यह लेख टी-एसक्यूएल बग, नुकसान और सर्वोत्तम प्रथाओं के बारे में श्रृंखला में दूसरा है। इस बार मैं क्लासिक बग पर ध्यान केंद्रित करता हूं जिसमें सबक्वेरी शामिल हैं। विशेष रूप से, मैं प्रतिस्थापन त्रुटियों और तीन-मूल्यवान तर्क समस्याओं को कवर करता हूं। श्रृंखला में मेरे द्वारा कवर किए जाने वाले कई विषय साथी एमवीपी द्वारा इस विषय पर हुई चर्चा में सुझाए गए थे। आपके सुझावों के लिए एरलैंड सोमरस्कोग, आरोन बर्ट्रेंड, एलेजांद्रो मेसा, उमाचंदर जयचंद्रन (यूसी), फैबियानो नेव्स अमोरिम, मिलोस रेडिवोजेविक, साइमन सबिन, एडम मचानिक, थॉमस ग्रोसर, चैन मिंग मैन और पॉल व्हाइट को धन्यवाद!
प्रतिस्थापन त्रुटि
क्लासिक प्रतिस्थापन त्रुटि प्रदर्शित करने के लिए, मैं एक साधारण ग्राहक-आदेश परिदृश्य का उपयोग करूँगा। GetNums नामक एक सहायक फ़ंक्शन बनाने और ग्राहक और ऑर्डर तालिका बनाने और पॉप्युलेट करने के लिए निम्न कोड चलाएँ:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); वर्तमान में, ग्राहक तालिका में 1 से 100 की सीमा में लगातार ग्राहक आईडी वाले 100 ग्राहक हैं। उन ग्राहकों में से 98 के पास ऑर्डर तालिका में संबंधित ऑर्डर हैं। आईडी 17 और 59 वाले ग्राहकों ने अभी तक कोई ऑर्डर नहीं दिया है और इसलिए ऑर्डर टेबल में उनकी कोई उपस्थिति नहीं है।
आप केवल ऑर्डर देने वाले ग्राहकों के पीछे हैं, और आप निम्न क्वेरी का उपयोग करके इसे प्राप्त करने का प्रयास करते हैं (इसे क्वेरी 1 कहते हैं):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
आपको 98 ग्राहक वापस मिलेंगे, लेकिन इसके बजाय आपको सभी 100 ग्राहक मिलेंगे, जिनमें 17 और 59 आईडी वाले ग्राहक शामिल हैं:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
क्या आप समझ सकते हैं कि क्या गलत है?
भ्रम में जोड़ने के लिए, चित्र 1 में दिखाए गए अनुसार प्रश्न 1 की योजना की जांच करें।
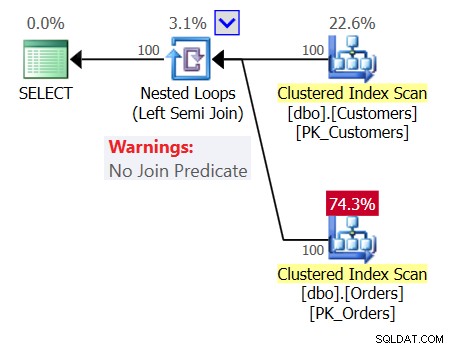 चित्र 1:प्रश्न 1 की योजना
चित्र 1:प्रश्न 1 की योजना
यह योजना एक नेस्टेड लूप्स (लेफ्ट सेमी जॉइन) ऑपरेटर दिखाती है, जिसमें कोई जॉइन प्रेडिकेट नहीं है, जिसका अर्थ है कि ग्राहक को वापस करने की एकमात्र शर्त एक गैर-रिक्त ऑर्डर टेबल होना है, जैसे कि आपके द्वारा लिखी गई क्वेरी निम्नलिखित थी:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
आप शायद चित्र 2 में दिखाए गए योजना के समान योजना की उम्मीद कर रहे हैं।
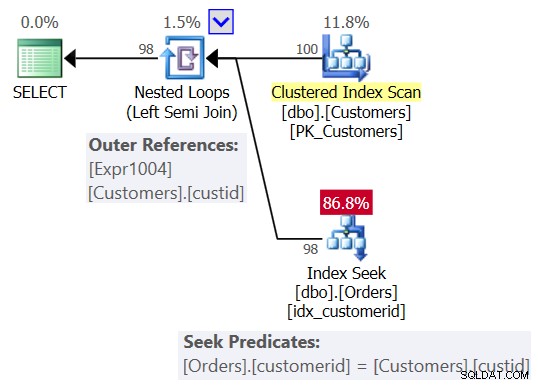 चित्र 2:प्रश्न 1 के लिए अपेक्षित योजना
चित्र 2:प्रश्न 1 के लिए अपेक्षित योजना
इस योजना में आप एक नेस्टेड लूप्स (लेफ्ट सेमी जॉइन) ऑपरेटर देखते हैं, जिसमें बाहरी इनपुट के रूप में ग्राहकों पर क्लस्टर इंडेक्स का स्कैन होता है और ऑर्डर में ग्राहक आईडी कॉलम पर इंडेक्स में आंतरिक इनपुट के रूप में होता है। आप Customers में custid कॉलम के आधार पर एक बाहरी संदर्भ (सहसंबद्ध पैरामीटर) भी देखते हैं, और ऑर्डर्स विधेय की तलाश करते हैं। Customerid =Customers.custid।
तो आपको चित्र 1 में योजना क्यों मिल रही है न कि चित्र 2 में? यदि आपने अभी तक इसका पता नहीं लगाया है, तो दोनों तालिकाओं की परिभाषाओं को ध्यान से देखें - विशेष रूप से कॉलम के नाम - और क्वेरी में उपयोग किए गए कॉलम नामों पर। आप देखेंगे कि ग्राहक तालिका ग्राहक आईडी को ग्राहक आईडी नामक कॉलम में रखती है, और ऑर्डर तालिका ग्राहक आईडी नामक कॉलम में ग्राहक आईडी रखती है। हालाँकि, कोड बाहरी और आंतरिक दोनों प्रश्नों में custid का उपयोग करता है। चूंकि आंतरिक क्वेरी में कस्टिड का संदर्भ अयोग्य है, इसलिए SQL सर्वर को यह हल करना होगा कि कॉलम किस तालिका से आ रहा है। SQL मानक के अनुसार, SQL सर्वर को तालिका में उस कॉलम की तलाश करनी चाहिए जो पहले उसी दायरे में पूछताछ की जाती है, लेकिन चूंकि ऑर्डर में custid नामक कोई कॉलम नहीं है, इसलिए इसे बाहरी में तालिका में देखना चाहिए गुंजाइश है, और इस बार एक मैच है। तो अनजाने में, custid का संदर्भ परोक्ष रूप से एक सहसंबद्ध संदर्भ बन जाता है, जैसे कि आपने निम्नलिखित प्रश्न लिखा हो:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
बशर्ते कि ऑर्डर खाली न हों, और बाहरी कस्टिड मान शून्य नहीं है (हमारे मामले में नहीं हो सकता क्योंकि कॉलम को न्यूल के रूप में परिभाषित किया गया है), आपको हमेशा एक मैच मिलेगा क्योंकि आप मूल्य की तुलना स्वयं से करते हैं . तो प्रश्न 1 इसके बराबर हो जाता है:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
यदि बाहरी तालिका ने कस्टिड कॉलम में एनयूएलएल का समर्थन किया है, तो क्वेरी 1 इसके बराबर होगी:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
अब आप समझ गए हैं कि प्रश्न 1 को चित्र 1 में योजना के साथ अनुकूलित क्यों किया गया और आपको सभी 100 ग्राहक वापस क्यों मिले।
कुछ समय पहले मैंने एक ऐसे ग्राहक से मुलाकात की जिसके पास एक समान बग था, लेकिन दुर्भाग्य से एक DELETE कथन के साथ। एक पल के लिए सोचें कि इसका क्या मतलब है। सभी तालिका पंक्तियों को मिटा दिया गया, न कि केवल वे जिन्हें वे मूल रूप से हटाना चाहते थे!
जहां तक ऐसे बग से बचने में आपकी मदद करने वाले सर्वोत्तम अभ्यासों का सवाल है, तो दो मुख्य हैं। सबसे पहले, जितना आप इसे नियंत्रित कर सकते हैं, सुनिश्चित करें कि आप एक ही चीज़ का प्रतिनिधित्व करने वाली विशेषताओं के लिए तालिकाओं में लगातार कॉलम नामों का उपयोग करते हैं। दूसरा, सुनिश्चित करें कि आप तालिका में उपश्रेणियों में कॉलम संदर्भों को योग्य बनाते हैं, जिसमें स्व-निहित शामिल हैं जहां यह एक सामान्य अभ्यास नहीं है। बेशक, आप तालिका उपनाम का उपयोग कर सकते हैं यदि आप पूर्ण तालिका नामों का उपयोग नहीं करना चाहते हैं। इस अभ्यास को हमारी क्वेरी पर लागू करते हुए, मान लें कि आपके प्रारंभिक प्रयास में निम्नलिखित कोड का उपयोग किया गया था:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
यहां आप निहित कॉलम नाम समाधान की अनुमति नहीं दे रहे हैं और इसलिए SQL सर्वर निम्न त्रुटि उत्पन्न करता है:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
आप जाकर ऑर्डर तालिका के लिए मेटाडेटा की जांच करें, महसूस करें कि आपने गलत कॉलम नाम का उपयोग किया है, और क्वेरी को ठीक करें (इस क्वेरी 2 को कॉल करें), जैसे:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
इस बार आपको 98 ग्राहकों के साथ सही आउटपुट मिलता है, जिसमें आईडी 17 और 59 वाले ग्राहक शामिल नहीं हैं:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
आपको चित्र 2 में पहले दिखाई गई अपेक्षित योजना भी मिलती है।
एक तरफ, यह स्पष्ट है कि क्यों Customers.custid नेस्टेड लूप्स (लेफ्ट सेमी जॉइन) ऑपरेटर में एक बाहरी संदर्भ (सहसंबद्ध पैरामीटर) है। फेलो SQL सर्वर MVP पॉल व्हाइट का मानना है कि यह रीड-फॉरवर्ड मैकेनिज्म द्वारा दोहराए गए प्रयास से बचने के लिए स्टोरेज इंजन को संकेत देने के लिए बाहरी इनपुट के पत्ते से जानकारी का उपयोग करने से संबंधित हो सकता है। आप विवरण यहां पा सकते हैं।
तीन महत्वपूर्ण तर्क समस्या
उपश्रेणियों से जुड़े एक सामान्य बग का संबंध उन मामलों से है जहां बाहरी क्वेरी NOT IN विधेय का उपयोग करती है और उपश्रेणी संभावित रूप से NULLs को उसके मानों के बीच वापस कर सकती है। उदाहरण के लिए, मान लें कि आपको ग्राहक आईडी के रूप में NULL के साथ हमारे ऑर्डर टेबल में ऑर्डर स्टोर करने में सक्षम होना चाहिए। ऐसा मामला एक ऐसे आदेश का प्रतिनिधित्व करेगा जो किसी ग्राहक से संबद्ध नहीं है; उदाहरण के लिए, एक आदेश जो वास्तविक उत्पाद गणना और डेटाबेस में दर्ज की गई गणनाओं के बीच विसंगतियों की भरपाई करता है।
एनयूएलएल की अनुमति देने वाले कस्टिड कॉलम के साथ ऑर्डर तालिका को फिर से बनाने के लिए निम्न कोड का उपयोग करें, और अभी के लिए इसे पहले की तरह उसी नमूना डेटा के साथ पॉप्युलेट करें (ग्राहक आईडी 1 से 100 के ऑर्डर के साथ, 17 और 59 को छोड़कर):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); पर INDEX idx_custid बनाएं ध्यान दें कि जब हम इस पर होते हैं, तो मैंने समान विशेषताओं के लिए तालिकाओं में संगत कॉलम नामों का उपयोग करने के लिए पिछले अनुभाग में चर्चा की गई सर्वोत्तम प्रथा का पालन किया, और ग्राहक तालिका की तरह ही ऑर्डर टेबल कस्टिड में कॉलम का नाम दिया।
मान लीजिए कि आपको एक प्रश्न लिखने की आवश्यकता है जो उन ग्राहकों को लौटाता है जिन्होंने ऑर्डर नहीं दिए। आप NOT IN विधेय का उपयोग करते हुए निम्नलिखित सरल समाधान के साथ आते हैं (इसे क्वेरी 3 कहते हैं, पहला निष्पादन):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
यह क्वेरी 17 और 59 ग्राहकों के साथ अपेक्षित आउटपुट लौटाती है:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
कंपनी के गोदाम में एक इन्वेंट्री की जाती है, और कुछ उत्पाद की वास्तविक मात्रा और डेटाबेस में दर्ज मात्रा के बीच एक असंगतता पाई जाती है। तो, आप विसंगति के लिए खाते में एक डमी क्षतिपूर्ति आदेश जोड़ते हैं। चूंकि ऑर्डर से कोई वास्तविक ग्राहक नहीं जुड़ा है, इसलिए आप ग्राहक आईडी के रूप में NULL का उपयोग करते हैं। ऐसा ऑर्डर हेडर जोड़ने के लिए निम्न कोड चलाएँ:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
दूसरी बार क्वेरी 3 चलाएँ:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
इस बार, आपको एक खाली परिणाम मिलता है:
custid companyname ------- ------------ (0 rows affected)
जाहिर है, कुछ गड़बड़ है। आप जानते हैं कि ग्राहकों 17 और 59 ने कोई ऑर्डर नहीं दिया, और वास्तव में वे ग्राहक तालिका में दिखाई देते हैं लेकिन ऑर्डर तालिका में नहीं। फिर भी क्वेरी परिणाम का दावा है कि ऐसा कोई ग्राहक नहीं है जिसने कोई ऑर्डर नहीं दिया हो। क्या आप यह पता लगा सकते हैं कि बग कहां है और इसे कैसे ठीक किया जाए?
बग को निश्चित रूप से ऑर्डर तालिका में न्यूल के साथ करना है। SQL के लिए एक NULL एक लापता मान के लिए एक मार्कर है जो एक लागू ग्राहक का प्रतिनिधित्व कर सकता है। SQL यह नहीं जानता है कि हमारे लिए NULL एक लापता और अनुपयुक्त (अप्रासंगिक) ग्राहक का प्रतिनिधित्व करता है। ग्राहक तालिका के सभी ग्राहकों के लिए, जो ऑर्डर तालिका में मौजूद हैं, IN विधेय को TRUE देने वाला मिलान मिलता है और NOT IN भाग इसे FALSE बनाता है, इसलिए ग्राहक पंक्ति को छोड़ दिया जाता है। अब तक सब ठीक है. लेकिन ग्राहकों के लिए 17 और 59, IN विधेय UNKNOWN उत्पन्न करता है क्योंकि गैर-नल मानों के साथ सभी तुलना FALSE उत्पन्न करती है, और NULL के साथ तुलना UNKNOWN उत्पन्न करती है। याद रखें, SQL मानता है कि NULL किसी भी लागू ग्राहक का प्रतिनिधित्व कर सकता है, इसलिए तार्किक मान UNKNOWN इंगित करता है कि यह अज्ञात है कि बाहरी ग्राहक आईडी आंतरिक NULL ग्राहक आईडी के बराबर है या नहीं। असत्य या असत्य ... या अज्ञात अज्ञात है। फिर UNKNOWN पर लागू NOT IN भाग अभी भी UNKNOWN देता है।
सरल अंग्रेजी शब्दों में, आपने उन ग्राहकों को वापस करने के लिए कहा, जिन्होंने ऑर्डर नहीं दिए थे। तो स्वाभाविक रूप से, क्वेरी ऑर्डर तालिका में मौजूद ग्राहक तालिका से सभी ग्राहकों को हटा देती है क्योंकि यह निश्चित रूप से ज्ञात है कि उन्होंने ऑर्डर दिए हैं। बाकी के लिए (हमारे मामले में 17 और 59) क्वेरी उन्हें SQL के बाद से छोड़ देती है, जैसे यह अज्ञात है कि क्या उन्होंने ऑर्डर दिए हैं, यह उतना ही अज्ञात है कि क्या उन्होंने ऑर्डर नहीं दिए, और फ़िल्टर को निश्चितता (TRUE) की आवश्यकता है एक पंक्ति वापस करने का आदेश। क्या अचार है!
तो जैसे ही पहला NULL ऑर्डर टेबल में आता है, उसी पल से आपको NOT IN क्वेरी से हमेशा एक खाली परिणाम मिलता है। उन मामलों के बारे में जहां आपके पास वास्तव में डेटा में एनयूएलएल नहीं है, लेकिन कॉलम एनयूएलएल की अनुमति देता है? जैसा कि आपने क्वेरी 3 के पहले निष्पादन में देखा, ऐसे मामले में आपको सही परिणाम मिलता है। शायद आप सोच रहे हैं कि एप्लिकेशन डेटा में कभी भी एनयूएलएल पेश नहीं करेगा, इसलिए आपको चिंता करने की कोई बात नहीं है। कुछ कारणों से यह एक बुरा अभ्यास है। एक के लिए, यदि एक कॉलम को NULLs की अनुमति के रूप में परिभाषित किया गया है, तो यह बहुत निश्चित है कि NULLs अंततः वहां पहुंच जाएंगे, भले ही उन्हें ऐसा नहीं करना चाहिए; कुछ ही समय की बात है। यह खराब डेटा आयात करने, एप्लिकेशन में बग और अन्य कारणों का परिणाम हो सकता है। दूसरे के लिए, भले ही डेटा में एनयूएलएल शामिल न हों, यदि कॉलम उन्हें अनुमति देता है, तो ऑप्टिमाइज़र को इस संभावना के लिए जिम्मेदार होना चाहिए कि क्वेरी योजना बनाते समय एनयूएलएल मौजूद होंगे, और हमारे नॉट इन क्वेरी में यह एक प्रदर्शन जुर्माना लगाता है . इसे प्रदर्शित करने के लिए, NULL के साथ पंक्ति जोड़ने से पहले क्वेरी 3 के पहले निष्पादन की योजना पर विचार करें, जैसा कि चित्र 3 में दिखाया गया है।
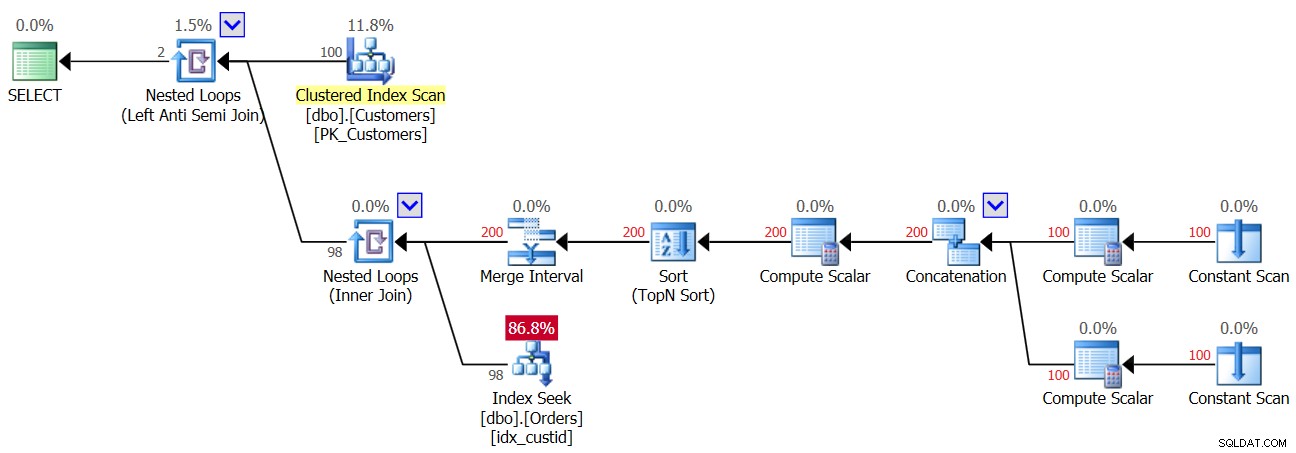 चित्र 3:क्वेरी 3 के पहले निष्पादन की योजना
चित्र 3:क्वेरी 3 के पहले निष्पादन की योजना
शीर्ष नेस्टेड लूप्स ऑपरेटर लेफ्ट एंटी सेमी जॉइन लॉजिक को हैंडल करता है। यह अनिवार्य रूप से गैर-मिलानों की पहचान करने के बारे में है, और जैसे ही कोई मैच मिलता है, आंतरिक गतिविधि को शॉर्ट सर्किट करना। लूप का बाहरी भाग सभी 100 ग्राहकों को ग्राहक तालिका से खींचता है, इसलिए लूप का आंतरिक भाग 100 बार निष्पादित होता है।
शीर्ष लूप का आंतरिक भाग नेस्टेड लूप्स (इनर जॉइन) ऑपरेटर को निष्पादित करता है। निचले लूप का बाहरी भाग प्रति ग्राहक दो पंक्तियाँ बनाता है—एक NULL मामले के लिए और दूसरी वर्तमान ग्राहक ID के लिए, इस क्रम में। मर्ज इंटरवल ऑपरेटर को भ्रमित न होने दें। यह आम तौर पर ओवरलैपिंग अंतरालों को मर्ज करने के लिए उपयोग किया जाता है, उदाहरण के लिए, एक विधेय जैसे col1 20 और 30 के बीच या col1 25 और 35 के बीच 20 और 35 के बीच col1 में परिवर्तित हो जाता है। इस विचार को IN विधेय में डुप्लिकेट को हटाने के लिए सामान्यीकृत किया जा सकता है। हमारे मामले में, वास्तव में कोई डुप्लिकेट नहीं हो सकता है। सरल शब्दों में, जैसा कि उल्लेख किया गया है, लूप के बाहरी भाग को प्रति ग्राहक दो पंक्तियों के रूप में समझें-पहला NULL केस के लिए, और दूसरा वर्तमान ग्राहक ID के लिए। फिर लूप का आंतरिक भाग पहले NULL की तलाश के लिए ऑर्डर पर इंडेक्स idx_custid में खोज करता है। यदि कोई NULL पाया जाता है, तो यह वर्तमान ग्राहक आईडी के लिए दूसरी खोज को सक्रिय नहीं करता है (शीर्ष एंटी सेमी जॉइन लूप द्वारा नियंत्रित शॉर्ट सर्किट को याद रखें)। ऐसे मामले में, बाहरी ग्राहक को छोड़ दिया जाता है। लेकिन अगर कोई NULL नहीं मिलता है, तो निचला लूप ऑर्डर में मौजूदा ग्राहक आईडी देखने के लिए दूसरी खोज को सक्रिय करता है। यदि यह पाया जाता है, तो बाहरी ग्राहक को छोड़ दिया जाता है। यदि यह नहीं मिला, तो बाहरी ग्राहक को वापस कर दिया जाता है। इसका मतलब यह है कि जब ऑर्डर में एनयूएलएल मौजूद नहीं होते हैं, तो यह योजना प्रति ग्राहक दो खोज करती है! इसे प्लान में बॉटम लूप के बाहरी इनपुट में 200 पंक्तियों की संख्या के रूप में देखा जा सकता है। परिणामस्वरूप, यहाँ I/O आँकड़े हैं जो पहले निष्पादन के लिए रिपोर्ट किए गए हैं:
Table 'Orders'. Scan count 200, logical reads 603
ऑर्डर तालिका में NULL वाली एक पंक्ति जोड़े जाने के बाद क्वेरी 3 के दूसरे निष्पादन की योजना को चित्र 4 में दिखाया गया है।
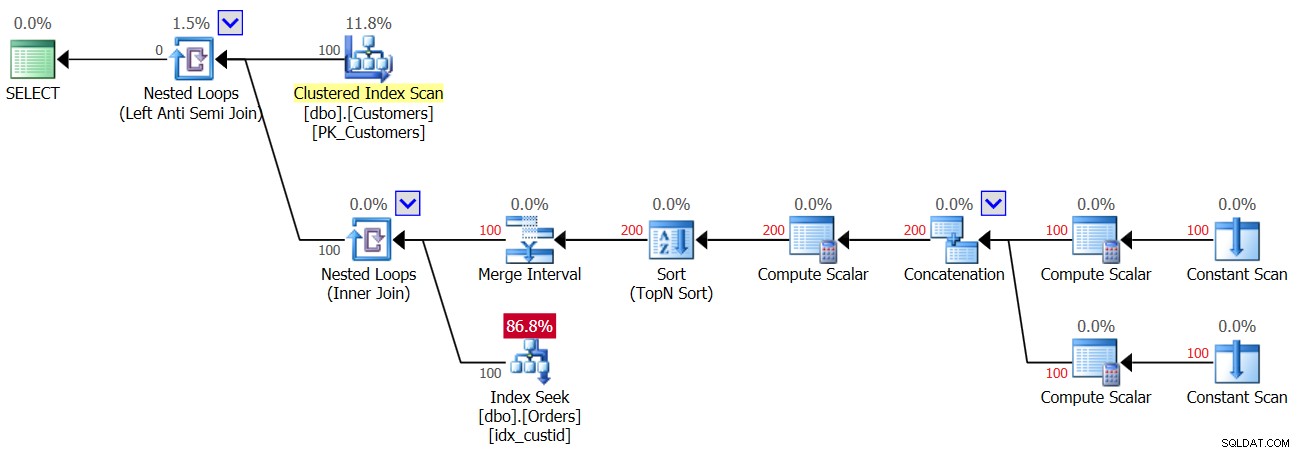 चित्र 4:क्वेरी 3 के दूसरे निष्पादन की योजना
चित्र 4:क्वेरी 3 के दूसरे निष्पादन की योजना
चूंकि तालिका में एक NULL मौजूद है, सभी ग्राहकों के लिए, इंडेक्स सीक ऑपरेटर का पहला निष्पादन एक मैच ढूंढता है, और इसलिए सभी ग्राहकों को छोड़ दिया जाता है। तो हाँ, हम प्रति ग्राहक केवल एक खोज करते हैं और दो नहीं, इसलिए इस बार आपको 100 तलाशें मिलती हैं न कि 200; हालांकि, साथ ही इसका मतलब है कि आपको एक खाली परिणाम वापस मिल रहा है!
दूसरे निष्पादन के लिए रिपोर्ट किए गए I/O आँकड़े यहां दिए गए हैं:
Table 'Orders'. Scan count 100, logical reads 300
इस कार्य का एक समाधान जब सबक्वेरी में दिए गए मानों के बीच NULLs संभव हैं, तो बस उन्हें फ़िल्टर करना है, जैसे (इसे समाधान 1/क्वेरी 4 कहते हैं):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
यह कोड अपेक्षित आउटपुट उत्पन्न करता है:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
इस समाधान का नकारात्मक पक्ष यह है कि आपको फ़िल्टर जोड़ने के लिए याद रखना होगा। मैं NOT EXISTS विधेय का उपयोग करके एक समाधान पसंद करता हूं, जहां सबक्वेरी का ग्राहक के ग्राहक आईडी के साथ ऑर्डर की ग्राहक आईडी की तुलना करने के लिए एक स्पष्ट सहसंबंध है, जैसे (इसे समाधान 2/क्वेरी 5 कहते हैं):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
याद रखें कि NULL और किसी भी चीज़ के बीच समानता-आधारित तुलना UNKNOWN उत्पन्न करती है, और UNKNOWN WHERE फ़िल्टर द्वारा त्याग दी जाती है। इसलिए यदि ऑर्डर में NULLs मौजूद हैं, तो वे आपके द्वारा स्पष्ट NULL उपचार जोड़ने की आवश्यकता के बिना आंतरिक क्वेरी के फ़िल्टर द्वारा समाप्त हो जाते हैं, और इसलिए आपको इस बारे में चिंता करने की आवश्यकता नहीं है कि NULLs डेटा में मौजूद हैं या नहीं।
यह क्वेरी अपेक्षित आउटपुट उत्पन्न करती है:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
दोनों समाधानों की योजनाएं चित्र 5 में दिखाई गई हैं।
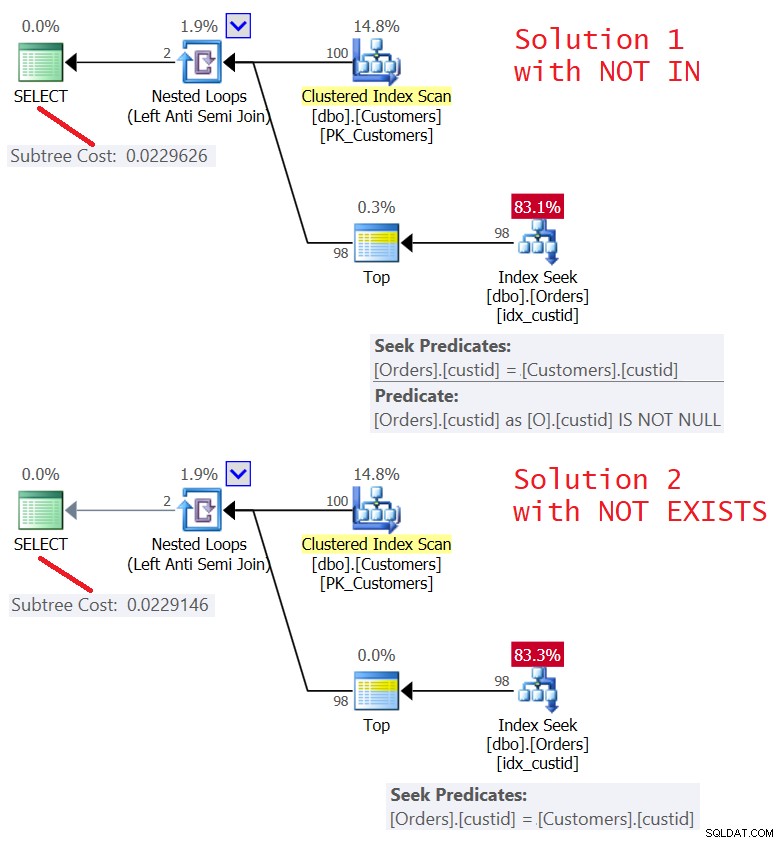 चित्र 5:प्रश्न 4 (समाधान 1) और प्रश्न 5 (समाधान 2) के लिए योजनाएं )
चित्र 5:प्रश्न 4 (समाधान 1) और प्रश्न 5 (समाधान 2) के लिए योजनाएं )
जैसा कि आप देख सकते हैं कि योजनाएं लगभग समान हैं। शॉर्ट-सर्किट के साथ लेफ्ट सेमी जॉइन ऑप्टिमाइज़ेशन का उपयोग करते हुए, वे काफी कुशल भी हैं। दोनों ऑर्डर पर इंडेक्स idx_custid में केवल 100 खोज करते हैं, और शीर्ष ऑपरेटर के साथ, पत्ती में एक पंक्ति को छूने के बाद शॉर्ट सर्किट लागू करते हैं।
दोनों प्रश्नों के लिए I/O आँकड़े समान हैं:
Table 'Orders'. Scan count 100, logical reads 348
हालांकि विचार करने वाली एक बात यह है कि क्या बाहरी तालिका के लिए सहसंबद्ध कॉलम (हमारे मामले में संरक्षक) में एनयूएलएल होने का कोई मौका है। ग्राहक-आदेश जैसे परिदृश्य में प्रासंगिक होने की बहुत संभावना नहीं है, लेकिन अन्य परिदृश्यों में प्रासंगिक हो सकता है। यदि वास्तव में ऐसा है, तो दोनों समाधान बाहरी NULL को गलत तरीके से संभालते हैं।
इसे प्रदर्शित करने के लिए, नीचे दिए गए कोड को चलाकर ग्राहक तालिका को NULL के साथ ग्राहक आईडी में से एक के रूप में छोड़ दें और फिर से बनाएं:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); . से समाधान 1 एक बाहरी NULL नहीं लौटाएगा, भले ही कोई आंतरिक NULL मौजूद हो या नहीं।
समाधान 2 एक बाहरी NULL लौटाएगा, भले ही कोई आंतरिक NULL मौजूद हो या नहीं।
यदि आप एनयूएलएल को संभालना चाहते हैं जैसे आप गैर-शून्य मानों को संभालते हैं, यानी, ग्राहकों में मौजूद होने पर न्यूल वापस कर दें, लेकिन ऑर्डर में नहीं, और दोनों में मौजूद होने पर इसे वापस न करें, आपको विशिष्टता का उपयोग करने के लिए समाधान के तर्क को बदलने की जरूरत है समानता-आधारित तुलना के बजाय आधारित तुलना। इसे EXISTS विधेय और EXCEPT सेट ऑपरेटर के संयोजन से प्राप्त किया जा सकता है, जैसे (इस समाधान 3/क्वेरी 6 को कॉल करें):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
चूंकि वर्तमान में ग्राहकों और ऑर्डर दोनों में एनयूएलएल हैं, इसलिए यह क्वेरी सही ढंग से न्यूल नहीं लौटाती है। यह रहा क्वेरी आउटपुट:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
आदेश तालिका से NULL वाली पंक्ति को निकालने के लिए निम्न कोड चलाएँ और समाधान 3 को फिर से चलाएँ:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
इस बार, चूंकि NULL ग्राहकों में मौजूद है, लेकिन ऑर्डर में नहीं, परिणाम में NULL शामिल है:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
इस समाधान की योजना चित्र 6 में दिखाई गई है:
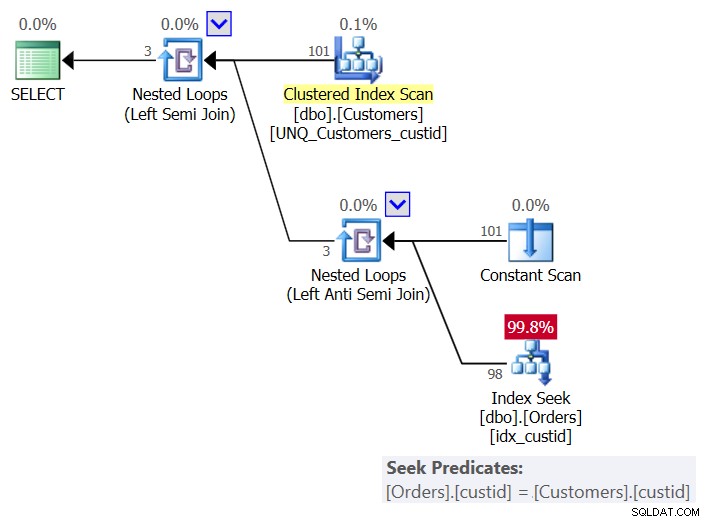 चित्र 6:प्रश्न 6 के लिए योजना (समाधान 3)
चित्र 6:प्रश्न 6 के लिए योजना (समाधान 3)
प्रति ग्राहक, योजना मौजूदा ग्राहक के साथ एक पंक्ति बनाने के लिए एक कॉन्स्टेंट स्कैन ऑपरेटर का उपयोग करती है, और यह जांचने के लिए कि ग्राहक ऑर्डर में मौजूद है या नहीं, ऑर्डर पर इंडेक्स idx_custid में सिंगल सीक लागू करता है। आप प्रति ग्राहक एक खोज के साथ समाप्त होते हैं। चूँकि वर्तमान में हमारे पास तालिका में 101 ग्राहक हैं, इसलिए हमें 101 खोज प्राप्त होती हैं।
इस क्वेरी के लिए I/O आँकड़े यहां दिए गए हैं:
Table 'Orders'. Scan count 101, logical reads 415
निष्कर्ष
इस महीने मैंने सबक्वायरी से संबंधित बग, नुकसान और सर्वोत्तम प्रथाओं को कवर किया। मैंने प्रतिस्थापन त्रुटियों और तीन-मूल्यवान तर्क समस्याओं को कवर किया। सभी तालिकाओं में संगत स्तंभ नामों का उपयोग करना याद रखें, और तालिका हमेशा उपश्रेणियों में स्तंभों को योग्य बनाएं, भले ही वे स्वयं निहित हों। यह भी याद रखें कि जब कॉलम को NULLs की अनुमति नहीं दी जाती है, और जब आपके डेटा में संभव हो तो NULLs को हमेशा ध्यान में रखते हुए NOT NULL बाधा लागू करना याद रखें। सुनिश्चित करें कि आप अपने नमूना डेटा में एनयूएलएल शामिल करते हैं जब उन्हें अनुमति दी जाती है ताकि परीक्षण करते समय आप अपने कोड में बग को आसानी से पकड़ सकें। सबक्वेरी के साथ संयुक्त होने पर NOT IN विधेय से सावधान रहें। यदि आंतरिक क्वेरी के परिणाम में NULLs संभव हैं, तो NOT EXISTS विधेय आमतौर पर पसंदीदा विकल्प होता है।