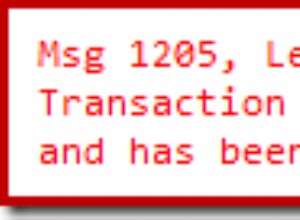
SQL सर्वर हमें कई विंडो फ़ंक्शन प्रदान करता है जो हमें डेटाबेस में कॉल को दोहराने की आवश्यकता के बिना पंक्तियों के एक सेट में गणना करने में मदद करता है। मानक कुल कार्यों के विपरीत, विंडो फ़ंक्शन पंक्तियों को एक आउटपुट पंक्ति में समूहित नहीं करेंगे, वे उन पंक्तियों के लिए अलग पहचान रखते हुए, प्रत्येक पंक्ति के लिए एक एकल समेकित मान लौटाएंगे। यहां विंडो शब्द माइक्रोसॉफ्ट विंडोज ऑपरेटिंग सिस्टम से संबंधित नहीं है, यह उन पंक्तियों के सेट का वर्णन करता है जिन्हें फ़ंक्शन संसाधित करेगा।
विंडो फ़ंक्शंस के सबसे उपयोगी प्रकारों में से एक है रैंकिंग विंडो फ़ंक्शंस जिनका उपयोग विशिष्ट फ़ील्ड मानों को रैंक करने और प्रत्येक पंक्ति के रैंक के अनुसार उन्हें वर्गीकृत करने के लिए किया जाता है, जिसके परिणामस्वरूप प्रत्येक भाग लेने वाली पंक्ति के लिए एक एकल समेकित मान होता है। SQL सर्वर में समर्थित चार रैंकिंग विंडो फ़ंक्शन हैं; ROW_NUMBER (), रैंक (), DENSE_RANK (), और NTILE ()। इन सभी कार्यों का उपयोग अपने तरीके से प्रदान की गई पंक्तियों की विंडो के लिए ROWID की गणना करने के लिए किया जाता है।
चार रैंकिंग विंडो फ़ंक्शन ओवर () क्लॉज का उपयोग करते हैं जो क्वेरी परिणाम सेट के भीतर पंक्तियों के उपयोगकर्ता द्वारा निर्दिष्ट सेट को परिभाषित करता है। ओवर () क्लॉज को परिभाषित करके, आप पार्टिशन बाय क्लॉज को भी शामिल कर सकते हैं जो विभाजन को परिभाषित करने के लिए कॉलम या कॉमा से अलग किए गए कॉलम प्रदान करके विंडो फ़ंक्शन द्वारा संसाधित की जाने वाली पंक्तियों के सेट को निर्धारित करता है। इसके अलावा, ORDER BY खंड को शामिल किया जा सकता है, जो विभाजन के भीतर छँटाई मानदंड को परिभाषित करता है कि प्रसंस्करण के दौरान फ़ंक्शन पंक्तियों के माध्यम से जाएगा।
इस लेख में, हम चर्चा करेंगे कि चार रैंकिंग विंडो फ़ंक्शंस का उपयोग कैसे करें:ROW_NUMBER (), RANK (), DENSE_RANK (), और NTILE () व्यावहारिक रूप से, और उनके बीच का अंतर।
हमारे डेमो की सेवा के लिए, हम एक नई सरल तालिका बनाएंगे और नीचे टी-एसक्यूएल स्क्रिप्ट का उपयोग करके तालिका में कुछ रिकॉर्ड डालेंगे:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
आप निम्न SELECT स्टेटमेंट का उपयोग करके जांच सकते हैं कि डेटा सफलतापूर्वक डाला गया है:
SELECT * FROM StudentScore ORDER BY Student_Scoreसॉर्ट किए गए परिणाम लागू होने के साथ, परिणाम सेट इस प्रकार है:

ROW_NUMBER()
ROW_NUMBER() रैंकिंग विंडो फ़ंक्शन निर्दिष्ट विंडो के विभाजन के भीतर प्रत्येक पंक्ति के लिए एक अद्वितीय अनुक्रमिक संख्या देता है, प्रत्येक विभाजन में पहली पंक्ति के लिए 1 से शुरू होता है और प्रत्येक विभाजन के रैंकिंग परिणाम में संख्याओं को दोहराए या छोड़े बिना। यदि पंक्ति सेट में डुप्लिकेट मान हैं, तो रैंकिंग आईडी नंबर मनमाने ढंग से असाइन किए जाएंगे। यदि खंड द्वारा विभाजन निर्दिष्ट किया गया है, तो प्रत्येक विभाजन के लिए रैंकिंग पंक्ति संख्या को रीसेट कर दिया जाएगा। पहले बनाई गई तालिका में, नीचे दी गई क्वेरी से पता चलता है कि ROW_NUMBER रैंकिंग विंडो फ़ंक्शन का उपयोग कैसे करें ताकि प्रत्येक छात्र के स्कोर के अनुसार स्टूडेंटस्कोर तालिका पंक्तियों को रैंक किया जा सके:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
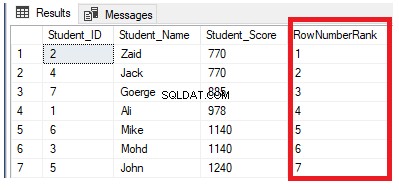
नीचे दिए गए परिणाम से यह स्पष्ट है कि ROW_NUMBER विंडो फ़ंक्शन प्रत्येक पंक्ति के लिए Student_Score कॉलम मानों के अनुसार तालिका पंक्तियों को रैंक करता है, प्रत्येक पंक्ति की एक अद्वितीय संख्या उत्पन्न करता है जो डुप्लिकेट या अंतराल के बिना नंबर 1 से शुरू होने वाली अपनी Student_Score रैंकिंग को दर्शाता है और सभी पंक्तियों को एक विभाजन के रूप में व्यवहार करना। आप यह भी देख सकते हैं कि डुप्लिकेट स्कोर अलग-अलग रैंकों को यादृच्छिक रूप से असाइन किए गए हैं:
यदि हम एक से अधिक विभाजन के लिए पार्टिशन बाय क्लॉज को शामिल करके पिछली क्वेरी को संशोधित करते हैं, जैसा कि नीचे टी-एसक्यूएल क्वेरी में दिखाया गया है:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
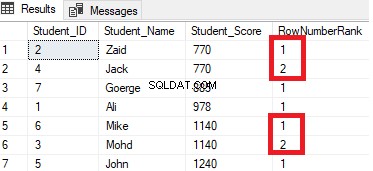
परिणाम दिखाएगा कि ROW_NUMBER विंडो फ़ंक्शन प्रत्येक पंक्ति के लिए Student_Score कॉलम मानों के अनुसार तालिका पंक्तियों को रैंक करेगा, लेकिन यह उन पंक्तियों से निपटेगा जिनका एक विभाजन के रूप में समान Student_Score मान है। आप देखेंगे कि प्रत्येक पंक्ति के लिए एक अद्वितीय संख्या उत्पन्न होगी जो उसकी छात्र_स्कोर रैंकिंग को दर्शाती है, एक ही विभाजन के भीतर डुप्लिकेट या अंतराल के बिना नंबर 1 से शुरू होकर, एक अलग छात्र_स्कोर मान पर जाने पर रैंक संख्या को रीसेट करना।
उदाहरण के लिए, 770 अंक प्राप्त करने वाले छात्रों को एक रैंक संख्या निर्दिष्ट करके उस स्कोर के भीतर रैंक किया जाएगा। हालांकि, जब इसे 885 अंक वाले छात्र के पास ले जाया जाता है, तो रैंक की शुरुआती संख्या 1 पर फिर से शुरू करने के लिए रीसेट हो जाएगी, जैसा कि नीचे दिखाया गया है:
रैंक ()
रैंक () रैंकिंग विंडो फ़ंक्शन एक निर्दिष्ट कॉलम मान के अनुसार विभाजन के भीतर प्रत्येक विशिष्ट पंक्ति के लिए एक अद्वितीय रैंक संख्या देता है, प्रत्येक विभाजन में पहली पंक्ति के लिए 1 से शुरू होता है, डुप्लिकेट मानों के लिए समान रैंक के साथ और रैंकों के बीच अंतराल छोड़कर; डुप्लिकेट मानों के बाद अनुक्रम में यह अंतर दिखाई देता है। दूसरे शब्दों में, रैंक () रैंकिंग विंडो फ़ंक्शन समान मूल्यों वाली पंक्तियों को छोड़कर ROW_NUMBER () फ़ंक्शन की तरह व्यवहार करता है, जहां यह समान रैंक आईडी के साथ रैंक करेगा और इसके बाद एक अंतर उत्पन्न करेगा। यदि हम RANK() रैंकिंग फ़ंक्शन का उपयोग करने के लिए पिछली रैंकिंग क्वेरी को संशोधित करते हैं:
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreआप परिणाम से देखेंगे कि RANK विंडो फ़ंक्शन प्रत्येक पंक्ति के लिए Student_Score कॉलम मानों के अनुसार तालिका पंक्तियों को रैंक करेगा, एक रैंकिंग मान के साथ इसका Student_Score नंबर 1 से शुरू होता है, और उन पंक्तियों की रैंकिंग करता है जिनमें समान Student_Score होता है। समान रैंक मान। आप यह भी देख सकते हैं कि 770 के बराबर स्टूडेंट_स्कोर वाली दो पंक्तियों को एक ही मान के साथ रैंक किया गया है, जो दूसरी रैंक वाली पंक्ति के बाद एक अंतर छोड़ देता है, जो छूटी हुई संख्या 2 है। ऐसा ही उन पंक्तियों के साथ होता है जहां छात्र_स्कोर 1140 के बराबर होता है, जो समान मान के साथ रैंक किया जाता है, एक अंतर छोड़ता है, जो कि दूसरी पंक्ति के बाद लापता संख्या 6 है, जैसा कि नीचे दिखाया गया है:
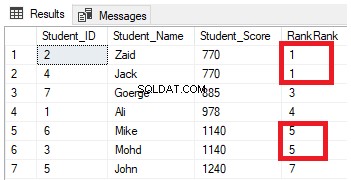
पार्टिशन बाय क्लॉज को शामिल करके पिछली क्वेरी को एक से अधिक पार्टीशन के लिए संशोधित करना, जैसा कि नीचे टी-एसक्यूएल क्वेरी में दिखाया गया है:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreरैंकिंग परिणाम का कोई मतलब नहीं होगा, क्योंकि रैंक प्रत्येक विभाजन के अनुसार Student_Score मानों के अनुसार किया जाएगा, और डेटा को Student_Score मानों के अनुसार विभाजित किया जाएगा। और इस तथ्य के कारण कि प्रत्येक विभाजन में समान Student_Score मानों वाली पंक्तियाँ होंगी, एक ही विभाजन में समान Student_Score मानों वाली पंक्तियों को 1 के बराबर मान के साथ रैंक किया जाएगा। इस प्रकार, दूसरे विभाजन में जाने पर, रैंक होगा रीसेट किया जा सकता है, नंबर 1 के साथ फिर से शुरू करना, जिसमें सभी रैंकिंग मान 1 के बराबर हों, जैसा कि नीचे दिखाया गया है:
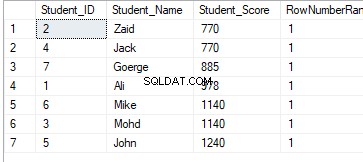
DENSE_RANK()
DENSE_RANK () रैंकिंग विंडो फ़ंक्शन RANK () फ़ंक्शन के समान है, जो एक निर्दिष्ट कॉलम मान के अनुसार विभाजन के भीतर प्रत्येक विशिष्ट पंक्ति के लिए एक अद्वितीय रैंक संख्या उत्पन्न करता है, प्रत्येक विभाजन में पहली पंक्ति के लिए 1 से शुरू होकर, पंक्तियों की रैंकिंग के साथ समान रैंक संख्या के साथ समान मान, सिवाय इसके कि यह किसी रैंक को नहीं छोड़ता है, रैंकों के बीच कोई अंतराल नहीं छोड़ता है।
यदि हम DENSE_RANK() रैंकिंग फ़ंक्शन का उपयोग करने के लिए पिछली रैंकिंग क्वेरी को फिर से लिखते हैं:
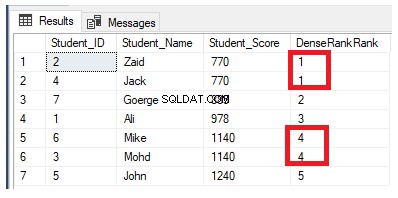
फिर से, एक से अधिक विभाजन के लिए पार्टिशन बाय क्लॉज को शामिल करके पिछली क्वेरी को संशोधित करें, जैसा कि नीचे टी-एसक्यूएल क्वेरी में दिखाया गया है:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
रैंकिंग मानों का कोई अर्थ नहीं होगा, जहां सभी पंक्तियों को मान 1 के साथ रैंक किया जाएगा, एक ही रैंकिंग मान के लिए डुप्लिकेट मान निर्दिष्ट करने और नए विभाजन को संसाधित करते समय रैंक प्रारंभिक आईडी को रीसेट करने के कारण, जैसा कि नीचे दिखाया गया है:
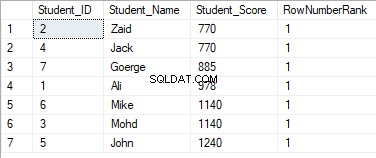
NTILE(N)
NTILE(N) रैंकिंग विंडो फ़ंक्शन का उपयोग पंक्तियों में पंक्तियों को समूहों की एक निर्दिष्ट संख्या में वितरित करने के लिए किया जाता है, पंक्ति में प्रत्येक पंक्ति को एक अद्वितीय समूह संख्या के साथ प्रदान करता है, नंबर 1 से शुरू होता है जो समूह को दिखाता है कि यह पंक्ति संबंधित है to, जहां N एक धनात्मक संख्या है, जो उन समूहों की संख्या को परिभाषित करती है जिनमें आपको सेट की गई पंक्तियों को वितरित करने की आवश्यकता है।
दूसरे शब्दों में, यदि आपको विशिष्ट स्तंभ मानों के आधार पर तालिका की विशिष्ट डेटा पंक्तियों को 3 समूहों में विभाजित करने की आवश्यकता है, तो NTILE(3) रैंकिंग विंडो फ़ंक्शन आपको इसे आसानी से प्राप्त करने में मदद करेगा।
प्रत्येक समूह में पंक्तियों की संख्या की गणना पंक्तियों की संख्या को आवश्यक समूहों में विभाजित करके की जा सकती है। यदि हम सात टेबल पंक्तियों को चार समूहों में रैंक करने के लिए NTILE(4) रैंकिंग विंडो फ़ंक्शन का उपयोग करने के लिए पिछली रैंकिंग क्वेरी को नीचे T-SQL क्वेरी के रूप में संशोधित करते हैं:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
प्रत्येक समूह में पंक्तियों की संख्या (7/4=1.75) पंक्तियाँ होनी चाहिए। NTILE () फ़ंक्शन का उपयोग करते हुए, SQL सर्वर इंजन पहले तीन समूहों को 2 पंक्तियाँ और अंतिम समूह को एक पंक्ति निर्दिष्ट करेगा, ताकि सभी पंक्तियों को समूहों में शामिल किया जा सके, जैसा कि नीचे दिए गए परिणाम में दिखाया गया है:
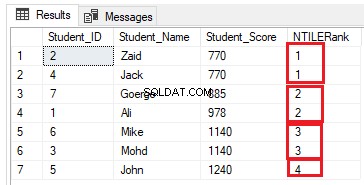
पार्टिशन बाय क्लॉज को शामिल करके पिछली क्वेरी को एक से अधिक पार्टीशन के लिए संशोधित करना, जैसा कि नीचे टी-एसक्यूएल क्वेरी में दिखाया गया है:
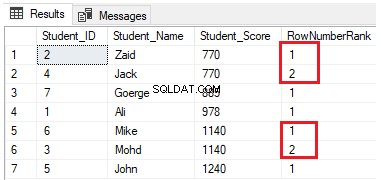
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreपंक्तियों को प्रत्येक विभाजन पर चार समूहों में वितरित किया जाएगा। उदाहरण के लिए, 770 के बराबर Student_Score वाली पहली दो पंक्तियाँ एक ही विभाजन में होंगी, और प्रत्येक को एक अद्वितीय संख्या के साथ रैंकिंग करने वाले समूहों में वितरित की जाएंगी, जैसा कि नीचे दिए गए परिणाम में दिखाया गया है:
सब को एक साथ रखना
अधिक स्पष्ट तुलना परिदृश्य के लिए, आइए हम पिछली तालिका को छोटा करें, एक और वर्गीकरण मानदंड जोड़ें, जो छात्रों की कक्षा है, और अंत में नीचे टी-एसक्यूएल स्क्रिप्ट का उपयोग करके नई सात पंक्तियां डालें:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')उसके बाद, हम प्रत्येक छात्र के स्कोर के अनुसार सात पंक्तियों को रैंक करेंगे, छात्रों को उनकी कक्षा के अनुसार विभाजित करेंगे। दूसरे शब्दों में, प्रत्येक विभाजन में एक कक्षा शामिल होगी, और छात्रों के प्रत्येक वर्ग को एक ही कक्षा के भीतर उनके स्कोर के अनुसार रैंक किया जाएगा, जैसा कि नीचे टी-एसक्यूएल स्क्रिप्ट में दिखाया गया है:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOइस तथ्य के कारण कि कोई डुप्लिकेट मान नहीं हैं, चार रैंकिंग विंडो फ़ंक्शन उसी तरह काम करेंगे, वही परिणाम लौटाएंगे, जैसा कि नीचे दिए गए परिणाम में दिखाया गया है:
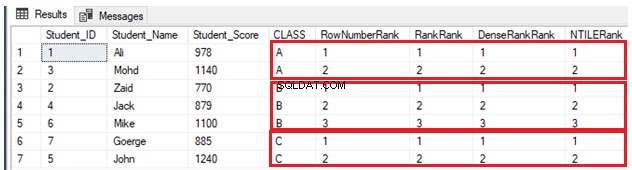
यदि किसी अन्य छात्र को कक्षा ए में एक अंक के साथ शामिल किया गया है, तो उसी कक्षा के किसी अन्य छात्र के पास पहले से ही नीचे दिए गए INSERT कथन का उपयोग है:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')ROW_NUMBER() और NTILE() रैंकिंग विंडो फ़ंक्शंस के लिए कुछ भी नहीं बदलेगा। रैंक और DENSE_RANK () फ़ंक्शन समान स्कोर वाले छात्रों के लिए समान रैंक प्रदान करेंगे, रैंक फ़ंक्शन का उपयोग करते समय डुप्लिकेट रैंक के बाद रैंक में अंतर के साथ और DENSE_RANK का उपयोग करते समय डुप्लिकेट रैंक के बाद रैंक में कोई अंतर नहीं होगा। ), जैसा कि नीचे दिए गए परिणाम में दिखाया गया है:
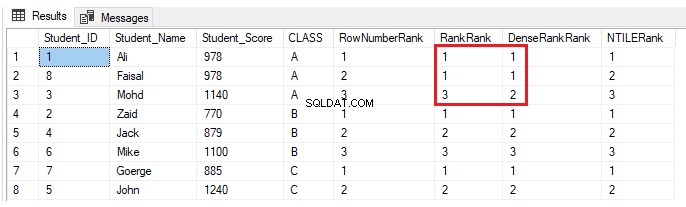
व्यावहारिक परिदृश्य
SQL सर्वर डेवलपर्स द्वारा रैंकिंग विंडो फ़ंक्शंस का व्यापक रूप से उपयोग किया जाता है। रैंकिंग फ़ंक्शंस के उपयोग के लिए सामान्य परिदृश्यों में से एक, जब आप विशिष्ट पंक्तियों को प्राप्त करना चाहते हैं और अन्य को छोड़ना चाहते हैं, तो CTE के भीतर ROW_NUMBER (,) रैंकिंग विंडो फ़ंक्शन का उपयोग करके, जैसा कि नीचे T-SQL स्क्रिप्ट में है, जो छात्रों को रैंक के साथ लौटाता है 2 और 5 और अन्य को छोड़ दें:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
परिणाम दिखाएगा कि केवल 2 और 5 के बीच रैंक वाले छात्रों को ही लौटाया जाएगा:
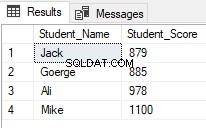
SQL सर्वर 2012 से शुरू होकर, एक नया उपयोगी आदेश, ऑफ़सेट फ़ेच नीचे टी-एसक्यूएल स्क्रिप्ट का उपयोग करके, विशिष्ट रिकॉर्ड प्राप्त करके और अन्य को छोड़ कर उसी पिछले कार्य को करने के लिए इस्तेमाल किया जा सकता है:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;जैसा कि नीचे दिखाया गया है, वही पिछला परिणाम प्राप्त करना:
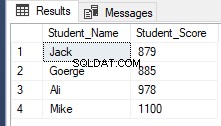
निष्कर्ष
SQL सर्वर हमें चार रैंकिंग विंडो फ़ंक्शन प्रदान करता है जो हमें विशिष्ट कॉलम मानों के अनुसार सेट की गई पंक्तियों को रैंक करने में मदद करता है। ये कार्य हैं:ROW_NUMBER (), रैंक (), DENSE_RANK () और NTILE ()। ये सभी रैंकिंग फ़ंक्शन रैंकिंग कार्य को अपने तरीके से करते हैं, पंक्तियों में कोई डुप्लिकेट मान नहीं होने पर समान परिणाम लौटाते हैं। यदि पंक्ति सेट के भीतर कोई डुप्लिकेट मान है, तो RANK फ़ंक्शन समान मान वाली सभी पंक्तियों के लिए समान रैंकिंग ID असाइन करेगा, जिससे डुप्लिकेट के बाद रैंकों के बीच अंतराल रह जाएगा। DENSE_RANK फ़ंक्शन समान मान वाली सभी पंक्तियों के लिए समान रैंकिंग आईडी निर्दिष्ट करेगा, लेकिन डुप्लिकेट के बाद रैंकों के बीच कोई अंतर नहीं छोड़ेगा। हम इस लेख के भीतर विभिन्न परिदृश्यों से गुजरते हैं ताकि सभी संभावित मामलों को कवर किया जा सके जो आपको रैंकिंग विंडो के कार्यों को व्यावहारिक रूप से समझने में मदद करते हैं।
संदर्भ:
- ROW_NUMBER (लेनदेन-एसक्यूएल)
- रैंक (लेनदेन-एसक्यूएल)
- DENSE_RANK (लेनदेन-एसक्यूएल)
- NTILE (ट्रांजैक्ट-एसक्यूएल)
- ऑफसेट फ़ेच क्लॉज़ (एसक्यूएल सर्वर कॉम्पैक्ट)