SQL सर्वर अनुक्रमणिका अवलोकन
SQL सर्वर प्रदर्शन ट्यूनिंग और क्वेरी एन्हांसमेंट के बारे में बात करते समय, SQL सर्वर इंडेक्स पर विचार करने वाली पहली चीज़ है। यह अनुरोधित पंक्तियों तक त्वरित पहुँच प्रदान करके अंतर्निहित तालिकाओं से डेटा पढ़ने में तेजी लाने का कार्य करता है। इस प्रकार, इसे तालिका के सभी रिकॉर्ड को स्कैन करने की आवश्यकता नहीं होगी।
SQL सर्वर इंडेक्स इंडेक्स की बी-ट्री संरचना के कारण उन तेज़ खोज क्षमताओं को प्रदान करता है। यह संरचना इंडेक्स कुंजी के आधार पर तालिका पंक्तियों के माध्यम से जल्दी से आगे बढ़ना और अनुरोधित रिकॉर्ड को एक बार में पुनर्प्राप्त करना संभव बनाती है। इसे पूरी तालिका पढ़ने की आवश्यकता नहीं होगी।
SQL सर्वर अनुक्रमणिका के प्रकार
मुख्य प्रकारों में से, हम संकुल और गैर-संकुल अनुक्रमणिका पर ध्यान देते हैं।
संकुलित अनुक्रमणिका क्लस्टर इंडेक्स कुंजी मानों के अनुसार डेटा पृष्ठों में वास्तविक डेटा को सॉर्ट करता है। यह डेटा को इंडेक्स के 'लीफ' स्तर पर स्टोर करता है, जिससे प्रत्येक टेबल पर केवल एक क्लस्टर इंडेक्स बनाने की संभावना सुनिश्चित होती है। जब हीप टेबल पर प्राथमिक कुंजी बाधा दिखाई देती है, तो क्लस्टर इंडेक्स अपने आप बन जाता है।
गैर-संकुल अनुक्रमणिका मुख्य तालिका में शेष पंक्ति स्तंभों के लिए अनुक्रमणिका कुंजी मान और एक सूचक होता है। यह सूचकांक का 'पत्ती' स्तर है, जिसमें प्रत्येक टेबल पर 999 गैर-संकुल सूचकांक बनाने की क्षमता है।
यदि आपकी तालिका में कोई संकुल अनुक्रमणिका नहीं बनाई गई है, तो तालिका को 'हीप तालिका' कहा जाता है। इस तरह की तालिका में पृष्ठों के अंदर डेटा क्रम निर्दिष्ट करने और पृष्ठों की सॉर्टिंग और लिंकिंग को एक साथ जोड़ने के लिए कोई मानदंड नहीं है।
जब उस टेबल पर एक क्लस्टर इंडेक्स बनाया जाता है, तो हम सॉर्ट की गई टेबल को क्लस्टर्ड टेबल कहते हैं।
SQL सर्वर द्वारा प्रदान किए गए अन्य प्रकार के इंडेक्स भी हैं:
- अद्वितीय अनुक्रमणिका स्तंभ मानों की विशिष्टता को लागू करती है;
- कवरिंग इंडेक्स में क्वेरी द्वारा अनुरोधित सभी कॉलम शामिल हैं;
- संयुक्त अनुक्रमणिका में अनुक्रमणिका कुंजी में एकाधिक स्तंभ होते हैं;
- अन्य विशेष इंडेक्स प्रकार हैं XML, Spatial, और Columnstore इंडेक्स।
SQL सर्वर इंडेक्स का लाभ यह है कि यह क्वेरी के प्रदर्शन को बढ़ाता है। हालाँकि, यह तभी काम करता है जब केवल अनुक्रमणिका सही हो। यदि आप इसे गलत डिज़ाइन करते हैं, तो यह प्रश्नों के प्रदर्शन को नकारात्मक रूप से प्रभावित करेगा और बेकार इंडेक्स को स्टोर और बनाए रखने के लिए SQL सर्वर संसाधनों का उपभोग करेगा।
सभी समस्याओं को ठीक करने वाला सर्वोत्तम सूचकांक चुनना कोई आसान काम नहीं है। एक नया सूचकांक जोड़ने से डेटा पुनर्प्राप्ति प्रक्रिया में तेजी आ सकती है, लेकिन यह डेटा संशोधन प्रक्रियाओं को धीमा कर देती है। अंतर्निहित तालिका में किया गया कोई भी परिवर्तन डेटा को सुसंगत रखने के लिए सभी संबंधित अनुक्रमणिकाओं पर सीधे प्रतिबिंबित होता है।
यही कारण है कि आपको नए सूचकांक को उत्पादन वातावरण में बनाने से पहले उसके प्रभाव का अध्ययन और परीक्षण करना चाहिए। इसे उत्पादन परिवेश में परिनियोजित करने के बाद इसके प्रभाव और उपयोग की निगरानी करना भी आवश्यक है।
नई SQL सर्वर अनुक्रमणिका डिज़ाइन करते समय विचार करने योग्य कारक
पहला कारक है डेटाबेस वर्कलोड प्रकार . मान लीजिए कि हम बड़ी संख्या में लेखन कार्यों के साथ एक OLTP कार्यभार से निपटते हैं। इसके लिए न्यूनतम संभव संख्या में अनुक्रमणिका की आवश्यकता होती है। एक अन्य मामला एक OLAP वर्कलोड है जिसमें कई रीड ऑपरेशन होते हैं - यह डेटा पुनर्प्राप्ति को गति देने के लिए अधिक से अधिक इंडेक्स की मांग करेगा।
साथ ही, आपको टेबल आकार . को भी देखना होगा . SQL सर्वर इंजन उस छोटी तालिका से डेटा पुनर्प्राप्ति के लिए सर्वोत्तम अनुक्रमणिका चुनने पर समय और संसाधनों को बर्बाद करने के बजाय सीधे अंतर्निहित तालिका को स्कैन करना पसंद करता है।
एक बार जब आप उस तालिका पर एक अनुक्रमणिका बनाने का निर्णय ले लेते हैं, तो आपको अपनी क्वेरी प्रस्तुत करने के लिए अनुक्रमणिका प्रकार की पहचान करने की आवश्यकता होती है . वहां, आप अनुक्रमणिका कुंजी में जोड़े गए कॉलम निर्दिष्ट करते हैं। आधार स्तंभ डेटा प्रकार हैं और क्वेरी में स्थिति विधेय और शर्तों में शामिल होती है।
इन कारकों को सही क्रम में सर्वोत्तम डेटा पुनर्प्राप्ति प्रदर्शन की गारंटी देनी चाहिए, और सूचकांक को यथासंभव छोटा और सरल रखना चाहिए।
नई अनुक्रमणिका डिज़ाइन करते समय विचार करने वाला एक अन्य कारक अनुक्रमणिका संग्रहण . है . एक अलग फ़ाइल समूह और डिस्क ड्राइव पर गैर-संकुल अनुक्रमणिका बनाने की अनुशंसा की जाती है। इस तरह, आप डेटाबेस डेटा फ़ाइलों से अनुक्रमणिका डेटा पृष्ठों में किए गए I/O संचालन को अलग करते हैं।
इंडेक्स सेट करने पर विचार करें फिलफैक्टर , जो डेटा से भरे प्रत्येक पत्ती-स्तरीय पृष्ठ पर स्थान का प्रतिशत निर्धारित करता है (मान डिफ़ॉल्ट 0 या 100 प्रतिशत से भिन्न होता है)। लक्ष्य नए सम्मिलित या अद्यतन किए गए रिकॉर्ड के लिए प्रत्येक अनुक्रमणिका डेटा पृष्ठ में स्थान छोड़ना है। यह पृष्ठ विभाजन की घटना को भी कम करता है जिससे अनुक्रमणिका विखंडन की समस्या हो सकती है।
सूचकांक प्रबंधन
SQL सर्वर इंडेक्स के साथ क्वेरी के प्रदर्शन को बढ़ाने में डेटाबेस एडमिनिस्ट्रेटर की भूमिका इंडेक्स बनाने तक सीमित नहीं है। आपको इसकी गुणवत्ता की पहचान करने के लिए सूचकांक के उपयोग की लगातार निगरानी करनी चाहिए। इसके अलावा, हमें विखंडन के मुद्दों को ठीक करने के लिए नियमित रूप से सूचकांक को बनाए रखने की आवश्यकता है।
SQL सर्वर प्रबंधन स्टूडियो, अपनी मजबूत रिपोर्टिंग कार्यक्षमता के साथ, डेटाबेस व्यवस्थापकों को सबसे उपयोगी आँकड़े डेटा प्रदान करता है। इनमें से एक अंतर्निहित रिपोर्ट है सूचकांक उपयोग के आंकड़े :
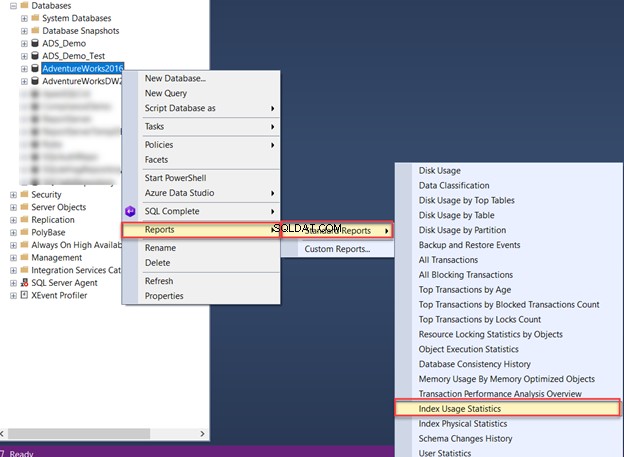
इंडेक्स यूसेज स्टैटिस्टिक्स रिपोर्ट बताती है कि कैसे डेटाबेस इंडेक्स का उपयोग इस रूप में किया जाता है:
- खोजता है :किसी विशिष्ट पंक्ति को खोजने के लिए SQL इंजन द्वारा अनुक्रमणिका का कितनी बार उपयोग किया जाता है।
- स्कैन करें :SQL इंजन द्वारा इंडेक्स लीफ पेजों को स्कैन किए जाने की संख्या।
- लुकअप :गैर-संकुल अनुक्रमणिका में सूचीबद्ध नहीं किए गए शेष स्तंभों को पुनः प्राप्त करने के लिए एक गैर-संकुल अनुक्रमणिका को क्लस्टर अनुक्रमणिका के रूप में उपयोग किए जाने की संख्या।
- अपडेट :इंडेक्स डेटा को कितनी बार संशोधित किया गया है।
ध्यान दें कि इंडेक्स बनाने का प्राथमिक उद्देश्य इंडेक्स सीक ऑपरेशन करना है, जैसा कि नीचे दिखाया गया है:
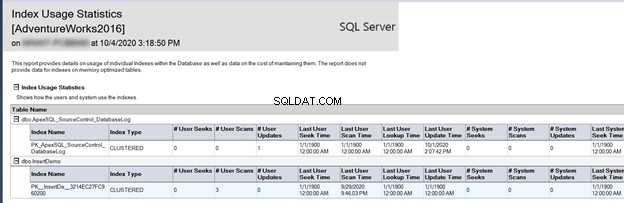
पिछली रिपोर्ट यह निर्दिष्ट करने में महत्वपूर्ण रूप से मदद करती है कि SQL सर्वर डेटा पुनर्प्राप्ति प्रक्रिया में तेजी लाने के लिए इन अनुक्रमणिकाओं का लाभ उठाता है या नहीं। अगर यह पता चलता है कि कोई विशेष इंडेक्स उस तरह का प्रदर्शन नहीं करता जैसा उसे करना चाहिए, तो उसे छोड़ दें, और इसे एक बेहतर इंडेक्स से बदल दें।
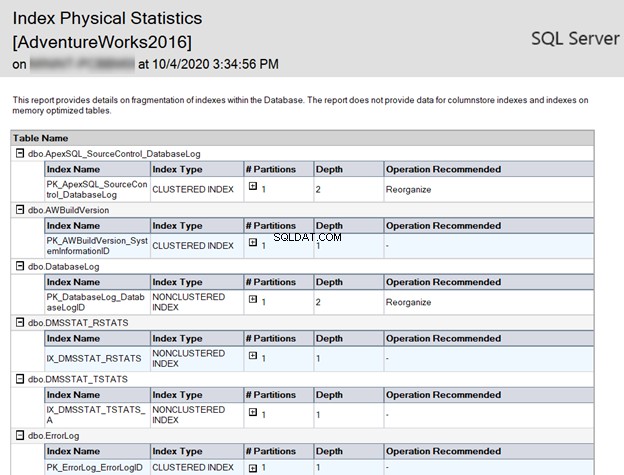
SSMS द्वारा प्रदान की गई दूसरी रिपोर्ट भौतिक सांख्यिकी सूचकांक . है . यह प्रत्येक अनुक्रमणिका विभाजन पर सूचकांक विखंडन प्रतिशत के बारे में सांख्यिकीय जानकारी देता है, प्रत्येक सूचकांक विभाजन पर पृष्ठों की संख्या के साथ।
यह भी अनुशंसा करता है कि फ़्रेग्मेंटेशन प्रतिशत के अनुसार, उस अनुक्रमणिका का पुनर्निर्माण या पुनर्व्यवस्थित करके अनुक्रमणिका फ़्रेग्मेंटेशन समस्याओं को कैसे ठीक किया जाए, जैसा कि नीचे दिखाया गया है:
रिपोर्ट द्वारा प्रदान की गई सिफारिशों को लागू करने के लिए, आप प्रत्येक इंडेक्स के लिए इंडेक्स डीफ़्रेग्मेंटेशन कमांड चला सकते हैं। या, आप इंडेक्स को सर्वोत्तम तरीके से बनाए रखने के लिए SSMS का उपयोग करके एक रखरखाव योजना बना सकते हैं।
dbForge अनुक्रमणिका प्रबंधक
dbForge अनुक्रमणिका प्रबंधक एक SSMS ऐड-इन है, जो SQL सर्वर अनुक्रमणिका फ़्रेग्मेंटेशन समस्याओं का पता लगाने और उन्हें ठीक करने के लिए कार्य करता है।
यह एक केंद्रीकृत उपकरण भी है, जो पूरे डेटाबेस में सूचकांक विखंडन प्रतिशत का पता लगाने की क्षमता प्रदान करता है। आप एक अनुक्रमणिका पुनर्निर्माण करके इन समस्याओं को ठीक कर सकते हैं। एक अन्य तरीका उस सूचकांक की विखंडन गंभीरता के आधार पर संचालन को पुनर्गठित करना है। अन्य विकल्पों में, इंडेक्स-संबंधित कमांड निष्पादन के लिए टी-एसक्यूएल स्क्रिप्ट पीढ़ी है, बाद के संदर्भ के लिए इंडेक्स विश्लेषण परिणाम निर्यात करना, और इंडेक्स रखरखाव कार्यों को स्वचालित करने के लिए कमांड लाइन इंटरफेस का उपयोग करना।
dbForge अनुक्रमणिका प्रबंधक Devart डाउनलोड पृष्ठ पर उपलब्ध है। आप स्ट्रेट-फॉरवर्ड इंस्टॉलेशन विज़ार्ड का उपयोग करके इसे अपनी मशीन में इंस्टॉल कर सकते हैं। सफल स्थापना के बाद, यह ऐड-इन उपयोग के लिए तैयार है।
SSMS में इसका उपयोग करने के लिए, डेटाबेस पर राइट-क्लिक करें और इंडेक्स फ़्रेग्मेंटेशन प्रबंधित करें चुनें अनुक्रमणिका प्रबंधक सूची से:
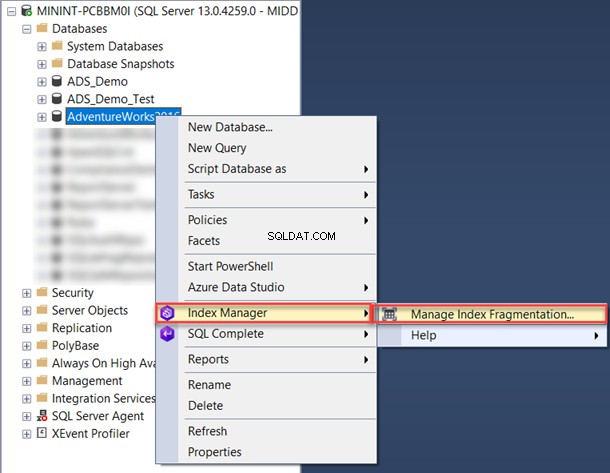
अनुक्रमणिका प्रबंधक विंडो से, आप उस डेटाबेस नाम को फ़िल्टर कर सकते हैं जिसमें आपकी रुचि है।
पुन:विश्लेषण करें . पर क्लिक करें चयनित डेटाबेस के लिए अनुक्रमणिका विखंडन जाँच करने के लिए। यह स्वचालित रूप से इस प्रक्रिया के दौरान चयनित डेटाबेस के तहत बनाए गए सभी इंडेक्स के लिए इंडेक्स विखंडन के आंकड़े दिखाता है।
इंडेक्स मैनेजर टूल, फ़्रेग्मेंटेशन प्रतिशत के आधार पर इंडेक्स फ़्रेग्मेंटेशन समस्याओं को ठीक करने के लिए कार्रवाई की भी सिफारिश करता है:
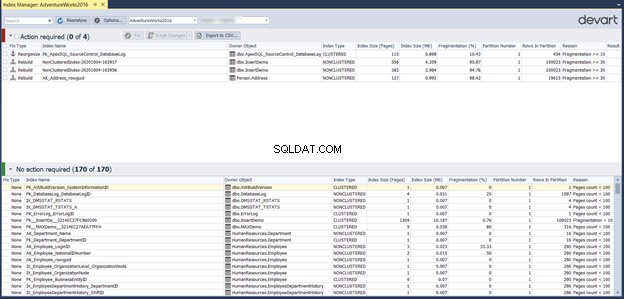
पिछली विंडो में आवश्यक क्रियाएँ अनुभाग के अंतर्गत अनुक्रमणिका जाँचने से क्रिया सूची को CSV रिपोर्ट के रूप में निर्यात करना संभव हो जाता है। यह आपको उस पृष्ठ से सीधे समस्याग्रस्त अनुक्रमणिका को पुनर्व्यवस्थित या पुनर्निर्माण करके सुझाए गए सुधार करने की अनुमति देता है या इसे बाद में करने के लिए एक स्क्रिप्ट उत्पन्न करता है:
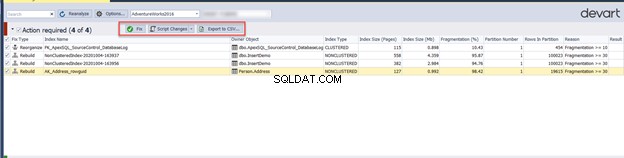
हमारे परिदृश्य में इंडेक्स फ़्रेग्मेंटेशन फिक्स इस प्रकार होगा:
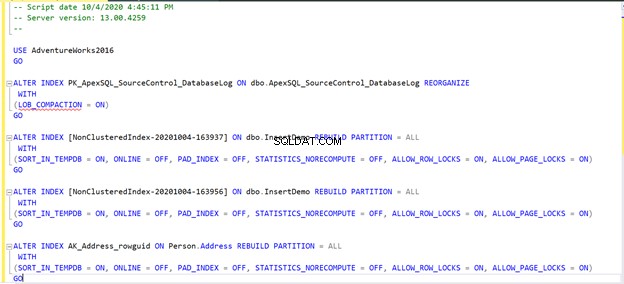
यदि आप पिछली स्क्रिप्ट चलाते हैं या ठीक करें . पर क्लिक करते हैं विकल्प, और फिर पुन:विश्लेषण करें परिणाम, आप देखते हैं कि विखंडन मुद्दा सीधे तय किया गया है:
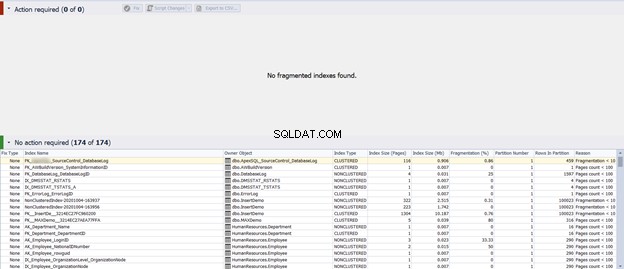
इस तरह, हम इंडेक्स फ्रैगमेंटेशन मुद्दों का विश्लेषण और पहचान करने के लिए डीबीफोर्ज इंडेक्स मैनेजर का लाभ उठाते हैं और फिर उन्हें उसी स्थान से सीधे रिपोर्ट या ठीक करते हैं।
उपयोगी टूल
dbForge इंडेक्स मैनेजर SSMS में स्मार्ट इंडेक्स फिक्सिंग और इंडेक्स फ़्रेग्मेंटेशन लाता है। टूल आपको इंडेक्स फ़्रेग्मेंटेशन के आंकड़े तेज़ी से इकट्ठा करने और रखरखाव की आवश्यकता वाले डेटाबेस का पता लगाने की अनुमति देता है। आप विज़ुअल मोड में SQL सर्वर इंडेक्स को तुरंत पुनर्निर्माण और पुनर्व्यवस्थित कर सकते हैं या भविष्य में उपयोग के लिए SQL स्क्रिप्ट उत्पन्न कर सकते हैं। SQL सर्वर के लिए dbForge अनुक्रमणिका प्रबंधक बिना अधिक प्रयास के आपके प्रदर्शन को महत्वपूर्ण रूप से बढ़ावा देगा।