SQL सर्वर DBA के रूप में, हमने सुना है कि अनुक्रमणिका संरचनाएं किसी भी क्वेरी (या प्रश्नों के सेट) के प्रदर्शन में नाटकीय रूप से सुधार कर सकती हैं। फिर भी, कुछ विवरण हैं जिन्हें कई डीबीए अनदेखा कर देते हैं, जैसे निम्न:
- सूचकांक संरचनाएं खंडित हो सकती हैं, जिससे संभावित रूप से प्रदर्शन में गिरावट की समस्या हो सकती है।
- एक बार एक डेटाबेस तालिका के लिए एक अनुक्रमणिका संरचना को तैनात किया गया है, SQL सर्वर उस तालिका के लिए जब भी लेखन कार्य करता है तो उसे अपडेट करता है। ऐसा तब होता है जब इंडेक्स के अनुरूप कॉलम प्रभावित होते हैं।
- एसक्यूएल सर्वर के अंदर मेटाडेटा है जिसका उपयोग यह जानने के लिए किया जा सकता है कि किसी विशेष इंडेक्स संरचना के आंकड़े आखिरी बार कब अपडेट किए गए थे (यदि कभी)। अपर्याप्त या पुराने आंकड़े कुछ प्रश्नों के प्रदर्शन को प्रभावित कर सकते हैं।
- एसक्यूएल सर्वर के अंदर मेटाडेटा है जिसका उपयोग यह जानने के लिए किया जा सकता है कि या तो रीड ऑपरेशंस द्वारा इंडेक्स स्ट्रक्चर का कितना उपभोग किया गया है, या एसक्यूएल सर्वर द्वारा राइट ऑपरेशंस द्वारा अपडेट किया गया है। यह जानकारी यह जानने के लिए उपयोगी हो सकती है कि क्या ऐसे इंडेक्स हैं जिनकी लिखने की मात्रा पढ़ने वाले से काफी अधिक है। यह संभावित रूप से एक इंडेक्स संरचना हो सकती है जो आसपास रखने के लिए उपयोगी नहीं है।*
*यह ध्यान रखना बहुत ज़रूरी है कि इस विशेष मेटाडेटा को रखने वाला सिस्टम व्यू हर बार SQL सर्वर इंस्टेंस के पुनरारंभ होने पर वाइप हो जाता है, इसलिए यह इसकी अवधारणा से जानकारी नहीं होगी।
इन विवरणों के महत्व के कारण, मैंने यथासंभव सक्रिय रूप से कार्य करने के लिए, उसके वातावरण में सूचकांक संरचनाओं के बारे में जानकारी का ट्रैक रखने के लिए एक संग्रहीत प्रक्रिया बनाई है।
प्रारंभिक विचार
- सुनिश्चित करें कि इस संग्रहीत प्रक्रिया को निष्पादित करने वाले खाते में पर्याप्त विशेषाधिकार हैं। आप शायद sysadmin वाले के साथ शुरू कर सकते हैं और फिर यह सुनिश्चित करने के लिए जितना संभव हो उतना बारीक जा सकते हैं कि उपयोगकर्ता के पास SP को ठीक से काम करने के लिए आवश्यक न्यूनतम विशेषाधिकार हैं।
- डेटाबेस ऑब्जेक्ट (डेटाबेस तालिका और संग्रहीत कार्यविधि) स्क्रिप्ट निष्पादित होने के समय चयनित डेटाबेस के अंदर बनाए जाएंगे, इसलिए सावधानी से चुनें।
- स्क्रिप्ट को इस तरह से तैयार किया गया है कि इसे बिना किसी त्रुटि के कई बार निष्पादित किया जा सकता है। संग्रहीत प्रक्रिया के लिए, मैंने SQL Server 2016 SP1 के बाद से उपलब्ध क्रिएट या ALTER PROCEDURE स्टेटमेंट का उपयोग किया।
- यदि आप किसी भिन्न नामकरण परंपरा का उपयोग करना चाहते हैं, तो बनाए गए डेटाबेस ऑब्जेक्ट का नाम बदलने के लिए स्वतंत्र महसूस करें।
- जब आप संग्रहीत प्रक्रिया द्वारा लौटाए गए डेटा को जारी रखना चुनते हैं, तो लक्ष्य तालिका को पहले छोटा कर दिया जाएगा, इसलिए केवल सबसे हाल का परिणाम सेट संग्रहीत किया जाएगा। आप आवश्यक समायोजन कर सकते हैं यदि आप चाहते हैं कि यह किसी भी कारण से अलग व्यवहार करे (शायद ऐतिहासिक जानकारी रखने के लिए?)।
संग्रहीत प्रक्रिया का उपयोग कैसे करें?
- टी-एसक्यूएल कोड को कॉपी और पेस्ट करें (इस लेख में उपलब्ध)।
- एसपी को 2 मापदंडों की उम्मीद है:
- @पर्सिस्टडेटा:'Y' यदि DBA किसी लक्ष्य तालिका में आउटपुट को सहेजना चाहता है, और 'N' यदि DBA केवल आउटपुट को सीधे देखना चाहता है।
- @db:सभी डेटाबेस (सिस्टम और उपयोगकर्ता) के लिए जानकारी प्राप्त करने के लिए 'सभी', उपयोगकर्ता डेटाबेस को लक्षित करने के लिए 'उपयोगकर्ता', केवल सिस्टम डेटाबेस को लक्षित करने के लिए 'सिस्टम' (tempdb को छोड़कर), और अंत में वास्तविक नाम एक विशेष डेटाबेस।
प्रस्तुत किए गए फ़ील्ड और उनके अर्थ
- डीबीनाम: डेटाबेस का नाम जहां इंडेक्स ऑब्जेक्ट रहता है।
- स्कीमानाम: स्कीमा का नाम जहां इंडेक्स ऑब्जेक्ट रहता है।
- तालिका का नाम: टेबल का नाम जहां इंडेक्स ऑब्जेक्ट रहता है।
- इंडेक्सनाम: सूचकांक संरचना का नाम।
- प्रकार: अनुक्रमणिका का प्रकार (उदा. संकुलित, गैर-संकुल)।
- आवंटन_इकाई_प्रकार: संदर्भित डेटा के प्रकार को निर्दिष्ट करता है (उदाहरण के लिए पंक्ति में डेटा, लॉब डेटा)।
- विखंडन: विखंडन की मात्रा (% में) जो वर्तमान में सूचकांक संरचना में है।
- पृष्ठ: अनुक्रमणिका संरचना बनाने वाले 8KB पृष्ठों की संख्या।
- लिखता है: SQL सर्वर इंस्टेंस के अंतिम बार पुनरारंभ होने के बाद से इंडेक्स संरचना का अनुभव करने वाले लिखने की संख्या।
- पढ़ता है: SQL सर्वर इंस्टेंस के अंतिम बार पुनरारंभ होने के बाद से इंडेक्स संरचना ने जो रीड्स का अनुभव किया है, उनकी संख्या।
- अक्षम: 1 यदि अनुक्रमणिका संरचना वर्तमान में अक्षम है या 0 यदि संरचना सक्षम है।
- stats_timestamp: उस समय का टाइमस्टैम्प मान जब किसी विशेष अनुक्रमणिका संरचना के आंकड़े अंतिम बार अपडेट किए गए थे (NULL यदि कभी नहीं)।
- data_collection_timestamp: केवल तभी दिखाई देता है जब 'Y' @persistData पैरामीटर को पास किया जाता है, और इसका उपयोग यह जानने के लिए किया जाता है कि SP कब निष्पादित किया गया था और जानकारी सफलतापूर्वक DBA_Indexes तालिका में सहेजी गई थी।
निष्पादन परीक्षण
मैं संग्रहीत प्रक्रिया के कुछ निष्पादन प्रदर्शित करूंगा ताकि आप यह जान सकें कि इससे क्या उम्मीद की जा सकती है:
*आप इस लेख के अंत में स्क्रिप्ट का पूरा टी-एसक्यूएल कोड पा सकते हैं, इसलिए निम्न अनुभाग के साथ आगे बढ़ने से पहले इसे निष्पादित करना सुनिश्चित करें।
*परिणाम सेट 1 स्क्रीनशॉट में ठीक से फिट होने के लिए बहुत चौड़ा होगा, इसलिए मैं पूरी जानकारी प्रस्तुत करने के लिए सभी आवश्यक स्क्रीनशॉट साझा करूंगा।
/* सभी सिस्टम और उपयोगकर्ता डेटाबेस के लिए सभी इंडेक्स जानकारी प्रदर्शित करें */
EXEC GetIndexData @persistData = 'N',@db = 'all'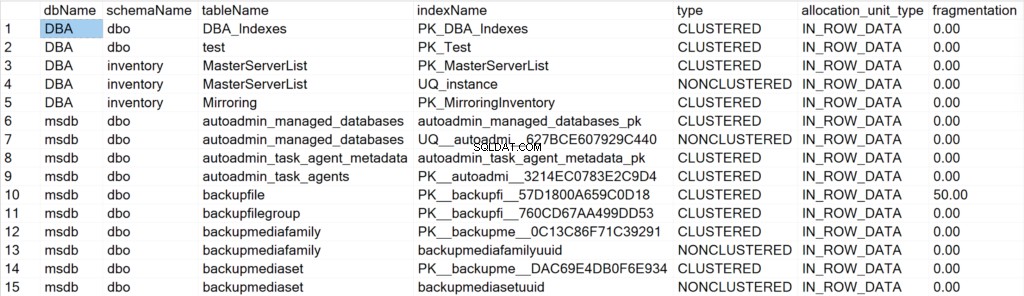
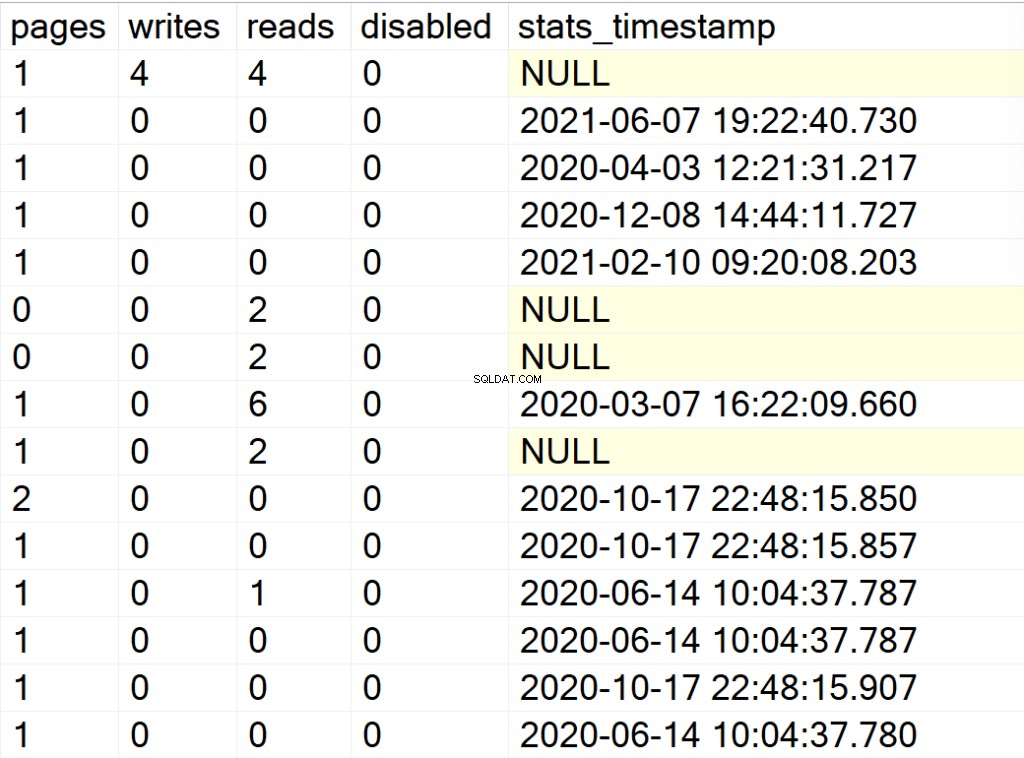
/* सभी सिस्टम डेटाबेस के लिए सभी इंडेक्स जानकारी प्रदर्शित करें */
EXEC GetIndexData @persistData = 'N',@db = 'system'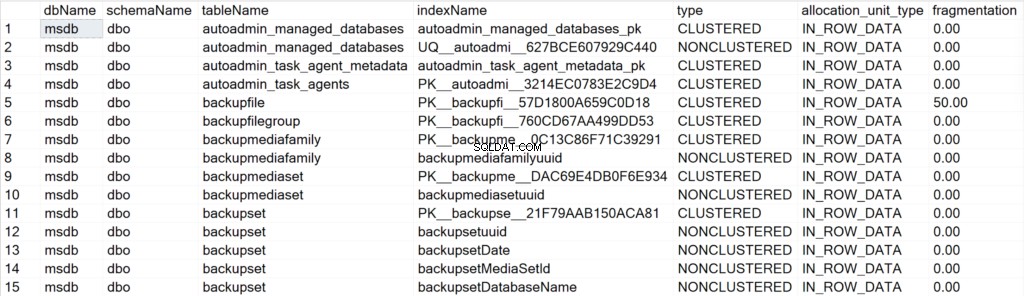
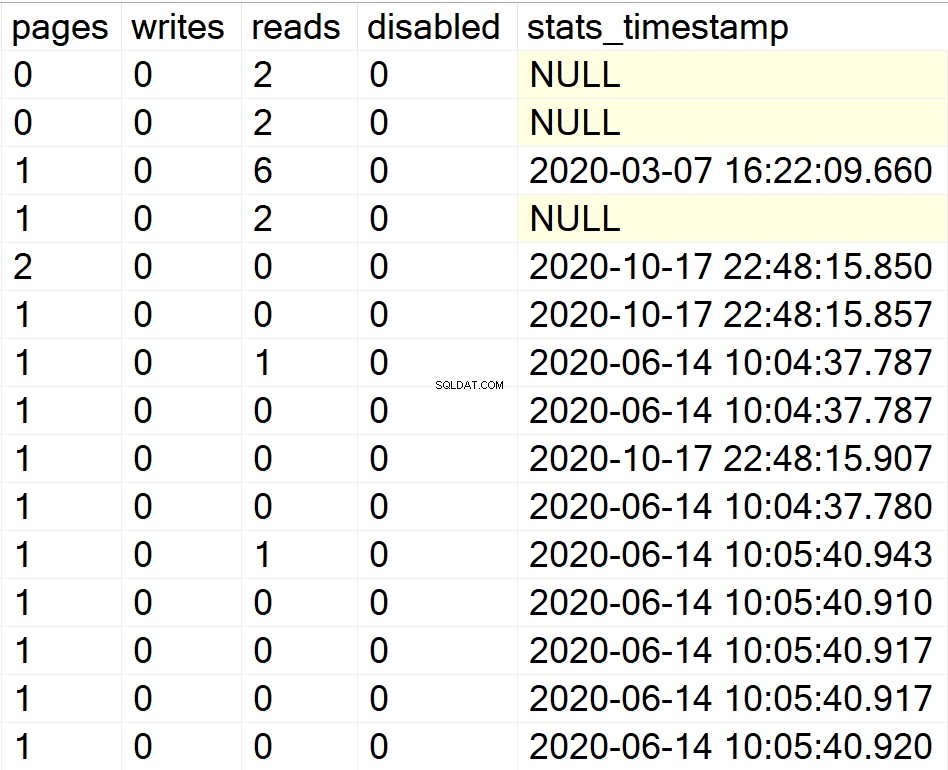
/* सभी उपयोगकर्ता डेटाबेस के लिए सभी अनुक्रमणिका जानकारी प्रदर्शित करें */
EXEC GetIndexData @persistData = 'N',@db = 'user'
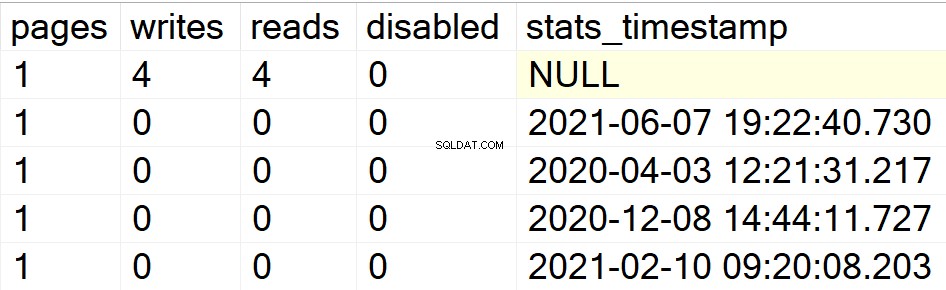
/* विशिष्ट उपयोगकर्ता डेटाबेस के लिए सभी अनुक्रमणिका जानकारी प्रदर्शित करें */
मेरे पिछले उदाहरणों में, केवल डेटाबेस DBA ने मेरे एकमात्र उपयोगकर्ता डेटाबेस के रूप में इसमें अनुक्रमणिका के साथ दिखाया। इसलिए, मुझे एक और डेटाबेस में एक इंडेक्स स्ट्रक्चर बनाने दें जो मैंने उसी उदाहरण में बिछाया है ताकि आप देख सकें कि एसपी अपना काम करता है या नहीं।
EXEC GetIndexData @persistData = 'N',@db = 'db2'
अब तक दिखाए गए सभी उदाहरण उस आउटपुट को प्रदर्शित करते हैं जो आपको तब मिलता है जब आप डेटा को बनाए रखना नहीं चाहते हैं, @db पैरामीटर के विकल्पों के विभिन्न संयोजनों के लिए। आउटपुट खाली होता है जब आप या तो कोई विकल्प निर्दिष्ट करते हैं जो मान्य नहीं है या लक्ष्य डेटाबेस मौजूद नहीं है। लेकिन क्या होगा जब डीबीए डेटाबेस तालिका में डेटा जारी रखना चाहता है? आइए जानें।
*मैं केवल एक मामले के लिए SP चलाने जा रहा हूँ क्योंकि @db पैरामीटर के लिए बाकी विकल्पों को ऊपर बहुत अधिक प्रदर्शित किया गया है और परिणाम समान है लेकिन डेटाबेस तालिका पर कायम है।
EXEC GetIndexData @persistData = 'Y',@db = 'user'
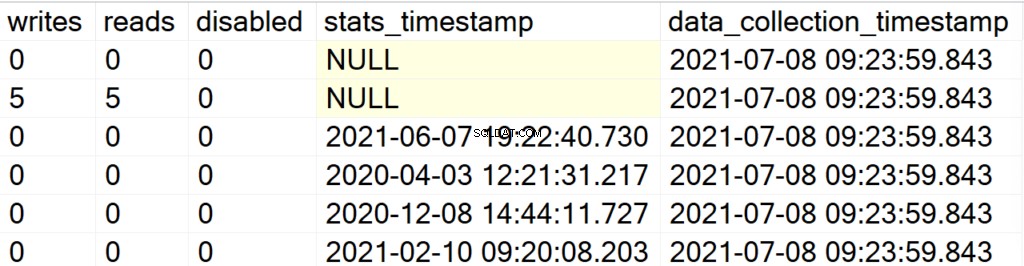
अब, संग्रहीत प्रक्रिया को निष्पादित करने के बाद आपको कोई आउटपुट नहीं मिलेगा। परिणाम सेट को क्वेरी करने के लिए आपको DBA_Indexes तालिका के विरुद्ध एक चयन कथन जारी करना होगा। यहां मुख्य आकर्षण यह है कि आप विश्लेषण के बाद प्राप्त परिणाम सेट और डेटा_संग्रह_टाइमस्टैम्प फ़ील्ड को जोड़ने के लिए क्वेरी कर सकते हैं जो आपको बताएगा कि आप जो डेटा देख रहे हैं वह कितना पुराना/पुराना है।
साइड क्वेरी
अब, डीबीए को अधिक मूल्य प्रदान करने के लिए, मैंने कुछ प्रश्न तैयार किए हैं जो तालिका में मौजूद डेटा से उपयोगी जानकारी प्राप्त करने में आपकी सहायता कर सकते हैं।
*समग्र रूप से बहुत खंडित अनुक्रमणिका खोजने की क्वेरी।
*उस% की संख्या चुनें जिसे आप उपयुक्त मानते हैं।
*1500 पृष्ठ मेरे द्वारा पढ़े गए लेख पर आधारित हैं, जो माइक्रोसॉफ्ट की सिफारिश पर आधारित है।
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*आपके परिवेश में अक्षम अनुक्रमणिका खोजने की क्वेरी.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*अनुक्रमणिका (ज्यादातर गैर-संकुल) खोजने के लिए क्वेरी जो कि क्वेरी द्वारा इतना अधिक उपयोग नहीं की जाती हैं, कम से कम पिछली बार जब SQL सर्वर इंस्टेंस को पुनरारंभ किया गया था।
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*ऐसे आंकड़े खोजने की क्वेरी जो या तो कभी अपडेट नहीं हुए या पुराने हैं।
*आप निर्धारित करते हैं कि आपके परिवेश में क्या पुराना है, इसलिए दिनों की संख्या को तदनुसार समायोजित करना सुनिश्चित करें।
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;यहाँ संग्रहीत प्रक्रिया का पूरा कोड है:
*स्क्रिप्ट की शुरुआत में, आप डिफ़ॉल्ट मान देखेंगे जिसे संग्रहीत प्रक्रिया मानती है यदि प्रत्येक पैरामीटर के लिए कोई मान पास नहीं किया जाता है।
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOनिष्कर्ष
- आप इस SP को अपने समर्थन के तहत प्रत्येक SQL सर्वर इंस्टेंस में परिनियोजित कर सकते हैं और समर्थित इंस्टेंस के अपने पूरे स्टैक में एक चेतावनी तंत्र लागू कर सकते हैं।
- यदि आप एक एजेंट की नौकरी लागू करते हैं जो इस जानकारी को अपेक्षाकृत बार-बार पूछताछ कर रही है, तो आप अपने समर्थित वातावरण के भीतर इंडेक्स संरचनाओं की देखभाल करने के लिए खेल के शीर्ष पर रह सकते हैं।
- सैंडबॉक्स वातावरण में इस तंत्र का ठीक से परीक्षण करना सुनिश्चित करें और, जब आप उत्पादन परिनियोजन की योजना बना रहे हों, तो कम गतिविधि अवधि चुनना सुनिश्चित करें।
सूचकांक विखंडन के मुद्दे मुश्किल और तनावपूर्ण हो सकते हैं। उन्हें खोजने और ठीक करने के लिए, आप विभिन्न टूल का उपयोग कर सकते हैं, जैसे dbForge Index Manager जिसे यहां डाउनलोड किया जा सकता है।