मुझे पिछले हफ्ते PGDay UK में भाग लेने का सौभाग्य मिला - एक बहुत अच्छा कार्यक्रम, उम्मीद है कि मुझे अगले साल वापस आने का मौका मिलेगा। बहुत सारी दिलचस्प बातचीत हुई, लेकिन जिसने विशेष रूप से मेरा ध्यान खींचा, वह थी परफॉर्मेस फॉर क्वेश्चन विद ग्रुपिंग विद अलेक्सी बश्तानोव।
मैंने अतीत में समान प्रदर्शन-उन्मुख वार्ताओं की एक उचित संख्या दी है, इसलिए मुझे पता है कि बेंचमार्क परिणामों को समझने योग्य और दिलचस्प तरीके से प्रस्तुत करना कितना मुश्किल है, और एलेक्सी ने बहुत अच्छा काम किया, मुझे लगता है। इसलिए यदि आप डेटा एकत्रीकरण (यानी बीआई, विश्लेषिकी, या इसी तरह के कार्यभार) से निपटते हैं, तो मैं स्लाइड्स के माध्यम से जाने की सलाह देता हूं और यदि आपको किसी अन्य सम्मेलन में बात करने का मौका मिलता है, तो मैं ऐसा करने की अत्यधिक अनुशंसा करता हूं।
लेकिन एक बिंदु है जहां मैं इस बात से असहमत हूं, हालांकि। कई जगहों पर चर्चा ने सुझाव दिया कि आपको आम तौर पर हैशएग्रीगेट पसंद करना चाहिए, क्योंकि प्रकार धीमे होते हैं।
मैं इसे थोड़ा भ्रामक मानता हूं, क्योंकि हैशएग्रेगेट का विकल्प ग्रुपएग्रीगेट है, सॉर्ट नहीं। तो अनुशंसा मानती है कि प्रत्येक GroupAggregate में एक नेस्टेड सॉर्ट होता है, लेकिन यह बिल्कुल सच नहीं है। GroupAggregate को सॉर्ट किए गए इनपुट की आवश्यकता होती है, और एक स्पष्ट सॉर्ट ऐसा करने का एकमात्र तरीका नहीं है - हमारे पास इंडेक्सस्कैन और इंडेक्सऑनलीस्कैन नोड्स भी हैं, जो सॉर्ट की लागत को खत्म करते हैं और सॉर्ट किए गए पथ (विशेष रूप से इंडेक्सऑनलीस्कैन) से जुड़े अन्य लाभों को रखते हैं।
मुझे यह दिखाने दें कि (IndexOnlyScan+GroupAggregate) HashAggregate और (Sort+GroupAggregate) दोनों की तुलना में कैसा प्रदर्शन करता है - माप के लिए मैंने जो स्क्रिप्ट इस्तेमाल की है, वह यहाँ है। यह चार सरल तालिकाओं का निर्माण करता है, प्रत्येक में 100M पंक्तियाँ और "branch_id" कॉलम (हैश तालिका के आकार का निर्धारण) में अलग-अलग संख्या में समूह होते हैं। सबसे छोटे समूह में 10k समूह होते हैं
-- 10k समूहों के साथ तालिका तालिका बनाएं t_10000 (branch_id bigint, राशि संख्यात्मक); t_10000 में डालें mod(i, 10000), random() से generate_series(1,100000000) s(i);
और तीन अतिरिक्त तालिकाओं में 100k, 1M और 5M समूह हैं। आइए डेटा एकत्र करने वाली इस सरल क्वेरी को चलाएं:
शाखा चुनेंऔर फिर डेटाबेस को तीन अलग-अलग योजनाओं का उपयोग करने के लिए मनाएं:
1) हैशएग्रीगेट
सेट इनेबल_सॉर्ट =ऑफ;सेट इनेबल_हैशग =ऑन; EXPLAIN सेलेक्ट ब्रांच_आईडी, एसयूएम (राशि) t_10000 ग्रुप बाय 1 से; प्रश्न योजना ------------------------------------------------- ---------------------------- हैशएग्रीगेट (लागत =2136943.00..2137067.99 पंक्तियाँ =9999 चौड़ाई =40) समूह कुंजी:शाखा_आईडी -> Seq t_10000 पर स्कैन करें (लागत=0.00..1636943.00 पंक्तियाँ=100000000 चौड़ाई=19)(3 पंक्तियाँ)2) GroupAggregate (सॉर्ट के साथ)
SET enable_sort =on;SET enable_hashagg =off; EXPLAIN सेलेक्ट ब्रांच_आईडी, SUM (राशि) t_10000 GROUP BY 1 से; प्रश्न योजना ------------------------------------------------- ----------------------------- ग्रुप एग्रीगेट (लागत =16975438.38..17725563.37 पंक्तियाँ =9999 चौड़ाई =40) समूह कुंजी:शाखा_आईडी -> क्रमबद्ध करें (लागत =16975438.38..17225438.38 पंक्तियाँ =100000000 चौड़ाई =19) क्रमबद्ध कुंजी:शाखा_आईडी -> t_10000 पर सेक स्कैन (लागत =0.00..1636943.00 पंक्तियाँ =100000000 ...) (5 पंक्तियाँ)3) GroupAggregate (IndexOnlyScan के साथ)
SET enable_sort =on;SET enable_hashagg =off; t_10000 (branch_id, राशि) पर इंडेक्स बनाएं; EXPLAIN सेलेक्ट ब्रांच_आईडी, SUM (राशि) t_10000 ग्रुप बाय 1 से; प्रश्न योजना ------------------------------------------------- -------------------------- ग्रुप एग्रीगेट (लागत =0.57..3983129.56 पंक्तियाँ =9999 चौड़ाई =40) समूह कुंजी:शाखा_आईडी -> केवल सूचकांक स्कैन t_10000 पर t_10000_branch_id_amount_idx का उपयोग करना (लागत =0.57..3483004.57 पंक्तियाँ =100000000 चौड़ाई =19) (3 पंक्तियाँ)परिणाम
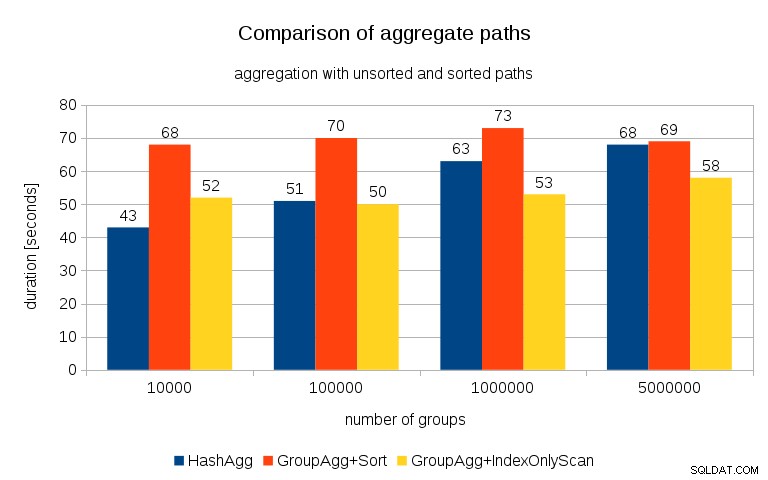
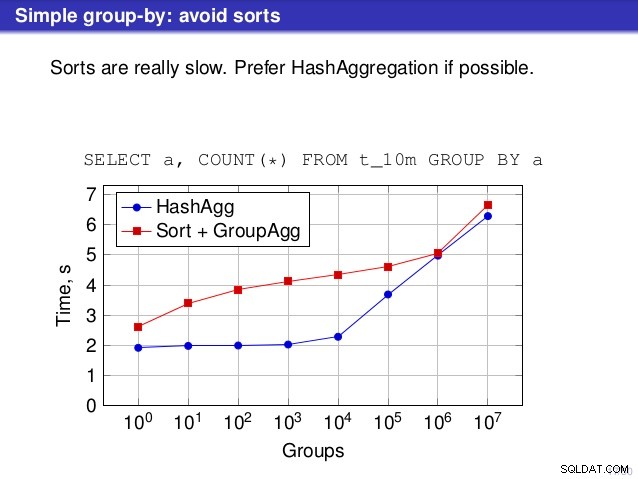
सभी तालिकाओं पर प्रत्येक योजना के लिए समय मापने के बाद, परिणाम इस तरह दिखते हैं:
छोटी हैश तालिकाओं के लिए (L3 कैश में फ़िट होना, जो इस मामले में 16MB है), हैशएग्रीगेट पथ दोनों क्रमबद्ध पथों की तुलना में स्पष्ट रूप से तेज़ है। लेकिन बहुत जल्द GroupAgg+IndexOnlyScan उतना ही तेज़ या उससे भी तेज़ हो जाता है - यह कैश दक्षता के कारण होता है, जो GroupAggregate का मुख्य लाभ है। जबकि हैशएग्रीगेट को एक बार में पूरी हैश तालिका को मेमोरी में रखने की आवश्यकता होती है, ग्रुपएग्रीगेट को केवल अंतिम समूह को रखने की आवश्यकता होती है। और आप जितनी कम मेमोरी का उपयोग करते हैं, उसके L3 कैश में फिट होने की संभावना उतनी ही अधिक होती है, जो कि नियमित RAM की तुलना में मोटे तौर पर परिमाण का एक क्रम है (L1/L2 कैश के लिए अंतर और भी बड़ा है)।
इसलिए, हालांकि इंडेक्सऑनलीस्कैन के साथ काफी ओवरहेड जुड़ा हुआ है (10k मामले के लिए यह हैशएग्रेगेट पथ की तुलना में लगभग 20% धीमा है), क्योंकि हैश तालिका में एल3 कैश हिट अनुपात तेजी से गिरता है और अंतर अंततः ग्रुपएग्रीगेट को तेज बनाता है। और अंतत:यहां तक कि GroupAggregate+Sort भी HashAggregate पथ के बराबर हो जाता है।
आप तर्क दे सकते हैं कि आपके डेटा में आम तौर पर काफी कम समूह होते हैं, और इस प्रकार हैश तालिका हमेशा L3 कैश में फिट होगी। लेकिन विचार करें कि L3 कैश CPU पर चलने वाली सभी प्रक्रियाओं और क्वेरी योजना के सभी भागों द्वारा साझा किया जाता है। इसलिए हालांकि वर्तमान में हमारे पास प्रति सॉकेट ~20MB L3 कैश है, आपकी क्वेरी को केवल उसी का एक हिस्सा मिलेगा, और वह बिट आपकी (संभवतः काफी जटिल) क्वेरी में सभी नोड्स द्वारा साझा किया जाएगा।
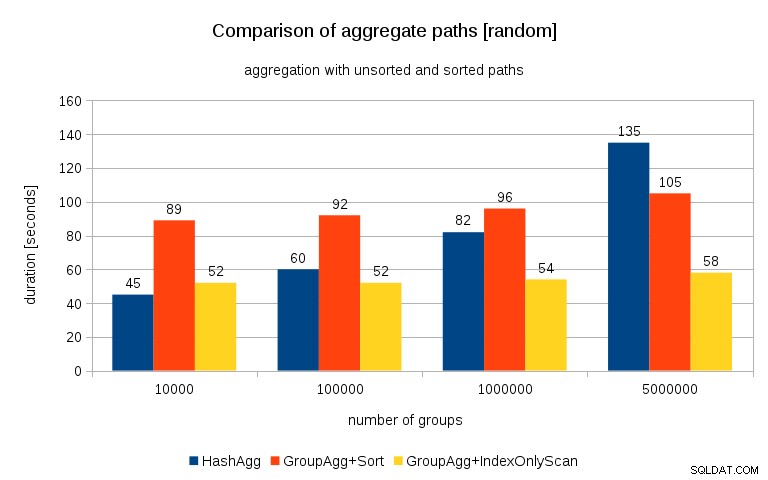
2016/07/26 अपडेट करें :जैसा कि पीटर जियोघेगन की टिप्पणियों में बताया गया है, जिस तरह से डेटा उत्पन्न किया गया था, वह शायद सहसंबंध में परिणाम देता है - मूल्यों (या बल्कि मूल्यों का हैश) नहीं, बल्कि स्मृति आवंटन। मैंने ठीक से यादृच्छिक डेटा के साथ प्रश्नों को दोहराया है, यानी कर रहा हूं
t_10000 में डालें (10000*random())::bigint, random() से generate_series(1,100000000) s(i);के बजाय
जनरेट_सीरीज(1,100000000) s(i) से t_10000 सेलेक्ट मॉड (i, 10000), रैंडम () में डालें;और परिणाम इस तरह दिखते हैं:
पिछले चार्ट के साथ इसकी तुलना करते हुए, मुझे लगता है कि यह बहुत स्पष्ट है कि परिणाम क्रमबद्ध पथों के पक्ष में और भी अधिक हैं, खासकर 5M समूहों के साथ डेटा सेट के लिए। 5M डेटा सेट यह भी दर्शाता है कि स्पष्ट सॉर्ट वाला GroupAgg, HashAgg से तेज़ हो सकता है।
सारांश
जबकि हैशएग्रीगेट स्पष्ट सॉर्ट के साथ ग्रुपएग्रीगेट की तुलना में तेज़ है (हालांकि, मुझे यह कहने में संकोच हो रहा है कि यह हमेशा ऐसा ही होता है), इंडेक्सऑनलीस्कैन के साथ ग्रुपएग्रीगेट का उपयोग तेजी से हैशएग्रेगेट की तुलना में बहुत तेज़ बना सकता है।
बेशक, आपको सीधे सटीक योजना नहीं चुननी है - योजनाकार को यह आपके लिए करना चाहिए। लेकिन आप (ए) इंडेक्स बनाकर और (बी)
work_memसेट करके चयन प्रक्रिया को प्रभावित करते हैं . यही कारण है कि कभी-कभीwork_memको कम कर देते हैं (औरmaintenance_work_mem) मूल्यों के परिणामस्वरूप बेहतर प्रदर्शन होता है।अतिरिक्त अनुक्रमणिका मुक्त नहीं हैं, हालांकि - उनमें CPU समय (नया डेटा सम्मिलित करते समय), और डिस्क स्थान दोनों खर्च होते हैं। इंडेक्सऑनलीस्कैन के लिए डिस्क स्थान की आवश्यकताएं काफी महत्वपूर्ण हो सकती हैं क्योंकि इंडेक्स को क्वेरी द्वारा संदर्भित सभी कॉलमों को शामिल करने की आवश्यकता होती है, और नियमित इंडेक्सस्कैन आपको समान प्रदर्शन नहीं देगा क्योंकि यह टेबल के खिलाफ बहुत सारे यादृच्छिक I/O उत्पन्न करता है (सभी को समाप्त करना) संभावित लाभ)।
एक और अच्छी विशेषता प्रदर्शन की स्थिरता है - ध्यान दें कि समूहों की संख्या के आधार पर हैशएग्रीगेट समय कैसे मौका देता है, जबकि ग्रुपएग्रीगेट पथ ज्यादातर समान प्रदर्शन करते हैं।