PostgreSQL एक अद्भुत परियोजना है और यह एक अद्भुत दर से विकसित होती है। हम ब्लॉग पोस्ट की एक श्रृंखला के साथ PostgreSQL में इसके सभी संस्करणों में दोष सहिष्णुता क्षमताओं के विकास पर ध्यान केंद्रित करेंगे। यह श्रृंखला की तीसरी पोस्ट है और हम समयरेखा के मुद्दों और पोस्टग्रेएसक्यूएल की गलती सहनशीलता और निर्भरता पर उनके प्रभावों के बारे में बात करेंगे।
यदि आप शुरुआत से ही विकास की प्रगति देखना चाहते हैं, तो कृपया श्रृंखला के पहले दो ब्लॉग पोस्ट देखें:
- PostgreSQL में दोष सहनशीलता का विकास
- PostgreSQL में दोष सहनशीलता का विकास:प्रतिकृति चरण

समयसीमा
पिछले समय में डेटाबेस को पुनर्स्थापित करने की क्षमता कुछ जटिलताएं पैदा करती है जिन्हें हम विफलता समझाकर कुछ मामलों को कवर करेंगे। (चित्र 1), स्विचओवर (चित्र 2) और pg_rewind (चित्र 3) इस विषय में बाद में मामले।
उदाहरण के लिए, डेटाबेस के मूल इतिहास में, मान लीजिए कि आपने मंगलवार शाम 5:15 बजे एक महत्वपूर्ण तालिका गिरा दी, लेकिन बुधवार दोपहर तक अपनी गलती का एहसास नहीं हुआ। अचंभित, आप अपना बैकअप प्राप्त करते हैं, मंगलवार शाम 5:14 बजे पॉइंट-इन-टाइम पर पुनर्स्थापित करते हैं, और ऊपर और चल रहे हैं। डेटाबेस ब्रह्मांड के इस इतिहास में, आपने तालिका को कभी नहीं छोड़ा। लेकिन मान लीजिए कि आपको बाद में एहसास हुआ कि यह इतना अच्छा विचार नहीं था, और मूल इतिहास में बुधवार की सुबह किसी समय वापस आना चाहेंगे। यदि आपका डेटाबेस अप-एंड-रनिंग के दौरान, यह कुछ WAL सेगमेंट फ़ाइलों को अधिलेखित कर देता है, जो उस समय तक ले जाती हैं, जब आप चाहते हैं कि आप वापस आ सकें।
इस प्रकार, इससे बचने के लिए, आपको पॉइंट-इन-टाइम पुनर्प्राप्ति करने के बाद जेनरेट किए गए WAL रिकॉर्ड की श्रृंखला को मूल डेटाबेस इतिहास में जेनरेट किए गए रिकॉर्ड से अलग करना होगा।
इस समस्या से निपटने के लिए, PostgreSQL के पास समयसीमा की धारणा है। जब भी कोई संग्रह पुनर्प्राप्ति पूर्ण हो जाती है, तो उस पुनर्प्राप्ति के बाद उत्पन्न WAL रिकॉर्ड की श्रृंखला की पहचान करने के लिए एक नई समयरेखा बनाई जाती है। टाइमलाइन आईडी नंबर वाल सेगमेंट फ़ाइल नामों का हिस्सा है, इसलिए एक नई टाइमलाइन पिछली टाइमलाइन द्वारा उत्पन्न वाल डेटा को ओवरराइट नहीं करती है। वास्तव में कई अलग-अलग समय-सारिणी संग्रहित करना संभव है।
उस स्थिति पर विचार करें जहां आप पूरी तरह से सुनिश्चित नहीं हैं कि किस समय-समय पर पुनर्प्राप्त करना है, और इसलिए परीक्षण और त्रुटि द्वारा कई पॉइंट-इन-टाइम पुनर्प्राप्ति करना है जब तक कि आप पुराने इतिहास से शाखा लगाने के लिए सबसे अच्छी जगह नहीं पाते। समयसीमा के बिना यह प्रक्रिया जल्द ही एक असहनीय गड़बड़ी उत्पन्न करेगी। समयसीमा के साथ, आप किसी भी पूर्व स्थिति में वापस आ सकते हैं, जिसमें समयरेखा शाखाओं में राज्य शामिल हैं जिन्हें आपने पहले छोड़ दिया था।
हर बार एक नई टाइमलाइन बनाई जाती है, PostgreSQL एक "टाइमलाइन हिस्ट्री" फाइल बनाता है जो दिखाता है कि यह किस टाइमलाइन से और कब से ब्रांच किया गया है। ये इतिहास फ़ाइलें एक संग्रह से पुनर्प्राप्त करते समय सिस्टम को सही WAL खंड फ़ाइलों को चुनने की अनुमति देने के लिए आवश्यक हैं जिसमें कई समयरेखा शामिल हैं। इसलिए, उन्हें WAL खंड फ़ाइलों की तरह ही WAL संग्रह क्षेत्र में संग्रहीत किया जाता है। इतिहास फ़ाइलें केवल छोटी पाठ फ़ाइलें होती हैं, इसलिए उन्हें अनिश्चित काल के लिए रखना सस्ता और उपयुक्त है (खंड फ़ाइलों के विपरीत जो बड़ी हैं)। यदि आप चाहें, तो इस विशेष समयरेखा को कैसे और क्यों बनाया गया, इस बारे में अपने नोट्स रिकॉर्ड करने के लिए इतिहास फ़ाइल में टिप्पणियां जोड़ सकते हैं। इस तरह की टिप्पणियां विशेष रूप से तब मूल्यवान होंगी जब आपके पास प्रयोग के परिणामस्वरूप अलग-अलग समयसीमाएं हों।
पुनर्प्राप्ति का डिफ़ॉल्ट व्यवहार उसी समयरेखा के साथ पुनर्प्राप्त करना है जो आधार बैकअप लेते समय वर्तमान था। यदि आप कुछ चाइल्ड टाइमलाइन में पुनर्प्राप्त करना चाहते हैं (अर्थात, आप किसी ऐसी स्थिति में वापस लौटना चाहते हैं जो पुनर्प्राप्ति प्रयास के बाद स्वयं उत्पन्न हुई थी), तो आपको पुनर्प्राप्ति में लक्ष्य टाइमलाइन आईडी निर्दिष्ट करने की आवश्यकता है। आप उन समय-सारिणी में वापस नहीं आ सकते हैं जो आधार बैकअप से पहले बंद हो गई हैं।
PostgreSQL में टाइमलाइन अवधारणा को सरल बनाने के लिए, विफलता . के मामले में टाइमलाइन संबंधी समस्याएं , स्विचओवर और pg_rewind चित्र 1, Fig.2 और Fig.3 के साथ संक्षेप और समझाया गया है।
विफलता परिदृश्य:
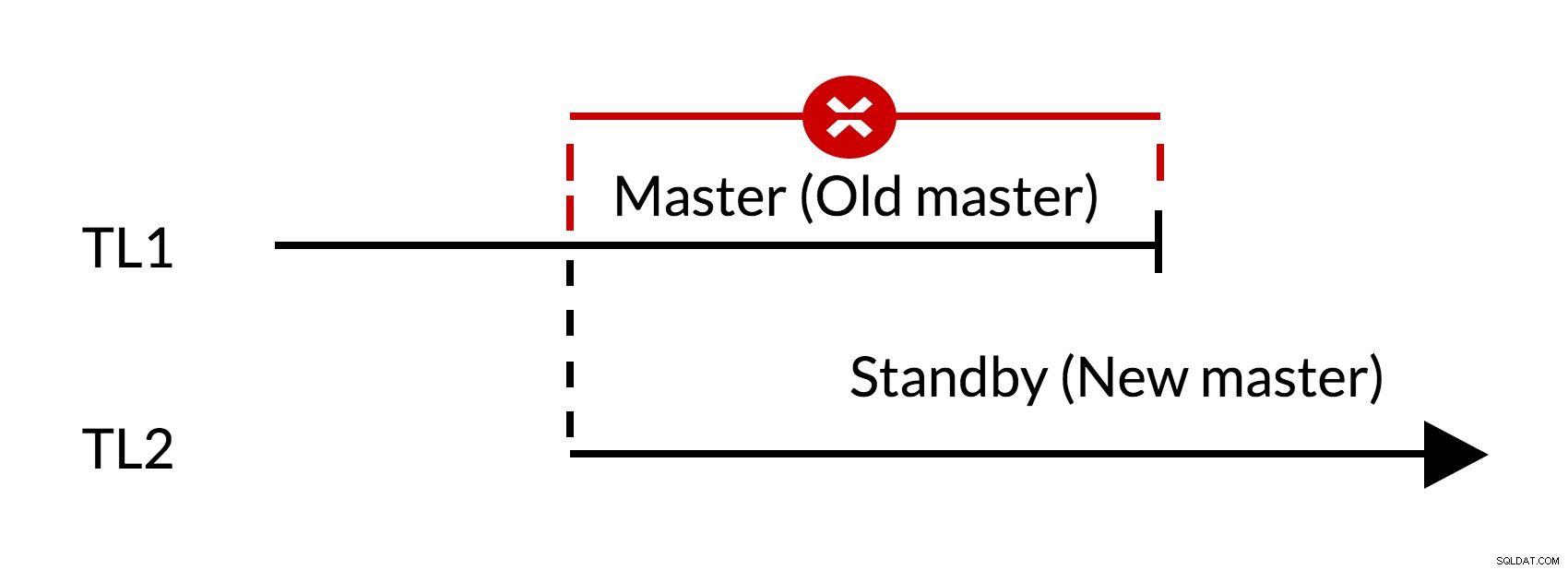
Fig.1 फ़ेलओवर
- पुराने मास्टर (TL1) में बकाया परिवर्तन हैं
- समय में वृद्धि परिवर्तनों के नए इतिहास (TL2) का प्रतिनिधित्व करती है
- पुरानी टाइमलाइन के बदलावों को नई टाइमलाइन पर स्विच करने वाले सर्वर पर दोबारा नहीं चलाया जा सकता
- पुराना गुरु नए गुरु का अनुसरण नहीं कर सकता
स्विचओवर परिदृश्य:
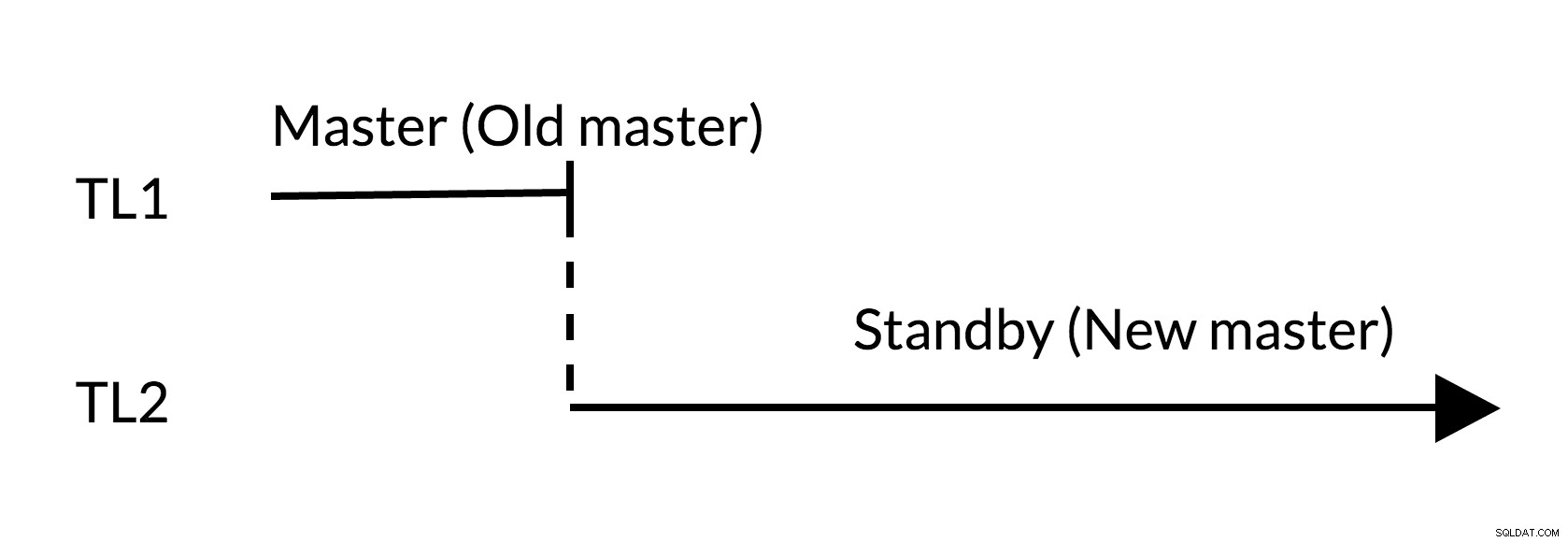 Fig.2 स्विचओवर
Fig.2 स्विचओवर
- पुराने मास्टर (TL1) में कोई उल्लेखनीय परिवर्तन नहीं हैं
- समय में वृद्धि परिवर्तनों के नए इतिहास (TL2) का प्रतिनिधित्व करती है
- पुराना मास्टर नए मास्टर के लिए स्टैंडबाय बन सकता है
pg_rewind परिदृश्य:
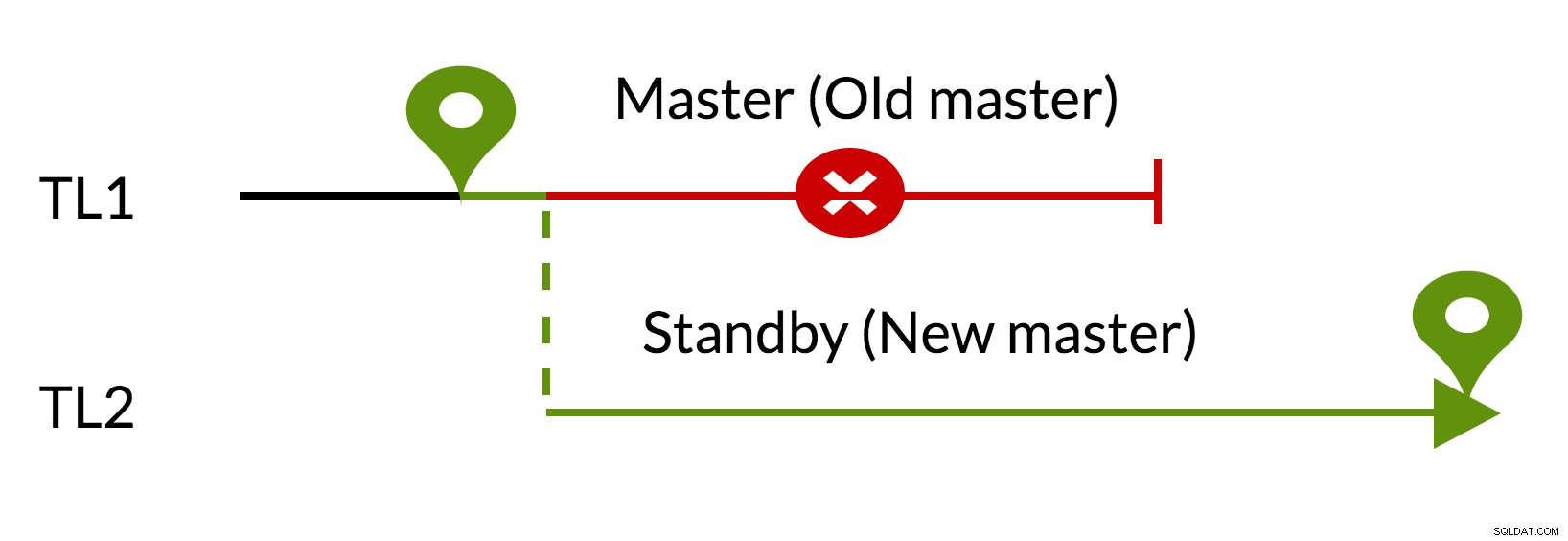 Fig.3 pg_rewind
Fig.3 pg_rewind
- नए मास्टर (TL1) के डेटा का उपयोग करके बकाया परिवर्तन हटा दिए जाते हैं
- पुराना मास्टर नए मास्टर (TL2) का अनुसरण कर सकता है
pg_rewind
pg_rewind एक PostgreSQL क्लस्टर को उसी क्लस्टर की दूसरी कॉपी के साथ सिंक्रोनाइज़ करने का एक उपकरण है, जब क्लस्टर की समय-सीमा अलग हो जाती है। एक सामान्य परिदृश्य एक पुराने मास्टर सर्वर को विफलता के बाद ऑनलाइन वापस लाना है, एक स्टैंडबाय के रूप में जो नए मास्टर का अनुसरण करता है।
परिणाम लक्ष्य डेटा निर्देशिका को स्रोत एक के साथ बदलने के बराबर है। कॉन्फ़िगरेशन फ़ाइलों सहित सभी फ़ाइलों की प्रतिलिपि बनाई गई है। नया आधार बैकअप, या rsync जैसे उपकरण लेने पर pg_rewind का लाभ यह है कि pg_rewind को क्लस्टर में सभी अपरिवर्तित फ़ाइलों के माध्यम से पढ़ने की आवश्यकता नहीं है। यह बहुत तेज़ बनाता है जब डेटाबेस बड़ा होता है और इसका केवल एक छोटा सा हिस्सा क्लस्टर के बीच भिन्न होता है।
यह कैसे काम करता है?
मूल विचार नए क्लस्टर से पुराने क्लस्टर में सब कुछ कॉपी करना है, केवल उन ब्लॉकों को छोड़कर जिन्हें हम समान जानते हैं।
- पुराने क्लस्टर के WAL लॉग को स्कैन करें, अंतिम चेकपॉइंट से उस बिंदु से पहले शुरू करें जहां नए क्लस्टर का टाइमलाइन इतिहास पुराने क्लस्टर से अलग हो गया था। प्रत्येक WAL रिकॉर्ड के लिए, स्पर्श किए गए डेटा ब्लॉकों को नोट करें। यह उन सभी डेटा ब्लॉकों की एक सूची देता है, जो नए क्लस्टर के बंद होने के बाद पुराने क्लस्टर में बदले गए थे।
- नए क्लस्टर से उन सभी बदले गए ब्लॉक को पुराने क्लस्टर में कॉपी करें।
- नए क्लस्टर से पुराने क्लस्टर में क्लॉग और कॉन्फ़िगरेशन फ़ाइलों जैसी अन्य सभी फ़ाइलों की प्रतिलिपि बनाएँ, संबंध फ़ाइलों को छोड़कर सब कुछ।
- नए क्लस्टर से WAL लागू करें, फेलओवर पर बनाए गए चेकपॉइंट से शुरू करें। (सख्ती से बोलते हुए, pg_rewind WAL को लागू नहीं करता है, यह सिर्फ एक बैकअप लेबल फ़ाइल बनाता है जो दर्शाता है कि जब PostgreSQL शुरू होता है, तो यह उस चेकपॉइंट से फिर से खेलना शुरू कर देगा और सभी आवश्यक WAL लागू करेगा।)
नोट: काम करने में सक्षम होने के लिए pg_rewind के लिए wal_log_hints को postgresql.conf में सेट किया जाना चाहिए। यह पैरामीटर केवल सर्वर प्रारंभ पर सेट किया जा सकता है। डिफ़ॉल्ट मान बंद है ।
निष्कर्ष
इस ब्लॉग पोस्ट में, हमने पोस्टग्रेज़ में समय-सीमा पर चर्चा की और हम फ़ेलओवर और स्विचओवर मामलों को कैसे संभालते हैं। हमने इस बारे में भी बात की कि pg_rewind कैसे काम करता है और पोस्टग्रेज फॉल्ट टॉलरेंस और निर्भरता के लिए इसके लाभ। हम अगले ब्लॉग पोस्ट में सिंक्रोनस कमिटमेंट जारी रखेंगे।
संदर्भ
PostgreSQL दस्तावेज़ीकरण
PostgreSQL 9 व्यवस्थापन कुकबुक - दूसरा संस्करण
pg_rewind नॉर्डिक PGDay Heikki Linnakangas द्वारा प्रस्तुति