TeamCity जावा में निर्मित एक सतत एकीकरण और निरंतर वितरण सर्वर है। यह क्लाउड सेवा और ऑन-प्रिमाइसेस के रूप में उपलब्ध है। जैसा कि आप कल्पना कर सकते हैं, निरंतर एकीकरण और वितरण उपकरण सॉफ्टवेयर विकास के लिए महत्वपूर्ण हैं, और उनकी उपलब्धता अप्रभावित होनी चाहिए। सौभाग्य से, TeamCity को अत्यधिक उपलब्ध मोड में परिनियोजित किया जा सकता है।
इस ब्लॉग पोस्ट में TeamCity के लिए अत्यधिक उपलब्ध वातावरण तैयार करना और परिनियोजित करना शामिल होगा।
पर्यावरण
TeamCity में कई तत्व होते हैं। एक जावा एप्लिकेशन और एक डेटाबेस है जो इसका बैक अप लेता है। यह उन एजेंटों का भी उपयोग करता है जो प्राथमिक TeamCity उदाहरण के साथ संचार कर रहे हैं। अत्यधिक उपलब्ध परिनियोजन में कई TeamCity उदाहरण शामिल हैं, जहाँ एक प्राथमिक के रूप में कार्य कर रहा है, और दूसरा द्वितीयक। वे उदाहरण एक ही डेटाबेस और डेटा निर्देशिका तक पहुंच साझा करते हैं। टीमसिटी दस्तावेज़ पृष्ठ पर सहायक स्कीमा उपलब्ध है, जैसा कि नीचे दिखाया गया है:

जैसा कि हम देख सकते हैं, दो साझा तत्व हैं — डेटा निर्देशिका और डेटाबेस। हमें यह सुनिश्चित करना चाहिए कि वे भी अत्यधिक उपलब्ध हों। साझा माउंट बनाने के लिए आप विभिन्न विकल्पों का उपयोग कर सकते हैं; हालांकि, हम GlusterFS का उपयोग करेंगे। डेटाबेस के लिए, हम समर्थित रिलेशनल डेटाबेस प्रबंधन प्रणालियों में से एक का उपयोग करेंगे - PostgreSQL, और हम इसके आधार पर एक उच्च उपलब्धता स्टैक बनाने के लिए ClusterControl का उपयोग करेंगे।
GlusterFS को कैसे कॉन्फ़िगर करें
आइए बुनियादी बातों से शुरू करते हैं। हम अपने TeamCity नोड्स पर होस्टनाम और /etc/hosts को कॉन्फ़िगर करना चाहते हैं, जहां हम GlusterFS भी तैनात करेंगे। ऐसा करने के लिए, हमें उन सभी पर GlusterFS के नवीनतम पैकेजों के लिए रिपॉजिटरी सेटअप करने की आवश्यकता है:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateतब हम अपने सभी TeamCity नोड्स पर GlusterFS स्थापित कर सकते हैं:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS नोड्स के बीच कनेक्टिविटी के लिए पोर्ट 24007 का उपयोग करता है; हमें यह सुनिश्चित करना चाहिए कि यह सभी नोड्स द्वारा खुला और सुलभ है।
एक बार कनेक्टिविटी हो जाने के बाद, हम एक नोड से चलाकर एक GlusterFS क्लस्टर बना सकते हैं:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.अब, हम जांच सकते हैं कि स्थिति कैसी दिखती है:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)ऐसा लगता है कि सब कुछ ठीक है और कनेक्टिविटी ठीक है।
इसके बाद, हमें GlusterFS द्वारा उपयोग किए जाने के लिए एक ब्लॉक डिवाइस तैयार करना चाहिए। यह सभी नोड्स पर निष्पादित किया जाना चाहिए। सबसे पहले, एक विभाजन बनाएं:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.फिर, उस विभाजन को प्रारूपित करें:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0आखिरकार, सभी नोड्स पर, हमें एक निर्देशिका बनाने की आवश्यकता होती है जिसका उपयोग विभाजन को माउंट करने के लिए किया जाएगा और यह सुनिश्चित करने के लिए fstab संपादित किया जाएगा कि इसे स्टार्टअप पर माउंट किया जाएगा:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabआइए अब सत्यापित करें कि यह काम करता है:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)अब हम GlusterFS वॉल्यूम बनाने और शुरू करने के लिए किसी एक नोड का उपयोग कर सकते हैं:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successकृपया ध्यान दें कि हम प्रतिकृतियों की संख्या के लिए '3' के मान का उपयोग करते हैं। इसका मतलब है कि हर वॉल्यूम तीन प्रतियों में मौजूद होगा। हमारे मामले में, सभी नोड्स पर प्रत्येक ईंट, प्रत्येक /dev/sdb1 वॉल्यूम में सभी डेटा होगा।
वॉल्यूम शुरू होने के बाद, हम उनकी स्थिति की पुष्टि कर सकते हैं:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksजैसा कि आप देख सकते हैं, सब कुछ ठीक लग रहा है। महत्वपूर्ण यह है कि GlusterFS ने उस वॉल्यूम को एक्सेस करने के लिए पोर्ट 49152 को चुना है, और हमें यह सुनिश्चित करना चाहिए कि यह उन सभी नोड्स पर पहुंच योग्य है जहां हम इसे माउंट करेंगे।
अगला चरण GlusterFS क्लाइंट पैकेज को स्थापित करना होगा। इस उदाहरण के लिए, हमें इसे GlusterFS सर्वर के समान नोड्स पर स्थापित करने की आवश्यकता है:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.इसके बाद, हमें टीमसिटी के लिए साझा डेटा निर्देशिका के रूप में उपयोग करने के लिए सभी नोड्स पर एक निर्देशिका बनाने की आवश्यकता है। यह सभी नोड्स पर होना है:
example@sqldat.com:~# sudo mkdir /teamcity-storageअंत में, सभी नोड्स पर GlusterFS वॉल्यूम माउंट करें:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageयह साझा भंडारण की तैयारी पूरी करता है।
एक अत्यधिक उपलब्ध PostgreSQL क्लस्टर बनाना
टीमसिटी के लिए साझा स्टोरेज सेटअप पूरा होने के बाद, अब हम अपने अत्यधिक उपलब्ध डेटाबेस इंफ्रास्ट्रक्चर का निर्माण कर सकते हैं। टीमसिटी विभिन्न डेटाबेस का उपयोग कर सकती है; हालांकि, हम इस ब्लॉग में PostgreSQL का उपयोग करेंगे। हम डेटाबेस परिवेश को परिनियोजित करने और फिर प्रबंधित करने के लिए ClusterControl का लाभ उठाएँगे।
मल्टी-नोड परिनियोजन के निर्माण के लिए TeamCity की मार्गदर्शिका सहायक है, लेकिन ऐसा लगता है कि TeamCity के अलावा अन्य सभी चीज़ों की उच्च उपलब्धता को छोड़ दें। टीमसिटी की मार्गदर्शिका डेटा भंडारण के लिए एक एनएफएस या एसएमबी सर्वर का सुझाव देती है, जो अपने आप में अतिरेक नहीं है और विफलता का एकल बिंदु बन जाएगा। हमने इसे GlusterFS का उपयोग करके संबोधित किया है। वे एक साझा डेटाबेस का उल्लेख करते हैं, क्योंकि एक एकल डेटाबेस नोड स्पष्ट रूप से उच्च उपलब्धता प्रदान नहीं करता है। हमें एक उचित स्टैक बनाना होगा:

हमारे मामले में। इसमें तीन पोस्टग्रेएसक्यूएल नोड्स, एक प्राथमिक और दो प्रतिकृतियां शामिल होंगी। हम HAProxy को लोड बैलेंसर के रूप में उपयोग करेंगे और वर्चुअल आईपी को प्रबंधित करने के लिए Keepalived का उपयोग करेंगे ताकि एप्लिकेशन को कनेक्ट करने के लिए एक एकल समापन बिंदु प्रदान किया जा सके। क्लस्टर कंट्रोल प्रतिकृति टोपोलॉजी की निगरानी करके और आवश्यकतानुसार किसी भी आवश्यक पुनर्प्राप्ति को निष्पादित करके विफलताओं को संभालेगा, जैसे विफल प्रक्रियाओं को पुनरारंभ करना या प्राथमिक नोड के नीचे जाने पर प्रतिकृतियों में से किसी एक को विफल करना।
शुरू करने के लिए, हम डेटाबेस नोड्स को तैनात करेंगे। कृपया ध्यान रखें कि ClusterControl को ClusterControl नोड से SSH कनेक्टिविटी की आवश्यकता होती है जो इसे प्रबंधित करता है।

फिर, हम एक उपयोगकर्ता चुनते हैं जिसका उपयोग हम इससे कनेक्ट करने के लिए करेंगे डेटाबेस, उसका पासवर्ड, और पोस्टग्रेएसक्यूएल संस्करण परिनियोजित करने के लिए:

अगला, हम परिभाषित करने जा रहे हैं कि PostgreSQL को परिनियोजित करने के लिए किन नोड्स का उपयोग करना है :
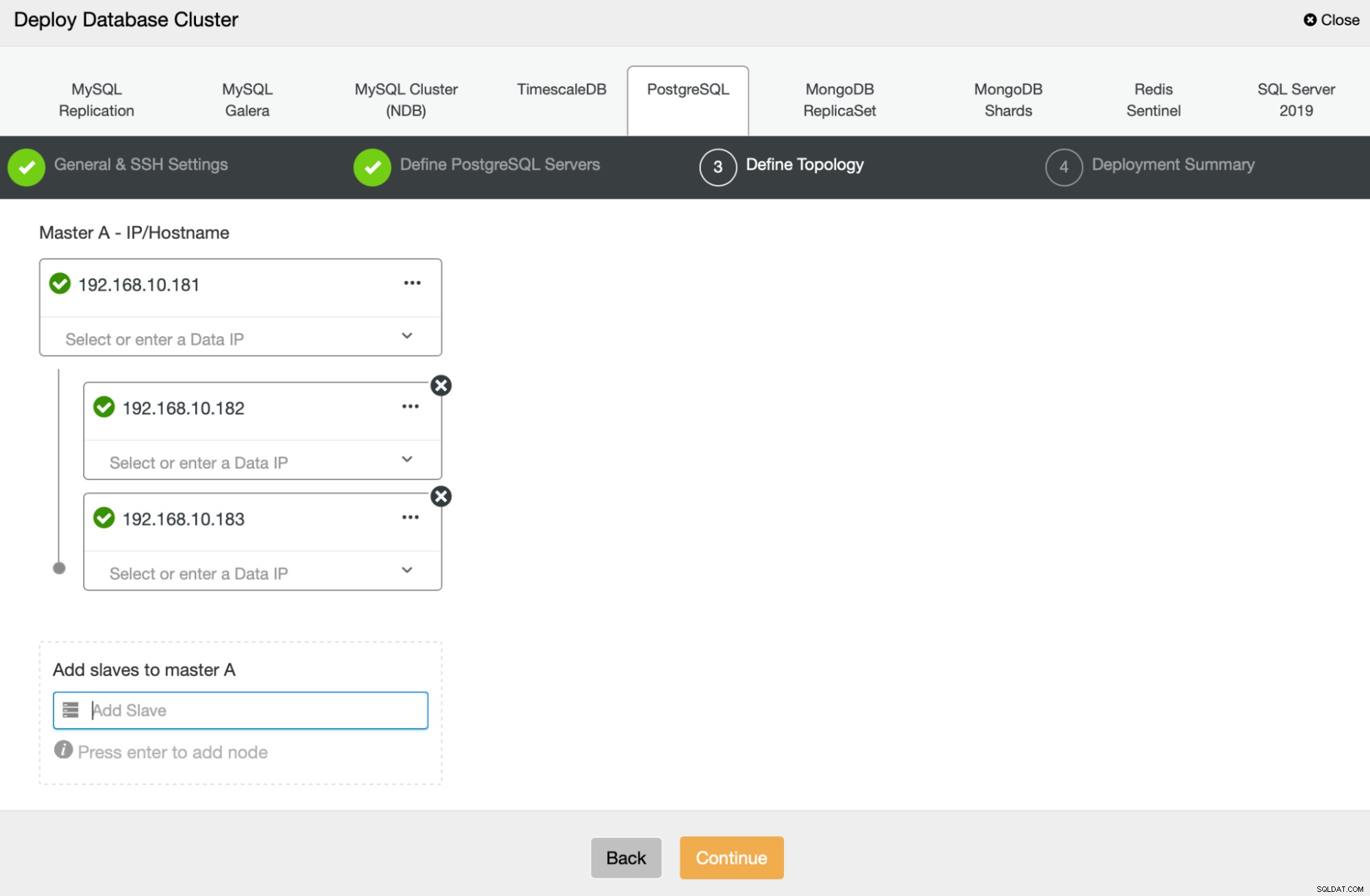
आखिरकार, हम यह परिभाषित कर सकते हैं कि नोड्स को एसिंक्रोनस या सिंक्रोनस प्रतिकृति का उपयोग करना चाहिए या नहीं। इन दोनों के बीच मुख्य अंतर यह है कि सिंक्रोनस प्रतिकृति यह सुनिश्चित करती है कि प्राथमिक नोड पर निष्पादित प्रत्येक लेनदेन हमेशा प्रतिकृतियों पर दोहराया जाएगा। हालाँकि, सिंक्रोनस प्रतिकृति भी कमिटमेंट को धीमा कर देती है। हम सर्वोत्तम स्थायित्व के लिए सिंक्रोनस प्रतिकृति को सक्षम करने की अनुशंसा करते हैं, लेकिन आपको बाद में सत्यापित करना चाहिए कि क्या प्रदर्शन स्वीकार्य है।

"तैनाती" पर क्लिक करने के बाद, एक परिनियोजन कार्य शुरू हो जाएगा। हम ClusterControl UI में गतिविधि टैब में इसकी प्रगति की निगरानी कर सकते हैं। हमें अंततः यह देखना चाहिए कि कार्य पूरा हो गया है और क्लस्टर सफलतापूर्वक परिनियोजित किया गया है।

मैनेज -> लोड बैलेंसर्स पर जाकर HAProxy इंस्टेंसेस को डिप्लॉय करें। लोड बैलेंसर के रूप में HAProxy का चयन करें और फ़ॉर्म भरें। सबसे महत्वपूर्ण विकल्प वह है जहाँ आप HAProxy को परिनियोजित करना चाहते हैं। हमने इस मामले में एक डेटाबेस नोड का उपयोग किया है, लेकिन एक उत्पादन वातावरण में, आप सबसे अधिक संभावना है कि आप लोड बैलेंसर्स को डेटाबेस इंस्टेंस से अलग करना चाहते हैं। इसके बाद, HAProxy में शामिल करने के लिए कौन से PostgreSQL नोड चुनें. हम उन सभी को चाहते हैं।

अब HAProxy परिनियोजन प्रारंभ हो जाएगा। हम अतिरेक के लिए दो HAProxy उदाहरण बनाने के लिए इसे कम से कम एक बार फिर दोहराना चाहते हैं। इस परिनियोजन में, हमने तीन HAProxy लोड बैलेंसर्स के साथ जाने का निर्णय लिया। दूसरे HAProxy के परिनियोजन को कॉन्फ़िगर करते समय सेटिंग स्क्रीन का स्क्रीनशॉट नीचे दिया गया है:
जब हमारे सभी HAProxy इंस्टेंस चल रहे हों और चल रहे हों, तो हम Keepalived को परिनियोजित कर सकते हैं . यहाँ विचार यह है कि Keepalived को HAProxy के साथ जोड़ा जाएगा और HAProxy की प्रक्रिया की निगरानी की जाएगी। काम करने वाले HAProxy के उदाहरणों में से एक में वर्चुअल IP असाइन किया जाएगा। इस VIP का उपयोग एप्लिकेशन द्वारा डेटाबेस से कनेक्ट करने के लिए किया जाना चाहिए। Keepalived यह पता लगाएगा कि क्या वह HAProxy अनुपलब्ध हो जाता है और किसी अन्य उपलब्ध HAProxy इंस्टेंस पर चला जाता है।
परिनियोजन विज़ार्ड के लिए आवश्यक है कि हम HAProxy इंस्टेंस पास करें जिनकी हम निगरानी रखना चाहते हैं। हमें VIP के लिए IP पता और नेटवर्क इंटरफ़ेस भी पास करना होगा।

टीमसिटी के लिए डेटाबेस बनाने का अंतिम और अंतिम चरण होगा: 
इसके साथ, हमने अत्यधिक उपलब्ध PostgreSQL क्लस्टर की तैनाती का निष्कर्ष निकाला है।
टीमसिटी को मल्टी-नोड के रूप में परिनियोजित करना
अगला कदम टीमसिटी को एक बहु-नोड वातावरण में तैनात करना है। हम तीन TeamCity नोड्स का उपयोग करेंगे। सबसे पहले, हमें Java JRE और JDK को स्थापित करना होगा जो TeamCity की आवश्यकताओं से मेल खाते हों।
apt install default-jre default-jdkअब, सभी नोड्स पर, हमें टीमसिटी को डाउनलोड करना होगा। हम एक स्थानीय में स्थापित करेंगे, साझा निर्देशिका में नहीं।
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzफिर हम किसी एक नोड पर टीमसिटी शुरू कर सकते हैं:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logटीमसिटी शुरू होने के बाद, हम यूआई तक पहुंच सकते हैं और तैनाती शुरू कर सकते हैं। प्रारंभ में, हमें डेटा निर्देशिका स्थान को पास करना होगा। यह साझा वॉल्यूम है जिसे हमने GlusterFS पर बनाया है।

इसके बाद, डेटाबेस चुनें। हम एक PostgreSQL क्लस्टर का उपयोग करने जा रहे हैं जिसे हमने पहले ही बना लिया है।

JDBC ड्राइवर को डाउनलोड और इंस्टॉल करें:

इसके बाद, एक्सेस विवरण भरें। हम Keepalived द्वारा प्रदान किए गए वर्चुअल IP का उपयोग करेंगे। कृपया ध्यान दें कि हम पोर्ट 5433 का उपयोग करते हैं। यह HAProxy के रीड/राइट बैकएंड के लिए उपयोग किया जाने वाला पोर्ट है; यह हमेशा सक्रिय प्राथमिक नोड की ओर इशारा करेगा। इसके बाद, टीमसिटी के साथ उपयोग करने के लिए एक उपयोगकर्ता और डेटाबेस चुनें।

एक बार ऐसा करने के बाद, TeamCity डेटाबेस संरचना को प्रारंभ करना शुरू कर देगी। 
लाइसेंस समझौते से सहमत:

आखिरकार, टीमसिटी के लिए एक उपयोगकर्ता बनाएं:

बस! अब हमें टीमसिटी जीयूआई देखने में सक्षम होना चाहिए:

अब, हमें टीमसिटी को मल्टी-नोड मोड में सेट करना होगा। सबसे पहले, हमें सभी नोड्स पर स्टार्टअप स्क्रिप्ट को संपादित करना होगा:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shहमें यह सुनिश्चित करना होगा कि निम्नलिखित दो चर निर्यात किए गए हैं। कृपया सत्यापित करें कि आप स्थानीय और साझा भंडारण के लिए उचित होस्टनाम, आईपी और सही निर्देशिकाओं का उपयोग करते हैं:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"एक बार यह हो जाने के बाद, आप शेष नोड्स शुरू कर सकते हैं:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startआपको व्यवस्थापन में निम्न आउटपुट देखना चाहिए -> नोड्स कॉन्फ़िगरेशन:एक मुख्य नोड और दो स्टैंडबाय नोड्स।

कृपया ध्यान रखें कि TeamCity में विफलता स्वचालित नहीं है। यदि मुख्य नोड काम करना बंद कर देता है, तो आपको द्वितीयक नोड्स में से एक से जुड़ना चाहिए। ऐसा करने के लिए, "नोड्स कॉन्फ़िगरेशन" पर जाएं और इसे "मुख्य" नोड में प्रचारित करें। लॉगिन स्क्रीन से, आप एक स्पष्ट संकेत देखेंगे कि यह एक द्वितीयक नोड है:

"नोड्स कॉन्फ़िगरेशन" में, आप देखेंगे कि एक नोड में क्लस्टर से हटा दिया गया:

आपको यह बताते हुए एक संदेश प्राप्त होगा कि आप इस नोड को नहीं लिख सकते हैं। चिंता मत करो; इस नोड को "मुख्य" स्थिति में बढ़ावा देने के लिए आवश्यक लेखन ठीक काम करेगा:

"सक्षम करें" पर क्लिक करें और हमने द्वितीयक TimeCity नोड का सफलतापूर्वक प्रचार किया है:

जब नोड1 उपलब्ध हो जाता है और उस नोड पर टीमसिटी फिर से शुरू हो जाती है, तो हम करेंगे इसे फिर से क्लस्टर में देखें:

यदि आप प्रदर्शन में और सुधार करना चाहते हैं, तो आप HAProxy + Keepalived को TeamCity UI के सामने तैनात कर सकते हैं ताकि GUI को एकल प्रवेश बिंदु प्रदान किया जा सके। आप टीमसिटी के लिए HAProxy को कॉन्फ़िगर करने के बारे में विवरण दस्तावेज़ीकरण में पा सकते हैं।
रैपिंग अप
जैसा कि आप देख सकते हैं, टीमसिटी को उच्च उपलब्धता के लिए तैनात करना उतना मुश्किल नहीं है - इसमें से अधिकांश को दस्तावेज़ीकरण में पूरी तरह से कवर किया गया है। यदि आप इनमें से कुछ को स्वचालित करने और अत्यधिक उपलब्ध डेटाबेस बैकएंड जोड़ने के तरीकों की तलाश कर रहे हैं, तो 30 दिनों के लिए ClusterControl का निःशुल्क मूल्यांकन करने पर विचार करें। ClusterControl स्वचालित विफलता, पुनर्प्राप्ति, निगरानी, बैकअप प्रबंधन, और बहुत कुछ प्रदान करते हुए, बैकएंड को शीघ्रता से परिनियोजित और मॉनिटर कर सकता है।
सॉफ़्टवेयर विकास टूल और सर्वोत्तम प्रथाओं के बारे में अधिक युक्तियों के लिए, अपनी DevOps टीम को उनकी डेटाबेस आवश्यकताओं के साथ समर्थन करने का तरीका देखें।
अपने ओपन-सोर्स-आधारित डेटाबेस इन्फ्रास्ट्रक्चर के प्रबंधन के लिए नवीनतम समाचार और सर्वोत्तम अभ्यास प्राप्त करने के लिए, हमें ट्विटर या लिंक्डइन पर फॉलो करना न भूलें और हमारे न्यूज़लेटर की सदस्यता लें। जल्द ही मिलेंगे!