परिचय
इस लेख में, हम nvarchar . का उपयोग करने के बारे में बात करने जा रहे हैं डेटा प्रकार। हम यह पता लगाएंगे कि SQL सर्वर इस डेटा प्रकार को डिस्क पर कैसे संग्रहीत करता है और इसे RAM में कैसे संसाधित किया जाता है। हम यह भी जांचेंगे कि कैसे nvarchar का आकार प्रदर्शन को प्रभावित कर सकता है।
वास्तविक डेटा आकार:nchar बनाम nvarchar
हम nvarchar . का उपयोग करते हैं जब कॉलम डेटा प्रविष्टियों का आकार संभवतः काफी भिन्न होने वाला है। भंडारण आकार (बाइट्स में) दर्ज किए गए डेटा की वास्तविक लंबाई + 2 बाइट्स से दोगुना है। यह हमें nchar . के उपयोग की तुलना में डिस्क संग्रहण को सहेजने की अनुमति देता है डेटा प्रकार। आइए निम्नलिखित उदाहरण पर विचार करें। हम दो टेबल बना रहे हैं। एक तालिका में nvarchar कॉलम होता है, दूसरी तालिका में nchar कॉलम होते हैं। कॉलम का आकार 2000 वर्ण (4000 बाइट्स) है।
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
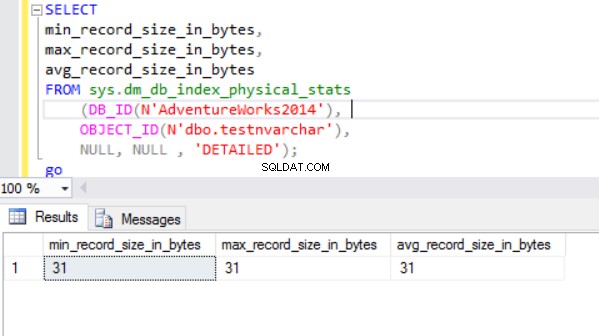
वास्तविक पंक्ति आकार है:
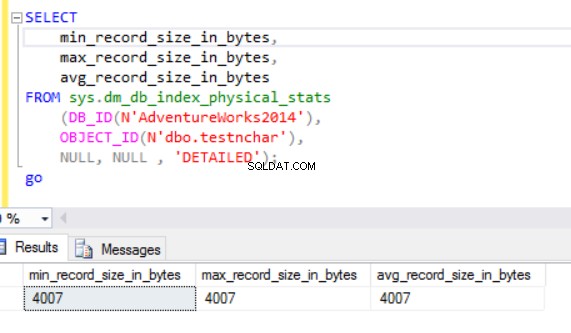
जैसा कि हम देख सकते हैं, nvarchar डेटाटाइप का वास्तविक पंक्ति आकार nchar डेटाटाइप से बहुत छोटा है। nchar डेटाटाइप के मामले में, हम 10 सिंबल कैरेक्टर स्ट्रिंग को स्टोर करने के लिए ~4000 बाइट्स का उपयोग करते हैं। हम nvarchar डेटाटाइप के मामले में समान वर्ण स्ट्रिंग को संग्रहीत करने के लिए ~20 बाइट्स का उपयोग करते हैं।
SQL सर्वर इंजन डेटा को RAM (बफर पूल) में प्रोसेस करता है। स्मृति में पंक्ति आकार के बारे में क्या?
वास्तविक डेटा आकार:HDD बनाम RAM
आइए निम्नलिखित क्वेरी निष्पादित करें:
SELECT col1 FROM dbo.testnchar;

फिक्स्ड-लेंथ कैरेक्टर स्ट्रिंग के मामले में डिस्क और रैम के उपयोग में कोई अंतर नहीं है।
SELECT col1 FROM dbo.testnvarchar;

हम देख सकते हैं कि SQL सर्वर इंजन ने घोषित पंक्ति आकार के केवल आधे (वास्तविक 20 बाइट्स के बजाय 2000 बाइट्स) और अतिरिक्त जानकारी के लिए कई बाइट्स के लिए मेमोरी का अनुरोध किया। एक तरफ से हम डिस्क स्थान का उपयोग कम करते हैं लेकिन दूसरी तरफ से हम अनुरोधित RAM को बढ़ा सकते हैं। यह अलग-अलग वर्ण डेटाटाइप के उपयोग का एक साइड इफेक्ट है। यह दुष्प्रभाव कुछ मामलों में संसाधनों पर भारी प्रभाव डाल सकता है।
FORMAT():RAM अनुरोधित बनाम RAM उपयोग की गई
हम FORMAT फ़ंक्शन का उपयोग करते हैं, जो निर्दिष्ट प्रारूप और वैकल्पिक संस्कृति के साथ एक स्वरूपित मान देता है। वापसी मूल्य nvarchar . है या शून्य। वापसी मूल्य की लंबाई प्रारूप . द्वारा निर्धारित की जाती है . FORMAT(getdate(), 'yyyyMMdd','en-US') का परिणाम '20170412' होगा। इस परिणाम को डिस्क पर कॉलम पर संग्रहीत करने के लिए हमें 16 बाइट्स की आवश्यकता है (परिणाम nvarchar(8) होगा)। विशेष डेटा के लिए RAM में डेटा का आकार क्या है?
आइए निम्नलिखित क्वेरी को निष्पादित करें। हम निम्नलिखित वातावरण का उपयोग करते हैं:
- AdventureWorks2014
- एमएस एसक्यूएल 2016 विकास संस्करण
- dbo.Customer (19'820'000 रिकॉर्ड) में Sales का डेटा होता है। Customer (19'820 रिकॉर्ड 1000 बार अपलोड किए जा चुके हैं)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
क्वेरी निष्पादन योजना काफी सरल है:

पहला ऑपरेशन dbo.Customer टेबल पर "क्लस्टर इंडेक्स स्कैन" है। ~19 000 000 रिकॉर्ड पढ़े जा चुके हैं। अनुमानित डेटा आकार 435 एमबी है।
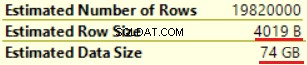
अगला ऑपरेशन "कंप्यूट स्केलर" (फॉर्मैट () फ़ंक्शन की गणना) है। परिणाम काफी अप्रत्याशित है क्योंकि हम 16 बाइट्स वर्ण स्ट्रिंग को प्रारूपित करते हैं। पंक्ति का आकार नाटकीय रूप से 23 बाइट्स से बढ़कर 4019 बाइट्स हो गया। अनुमानित डेटा आकार के साथ भी - 435 एमबी से 74 जीबी तक। हम देख सकते हैं कि FORMAT() NVARCHAR(4000) लौटाता है।
MS SQL Server 2016 में अत्यधिक मेमोरी ग्रांट दिखाने की बड़ी क्षमता है। हम पिछले ऑपरेशन में चेतावनी देख सकते हैं (T-SQL SELECT INTO):
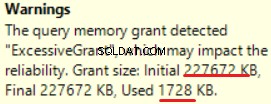
यह मेमोरी का "ओवर ग्रांटेड" है:दी गई मेमोरी के 90% से अधिक का उपयोग नहीं किया जाता है।
क्वेरी समय के आँकड़े हैं:
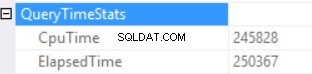
लंबा निष्पादन समय एक गैर-प्रभावी स्केलर फ़ंक्शन निष्पादन और अत्यधिक मेमोरी ग्रांट के बैक साइड इफेक्ट पर निर्भर करता है - हैश मैच (दायां बाहरी जुड़ाव)। हमें दो अलग-अलग कारणों का संचयी प्रभाव मिला है:एकाधिक स्केलर फ़ंक्शन निष्पादन और अत्यधिक स्मृति अनुदान।
SQL सर्वर इंजन प्रति क्वेरी अनुमत स्मृति का 25% से अधिक नहीं दे सकता है। हम संसाधन गवर्नर का उपयोग करके MS SQL सर्वर के एंटरप्राइज़ संस्करण में इस राशि को बदल सकते हैं। दी गई मेमोरी में दो भाग होते हैं:आवश्यक और अतिरिक्त। आंतरिक जरूरतों के लिए एक आवश्यक मेमोरी का उपयोग किया जाता है - सॉर्टिंग और हैश जॉइन ऑपरेशन के लिए। अतिरिक्त मेमोरी अनुमानित डेटा आकार पर आधारित है। यदि आवश्यक और अतिरिक्त स्मृति दोनों 25% की सीमा से अधिक है, तो SQL सर्वर इंजन उपलब्ध स्मृति का अन्य 25% देता है। विवरण के लिए SQL सर्वर मेमोरी ग्रांट पोस्ट पढ़ें।
आइए FORMAT() फ़ंक्शन के बिना उसी क्वेरी को निष्पादित करें।
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
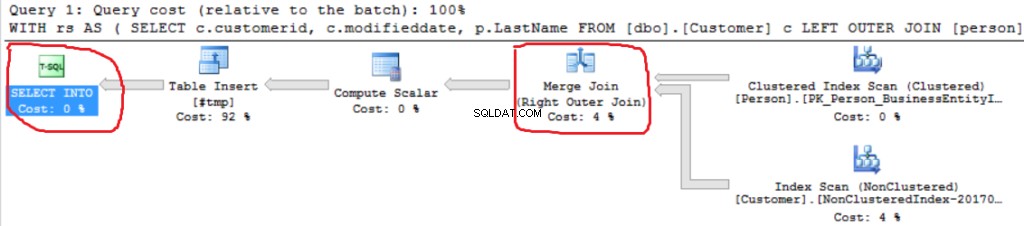
हम एक और राइट आउटर जॉइन इंप्लीमेंटेशन देख सकते हैं (हैश जॉइन के बजाय मर्ज जॉइन)।
मेमोरी ग्रांट की जानकारी है (यदि कोई सॉर्टिंग नहीं है और हैश जॉइन SQL सर्वर कोई मेमोरी नहीं दे सकता है):
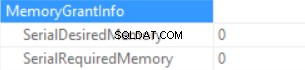
क्वेरी समय सांख्यिकी हैं (समय अनुमानित रूप से घटा है:कोई स्केलर फ़ंक्शन निष्पादन नहीं, अनुमानित डेटा आकार पिछले नमूने की तुलना में छोटा है):

इसलिए हम FORMAT () फ़ंक्शन का उपयोग करके "दी गई मेमोरी" को 222 एमबी तक बढ़ा रहे हैं (और इसके 2 एमबी से कम का उपयोग कर रहे हैं)। उदाहरण में डेटा वॉल्यूम छोटा है।
लंबे समय तक निष्पादन क्वेरी
उत्पादन परिवेश से वास्तविक SQL क्वेरी पर विचार करें। इस क्वेरी को बैच लोडिंग प्रक्रिया के दौरान निष्पादित किया गया है (क्लासिक ट्रांजैक्शनल परिदृश्य नहीं)। हम अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस, अमेज़ॅन रिलेशनल डेटाबेस सर्विस) पर शुरू किए गए एमएस एसक्यूएल सर्वर का उपयोग करते हैं। DB इंस्टेंस विशेषताएँ 160 GB RAM (~ 30 GB RAM प्रति क्वेरी से अधिक नहीं दी जा सकती हैं) और 40 vCPU हैं। SQL क्वेरी लगभग ऊपर के उदाहरण के समान थी (अंतर तालिकाओं और डेटा आकार की मात्रा में है):CTE में 6 तालिकाओं के बीच शामिल होना शामिल है। "मास्टर टेबल" (FROM क्लॉज में एक टेबल) में ~175'000'000 रिकॉर्ड होते हैं और डेटा का आकार 20GB होता है। लुकअप टेबल (जॉइन क्लॉज में राइट टेबल) छोटी हैं (मुख्य टेबल की तुलना में)। SQL क्वेरी में FORMAT () फ़ंक्शन के दो कॉल होते हैं ("मास्टर टेबल" तालिका से दो कॉलम इस फ़ंक्शन के पैरामीटर हैं)।
उत्पादन क्वेरी इस तरह दिखती है:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
निष्पादन योजना की "तस्वीर" नीचे है (निष्पादन योजना सरल है:अनुक्रमिक जुड़ती है और शीर्ष पर (DISTINCT कुंजी शब्द) क्रमबद्ध करती है):

आइए हम जानकारी को विस्तार से देखें।
पहला ऑपरेशन "टेबल स्कैन" है (सब सही है, कोई आश्चर्य नहीं):

"स्केलर कंप्यूट" ऑपरेशन नाटकीय रूप से अनुमानित पंक्ति आकार के साथ-साथ अनुमानित पंक्ति आकार (19 जीबी से 1,3 टीबी तक) को बढ़ाता है। FORMAT() फ़ंक्शन की दो कॉलों ने अनुमानित पंक्ति आकार में लगभग 8000 बाइट्स जोड़े (लेकिन वास्तविक डेटा आकार छोटा है)।

जॉइन ऑपरेशन में से एक (हैश मैच, राइट आउटर जॉइन) दाएं टेबल से गैर-अद्वितीय कॉलम का उपयोग करता है। कुछ अभिलेखों के मामले में इससे कोई फर्क नहीं पड़ता। यह हमारा मामला नहीं है। परिणामस्वरूप अनुमानित डेटा आकार ~2,4TB तक बढ़ रहा है।

एक चेतावनी भी है (इस ऑपरेशन को संसाधित करने के लिए पर्याप्त RAM नहीं):
SQL क्वेरी में शीर्ष पर एक "विशिष्ट सॉर्ट" ऑपरेशन होता है, जो केक के शीर्ष पर चेरी जैसा दिखता है। हम वही चेतावनी वहां देख सकते हैं।
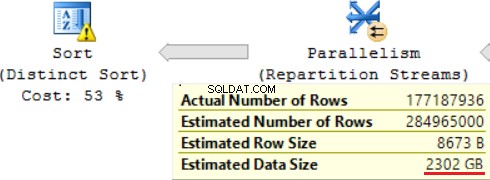
स्केलर फ़ंक्शन का उपयोग करने का परिणाम क्वेरी निष्पादन के लिए एक लंबा समय है:24 घंटे। इस समस्या के कारणों में से एक "अनुमानित डेटा आकार" के आधार पर अनुरोधित डेटा आकार का गलत अनुमान है। FORMAT() फ़ंक्शन का उपयोग किए बिना, MS SQL सर्वर इस क्वेरी को 2 घंटे में निष्पादित करता है।
निष्कर्ष
nvarchar और varchar डेटा प्रकारों का उपयोग करते समय डेवलपर्स को सावधान रहना चाहिए। कॉलम के लिए अनावश्यक डेटा प्रकारों का चयन करने से आवश्यक मेमोरी बढ़ सकती है। परिणामस्वरूप, RAM बर्बाद हो जाएगी, डेटाबेस का प्रदर्शन ख़राब हो जाएगा।