार पर क्रमबद्ध करेगी।
-
मल्टीकी इंडेक्स
इस सूचकांक का उपयोग सरणी डेटा को अनुक्रमित करने के लिए किया जा सकता है। यदि किसी संग्रह में किसी भी फ़ील्ड में इसके मान के रूप में एक सरणी है तो आप इस अनुक्रमणिका का उपयोग कर सकते हैं जो सरणी में प्रत्येक तत्व के लिए अलग अनुक्रमणिका प्रविष्टियां बनाएगी। यदि अनुक्रमित फ़ील्ड एक सरणी है, तो MongoDB स्वचालित रूप से उस पर बहु-कुंजी अनुक्रमणिका बनाएगा।
इस उदाहरण पर विचार करें:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }आप Mongo शेल में यह आदेश जारी करके addr फ़ील्ड पर एक बहु-कुंजी अनुक्रमणिका बना सकते हैं।
db.myColl.createIndex({ addr.zip: 1 }) -
भू-स्थानिक सूचकांक
मान लीजिए आपने कुछ निर्देशांक MongoDB संग्रह में संग्रहीत किए हैं। इस प्रकार के क्षेत्रों (जिसमें भू-स्थानिक डेटा है) पर अनुक्रमणिका बनाने के लिए, आप भू-स्थानिक अनुक्रमणिका का उपयोग कर सकते हैं। MongoDB दो प्रकार के भू-स्थानिक अनुक्रमणिका का समर्थन करता है।
-
2d अनुक्रमणिका:आप इस अनुक्रमणिका का उपयोग डेटा के लिए कर सकते हैं जिसे 2D समतल पर बिंदुओं के रूप में संग्रहीत किया जाता है।
db.collection.createIndex( { <location field> : "2d" } ) -
2dsphere अनुक्रमणिका:इस अनुक्रमणिका का उपयोग तब करें जब आपका डेटा GeoJson प्रारूप या निर्देशांक जोड़े (देशांतर, अक्षांश) के रूप में संग्रहीत हो
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
टेक्स्ट इंडेक्स
उन प्रश्नों का समर्थन करने के लिए जिनमें संग्रह में कुछ टेक्स्ट खोजना शामिल है, आप टेक्स्ट इंडेक्स का उपयोग कर सकते हैं।
उदाहरण:
db.myColl.createIndex( { address: "text" } ) -
हैश इंडेक्स
MongoDB हैश-आधारित शार्किंग का समर्थन करता है। हैशेड इंडेक्स इंडेक्स किए गए फ़ील्ड के मानों के हैश की गणना करता है। हैशेड इंडेक्स हैशेड शार्प कीज़ का उपयोग करके शार्किंग का समर्थन करता है। हैशेड शार्डिंग आपके क्लस्टर में डेटा को विभाजित करने के लिए इस इंडेक्स को शार्ड कुंजी के रूप में उपयोग करती है।
उदाहरण:
db.myColl.createIndex( { _id: "hashed" } )
-
अद्वितीय अनुक्रमणिका
यह गुण सुनिश्चित करता है कि अनुक्रमित फ़ील्ड में कोई डुप्लिकेट मान नहीं हैं। यदि अनुक्रमणिका बनाते समय कोई डुप्लिकेट मिलता है, तो वह उन प्रविष्टियों को त्याग देगा।
-
विरल अनुक्रमणिका
यह गुण सुनिश्चित करता है कि सभी क्वेरी अनुक्रमित फ़ील्ड के साथ दस्तावेज़ खोजें। यदि किसी दस्तावेज़ में अनुक्रमित फ़ील्ड नहीं है, तो उसे परिणाम सेट से हटा दिया जाएगा।
-
TTL अनुक्रमणिका
इस अनुक्रमणिका का उपयोग विशिष्ट समय अंतराल (TTL) के बाद संग्रह से दस्तावेज़ों को स्वचालित रूप से हटाने के लिए किया जाता है। यह इवेंट लॉग या उपयोगकर्ता सत्रों के दस्तावेज़ों को हटाने के लिए आदर्श है।
प्रदर्शन विश्लेषण
छात्र अंकों के संग्रह पर विचार करें। इसमें ठीक 3000000 दस्तावेज हैं। हमने इस संग्रह में कोई अनुक्रमणिका नहीं बनाई है। स्कीमा को समझने के लिए नीचे इस चित्र को देखें।
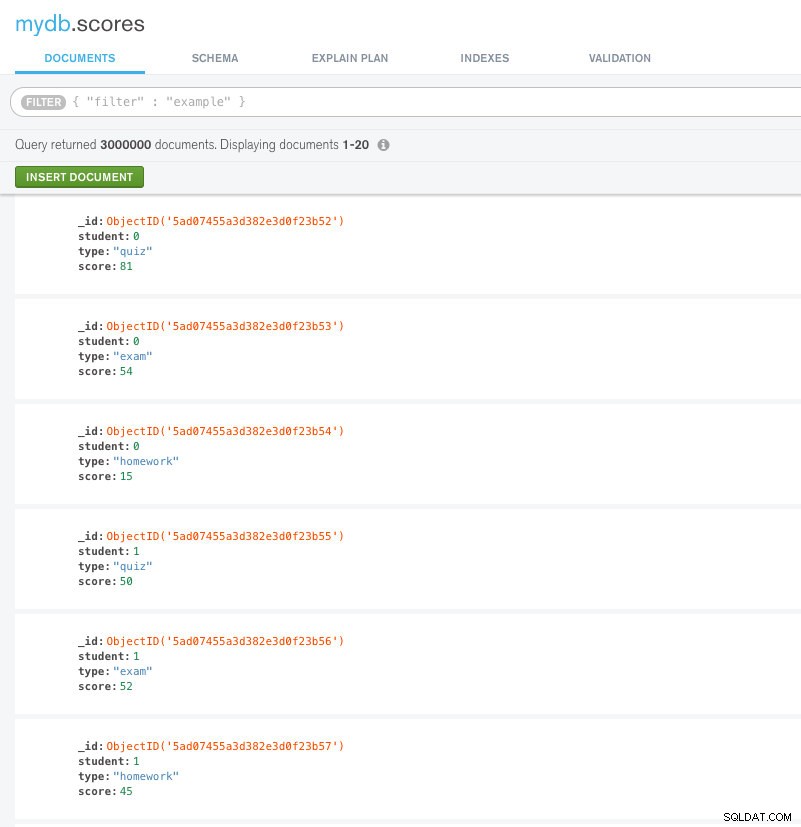 स्कोर संग्रह में नमूना दस्तावेज़
स्कोर संग्रह में नमूना दस्तावेज़ अब, बिना किसी अनुक्रमणिका के इस प्रश्न पर विचार करें:
db.scores.find({ student: 585534 }).explain("executionStats")इस क्वेरी को निष्पादित करने में 1155ms लगते हैं। यहाँ आउटपुट है। परिणाम के लिए निष्पादन टाइममिलिस फ़ील्ड खोजें।
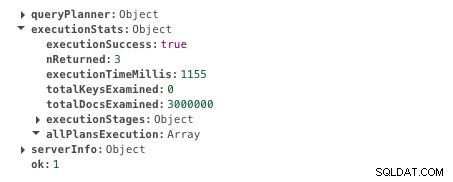 बिना अनुक्रमण के निष्पादन समय
बिना अनुक्रमण के निष्पादन समय अब स्टूडेंट फील्ड पर इंडेक्स बनाते हैं। अनुक्रमणिका बनाने के लिए इस क्वेरी को चलाएँ।
db.scores.createIndex({ student: 1 })अब वही क्वेरी 0ms लेती है।
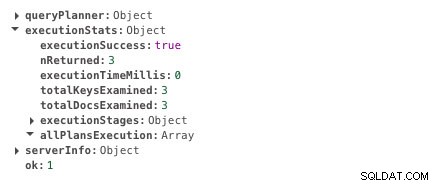 अनुक्रमण के साथ निष्पादन समय
अनुक्रमण के साथ निष्पादन समय आप निष्पादन समय में अंतर स्पष्ट रूप से देख सकते हैं। यह लगभग तात्कालिक है। यही अनुक्रमण की शक्ति है।
निष्कर्ष
एक स्पष्ट टेकअवे है:इंडेक्स बनाएं। अपने प्रश्नों के आधार पर, आप अपने संग्रह पर विभिन्न प्रकार के अनुक्रमित परिभाषित कर सकते हैं। यदि आप अनुक्रमणिका नहीं बनाते हैं, तो प्रत्येक क्वेरी पूरे संग्रह को स्कैन करेगी जिसमें बहुत समय लगता है जिससे आपका एप्लिकेशन बहुत धीमा हो जाता है और यह आपके सर्वर के बहुत सारे संसाधनों का उपयोग करता है। दूसरी ओर, बहुत अधिक इंडेक्स न बनाएं क्योंकि अनावश्यक इंडेक्स बनाने से सभी इंसर्ट, डिलीट और अपडेट के लिए अतिरिक्त समय ओवरहेड होगा। जब आप अनुक्रमित फ़ील्ड पर इनमें से कोई भी ऑपरेशन करते हैं, तो आपको इंडेक्स ट्री पर भी वही ऑपरेशन करना होता है जिसमें समय लगता है। अनुक्रमणिका को RAM में संग्रहीत किया जाता है ताकि अप्रासंगिक अनुक्रमणिकाएँ बनाने से आपका RAM स्थान समाप्त हो जाए, और आपका सर्वर धीमा हो जाए।



