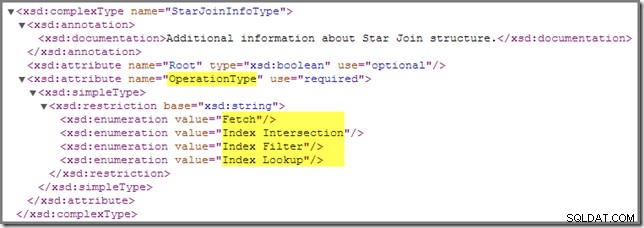
समय-समय पर, आप देख सकते हैं कि निष्पादन योजना में एक या अधिक शामिल होने पर StarJoinInfo के साथ एनोटेट किया जाता है। संरचना। आधिकारिक शोप्लान स्कीमा में इस योजना तत्व के बारे में कहने के लिए निम्नलिखित है (विस्तार करने के लिए क्लिक करें):
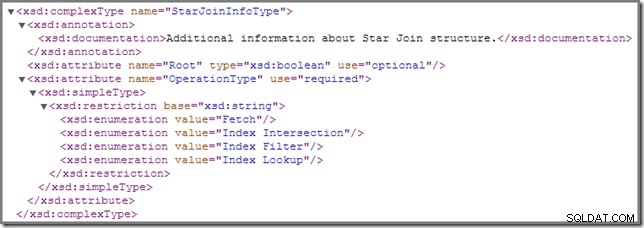
वहां दिखाया गया इन-लाइन दस्तावेज़ ("स्टार जॉइन संरचना के बारे में अतिरिक्त जानकारी ") इतना ज्ञानवर्धक नहीं है, हालांकि अन्य विवरण काफी पेचीदा हैं - हम इन्हें विस्तार से देखेंगे।
यदि आप "एसक्यूएल सर्वर स्टार जॉइन ऑप्टिमाइज़ेशन" जैसे शब्दों का उपयोग करके अधिक जानकारी के लिए अपने पसंदीदा खोज इंजन से परामर्श लेते हैं, तो आपको अनुकूलित बिटमैप फ़िल्टर का वर्णन करने वाले परिणाम दिखाई देने की संभावना है। यह एक अलग एंटरप्राइज़-ओनली सुविधा है जिसे SQL Server 2008 में पेश किया गया है, और StarJoinInfo से संबंधित नहीं है। संरचना बिल्कुल।
चुनिंदा स्टार क्वेरी के लिए ऑप्टिमाइज़ेशन
StarJoinInfo . की उपस्थिति इंगित करता है कि SQL सर्वर ने चुनिंदा स्टार-स्कीमा प्रश्नों पर लक्षित अनुकूलन के एक सेट को लागू किया है। ये अनुकूलन SQL सर्वर 2005 से सभी संस्करणों में उपलब्ध हैं (न केवल एंटरप्राइज़)। ध्यान दें कि चुनिंदा यहाँ तथ्य तालिका से प्राप्त पंक्तियों की संख्या को संदर्भित करता है। किसी क्वेरी में आयामी विधेय का संयोजन अभी भी चयनात्मक हो सकता है, भले ही इसकी व्यक्तिगत विधेय बड़ी संख्या में पंक्तियों को योग्य बनाती हो।
साधारण इंडेक्स इंटरसेक्शन
क्वेरी ऑप्टिमाइज़र कई गैर-संकुल अनुक्रमणिका को संयोजित करने पर विचार कर सकता है जहाँ एक उपयुक्त एकल अनुक्रमणिका मौजूद नहीं है, जैसा कि निम्न AdventureWorks क्वेरी प्रदर्शित करती है:
बिक्री से COUNT_BIG(*) चुनें.SalesOrderHeaderWHERE SalesPersonID =276AND CustomerID =29522;
ऑप्टिमाइज़र निर्धारित करता है कि दो गैर-संकुल अनुक्रमणिका (SalesPersonID पर एक) का संयोजन और दूसरा CustomerID . पर ) इस प्रश्न को संतुष्ट करने का सबसे सस्ता तरीका है (दोनों स्तंभों पर कोई अनुक्रमणिका नहीं है):
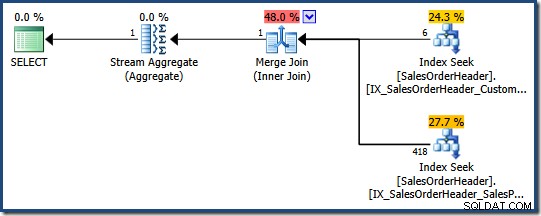
प्रत्येक अनुक्रमणिका विधेय को पार करने वाली पंक्तियों के लिए संकुल अनुक्रमणिका कुंजी लौटाती है। यह सुनिश्चित करने के लिए कि केवल दोनों . से मेल खाने वाली पंक्तियाँ, जॉइन लौटाई गई कुंजियों से मेल खाती हैं विधेय पारित किए जाते हैं।
यदि तालिका एक ढेर थी, तो प्रत्येक खोज क्लस्टर इंडेक्स कुंजियों के बजाय ढेर पंक्ति पहचानकर्ता (आरआईडी) लौटाएगा, लेकिन समग्र रणनीति समान है:प्रत्येक विधेय के लिए पंक्ति पहचानकर्ता खोजें, फिर उनका मिलान करें।
मैनुअल स्टार इंडेक्स इंटरसेक्शन में शामिल हों
आयाम तालिकाओं पर लागू विधेय का उपयोग करके एक तथ्य तालिका से पंक्तियों का चयन करने वाले प्रश्नों के लिए एक ही विचार बढ़ाया जा सकता है। यह कैसे काम करता है यह देखने के लिए, कॉन्टोसो स्टोर्स में ठीक 50 कर्मचारियों के साथ बेचे गए एमपी3 प्लेयर की कुल बिक्री राशि का पता लगाने के लिए निम्नलिखित क्वेरी (Contoso BI नमूना डेटाबेस का उपयोग करके) पर विचार करें:
dbo से SUM(FS.SalesAmount) चुनें। उत्पादनाम LIKE N'%MP3%';
बाद के प्रयासों की तुलना के लिए, यह (बहुत चयनात्मक) क्वेरी निम्नलिखित की तरह एक क्वेरी योजना तैयार करती है (विस्तार करने के लिए क्लिक करें):
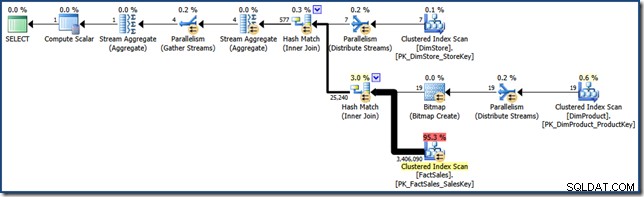
उस निष्पादन योजना की अनुमानित लागत 15.6 इकाइयों . से कुछ ही अधिक है . इसमें तथ्य तालिका के पूर्ण स्कैन के साथ समानांतर निष्पादन की सुविधा है (यद्यपि बिटमैप फ़िल्टर लागू होने के साथ)।
इस नमूना डेटाबेस में तथ्य तालिका में डिफ़ॉल्ट रूप से तथ्य तालिका विदेशी कुंजी पर गैर-संकुल अनुक्रमणिका शामिल नहीं है, इसलिए हमें एक जोड़े को जोड़ने की आवश्यकता है:
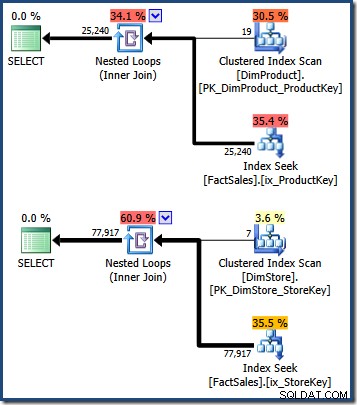
dbo पर INDEX ix_ProductKey बनाएं।FactSales (ProductKey);DBO पर INDEX ix_StoreKey बनाएं।इन इंडेक्स के साथ, हम यह देखना शुरू कर सकते हैं कि दक्षता में सुधार के लिए इंडेक्स चौराहे का उपयोग कैसे किया जा सकता है। पहला कदम प्रत्येक अलग विधेय के लिए तथ्य तालिका पंक्ति पहचानकर्ताओं को खोजना है। निम्नलिखित प्रश्न एकल आयाम विधेय को लागू करते हैं, फिर पंक्ति पहचानकर्ताओं को खोजने के लिए तथ्य तालिका में वापस शामिल होते हैं (तथ्य तालिका क्लस्टर इंडेक्स कुंजियाँ):
-- उत्पाद आयाम विधेय चुनें FS.SalesKeyFROM dbo.FactSales as FSJOIN dbo.DimProduct as DP ON DP.ProductKey =FS.ProductKeyWHERE DP.ProductName LIKE N'%MP3%'; -- स्टोर आयाम विधेय चुनें FS.SalesKeyFROM dbo.FactSales as FSJOIN dbo.DimStore AS DS ON DS.StoreKey =FS.StoreKeyWHERE DS.EmployeeCount =50;क्वेरी प्लान छोटे आयाम तालिका का स्कैन दिखाते हैं, इसके बाद पंक्ति पहचानकर्ताओं को खोजने के लिए तथ्य तालिका गैर-संकुल अनुक्रमणिका का उपयोग करके लुकअप करते हैं (याद रखें कि गैर-संकुल अनुक्रमणिका में हमेशा आधार तालिका क्लस्टरिंग कुंजी या हीप RID शामिल होती है):
तथ्य तालिका क्लस्टर्ड इंडेक्स कुंजियों के इन दो सेटों का प्रतिच्छेदन उन पंक्तियों की पहचान करता है जिन्हें मूल क्वेरी द्वारा वापस किया जाना चाहिए। एक बार जब हमारे पास ये पंक्ति पहचानकर्ता हो जाते हैं, तो हमें बस प्रत्येक तथ्य तालिका पंक्ति में बिक्री राशि को देखने की आवश्यकता होती है, और योग की गणना करने की आवश्यकता होती है।
मैन्युअल इंडेक्स इंटरसेक्शन क्वेरी
एक प्रश्न में वह सब एक साथ रखने से निम्नलिखित मिलता है:
से SUM(FS.SalesAmount) चुनें स्टोर आयाम dbo से FS.SalesKey का चयन करें। Keys.SalesKeyOPTION (MAXDOP 1);
FORCESEEKसंकेत यह सुनिश्चित करने के लिए है कि हमें तथ्य तालिका में बिंदु लुकअप प्राप्त हो। इसके बिना, ऑप्टिमाइज़र फैक्ट टेबल को स्कैन करने का विकल्प चुनता है, जो कि ठीक वही है जिससे हम बचना चाहते हैं।MAXDOP 1संकेत केवल अंतिम योजना को प्रदर्शन उद्देश्यों के लिए उचित आकार में रखने में मदद करता है (इसे पूर्ण आकार देखने के लिए क्लिक करें):
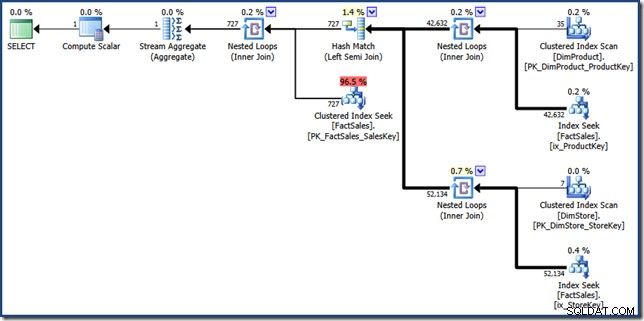
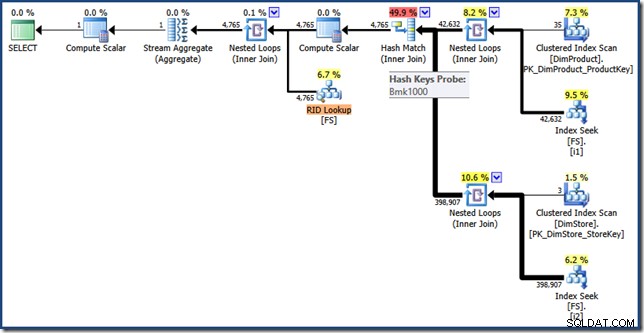
हस्तचालित सूचकांक प्रतिच्छेदन योजना के घटक भागों की पहचान करना काफी आसान है। दायीं ओर दो फैक्ट टेबल नॉनक्लस्टर इंडेक्स लुकअप फैक्ट टेबल रो आइडेंटिफायर के दो सेट तैयार करते हैं। हैश जॉइन इन दो सेटों के प्रतिच्छेदन का पता लगाता है। तथ्य तालिका में खोजी गई संकुल अनुक्रमणिका इन पंक्ति पहचानकर्ताओं के लिए बिक्री राशि ढूँढती है। अंत में, स्ट्रीम एग्रीगेट कुल राशि की गणना करता है।
यह क्वेरी योजना गैर-संकुलित और संकुल अनुक्रमित तथ्य तालिका में अपेक्षाकृत कम लुकअप करती है। यदि क्वेरी पर्याप्त रूप से चयनात्मक है, तो यह तथ्य तालिका को पूरी तरह से स्कैन करने की तुलना में एक सस्ती निष्पादन रणनीति हो सकती है। Contoso BI नमूना डेटाबेस अपेक्षाकृत छोटा है, बिक्री तथ्य तालिका में केवल 3.4 मिलियन पंक्तियाँ हैं। बड़े तथ्य तालिकाओं के लिए, एक पूर्ण स्कैन और कुछ सौ लुकअप के बीच का अंतर बहुत महत्वपूर्ण हो सकता है। दुर्भाग्य से, मैन्युअल पुनर्लेखन कुछ गंभीर कार्डिनैलिटी त्रुटियों का परिचय देता है, जिसके परिणामस्वरूप 46.5 इकाइयों की अनुमानित लागत वाली योजना होती है। ।
स्वचालित स्टार जॉइन इंडेक्स इंटरसेक्शन लुकअप के साथ
सौभाग्य से, हमें यह तय करने की आवश्यकता नहीं है कि हम जो प्रश्न लिख रहे हैं वह इस मैनुअल पुनर्लेखन को सही ठहराने के लिए पर्याप्त चयनात्मक है। चुनिंदा प्रश्नों के लिए स्टार जॉइन ऑप्टिमाइज़ेशन का मतलब है कि क्वेरी ऑप्टिमाइज़र अधिक उपयोगकर्ता के अनुकूल मूल क्वेरी सिंटैक्स का उपयोग करके हमारे लिए इस विकल्प का पता लगा सकता है:
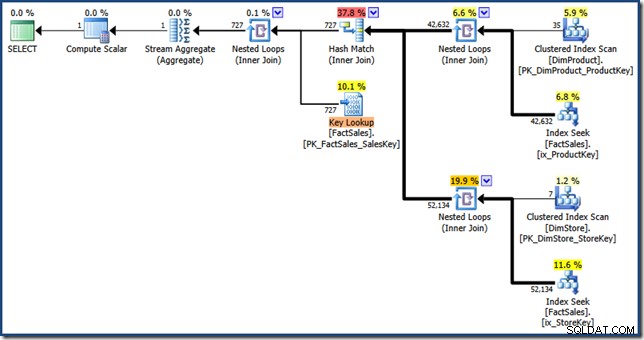
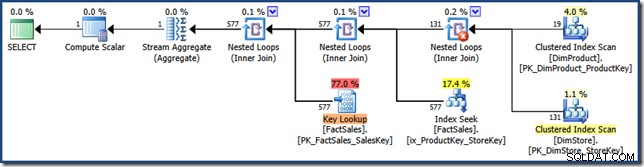
dbo से SUM(FS.SalesAmount) चुनें। उत्पादनाम LIKE N'%MP3%';अनुकूलक 1.64 . की अनुमानित लागत के साथ निम्नलिखित निष्पादन योजना तैयार करता है इकाइयां (विस्तार करने के लिए क्लिक करें):
इस योजना और मैनुअल संस्करण के बीच अंतर हैं:इंडेक्स इंटरसेक्शन एक सेमी जॉइन के बजाय एक इनर जॉइन है; और क्लस्टर्ड इंडेक्स लुकअप को क्लस्टर्ड इंडेक्स सीक के बजाय की लुकअप के रूप में दिखाया जाता है। बिंदु पर काम करने के जोखिम पर, यदि तथ्य तालिका एक ढेर थी, तो कुंजी लुकअप एक RID लुकअप होगा।
The StarJoinInfo गुण
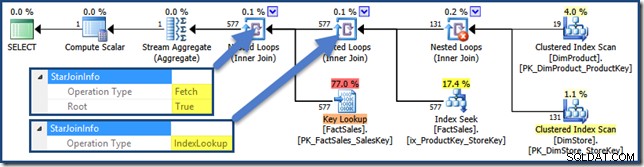
इस योजना में शामिल सभी लोगों के पास
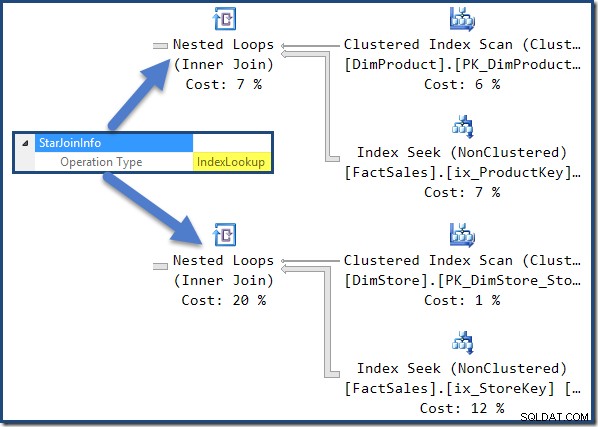
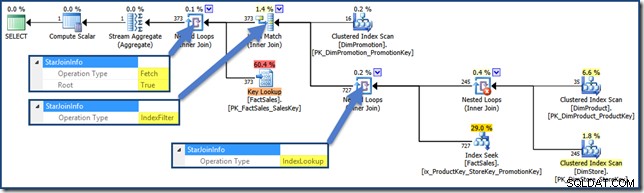
StarJoinInfoहै संरचना। इसे देखने के लिए, जॉइन इटरेटर पर क्लिक करें और SSMS प्रॉपर्टीज विंडो में देखें।StarJoinInfo. के बाईं ओर स्थित तीर पर क्लिक करें नोड का विस्तार करने के लिए तत्व।ऑप्टिमाइज़र द्वारा निर्मित इंडेक्स लुकअप योजना के दाईं ओर गैर-क्लस्टर किए गए तथ्य तालिका में शामिल हैं:
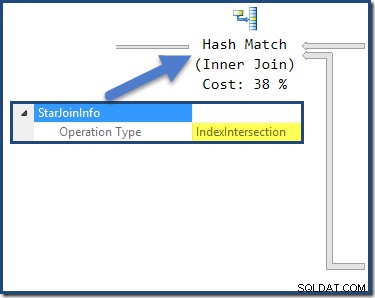
हैश जॉइन में एक
StarJoinInfoहोता है संरचना दिखा रही है कि यह एक इंडेक्स इंटरसेक्शन कर रहा है (फिर से, ऑप्टिमाइज़र द्वारा निर्मित):
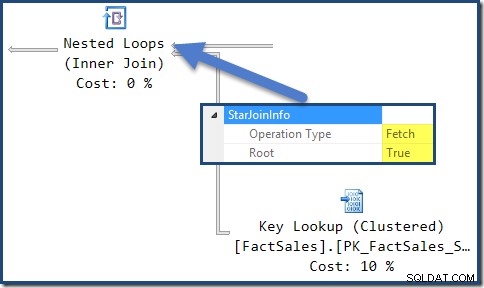
StarJoinInfoसबसे बाईं ओर नेस्टेड लूप्स में शामिल होने से पता चलता है कि यह पंक्ति पहचानकर्ता द्वारा तथ्य तालिका पंक्तियों को लाने के लिए उत्पन्न किया गया था। यह ऑप्टिमाइज़र-जनरेटेड स्टार जॉइन सबट्री के मूल में है:
कार्टेशियन उत्पाद और बहु-स्तंभ अनुक्रमणिका लुकअप
स्टार जॉइन ऑप्टिमाइज़ेशन के हिस्से के रूप में मानी जाने वाली इंडेक्स इंटरसेक्शन प्लान चुनिंदा फैक्ट टेबल क्वेरी के लिए उपयोगी होती है, जहां सिंगल-कॉलम नॉनक्लस्टर इंडेक्स फैक्ट टेबल फॉरेन कीज (एक सामान्य डिजाइन प्रैक्टिस) पर मौजूद होते हैं।
कभी-कभी अक्सर पूछे जाने वाले संयोजनों के लिए, तथ्य तालिका विदेशी कुंजियों पर बहु-स्तंभ अनुक्रमणिका बनाना भी समझ में आता है। बिल्ट-इन सेलेक्टिव स्टार क्वेरी ऑप्टिमाइज़ेशन में इस परिदृश्य के लिए एक पुनर्लेखन भी होता है। यह कैसे काम करता है यह देखने के लिए, निम्नलिखित बहु-स्तंभ अनुक्रमणिका को तथ्य तालिका में जोड़ें:
Dbo.FactSales (ProductKey, StoreKey);पर INDEX ix_ProductKey_StoreKey बनाएं।परीक्षण क्वेरी को फिर से संकलित करें:
dbo से SUM(FS.SalesAmount) चुनें। उत्पादनाम LIKE N'%MP3%';क्वेरी योजना में अब अनुक्रमणिका प्रतिच्छेदन की सुविधा नहीं है (विस्तार करने के लिए क्लिक करें):
यहां चुनी गई रणनीति प्रत्येक विधेय को आयाम तालिकाओं पर लागू करना है, परिणामों के कार्टेशियन उत्पाद को लेना है, और इसका उपयोग बहु-स्तंभ सूचकांक की दोनों कुंजियों को खोजने के लिए करना है। क्वेरी योजना तब पंक्ति पहचानकर्ताओं का उपयोग करके तथ्य तालिका में एक कुंजी लुकअप करती है जैसा कि पहले देखा गया था।
क्वेरी योजना विशेष रूप से दिलचस्प है क्योंकि यह तीन विशेषताओं को जोड़ती है जिन्हें अक्सर एक प्रदर्शन अनुकूलन में खराब चीजें (पूर्ण स्कैन, कार्टेशियन उत्पाद और कुंजी लुकअप) के रूप में माना जाता है। . यह एक मान्य रणनीति है जब दो आयामों का उत्पाद बहुत छोटा होने की उम्मीद है।
कोई
StarJoinInfoनहीं है कार्टेशियन उत्पाद के लिए, लेकिन अन्य जॉइन के पास जानकारी होती है (विस्तार करने के लिए क्लिक करें):
इंडेक्स फ़िल्टर
शोप्लान स्कीमा का जिक्र करते हुए, एक अन्य
StarJoinInfoहै ऑपरेशन जिसे हमें कवर करने की आवश्यकता है:
Index Filterवैल्यू को जॉइन के साथ देखा जाता है, जिन्हें फैक्ट टेबल लाने से पहले परफॉर्म करने लायक पर्याप्त सेलेक्टिव माना जाता है। जॉइन जो पर्याप्त रूप से चयनात्मक नहीं हैं, उन्हें लाने के बाद निष्पादित किया जाएगा, और उनके पासStarJoinInfoनहीं होगा। संरचना।हमारी परीक्षण क्वेरी का उपयोग करके एक इंडेक्स फ़िल्टर देखने के लिए, हमें मिक्स में एक तीसरी जॉइन टेबल जोड़ने की जरूरत है, अब तक बनाए गए गैर-क्लस्टर किए गए फैक्ट टेबल इंडेक्स को हटाने और एक नया जोड़ने की जरूरत है:
इंडेक्स बनाएं ix_ProductKey_StoreKey_PromotionKeyON dbo.FactSales (ProductKey, StoreKey, PromotionKey); dbo से SUM (FS.SalesAmount) चुनें। .PromotionKeyWhere DS.EmployeeCount =50 और DP.ProductName LIKE N'%MP3%' और DPR.DiscountPercent <=0.1;क्वेरी योजना अब है (विस्तार करने के लिए क्लिक करें):
हीप इंडेक्स इंटरसेक्शन क्वेरी प्लान
पूर्णता के लिए, इंडेक्स इंटरसेक्शन ऑप्टिमाइज़र को फिर से लिखने में सक्षम करने के लिए आवश्यक दो गैर-अनुक्रमित अनुक्रमणिकाओं के साथ तथ्य तालिका की एक ढेर प्रतिलिपि बनाने के लिए एक स्क्रिप्ट यहां दी गई है:
चुनें * FS में dbo.FactSales से; dbo.FS (ProductKey) पर INDEX i1 बनाएं; dbo.FS (StoreKey) पर INDEX i2 बनाएं; FS से FSJOIN dbo के रूप में SUM (FS.SalesAmount) चुनें। DP पर DP के रूप में DimProduct।ProductKey =FS.ProductKeyJOIN dbo.DimStore AS DS पर DS.StoreKey =FS.Store KeyWHERE DS.EmployeeCount <=10AND N'ProductName LIKE DP। %MP3%';इस क्वेरी के लिए निष्पादन योजना में पहले की तरह ही विशेषताएं हैं, लेकिन इंडेक्स चौराहे को तथ्य तालिका क्लस्टर इंडेक्स कुंजियों के बजाय आरआईडी का उपयोग करके किया जाता है, और अंतिम फ़ेच एक आरआईडी लुकअप है (विस्तार करने के लिए क्लिक करें):
अंतिम विचार
यहां दिखाए गए अनुकूलक पुनर्लेखन उन क्वेरी पर लक्षित हैं जो अपेक्षाकृत कम संख्या में पंक्तियां लौटाती हैं एक बड़े . से तथ्य तालिका। ये पुनर्लेखन 2005 से SQL सर्वर के सभी संस्करणों में उपलब्ध हैं।
हालांकि डेटा वेयरहाउसिंग में चयनात्मक स्टार (और स्नोफ्लेक) स्कीमा प्रश्नों को गति देने का इरादा है, ऑप्टिमाइज़र इन तकनीकों को लागू कर सकता है जहाँ भी यह तालिकाओं के उपयुक्त सेट का पता लगाता है और जुड़ता है। स्टार क्वेश्चन का पता लगाने के लिए उपयोग की जाने वाली हेरिस्टिक्स काफी व्यापक हैं, इसलिए आपको
StarJoinInfoके साथ प्लान शेप का सामना करना पड़ सकता है लगभग किसी भी प्रकार के डेटाबेस में संरचनाएँ। छोटी (आयाम जैसी) तालिकाओं के संदर्भ में उचित आकार की कोई भी तालिका (जैसे कि 100 पृष्ठ या अधिक) इन अनुकूलन के लिए एक संभावित उम्मीदवार है (ध्यान दें कि स्पष्ट विदेशी कुंजियाँ नहीं हैं। आवश्यक)।आप में से जो ऐसी चीजों का आनंद लेते हैं, उनके लिए तार्किक एन-टेबल जॉइन से चुनिंदा स्टार जॉइन पैटर्न बनाने के लिए जिम्मेदार ऑप्टिमाइज़र नियम को StarJoinToIdxStrategy कहा जाता है। (सूचकांक रणनीति में शामिल हों)।