इस लेख में, हम उन विशिष्ट त्रुटियों पर चर्चा करेंगे जो नौसिखिया डेवलपर्स को टी-एसक्यूएल कोड डिजाइन करते समय सामना करना पड़ सकता है। इसके अलावा, हम सर्वोत्तम प्रथाओं और कुछ उपयोगी युक्तियों पर एक नज़र डालेंगे जो SQL सर्वर के साथ काम करते समय आपकी मदद कर सकती हैं, साथ ही प्रदर्शन को बेहतर बनाने के लिए समाधान भी।
सामग्री:
1. डेटा प्रकार
2. *
3. उपनाम
4. कॉलम क्रम
5. NOT IN बनाम NULL
6. दिनांक प्रारूप
7. दिनांक फ़िल्टर
8. गणना
9. रूपांतरित करें
10. पसंद और दबा हुआ सूचकांक
11. यूनिकोड बनाम एएनएसआई
12. COLLATE
13. बाइनरी कोलेट
14. कोड शैली
15. [var]चार
16. डेटा की लंबाई
17. ISNULL बनाम COALESCE
18. गणित
19. यूनियन बनाम यूनियन ऑल
20. फिर से पढ़ें
21. सबक्वेरी
22. मामला जब
23. अदिश फंक
24. दृश्य
25. कर्सर
26. STRING_CONCAT
27. एसक्यूएल इंजेक्शन
डेटा प्रकार
SQL सर्वर के साथ काम करते समय हमारे सामने मुख्य समस्या डेटा प्रकारों का गलत चुनाव है।
मान लें कि हमारे पास दो समान टेबल हैं:
Declare @ Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) ,birthDate VARCHAR(20)) INSERT INTO@Employees1VALUES (123, 'YES', '2012-09-01')Declare@Employees2 TABLE (कर्मचारी आईडी INT प्राथमिक कुंजी , IsMale BIT , जन्मतिथि दिनांक) @Employees2VALUES (123, 1, '2012-09-01') में डालें
अंतर क्या है, यह जांचने के लिए एक क्वेरी निष्पादित करें:
DECLARE @BirthDate DATE ='2012-09-01' चयन करें * @ Employees1 से जहां जन्मतिथि =@BirthDateSELECT * @ Employees2 से जहां जन्मतिथि =@BirthDate
पहले मामले में, डेटा प्रकार जितना हो सकता है उससे अधिक बेमानी हैं। हमें YES/NO . के रूप में थोड़ा मान क्यों स्टोर करना चाहिए? पंक्ति? हमें एक तारीख को एक पंक्ति के रूप में क्यों स्टोर करना चाहिए? हमें BIGINT . का उपयोग क्यों करना चाहिए INT . के बजाय तालिका में कर्मचारियों के लिए ?
यह निम्नलिखित कमियों की ओर ले जाता है:
- टेबल्स डिस्क पर अधिक जगह ले सकती हैं;
- हमें और पेज पढ़ने और बफ़रपूल में और डेटा डालने की ज़रूरत है डेटा को संभालने के लिए।
- खराब प्रदर्शन।
*
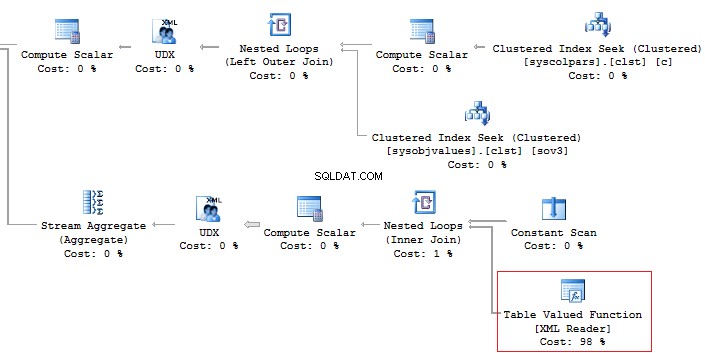
मुझे उस स्थिति का सामना करना पड़ा है जब डेवलपर्स एक टेबल से सभी डेटा पुनर्प्राप्त करते हैं, और फिर क्लाइंट-साइड पर, DataReader का उपयोग करते हैं केवल आवश्यक फ़ील्ड का चयन करने के लिए। मैं इस दृष्टिकोण का उपयोग करने की अनुशंसा नहीं करता:
AdventureWorks2014GOSET सांख्यिकी समय का उपयोग करें, IO ONSELECT *Person सेक्वेरी निष्पादन समय में महत्वपूर्ण अंतर होगा। इसके अलावा, कवरिंग इंडेक्स कई तार्किक पठन को कम कर सकता है।
तालिका 'व्यक्ति'। स्कैन गिनती 1, तार्किक 3819 पढ़ता है, भौतिक 3 पढ़ता है, ... SQL सर्वर निष्पादन समय:CPU समय =31 एमएस, बीता हुआ समय =1235 एमएस। तालिका 'व्यक्ति'। स्कैन काउंट 1, लॉजिकल रीड्स 109, फिजिकल रीड्स 1, ... SQL सर्वर एक्ज़ीक्यूशन टाइम्स:CPU टाइम =0 ms, बीता हुआ समय =227 ms।उपनाम
आइए एक टेबल बनाएं:
AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') नॉट न्यूल ड्रॉप टेबल सेल्स है।मान लें कि हमारे पास एक क्वेरी है जो दोनों तालिकाओं में समान पंक्तियों की मात्रा लौटाती है:
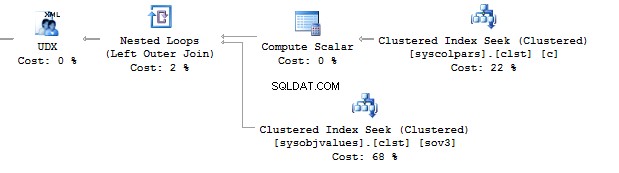
बिक्री से COUNT_BIG(*) चुनें.मुद्रा जहां करेंसी कोड IN (बिक्री से करेंसी कोड चुनें.उपयोगकर्ता करेंसी)जब तक कोई Sales.UserCurrency में कॉलम का नाम नहीं बदलता, तब तक सब कुछ अपेक्षित रूप से काम करता रहेगा। तालिका:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'कोड', 'COLUMN'इसके बाद, हम एक क्वेरी निष्पादित करेंगे और देखेंगे कि हमें Sales.Curency में सभी पंक्तियां मिलती हैं। तालिका, 1 पंक्ति के बजाय। एक निष्पादन योजना बनाते समय, बाध्यकारी चरण पर, SQL सर्वर Sales.UserCurrency, के कॉलम की जांच करेगा। यह नहीं मिलेगा मुद्रा कोड वहां जाता है और तय करता है कि यह कॉलम बिक्री.मुद्रा . से संबंधित है टेबल। उसके बाद, एक अनुकूलक मुद्रा कोड =मुद्रा कोड . को छोड़ देगा हालत।
इस प्रकार, मैं उपनामों का उपयोग करने की सलाह देता हूं:
बिक्री से COUNT_BIG(*) चुनें.मुद्रा cWHERE c.CurrencyCode IN (बिक्री से u.CurrencyCode चुनें.UserCurrency u)स्तंभ क्रम
मान लें कि हमारे पास एक टेबल है:
अगर OBJECT_ID('dbo.DatePeriod') न्यूल ड्रॉप टेबल नहीं है dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod (StartDate DATE , EndDate DATE)हम हमेशा कॉलम ऑर्डर के बारे में जानकारी के आधार पर वहां डेटा डालते हैं।
dbo.DatePeriodचुनें '2015-01-01', '2015-01-31' में डालेंमान लें कि कोई व्यक्ति स्तंभों का क्रम बदल देता है:
टेबल dbo.DatePeriod बनाएं (EndDate DATE , StartDate DATE)डेटा एक अलग क्रम में डाला जाएगा। इस मामले में, INSERT कथन में स्पष्ट रूप से कॉलम निर्दिष्ट करना एक अच्छा विचार है:
dbo.DatePeriod में INSERT करें (StartDate, EndDate)चुनें '2015-01-01', '2015-01-31'यहाँ एक और उदाहरण है:
शीर्ष चुनें(1) *dbo.DatePeriodORDER BY 2 DESCहम किस कॉलम पर डेटा ऑर्डर करने जा रहे हैं? यह किसी तालिका में स्तंभ क्रम पर निर्भर करेगा। यदि कोई आदेश बदलता है तो हमें गलत परिणाम मिलते हैं।
NOT IN बनाम NULL
आइए बात करते हैं NOT IN . के बारे में बयान।
उदाहरण के लिए, आपको कुछ प्रश्न लिखने की आवश्यकता है:पहली तालिका से रिकॉर्ड लौटाएं, जो दूसरी तालिका और वीज़ा पद्य में मौजूद नहीं है। आमतौर पर, जूनियर डेवलपर IN . का उपयोग करते हैं और में नहीं :
घोषित @t1 तालिका (t1 INT, अद्वितीय क्लस्टर (t1)) @t1 मानों में सम्मिलित करें (1), (2) घोषित @t2 तालिका (t2 INT, अद्वितीय क्लस्टर (t2)) @t2 मानों में सम्मिलित करें (1 )चुनें *@t1 से जहां t1 अंदर नहीं है (@t2 से t2 चुनें) चुनें * @t1 से चुनें जहां t1 IN (@t2 से t2 चुनें)पहली क्वेरी 2 लौटा, दूसरी वाली - 1. इसके अलावा, हम दूसरी तालिका में एक और मान जोड़ेंगे - NULL :
INSERT INTO @t2 VALUES (1), (NULL)नहीं में . के साथ क्वेरी निष्पादित करते समय , हमें कोई परिणाम नहीं मिलेगा। IN क्यों काम करता है और नहीं में क्यों? कारण यह है कि SQL सर्वर TRUE . का उपयोग करता है , गलत , और अज्ञात डेटा की तुलना करते समय तर्क।
क्वेरी निष्पादित करते समय, SQL सर्वर निम्नलिखित तरीके से IN स्थिति की व्याख्या करता है:
एक IN (1, NULL) ==a=1 या a=NULLमें नहीं :
एक NOT IN (1, NULL) ==a<>1 और a<>NULLकिसी भी मान की तुलना NULL, . से करते समय SQL सर्वर अज्ञात लौटाता है। या तो 1=NULL या NULL=NULL - दोनों का परिणाम UNKNOWN होता है। जहां तक हमारे पास है और व्यंजक में, दोनों पक्ष UNKNOWN लौटाते हैं।
मैं यह बताना चाहूंगा कि यह मामला दुर्लभ नहीं है। उदाहरण के लिए, आप किसी कॉलम को NOT NULL के रूप में चिह्नित करते हैं। कुछ समय बाद, एक अन्य डेवलपर इसके लिए NULLs . की अनुमति देने का निर्णय लेता है वह स्तंभ। इससे ऐसी स्थिति उत्पन्न हो सकती है, जब तालिका में कोई NULL-मान डालने के बाद क्लाइंट रिपोर्ट काम करना बंद कर देती है।
इस मामले में, मैं NULL मानों को बाहर करने का सुझाव दूंगा:
चुनें *@t1 से जहां t1 अंदर नहीं है (चुनें t2 से @t2 जहां t2 न्यूल नहीं है)इसके अलावा, छोड़कर . का उपयोग करना संभव है :
चुनें* @t1 से चुनें* @t2 सेवैकल्पिक रूप से, आप मौजूद नहीं . का उपयोग कर सकते हैं :
चुनें *@t1 से जहां मौजूद नहीं है (@t2 से 1 चुनें जहां t1 =t2)कौन सा विकल्प अधिक बेहतर है? बाद वाला विकल्प मौजूद नहीं है . के साथ यह सबसे अधिक उत्पादक प्रतीत होता है क्योंकि यह अधिक इष्टतम प्रेडिकेट पुशडाउन . उत्पन्न करता है दूसरी तालिका से डेटा एक्सेस करने के लिए ऑपरेटर।
वास्तव में, NULL मान एक अप्रत्याशित परिणाम दे सकता है।
इस विशेष उदाहरण पर विचार करें:
एडवेंचरवर्क्स2014 का उपयोग करेंउत्पादन से COUNT_BIG(*) चुनें।उत्पाद से COUNT_BIG(*) चुनें। उत्पाद जहां रंग ='ग्रे' चुनें COUNT_BIG(*)उत्पादन से। उत्पादजहां रंग <> 'ग्रे'जैसा कि आप देख सकते हैं, आपको अपेक्षित परिणाम नहीं मिला है क्योंकि NULL मानों के अलग-अलग तुलना ऑपरेटर हैं:
उत्पादन से COUNT_BIG(*) चुनें। उत्पाद जहां रंग शून्य है उत्पादन से COUNT_BIG(*) चुनें। उत्पाद जहां रंग पूर्ण नहीं हैयहां चेक . के साथ एक और उदाहरण दिया गया है बाधाएं:
IF OBJECT_ID('tempdb.dbo.#temp') न्यूल ड्रॉप टेबल नहीं है #tempGOCREATE TABLE #temp (कलर VARCHAR(15) --NULL , CONSTRAINT CK CHECK (कलर इन ('ब्लैक', 'व्हाइट') ))हम केवल सफेद और काले रंग डालने की अनुमति के साथ एक तालिका बनाते हैं:
#temp VALUES ('ब्लैक')(1 पंक्ति(ओं) प्रभावित) में डालेंसब कुछ उम्मीद के मुताबिक काम करता है।
INSERT INTO #temp VALUES ('Red') INSERT कथन CHECK बाधा के विपरीत है... कथन को समाप्त कर दिया गया है।अब, NULL जोड़ें:
#temp VALUES (NULL)(1 पंक्ति (प्रभावित) प्रभावित) में डालेंCHECK बाधा ने NULL मान क्यों पारित किया? खैर, इसका कारण यह है कि पर्याप्त गलत नहीं . है रिकॉर्ड बनाने की शर्त वर्कअराउंड स्पष्ट रूप से एक कॉलम को NOT NULL . के रूप में परिभाषित करना है या बाधा में NULL का उपयोग करें।
दिनांक प्रारूप
बहुत बार, आपको डेटा प्रकारों में कठिनाई हो सकती है।
उदाहरण के लिए, आपको वर्तमान तिथि प्राप्त करने की आवश्यकता है। ऐसा करने के लिए, आप GETDATE फ़ंक्शन का उपयोग कर सकते हैं:
चुनें GETDATE()फिर दिए गए परिणाम को एक आवश्यक क्वेरी में कॉपी करें, और समय हटाएं:
चुनें *sys.objects से जहां create_date <'2016-11-14'क्या यह सही है?
दिनांक एक स्ट्रिंग स्थिरांक द्वारा निर्दिष्ट किया गया है:
सेट लैंग्वेज इंग्लिशसेट डेटफॉर्मेट DMYDECLARE @d1 DATETIME ='05/12/2016', @d2 DATETIME ='2016/12/05', @d3 DATETIME ='2016-12-05', @d4 DATETIME ='05 -दिसंबर-2016'चुनें @d1, @d2, @d3, @d4सभी मूल्यों की एक-मूल्यवान व्याख्या होती है:
-------------------------------------------------------2016-12 -05 2016-05-12 2016-05-12 2016-12-05जब तक इस व्यवसाय तर्क के साथ क्वेरी को किसी अन्य सर्वर पर निष्पादित नहीं किया जाता है, जहां सेटिंग्स भिन्न हो सकती हैं, तब तक इससे कोई समस्या नहीं होगी:
सेट डेटफॉर्मेट MDYDECLARE @d1 DATETIME ='05/12/2016', @d2 DATETIME ='2016/12/05', @d3 DATETIME ='2016-12-05', @d4 DATETIME ='05-dec -2016'चुनें @d1, @d2, @d3, @d4हालांकि, इन विकल्पों से तारीख की गलत व्याख्या हो सकती है:
-------------------------------------------------------2016-05 -12 2016-12-05 2016-12-05 2016-12-05इसके अलावा, यह कोड एक दृश्य और गुप्त बग दोनों को जन्म दे सकता है।
निम्नलिखित उदाहरण पर विचार करें। हमें एक परीक्षण तालिका में डेटा सम्मिलित करने की आवश्यकता है। एक परीक्षण सर्वर पर सब कुछ सही काम करता है:
DECLARE @t TABLE (एक DATETIME) INSERT INTO @t VALUES ('05/13/2016')फिर भी, क्लाइंट की ओर से इस क्वेरी में समस्याएँ होंगी क्योंकि हमारी सर्वर सेटिंग्स भिन्न हैं:
DECLARE @t TABLE (एक DATETIME)सेट DATEFORMAT DMYINSERT INTO @t VALUES ('05/13/2016')संदेश 242, स्तर 16, राज्य 3, पंक्ति 28वर्चर डेटा प्रकार के डेटाटाइम डेटा प्रकार में रूपांतरण के परिणामस्वरूप एक आउट-ऑफ-रेंज मान प्राप्त हुआ।इस प्रकार, दिनांक स्थिरांक घोषित करने के लिए हमें किस प्रारूप का उपयोग करना चाहिए? इस प्रश्न का उत्तर देने के लिए, इस क्वेरी को निष्पादित करें:
सेट डेटफॉर्मेट YMDSET भाषा अंग्रेजीDECLARE @d1 DATETIME ='2016/01/12', @d2 DATETIME ='2016-01-12', @d3 DATETIME ='12-jan-2016', @d4 DATETIME ='20160112 'चुनें @d1, @d2, @d3, @d4GOSET भाषा DeutschDECLARE @d1 DATETIME ='2016/01/12', @d2 DATETIME ='2016-01-12', @d3 DATETIME ='12-जनवरी-2016' , @d4 DATETIME ='20160112' @d1, @d2, @d3, @d4चुनेंस्थिरांक की व्याख्या स्थापित भाषा के आधार पर भिन्न हो सकती है:
-------------------------------------------------------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ------------------------------------ -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12इस प्रकार, अंतिम दो विकल्पों का उपयोग करना बेहतर है। साथ ही, मैं यह भी जोड़ना चाहूंगा कि तारीख को स्पष्ट रूप से निर्दिष्ट करना एक अच्छा विचार नहीं है:
सेट भाषा फ़्रेंचDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29Échec de la कन्वर्जन डे ला डेट और ou de l'heure partir d'une chaîne de caractères।इसलिए, यदि आप चाहते हैं कि तारीखों के साथ स्थिरांक की सही व्याख्या की जाए, तो आपको उन्हें निम्न प्रारूप में निर्दिष्ट करना होगा YYYYMMDD।
इसके अलावा, मैं आपका ध्यान कुछ डेटा प्रकारों के व्यवहार की ओर आकर्षित करना चाहूंगा:
सेट लैंग्वेज इंग्लिशसेट डेटफॉर्मेट YMDDECLARE @d1 DATE ='2016-01-12', @d2 DATETIME ='2016-01-12' Select @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12' @d1, @d2 चुनेंDATETIME के विपरीत, DATE सर्वर पर विभिन्न सेटिंग्स के साथ प्रकार की सही व्याख्या की जाती है:
--------------------2016-01-12 2016-01-12-------------------- ---2016-01-12 2016-12-01तिथि फ़िल्टर
आगे बढ़ने के लिए, हम विचार करेंगे कि डेटा को प्रभावी ढंग से कैसे फ़िल्टर किया जाए। आइए उनसे DATETIME/DATE को प्रारंभ करें:
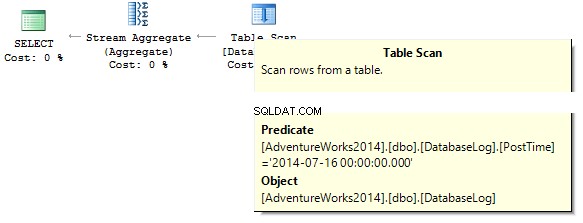
AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12' का उपयोग करेंअब, हम यह पता लगाने की कोशिश करेंगे कि एक निर्दिष्ट दिन के लिए क्वेरी कितनी पंक्तियों में लौटती है:
dbo.DatabaseLogWHERE से COUNT_BIG(*) चुनें, जहां पोस्टटाइम ='20140716'क्वेरी वापस आ जाएगी। निष्पादन योजना बनाते समय, SQL सर्वर कॉलम के डेटा प्रकार के लिए एक स्ट्रिंग स्थिरांक डालने का प्रयास कर रहा है जिसे हमें फ़िल्टर करने की आवश्यकता है:
एक इंडेक्स बनाएं:
असंबद्ध सूचकांक IX_PostTime dbo.DatabaseLog (पोस्टटाइम) पर बनाएंडेटा आउटपुट करने के लिए सही और गलत विकल्प हैं। उदाहरण के लिए, आपको समय कॉलम को हटाना होगा:
dbo से COUNT_BIG(*) चुनें।या हमें एक सीमा निर्दिष्ट करने की आवश्यकता है:
dbo.DatabaseLog से COUNT_BIG(*) चुनें, जहां '20140716' और '20140716 23:59:59.997' के बीच पोस्टटाइम का चयन करें।>अनुकूलन को ध्यान में रखते हुए, मैं कह सकता हूं कि ये दो प्रश्न सबसे सही हैं। मुद्दा यह है कि फ़िल्टर किए जा रहे इंडेक्स कॉलम के सभी रूपांतरण और गणना से प्रदर्शन में भारी कमी आ सकती है और तर्क रीडिंग का समय बढ़ सकता है:
टेबल 'डेटाबेसलॉग'। स्कैन काउंट 1, लॉजिकल रीड्स 7, ...टेबल 'डेटाबेसलॉग'। स्कैन गिनती 1, तार्किक 2 पढ़ता है, ...पोस्टटाइम फ़ील्ड को पहले इंडेक्स में शामिल नहीं किया गया था, और हम फ़िल्टरिंग में इस सही दृष्टिकोण का उपयोग करने में कोई दक्षता नहीं देख सके। दूसरी बात यह है कि जब हमें एक महीने के लिए डेटा आउटपुट करने की आवश्यकता होती है:
से COUNT_BIG (*) चुनें। पोस्टटाइम) =7 सेलेक्ट COUNT_BIG (*) से dbo.DatabaseLogWHERE YEAR (पोस्टटाइम) =2014 और MONTH (पोस्टटाइम) =7 सेलेक्ट COUNT_BIG (*) से dbo.DatabaseLogWHERE EOMONTH (पोस्टटाइम) ='20140731' सेलेक्ट COUNT_BIG(*)DatabaseLogFROM पोस्टटाइम>='20140701' और पोस्टटाइम <'20140801'फिर से, बाद वाला विकल्प अधिक बेहतर है:
इसके अलावा, आप हमेशा परिकलित फ़ील्ड के आधार पर एक इंडेक्स बना सकते हैं:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') पूरी तरह से टेबल नहीं है।पिछली क्वेरी की तुलना में, तार्किक रीडिंग में अंतर महत्वपूर्ण हो सकता है (यदि बड़ी तालिकाएँ प्रश्न में हैं):
सेट आँकड़ों का चयन COUNT_BIG (*) से dbo.DatabaseLogWHERE पोस्टटाइम> ='20140701' और पोस्टटाइम <'20140801' से COUNT_BIG(*) से dbo.DatabaseLogWHERE MonthLastDay ='20140731'सेट सांख्यिकी डेटाबेस IO ऑफ़टेबल' सेट करें। स्कैन काउंट 1, लॉजिकल रीड्स 7, ...टेबल 'डेटाबेसलॉग'। स्कैन गिनती 1, तार्किक 3 पढ़ता है, ...गणना
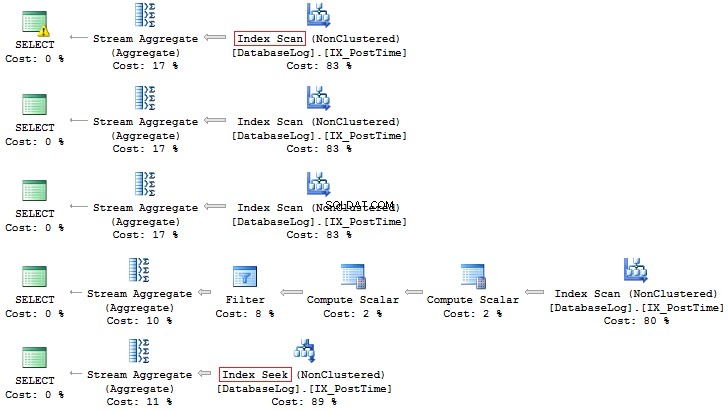
जैसा कि पहले ही चर्चा की जा चुकी है, इंडेक्स कॉलम पर कोई भी गणना प्रदर्शन को कम करती है और तर्क का समय बढ़ाती है:
एडवेंचरवर्क्स2014गोसेट सांख्यिकी का उपयोग करें आईओ ऑन-सिलेक्ट बिजनेसएंटिटीआईडीफ्रॉम पर्सन।पर्सनव्हेयर बिजनेसएंटिटीआईडी * 2 =100000 सेलेक्ट बिजनेसएंटिटीआईडीफ्रॉम पर्सन। पर्सनव्हेयर बिजनेसएंटिटीआईडी =2500 * 2 सेलेक्ट बिजनेसएंटिटीआईडीफ्रॉम पर्सन। स्कैन काउंट 1, लॉजिकल रीड्स 67, ...टेबल 'पर्सन'। स्कैन काउंट 0, लॉजिकल रीड्स 3, ...यदि हम निष्पादन योजनाओं को देखें, तो पहले वाले में, SQL सर्वर IndexScan निष्पादित करता है :
फिर, जब अनुक्रमणिका स्तंभों पर कोई गणना नहीं होती है, तो हम IndexSeek . देखेंगे :
अंतर्निहित रूपांतरित करें
आइए इन दो प्रश्नों पर एक नज़र डालें जो समान मान के आधार पर फ़िल्टर करते हैं:
AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845 BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'का उपयोग करेंनिष्पादन योजनाएं निम्नलिखित जानकारी प्रदान करती हैं:

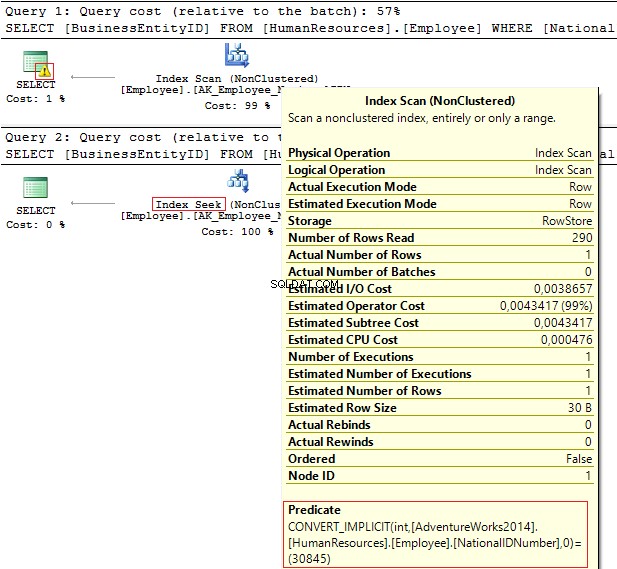
- चेतावनी और इंडेक्सस्कैन पहली योजना पर
- इंडेक्ससीक - दूसरे पर।
टेबल 'कर्मचारी'। स्कैन काउंट 1, लॉजिकल रीड्स 4, ...टेबल 'कर्मचारी'। स्कैन काउंट 0, लॉजिकल रीड्स 2, ...
NationalIDNumber कॉलम में NVARCHAR(15) . है डेटा प्रकार। डेटा को फ़िल्टर करने के लिए हम जिस स्थिरांक का उपयोग करते हैं उसे INT . के रूप में सेट किया जाता है जो हमें एक निहित डेटा प्रकार रूपांतरण की ओर ले जाता है। बदले में, यह प्रदर्शन को कम कर सकता है। जब कोई कॉलम में डेटा प्रकार को संशोधित करता है, तो आप इसकी निगरानी कर सकते हैं, हालांकि, क्वेरीज़ नहीं बदली जाती हैं।
यह समझना महत्वपूर्ण है कि एक अंतर्निहित डेटा प्रकार रूपांतरण से रनटाइम में त्रुटियां हो सकती हैं। उदाहरण के लिए, पोस्टलकोड फ़ील्ड के संख्यात्मक होने से पहले, यह पता चला कि पोस्टल कोड में अक्षर हो सकते हैं। इस प्रकार, डेटा प्रकार अद्यतन किया गया था। फिर भी, यदि हम एक अल्फाबेटिक पोस्टल कोड डालते हैं, तो पुरानी क्वेरी अब काम नहीं करेगी:
पता चुनेंIDFROM व्यक्ति।[पता]जहां पोस्टलकोड =92700 चयन पताIDFROM व्यक्ति।[पता]जहां पोस्टलकोड ='92700'संदेश 245, स्तर 16, राज्य 1, पंक्ति 16 nvarchar मान 'K4B 1S2' को डेटा प्रकार में परिवर्तित करते समय रूपांतरण विफल रहा इंट.
एक अन्य उदाहरण है जब आपको EntityFramework . का उपयोग करने की आवश्यकता होती है प्रोजेक्ट पर, जो डिफ़ॉल्ट रूप से सभी पंक्ति क्षेत्रों को यूनिकोड के रूप में व्याख्या करता है:
ग्राहक आईडी चुनें, बिक्री से खाता संख्या। ग्राहक जहां खाता संख्या =एन'एडब्ल्यू 00000009' ग्राहक आईडी चुनें, बिक्री से खाता संख्या। ग्राहक जहां खाता संख्या ='AW00000009'
इसलिए, गलत प्रश्न उत्पन्न होते हैं:

इस समस्या को हल करने के लिए, सुनिश्चित करें कि डेटा प्रकार मेल खाते हैं।
पसंद और दबाई गई अनुक्रमणिका
वास्तव में, कवरिंग इंडेक्स होने का मतलब यह नहीं है कि आप इसका प्रभावी ढंग से उपयोग करेंगे।
आइए इसे इस विशेष उदाहरण पर देखें। मान लें कि हमें उन सभी पंक्तियों को आउटपुट करने की आवश्यकता है जो शुरू होती हैं…
एडवेंचरवर्क्स2014GOSET सांख्यिकी का उपयोग करें। व्यक्ति से पता लाइन 1 चुनें। [पता] जहां सबस्ट्रिंग (पता रेखा 1, 1, 3) ='100' व्यक्ति से पता पंक्ति 1 चुनें। पता]जहां CAST(AddressLine1 AS CHAR(3)) ='100' व्यक्ति से पता लाइन 1 चुनें।हमें निम्नलिखित तर्क रीडिंग और निष्पादन योजनाएँ मिलेंगी:
तालिका 'पता'। स्कैन गिनती 1, तार्किक 216 पढ़ता है, ...तालिका 'पता'। स्कैन गिनती 1, तार्किक 216 पढ़ता है, ...तालिका 'पता'। स्कैन गिनती 1, तार्किक 216 पढ़ता है, ...तालिका 'पता'। स्कैन काउंट 1, लॉजिकल रीड्स 4, ...
इस प्रकार, यदि कोई अनुक्रमणिका है, तो उसमें कोई गणना या प्रकार, फ़ंक्शन आदि का रूपांतरण नहीं होना चाहिए।
लेकिन अगर आपको किसी स्ट्रिंग में सबस्ट्रिंग की घटना का पता लगाना है तो आप क्या करेंगे?
व्यक्ति से पता लाइन1 चुनें।[पता]जहां पतालाइन1 पसंद '%100%'vहम इस प्रश्न पर बाद में वापस आएंगे।
यूनिकोड बनाम एएनएसआई
यह याद रखना महत्वपूर्ण है कि UNICODE . हैं और एएनएसआई तार। UNICODE प्रकार में शामिल हैं NVARCHAR/NCHAR (एक प्रतीक के लिए 2 बाइट्स)। स्टोर करने के लिए एएनएसआई तार, VARCHAR/CHAR . का उपयोग करना संभव है (1 बाइट से 1 प्रतीक)। पाठ/NTEXT . भी है , लेकिन मैं उनका उपयोग करने की अनुशंसा नहीं करता क्योंकि वे प्रदर्शन को कम कर सकते हैं।
यदि आप किसी क्वेरी में यूनिकोड स्थिरांक निर्दिष्ट करते हैं, तो उसके पहले N चिह्न होना आवश्यक है। इसे जांचने के लिए, निम्न क्वेरी निष्पादित करें:
चुनें '文本 ANSI' , N'文本 UNICODE'--------------------?? एएनएसआई 文本 यूनिकोडयदि N स्थिरांक से पहले नहीं आता है, तो SQL सर्वर ANSI कोडिंग में एक उपयुक्त प्रतीक खोजने का प्रयास करेगा। यदि यह खोजने में विफल रहता है, तो यह एक प्रश्न चिह्न दिखाएगा।
कोलेट करें
बहुत बार, जब मध्य/वरिष्ठ डीबी डेवलपर पद के लिए साक्षात्कार लिया जाता है, तो एक साक्षात्कारकर्ता अक्सर निम्नलिखित प्रश्न पूछता है:क्या यह प्रश्न डेटा लौटाएगा?
DECLARE @a NCHAR(1) ='Ё', @b NCHAR(1) ='Ф'चुनें @a, @bWHERE @a =@bनिर्भर करता है। सबसे पहले, एन प्रतीक एक स्ट्रिंग स्थिरांक से पहले नहीं होता है, इस प्रकार, इसे एएनएसआई के रूप में व्याख्या किया जाएगा। दूसरे, बहुत कुछ वर्तमान COLLATE मान पर निर्भर करता है, जो स्ट्रिंग डेटा का चयन और तुलना करते समय नियमों का एक सेट है।
उपयोग [मास्टर]GOIF DB_ID('test') नॉट न्यूल BEGIN ALTER DATABASE परीक्षण सेट SINGLE_USER with ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE टेस्टGODECLARE @a' NCHAR((1) ='Ё' NCHAR((1) ='' NCHAR,(1) =' ) ='Ф' चुनें @a, @bWHERE @a =@bयह COLLATE कथन प्रश्नवाचक चिह्न लौटाएगा क्योंकि उनके प्रतीक समान हैं:
-------? ?यदि हम किसी अन्य कथन के लिए COLLATE कथन बदलते हैं:
डेटाबेस परीक्षण COLLATE सिरिलिक_जनरल_100_CI_ASइस मामले में, क्वेरी कुछ भी नहीं लौटाएगी, क्योंकि सिरिलिक वर्णों की सही व्याख्या की जाएगी।
इसलिए, यदि एक स्ट्रिंग स्थिरांक UNICODE लेता है, तो एक स्ट्रिंग स्थिरांक से पहले N को सेट करना आवश्यक है। फिर भी, जिन कारणों से हमने ऊपर चर्चा की है, उनके लिए मैं इसे हर जगह स्थापित करने की अनुशंसा नहीं करूंगा।
साक्षात्कार में पूछे जाने वाले एक अन्य प्रश्न का संबंध पंक्तियों की तुलना से है।
निम्नलिखित उदाहरण पर विचार करें:
DECLARE @a VARCHAR(10) ='TEXT', @b VARCHAR(10) ='text'Select IIF(@a =@b, 'TRUE', 'FALSE')क्या ये पंक्तियाँ समान हैं? इसे जांचने के लिए, हमें स्पष्ट रूप से COLLATE निर्दिष्ट करने की आवश्यकता है:
DECLARE @a VARCHAR(10) ='TEXT', @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')चूंकि पंक्तियों की तुलना और चयन करते समय केस-संवेदी (सीएस) और केस-असंवेदनशील (सीआई) कॉललेट होते हैं, हम निश्चित रूप से यह नहीं कह सकते कि क्या वे बराबर हैं। इसके अलावा, परीक्षण सर्वर और क्लाइंट दोनों पर विभिन्न COLLATEs होते हैं।
एक ऐसा मामला होता है जब लक्ष्य आधार के COLLATEs और tempdb मेल नहीं खाते।
COLLATE के साथ एक डेटाबेस बनाएं:
उपयोग [मास्टर]GOIF DB_ID('test') पूरी तरह से डेटाबेस परीक्षण सेट SINGLE_USER के साथ रोलबैक तत्काल ड्रॉप डेटाबेस परीक्षणENDGOCREATE DATABASE परीक्षण COLLATE अल्बानियाई_100_CS_ASVAGOUSE परीक्षण (गोक्रिएट टेबल) 'टी (सी) में सम्मिलित करें। ')GOIF OBJECT_ID('tempdb.dbo.#t1') नॉट नॉट ड्राप टेबल #t1IF OBJECT_ID('tempdb.dbo.#t2') नॉट नॉट न्यूल ड्रॉप टेबल #t2IF OBJECT_ID('tempdb.dbo.#t3') न्यूल ड्रॉप टेबल नहीं है #t3GOCREATE टेबल #t1 (c CHAR(1))#t1 Values में INSERT करें ('a') CREATE TABLE #t2 (c CHAR(1) COLLATE database_default) INSERT INTO #t2 VALUES ('a') सी =कास्ट ('ए' के रूप में चार्ज (1)) # टी 3 डिक्लेयर @ टी टेबल (सी वर्चर (100)) में चुनें ') UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') ट्यूनियन से ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') # से t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') # से t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') #t3UNION से ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') @t सेतालिका बनाते समय, यह डेटाबेस से COLLATE को इनहेरिट करता है। पहली अस्थायी तालिका के लिए एकमात्र अंतर, जिसके लिए हम स्पष्ट रूप से बिना COLLATE के एक संरचना निर्धारित करते हैं, वह यह है कि यह COLLATE को tempdb से विरासत में मिला है। डेटाबेस।
----------------टेम्पडब सिरिलिक_जनरल_सीआई_एटेस्ट अल्बानियाई_100_सीएस_एएसटी अल्बानियाई_100_सीएस_एएस#t1 सिरिलिक_जनरल_सीआई_एएस#t2 अल्बानियाई_100_CS_AS#t3 अल्बानियाई_100_CS_AS@t अल्बानियाई_100_CS_ASमैं उस मामले का वर्णन करूंगा जब COLLATEs विशेष उदाहरण पर #t1. से मेल नहीं खाते हैं।
उदाहरण के लिए, डेटा सही ढंग से फ़िल्टर नहीं किया गया है, क्योंकि COLLATE किसी मामले को ध्यान में नहीं रख सकता है:
चुनें *#t1 से जहां c ='A'वैकल्पिक रूप से, हमारे पास अलग-अलग COLLATEs के साथ तालिकाओं को जोड़ने का विरोध हो सकता है:
चुनें *#t1 से शामिल हों t पर [#t1].c =t.cऐसा लगता है कि परीक्षण सर्वर पर सब कुछ ठीक काम कर रहा है, जबकि क्लाइंट सर्वर पर हमें एक त्रुटि मिलती है:
संदेश 468, स्तर 16, राज्य 9, पंक्ति 93 "अल्बानियाई_100_CS_AS" और "सिरिलिक_जनरल_सीआई_एएस" के बीच के टकराव को बराबर संचालन में हल नहीं कर सकता।इसके समाधान के लिए, हमें हर जगह हैक सेट करने होंगे:
चुनें *#t1 से शामिल हों t पर [#t1].c =t.c डेटाबेस_डिफॉल्ट को मिलाएंबाइनरी कोलेट
अब, हम जानेंगे कि आपके लाभ के लिए COLLATE का उपयोग कैसे करें।
एक स्ट्रिंग में एक सबस्ट्रिंग की घटना के उदाहरण पर विचार करें:
व्यक्ति से पता पंक्ति1 चुनें।[पता]जहां पता पंक्ति1 '%100%' पसंद करती हैइस क्वेरी को अनुकूलित करना और इसके निष्पादन समय को कम करना संभव है।
सबसे पहले, हमें एक बड़ी तालिका बनाने की आवश्यकता है:
उपयोग [मास्टर]GOIF DB_ID('test') नॉट फुल BEGIN ALTER DATABASE टेस्ट सेट SINGLE_USER with ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE टेस्ट MODIFY FILE डेटाबेस परीक्षण संशोधित फ़ाइल (NAME =N'test_log', SIZE =64MB) GOUSE परीक्षणGOCREATE TABLE t (ansi VARCHAR(100) NOT NULL, यूनिकोड NVARCHAR(100) NOT NULL)GO; E1(N) AS के साथ (चुनें * से ( मान (1),(1),(1),(1),(1),(1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (E1 a, E1 b से 1 चुनें), E4 (N) AS (E2 a, E2 b से 1 चुनें), E8 (N) AS (E4 a, E4 b से 1 चुनें) tSELECT v, vFROM में डालें ( टॉप (50000) वी =रिप्लेस (कास्ट (न्यूड () एएस वचरर (36))) + कास्ट (न्यूड () एएस वचरर (36)), '-', '') ई8 से चुनें) टीबाइनरी COLLATEs और अनुक्रमणिका के साथ परिकलित स्तंभ बनाएं:
वैकल्पिक तालिका जोड़ें ansi_bin के रूप में UPPER(ansi) COLLATE लैटिन1_General_100_Bin2ALTER TABLE t UPPER (यूनिकोड) के रूप में यूनिकोड_बिन जोड़ें ansi_bin) गैर-अनुक्रमित अनुक्रमणिका बनाएं unicode_bin पर t (unicod_bin)निस्पंदन प्रक्रिया निष्पादित करें:
सेट स्टैटिस्टिक्स टाइम, आईओ ऑन सेलेक्ट COUNT_BIG (*) जहां से '% AB%' की तरह ansi '% AB%' से COUNT_BIG (*) चुनें जहां '% AB%' से COUNT_BIG (*) चुनें जहां से ansi_bin '% AB%' पसंद है। --COLLATE Latin1_General_100_BIN2 COUNT_BIG(*) से चुनें जहां से यूनिकोड_बिन '%AB%' पसंद है --COLLATE लैटिन1_General_100_BIN2SET आँकड़ा समय, IO OFFजैसा कि आप देख सकते हैं, यह क्वेरी निम्न परिणाम देती है:
एसक्यूएल सर्वर एक्ज़ीक्यूशन टाइम्स:सीपीयू टाइम =350 एमएस, बीता हुआ समय =354 एमएस।एसक्यूएल सर्वर एक्ज़ीक्यूशन टाइम्स:सीपीयू टाइम =335 एमएस, बीता हुआ समय =355 एमएस।एसक्यूएल सर्वर एक्ज़ीक्यूशन टाइम्स:सीपीयू समय =16 एमएस, बीता हुआ समय =18 ms.SQL सर्वर निष्पादन समय:CPU समय =17 ms, बीता हुआ समय =18 ms.मुद्दा यह है कि बाइनरी तुलना पर आधारित फ़िल्टर में कम समय लगता है। इस प्रकार, यदि आपको स्ट्रिंग्स की आवृत्ति को बार-बार और जल्दी से फ़िल्टर करने की आवश्यकता है, तो डेटा को BIN के साथ समाप्त होने वाले COLLATE के साथ संग्रहीत करना संभव है। हालांकि, यह ध्यान दिया जाना चाहिए कि सभी बाइनरी COLLATEs केस संवेदी होते हैं।
कोड शैली
कोडिंग की एक शैली सख्ती से व्यक्तिगत है। फिर भी, इस कोड को अन्य डेवलपर्स द्वारा बनाए रखा जाना चाहिए और कुछ नियमों से मेल खाना चाहिए।
अंदर एक अलग डेटाबेस और एक टेबल बनाएं:
उपयोग [मास्टर]GOIF DB_ID('test') नॉट फुल BEGIN ALTER DATABASE परीक्षण सेट SINGLE_USER with ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_INT PRI_ASGOUSE टेस्टGOCREATE TABLE preeID> कर्मचारी dbo.फिर, क्वेरी लिखें:
कर्मचारी से कर्मचारी आईडी चुनेंअब, COLLATE को किसी भी केस-संवेदी में बदलें:
ALTER DATABASE परीक्षण COLLATE लैटिन1_General_CS_AIफिर, क्वेरी को फिर से निष्पादित करने का प्रयास करें:
Msg 208, Level 16, State 1, Line 19अवैध ऑब्जेक्ट नाम 'कर्मचारी'।एक अनुकूलक वर्तमान COLLATE के लिए बाध्यकारी चरण में नियमों का उपयोग करता है जब वह तालिकाओं, स्तंभों और अन्य वस्तुओं की जांच करता है और साथ ही यह सिंटैक्स ट्री के प्रत्येक ऑब्जेक्ट की तुलना सिस्टम कैटलॉग के वास्तविक ऑब्जेक्ट से करता है।
यदि आप मैन्युअल रूप से प्रश्न उत्पन्न करना चाहते हैं, तो आपको ऑब्जेक्ट नामों में हमेशा सही केस का उपयोग करना होगा।
चर के लिए, COLLATEs को मास्टर डेटाबेस से विरासत में मिला है। इस प्रकार, आपको उनके साथ भी काम करने के लिए सही केस का उपयोग करने की आवश्यकता है:
डेटाबेसप्रॉपर्टीएक्स चुनें ('मास्टर', 'कोलेशन') DECLARE @EmpID INT =1SELECT @empidइस मामले में, आपको कोई त्रुटि नहीं मिलेगी:
---------------सिरिलिक_जनरल_सीआई_एएस------------1फिर भी, किसी अन्य सर्वर पर मामला त्रुटि दिखाई दे सकती है:
--------------------------लैटिन1_जनरल_सीएस_एएसएम 137, लेवल 15, स्टेट 2, लाइन 4 को स्केलर वेरिएबल "@empid" घोषित करना चाहिए।[var]char
जैसा कि आप जानते हैं, निश्चित हैं (CHAR , एनसीएचएआर ) और चर (VARCHAR , NVARCHAR ) डेटा प्रकार:
DECLARE @a CHAR(20) ='text', @b VARCHAR(20) ='text'Select LEN(@a), LEN(@b), DATALENGTH(@a), DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"' चुनें [a =b] =IIF(@a =@b, 'TRUE', 'FALSE'), [b =a] =IIF(@b =@a, 'TRUE', 'FALSE'), [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE'), [b LIKE a] =IIF(@ b LIKE @a, 'TRUE', 'FALSE')यदि एक पंक्ति की एक निश्चित लंबाई है, जैसे कि 20 प्रतीक, लेकिन आपने केवल 4 प्रतीक लिखे हैं, तो SQL सर्वर डिफ़ॉल्ट रूप से दाईं ओर 16 रिक्त स्थान जोड़ देगा:
---------------------------------------- -----------4 4 20 4 "पाठ" "पाठ"In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSEAs for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'Data length
It is always necessary to specify type length.
निम्नलिखित उदाहरण पर विचार करें:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3हालाँकि, ऐसा नहीं है। Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
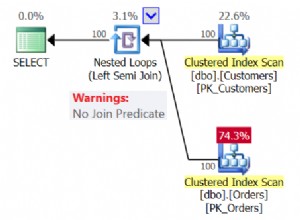
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLineAs we have OR in the statement, we will receive IndexScan:
Table 'Address'. Scan count 1, logical reads 90, ...Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) tWhen the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
टेबल 'वर्कटेबल'। Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityIDThe fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
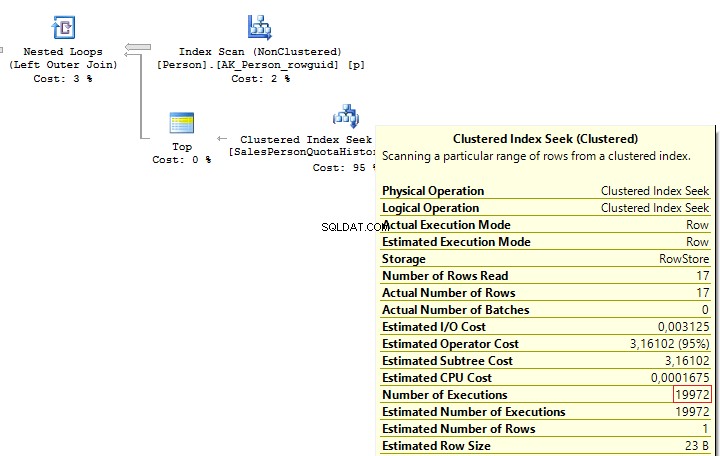
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person pHowever, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
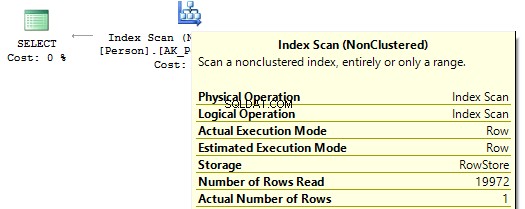
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) tWhen executing these queries, we will get the same issue – multiple IndexSeek operators:
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...Re-write this query with a window function:
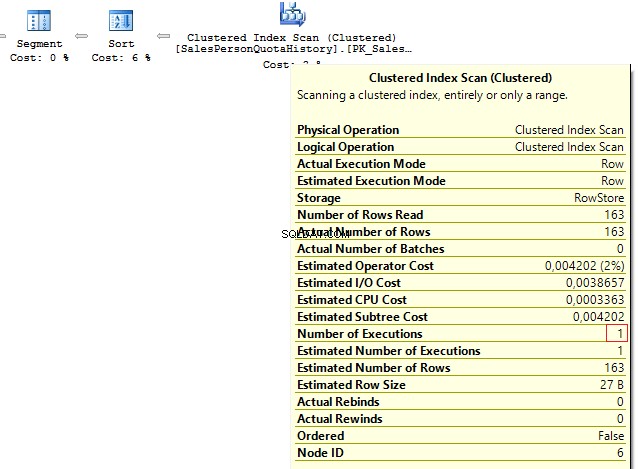
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1हमें निम्नलिखित परिणाम मिलते हैं:
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.EmployeeSQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.EmployeeThus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))ENDThen, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed )।
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddressThe function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddressIn this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) tIn this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.EmployeeThough statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) ENDScalar func
It is not recommended to use scalar functions in T-SQL queries.
निम्नलिखित उदाहरण पर विचार करें:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDENDThe queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFFHowever, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.CurrencyIn this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tblAs you can see, we get the correct result:
a b----------- -----------0 1Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tblWe receive the same result:
a b----------- -----------0 1Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tblResult:
a b c----------- ----------- -----------0 1 2When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityIDWhat should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
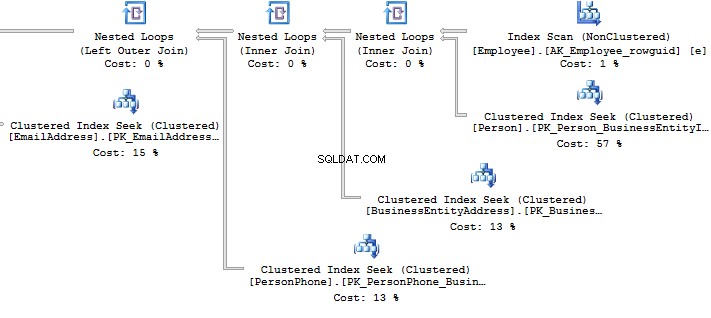
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )Look at the execution plan in the case of using a view:
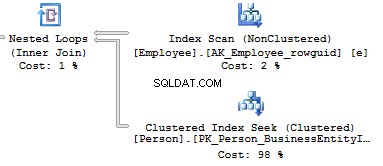
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...Now, we will compare it with the query we have written manually:
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE curThough, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTimeIn addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… ।
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1If we add any additional value to the property,
SET @param ='1; select ''hack'''Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@paramIt is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...}सारांश
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.