क्या आप अभी भी पैरेंट/चाइल्ड डिज़ाइन पर कायम हैं, या कुछ नया आज़माना चाहेंगे, जैसे SQL सर्वर पदानुक्रम आईडी? खैर, यह वास्तव में नया है क्योंकि 2008 से पदानुक्रम आईडी SQL सर्वर का हिस्सा रहा है। बेशक, नवीनता स्वयं एक प्रेरक तर्क नहीं है। लेकिन ध्यान दें कि Microsoft ने इस सुविधा को कई स्तरों के साथ एक-से-अनेक संबंधों को बेहतर तरीके से प्रस्तुत करने के लिए जोड़ा है।
आपको आश्चर्य हो सकता है कि सामान्य माता-पिता/बाल संबंधों के बजाय पदानुक्रम आईडी का उपयोग करने से आपको क्या फर्क पड़ता है और आपको कौन से लाभ मिलते हैं। यदि आपने इस विकल्प को कभी नहीं खोजा, तो यह आपके लिए आश्चर्यजनक हो सकता है।
सच तो यह है, मैंने इस विकल्प को रिलीज़ होने के बाद से नहीं खोजा। हालाँकि, जब मैंने आखिरकार इसे किया, तो मुझे यह एक महान नवाचार लगा। यह एक बेहतर दिखने वाला कोड है, लेकिन इसमें और भी बहुत कुछ है। इस लेख में, हम उन सभी बेहतरीन अवसरों के बारे में जानेंगे।
हालाँकि, इससे पहले कि हम SQL सर्वर पदानुक्रम आईडी का उपयोग करने की ख़ासियत में गोता लगाएँ, आइए इसके अर्थ और दायरे को स्पष्ट करें।
SQL Server HierarchyID क्या है?
SQL सर्वर पदानुक्रम आईडी एक अंतर्निहित डेटा प्रकार है जिसे पेड़ों का प्रतिनिधित्व करने के लिए डिज़ाइन किया गया है, जो कि पदानुक्रमित डेटा का सबसे सामान्य प्रकार है। पेड़ में प्रत्येक वस्तु को नोड कहा जाता है। तालिका प्रारूप में, यह पदानुक्रम आईडी डेटा प्रकार के स्तंभ वाली एक पंक्ति है।
आमतौर पर, हम टेबल डिज़ाइन का उपयोग करके पदानुक्रम प्रदर्शित करते हैं। एक आईडी कॉलम एक नोड का प्रतिनिधित्व करता है, और दूसरा कॉलम पैरेंट के लिए होता है। SQL सर्वर HierarchyID के साथ, हमें डेटा प्रकार के पदानुक्रम के साथ केवल एक कॉलम की आवश्यकता होती है।
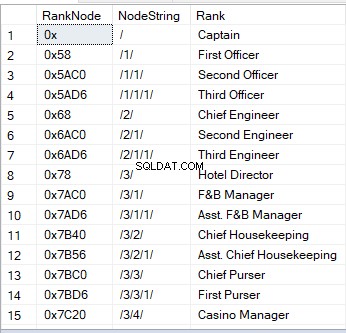
जब आप किसी पदानुक्रम आईडी स्तंभ वाली तालिका को क्वेरी करते हैं, तो आपको हेक्साडेसिमल मान दिखाई देते हैं। यह एक नोड की दृश्य छवियों में से एक है। दूसरा तरीका एक स्ट्रिंग है:
'/' का मतलब रूट नोड है;
'/1/', '/2/', '/3/' या '/n/' बच्चों के लिए खड़ा है - प्रत्यक्ष वंशज 1 से n;
'/1/1/' या '/1/2/' "बच्चों के बच्चे - "पोते" हैं। स्ट्रिंग जैसे '/1/2/' का अर्थ है कि जड़ से पहले बच्चे के दो बच्चे हैं, जो बदले में, जड़ के दो पोते हैं।
यह कैसा दिखता है इसका एक नमूना यहां दिया गया है:
अन्य डेटा प्रकारों के विपरीत, पदानुक्रम आईडी कॉलम अंतर्निहित विधियों का लाभ उठा सकते हैं। उदाहरण के लिए, यदि आपके पास RankNode . नामक एक पदानुक्रम आईडी कॉलम है , आपके पास निम्न सिंटैक्स हो सकता है:
रैंकनोड।<विधिनाम> ।
SQL सर्वर पदानुक्रम आईडी विधियाँ
उपलब्ध विधियों में से एक है IsDescendantOf . यह 1 लौटाता है यदि वर्तमान नोड एक पदानुक्रम आईडी मान का वंशज है।
आप नीचे दिए गए तरीके के समान इस विधि से कोड लिख सकते हैं:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1पदानुक्रम आईडी के साथ उपयोग की जाने वाली अन्य विधियां निम्नलिखित हैं:
- GetRoot - स्थिर विधि जो पेड़ की जड़ लौटाती है।
- GetDescendant - माता-पिता का चाइल्ड नोड लौटाता है।
- GetAncestor - किसी दिए गए नोड के nवें पूर्वज का प्रतिनिधित्व करने वाला एक पदानुक्रम आईडी देता है।
- GetLevel - एक पूर्णांक देता है जो नोड की गहराई को दर्शाता है।
- ToString - एक नोड के तार्किक प्रतिनिधित्व के साथ स्ट्रिंग लौटाता है। टूस्ट्रिंग परोक्ष रूप से कहा जाता है जब पदानुक्रम आईडी से स्ट्रिंग प्रकार में रूपांतरण होता है।
- GetReparentedValue - एक नोड को पुराने पैरेंट से नए पैरेंट में ले जाता है।
- पार्स - ToString . के विपरीत कार्य करता है . यह एक पदानुक्रम आईडी . के स्ट्रिंग दृश्य को रूपांतरित करता है हेक्साडेसिमल के लिए मान।
SQL सर्वर पदानुक्रमID अनुक्रमण रणनीतियाँ
यह सुनिश्चित करने के लिए कि पदानुक्रम आईडी का उपयोग करने वाली तालिकाओं के लिए क्वेरी जितनी जल्दी हो सके, आपको कॉलम को अनुक्रमित करने की आवश्यकता है। दो अनुक्रमण कार्यनीतियां हैं:
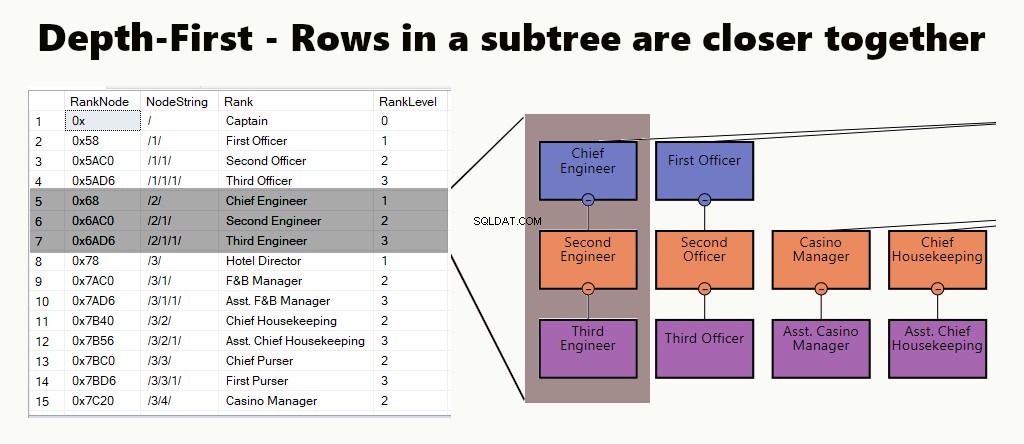
गहराई-पहली
डेप्थ-फर्स्ट इंडेक्स में, सबट्री रो एक दूसरे के करीब होते हैं। यह एक विभाग, उसके उप-इकाइयों और कर्मचारियों को खोजने जैसे प्रश्नों के अनुकूल है। एक अन्य उदाहरण एक प्रबंधक और उसके कर्मचारियों का एक साथ संग्रह करना है।
एक तालिका में, आप नोड्स के लिए एक संकुल सूचकांक बनाकर एक गहराई-प्रथम सूचकांक लागू कर सकते हैं। इसके अलावा, हम अपना एक उदाहरण ठीक उसी तरह करते हैं।
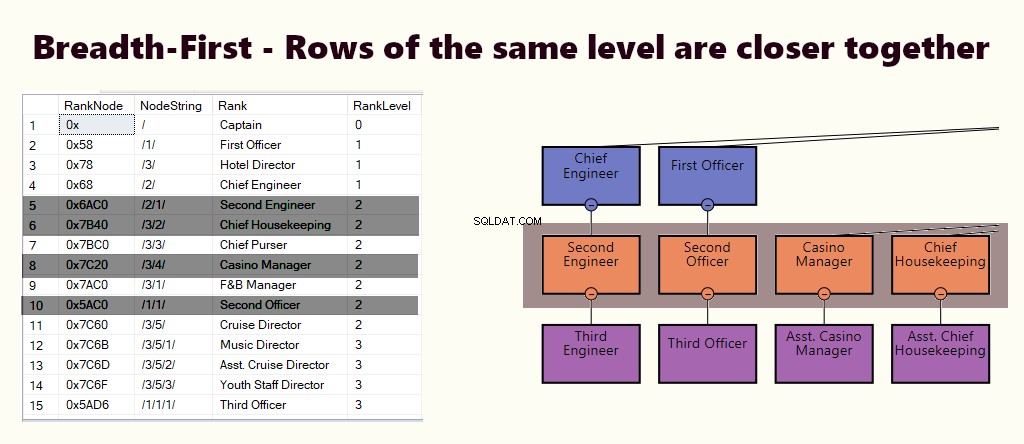
चौड़ाई-पहली
चौड़ाई-प्रथम सूचकांक में, समान स्तर की पंक्तियाँ एक साथ करीब होती हैं। यह सभी प्रबंधक के सीधे रिपोर्टिंग कर्मचारियों को खोजने जैसे प्रश्नों के अनुकूल है। यदि अधिकांश प्रश्न इसी तरह के हैं, तो (1) स्तर और (2) नोड के आधार पर एक संकुल अनुक्रमणिका बनाएं।
यह आपकी आवश्यकताओं पर निर्भर करता है यदि आपको गहराई-पहली अनुक्रमणिका, चौड़ाई-प्रथम, या दोनों की आवश्यकता है। आपको प्रश्नों के प्रकार के महत्व और टेबल पर आपके द्वारा निष्पादित डीएमएल स्टेटमेंट के बीच संतुलन बनाने की आवश्यकता है।
SQL सर्वर पदानुक्रम आईडी सीमाएं
दुर्भाग्य से, पदानुक्रम आईडी का उपयोग करने से सभी समस्याओं का समाधान नहीं हो सकता:
- एसक्यूएल सर्वर यह अनुमान नहीं लगा सकता कि माता-पिता का बच्चा क्या है। आपको तालिका में पेड़ को परिभाषित करना होगा।
- यदि आप एक अद्वितीय बाधा का उपयोग नहीं करते हैं, तो उत्पन्न पदानुक्रम आईडी मान अद्वितीय नहीं होगा। इस समस्या से निपटना डेवलपर की जिम्मेदारी है।
- माता-पिता और चाइल्ड नोड्स के संबंध विदेशी कुंजी संबंध की तरह लागू नहीं होते हैं। इसलिए, किसी नोड को हटाने से पहले, मौजूदा वंशजों के लिए क्वेरी करें।
पदानुक्रमों को विज़ुअलाइज़ करना
आगे बढ़ने से पहले, एक और प्रश्न पर विचार करें। नोड स्ट्रिंग्स के साथ सेट किए गए परिणाम को देखते हुए, क्या आप पदानुक्रम को अपनी आंखों के लिए कठिन कल्पना करते हुए पाते हैं?
मेरे लिए, यह एक बड़ी हां है क्योंकि मैं छोटा नहीं हो रहा हूं।
इस कारण से, हम अपने डेटाबेस टेबल के साथ एक्वेलॉन से पावर बीआई और पदानुक्रम चार्ट का उपयोग करने जा रहे हैं। वे एक संगठनात्मक चार्ट में पदानुक्रम प्रदर्शित करने में मदद करेंगे। मुझे उम्मीद है कि इससे काम आसान हो जाएगा।
अब, व्यापार पर चलते हैं।
SQL सर्वर HierarchyID के उपयोग
आप निम्न व्यावसायिक परिदृश्यों के साथ HierarchyID का उपयोग कर सकते हैं:
- संगठनात्मक संरचना
- फ़ोल्डर, सबफ़ोल्डर, और फ़ाइलें
- परियोजना में कार्य और उप-कार्य
- वेबसाइट के पृष्ठ और उपपृष्ठ
- देशों, क्षेत्रों और शहरों के साथ भौगोलिक डेटा
यहां तक कि अगर आपका व्यवसाय परिदृश्य उपरोक्त के समान है, और आप शायद ही कभी पदानुक्रम अनुभागों में क्वेरी करते हैं, तो आपको पदानुक्रम आईडी की आवश्यकता नहीं है।
उदाहरण के लिए, आपका संगठन कर्मचारियों के लिए पेरोल की प्रक्रिया करता है। क्या आपको किसी के पेरोल को संसाधित करने के लिए सबट्री तक पहुंचने की आवश्यकता है? बिल्कुल भी नहीं। हालाँकि, यदि आप बहु-स्तरीय विपणन प्रणाली में लोगों के कमीशन की प्रक्रिया करते हैं, तो यह भिन्न हो सकता है।
इस पोस्ट में, हम एक क्रूज जहाज पर संगठनात्मक संरचना के हिस्से और कमांड की श्रृंखला का उपयोग करते हैं। संरचना को यहां से संगठनात्मक चार्ट से अनुकूलित किया गया था। इसे नीचे चित्र 4 में देखें:

अब आप विचाराधीन पदानुक्रम की कल्पना कर सकते हैं। हम इस पूरी पोस्ट में नीचे दी गई तालिकाओं का उपयोग करते हैं:
- जहाज - क्रूज जहाजों की सूची के लिए खड़ी तालिका है।
- रैंक - चालक दल के रैंकों की तालिका है। वहां हम पदानुक्रम आईडी का उपयोग करके पदानुक्रम स्थापित करते हैं।
- चालक दल - प्रत्येक पोत के चालक दल और उनके रैंकों की सूची है।
प्रत्येक मामले की तालिका संरचना इस प्रकार है:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOSQL सर्वर पदानुक्रम आईडी के साथ तालिका डेटा सम्मिलित करना
पदानुक्रम आईडी का पूरी तरह से उपयोग करने में पहला कार्य एक पदानुक्रम आईडी . के साथ तालिका में रिकॉर्ड जोड़ना है कॉलम। इसे करने के दो तरीके हैं।
स्ट्रिंग का उपयोग करना
पदानुक्रम के साथ डेटा सम्मिलित करने का सबसे तेज़ तरीका स्ट्रिंग्स का उपयोग करना है। इसे कार्य में देखने के लिए, आइए कुछ रिकॉर्ड रैंक . में जोड़ें टेबल।
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)उपरोक्त कोड रैंक तालिका में 20 रिकॉर्ड जोड़ता है।
जैसा कि आप देख सकते हैं, पेड़ की संरचना को INSERT . में परिभाषित किया गया है ऊपर बयान। जब हम स्ट्रिंग्स का उपयोग करते हैं तो यह आसानी से समझ में आता है। इसके अलावा, SQL सर्वर इसे संगत हेक्साडेसिमल मानों में परिवर्तित करता है।
Max(), GetAncestor(), और GetDescendant()
का उपयोग करनास्ट्रिंग्स का उपयोग करना प्रारंभिक डेटा को पॉप्युलेट करने के कार्य के लिए उपयुक्त है। लंबे समय में, आपको स्ट्रिंग प्रदान किए बिना सम्मिलन को संभालने के लिए कोड की आवश्यकता होती है।
इस कार्य को करने के लिए, माता-पिता या पूर्वज द्वारा उपयोग किया जाने वाला अंतिम नोड प्राप्त करें। हम इसे MAX() . फ़ंक्शन का उपयोग करके पूरा करते हैं और GetAncestor() . नीचे नमूना कोड देखें:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())उपरोक्त कोड से लिए गए बिंदु नीचे दिए गए हैं:
- सबसे पहले, आपको अंतिम नोड और तत्काल श्रेष्ठ के लिए एक चर की आवश्यकता है।
- अंतिम नोड को MAX() . का उपयोग करके प्राप्त किया जा सकता है रैंकनोड . के विरुद्ध निर्दिष्ट माता-पिता या तत्काल श्रेष्ठ के लिए। हमारे मामले में, यह 0x7AD6 के नोड मान के साथ सहायक F&B प्रबंधक है।
- अगला, यह सुनिश्चित करने के लिए कि कोई डुप्लिकेट बच्चा दिखाई न दे, @ImmediateSuperior.GetDescendant(@MaxNode, NULL) का उपयोग करें . @MaxNode . में मान आखिरी बच्चा है। अगर यह नल नहीं है , GetDescendant() अगला संभावित नोड मान लौटाता है।
- आखिरी, GetLevel() बनाए गए नए नोड का स्तर लौटाता है।
डेटा क्वेरी करना
हमारी तालिका में रिकॉर्ड जोड़ने के बाद, इसे क्वेरी करने का समय आ गया है। डेटा क्वेरी करने के 2 तरीके उपलब्ध हैं:
प्रत्यक्ष वंशजों के लिए प्रश्न
जब हम कर्मचारियों की तलाश करते हैं जो सीधे प्रबंधक को रिपोर्ट करते हैं, तो हमें दो बातें जानने की जरूरत है:
- प्रबंधक या अभिभावक का नोड मान
- प्रबंधक के अधीन कर्मचारी का स्तर
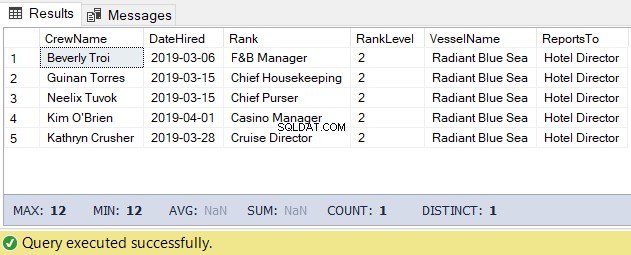
इस कार्य के लिए, हम नीचे दिए गए कोड का उपयोग कर सकते हैं। आउटपुट होटल निदेशक के तहत चालक दल की सूची है।
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel Directorउपरोक्त कोड का परिणाम चित्र 5 में इस प्रकार है:
उप-वृक्षों के लिए क्वेरी
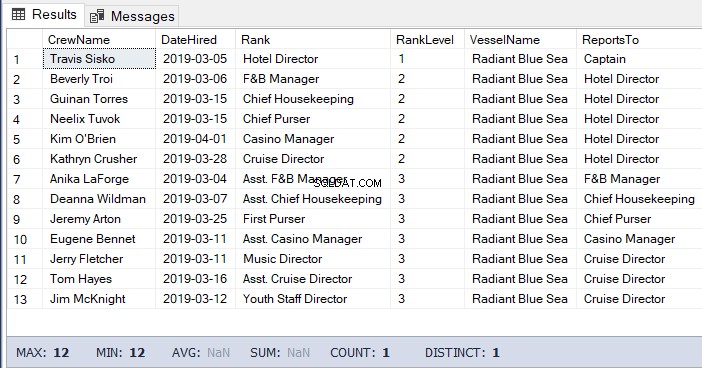
कभी-कभी, आपको बच्चों और बच्चों के बच्चों को नीचे से नीचे तक सूचीबद्ध करने की भी आवश्यकता होती है। ऐसा करने के लिए, आपके पास माता-पिता का पदानुक्रम आईडी होना चाहिए।
क्वेरी पिछले कोड के समान होगी लेकिन स्तर प्राप्त करने की आवश्यकता के बिना। कोड उदाहरण देखें:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1उपरोक्त कोड का परिणाम:
एसक्यूएल सर्वर पदानुक्रम आईडी के साथ नोड्स को स्थानांतरित करना
पदानुक्रमित डेटा के साथ एक और मानक ऑपरेशन एक बच्चे या पूरे उपट्री को दूसरे माता-पिता में ले जा रहा है। हालांकि, आगे बढ़ने से पहले, कृपया एक संभावित समस्या पर ध्यान दें:
संभावित समस्या
- सबसे पहले, मूविंग नोड्स में I/O शामिल होता है। यदि आप पदानुक्रम आईडी या सामान्य माता-पिता/बच्चे का उपयोग करते हैं तो आप कितनी बार नोड्स को स्थानांतरित करते हैं यह निर्णायक कारक हो सकता है।
- दूसरा, नोड को पैरेंट/चाइल्ड डिज़ाइन में ले जाना एक पंक्ति को अपडेट करता है। उसी समय, जब आप किसी नोड को पदानुक्रम आईडी के साथ स्थानांतरित करते हैं, तो यह एक या अधिक पंक्तियों को अद्यतन करता है। प्रभावित पंक्तियों की संख्या पदानुक्रम स्तर की गहराई पर निर्भर करती है। यह एक महत्वपूर्ण प्रदर्शन समस्या में बदल सकता है।
समाधान
आप इस समस्या को अपने डेटाबेस डिज़ाइन से संभाल सकते हैं।
आइए उस डिज़ाइन पर विचार करें जिसका हमने यहाँ उपयोग किया था।
कर्मीदल . पर पदानुक्रम को परिभाषित करने के बजाय तालिका, हमने इसे रैंक . में परिभाषित किया है टेबल। यह दृष्टिकोण कर्मचारी . से भिन्न है AdventureWorks . में तालिका नमूना डेटाबेस, और यह निम्नलिखित लाभ प्रदान करता है:
- चालक दल के सदस्य पोत के रैंकों की तुलना में अधिक बार चलते हैं। यह डिज़ाइन पदानुक्रम में नोड्स की गति को कम करेगा। नतीजतन, यह ऊपर परिभाषित समस्या को कम करता है।
- चालक दल . में एक से अधिक पदानुक्रम को परिभाषित करना तालिका अधिक जटिल है, क्योंकि दो जहाजों को दो कप्तानों की आवश्यकता होती है। परिणाम दो रूट नोड्स है।
- यदि आपको संबंधित क्रू सदस्य के साथ सभी रैंक प्रदर्शित करने की आवश्यकता है, तो आप बाएं जॉइन का उपयोग कर सकते हैं। अगर उस रैंक के लिए कोई भी बोर्ड पर नहीं है, तो यह स्थिति के लिए एक खाली स्लॉट दिखाता है।
अब, इस खंड के उद्देश्य की ओर बढ़ते हैं। गलत माता-पिता के तहत चाइल्ड नोड्स जोड़ें।
यह कल्पना करने के लिए कि हम क्या करने वाले हैं, नीचे दिए गए पदानुक्रम की कल्पना करें। पीले नोड्स पर ध्यान दें।

बिना बच्चों वाले नोड को स्थानांतरित करें
चाइल्ड नोड को स्थानांतरित करने के लिए निम्न की आवश्यकता होती है:
- चाइल्ड नोड को स्थानांतरित करने के लिए पदानुक्रम आईडी परिभाषित करें।
- पुराने माता-पिता के पदानुक्रम आईडी को परिभाषित करें।
- नए माता-पिता के पदानुक्रम आईडी को परिभाषित करें।
- अपडेट करें का उपयोग करें GetReparentedValue() . के साथ नोड को भौतिक रूप से स्थानांतरित करने के लिए।
बिना बच्चों वाले नोड को स्थानांतरित करके प्रारंभ करें। नीचे दिए गए उदाहरण में, हम क्रूज़ स्टाफ़ को क्रूज़ निदेशक के अधीन से सहायक के अधीन ले जाते हैं। क्रूज निदेशक।
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveएक बार नोड अपडेट हो जाने के बाद, नोड के लिए एक नया हेक्स मान उपयोग किया जाएगा। SQL सर्वर से मेरे Power BI कनेक्शन को ताज़ा करना - यह पदानुक्रम चार्ट को बदल देगा जैसा कि नीचे दिखाया गया है:
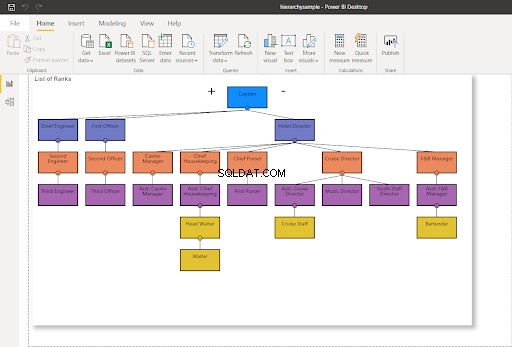
चित्र 8 में, क्रूज़ कर्मचारी अब क्रूज़ निदेशक को रिपोर्ट नहीं करते हैं - इसे सहायक क्रूज़ निदेशक को रिपोर्ट करने के लिए बदल दिया जाता है। इसकी तुलना ऊपर चित्र 7 से करें।
अब, अगले चरण पर चलते हैं और हेड वेटर को सहायक F&B प्रबंधक के पास ले जाते हैं।
बच्चों के साथ एक नोड ले जाएं
इस भाग में एक चुनौती है।
बात यह है कि पिछला कोड एक बच्चे के साथ नोड के साथ काम नहीं करेगा। हमें याद है कि एक नोड को स्थानांतरित करने के लिए एक या अधिक चिल्ड्रन नोड्स को अपडेट करने की आवश्यकता होती है।
इसके अलावा, यह वहाँ समाप्त नहीं होता है। यदि नए माता-पिता का कोई मौजूदा बच्चा है, तो हम डुप्लिकेट नोड मानों से टकरा सकते हैं।
इस उदाहरण में, हमें उस समस्या का सामना करना पड़ता है:सहायक। F&B प्रबंधक के पास बारटेंडर चाइल्ड नोड है।
तैयार? यह रहा कोड:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;उपरोक्त कोड उदाहरण में, पुनरावृत्ति शुरू होती है क्योंकि नोड को अंतिम स्तर पर बच्चे को नीचे स्थानांतरित करने की आवश्यकता होती है।
इसे चलाने के बाद, रैंक तालिका अद्यतन की जाएगी। और फिर से, यदि आप परिवर्तनों को दृष्टिगत रूप से देखना चाहते हैं, तो Power BI रिपोर्ट को ताज़ा करें। आप नीचे दिए गए परिवर्तनों के समान परिवर्तन देखेंगे:
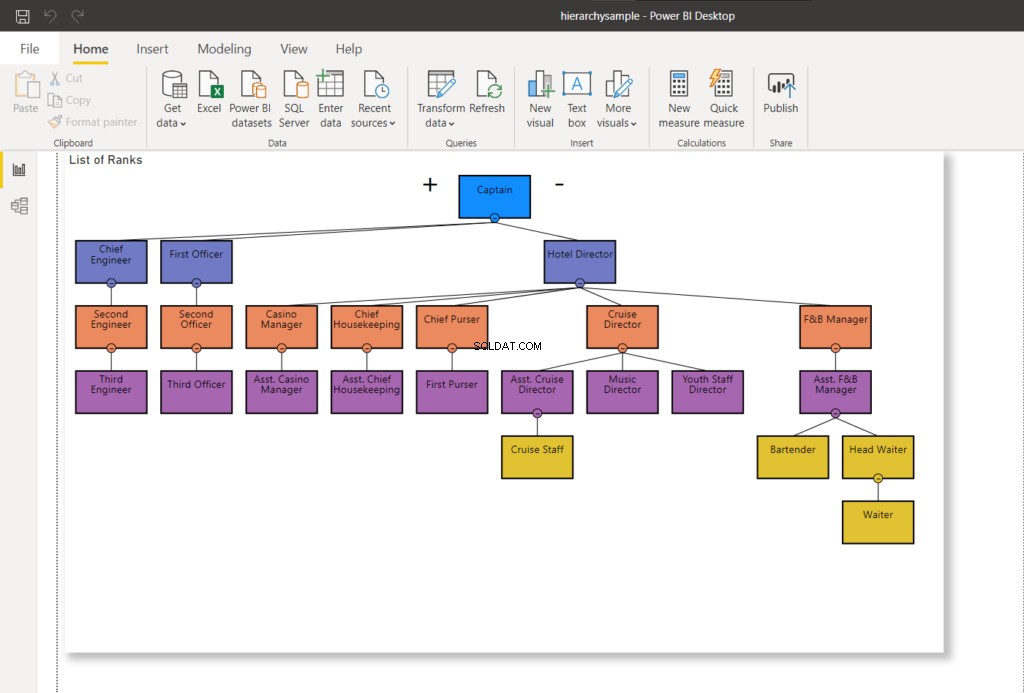
SQL सर्वर HierarchyID बनाम माता-पिता/बच्चे का उपयोग करने के लाभ
किसी को किसी सुविधा का उपयोग करने के लिए मनाने के लिए, हमें इसके लाभों को जानना होगा।
इस प्रकार, इस खंड में, हम शुरू से ही समान तालिकाओं का उपयोग करके कथनों की तुलना करेंगे। एक पदानुक्रम आईडी का उपयोग करेगा, और दूसरा माता-पिता/बाल दृष्टिकोण का उपयोग करेगा। परिणाम सेट दोनों दृष्टिकोणों के लिए समान होगा। हम इस अभ्यास के लिए इसकी अपेक्षा करते हैं क्योंकि यह चित्र 6 . से है ऊपर।
अब जबकि आवश्यकताएं सटीक हैं, आइए लाभों की अच्छी तरह से जांच करें।
कोड से सरल
नीचे दिया गया कोड देखें:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1इस नमूने को केवल एक पदानुक्रम आईडी मान की आवश्यकता है। आप क्वेरी को बदले बिना अपनी इच्छा से मान बदल सकते हैं।
अब, समान परिणाम सेट उत्पन्न करने वाले माता-पिता/बच्चे के दृष्टिकोण के लिए कथन की तुलना करें:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)तुम क्या सोचते हो? एक बिंदु को छोड़कर कोड के नमूने लगभग समान हैं।
कहां दूसरी क्वेरी में क्लॉज को अनुकूलित करने के लिए लचीला नहीं होगा यदि एक अलग उपट्री की आवश्यकता होती है।
दूसरी क्वेरी को सामान्य बनाएं, और कोड लंबा होगा। ओह!
तेज़ निष्पादन
माइक्रोसॉफ्ट के मुताबिक, माता-पिता/बच्चे की तुलना में "सबट्री क्वेश्चन पदानुक्रम आईडी के साथ काफी तेज हैं"। देखते हैं कि क्या यह सच है।
हम पहले की तरह ही प्रश्नों का उपयोग करते हैं। प्रदर्शन के लिए उपयोग की जाने वाली एक महत्वपूर्ण मीट्रिक है तार्किक पठन सेट सांख्यिकी IO . से . यह बताता है कि हमें इच्छित परिणाम सेट प्राप्त करने के लिए SQL सर्वर को कितने 8KB पृष्ठों की आवश्यकता होगी। मान जितना अधिक होगा, SQL सर्वर तक पहुँचने और पढ़ने वाले पृष्ठों की संख्या उतनी ही अधिक होगी, और क्वेरी जितनी धीमी होगी। सांख्यिकी IO को चालू करें . निष्पादित करें और उपरोक्त दो प्रश्नों को फिर से निष्पादित करें। तार्किक पठन का निम्न मान विजेता होगा।
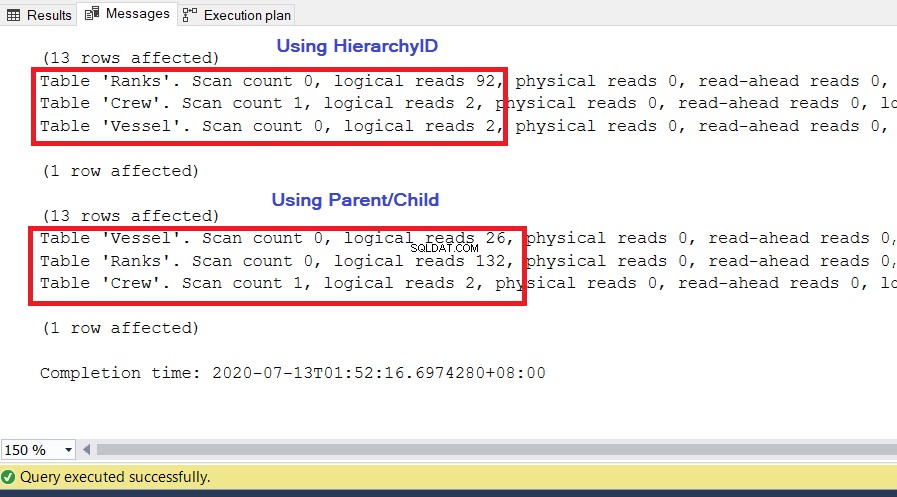
विश्लेषण
जैसा कि आप चित्र 10 में देख सकते हैं, पदानुक्रम आईडी के साथ क्वेरी के लिए I/O आँकड़ों में उनके माता-पिता/बाल समकक्षों की तुलना में कम तार्किक पठन होता है। इस परिणाम में निम्नलिखित बातों पर ध्यान दें:
- द पोत तालिका तीन तालिकाओं में सबसे उल्लेखनीय है। पदानुक्रम आईडी का उपयोग करने के लिए केवल 2 * 8KB =16KB पृष्ठों को SQL सर्वर द्वारा कैशे (मेमोरी) से पढ़ने की आवश्यकता होती है। इस बीच, माता-पिता/बच्चे का उपयोग करने के लिए 26 * 8KB =208KB पृष्ठों की आवश्यकता होती है - पदानुक्रम आईडी का उपयोग करने से काफी अधिक।
- द रैंक तालिका, जिसमें पदानुक्रम की हमारी परिभाषा शामिल है, के लिए 92 * 8KB =736KB की आवश्यकता होती है। दूसरी ओर, माता-पिता/बच्चे का उपयोग करने के लिए 132 * 8KB =1056KB की आवश्यकता होती है।
- द क्रू तालिका को 2 * 8KB =16KB की आवश्यकता है, जो दोनों दृष्टिकोणों के लिए समान है।
पृष्ठों के किलोबाइट अभी के लिए एक छोटा मूल्य हो सकता है, लेकिन हमारे पास केवल कुछ रिकॉर्ड हैं। हालांकि, यह हमें इस बात का अंदाजा देता है कि किसी भी सर्वर पर हमारी क्वेरी पर कितना टैक्स लगेगा। प्रदर्शन में सुधार के लिए, आप निम्न में से एक या अधिक कार्य कर सकते हैं:
- उपयुक्त अनुक्रमणिका जोड़ें
- क्वेरी का पुनर्गठन करें
- आंकड़े अपडेट करें
यदि आपने उपरोक्त किया है, और अधिक रिकॉर्ड जोड़े बिना तार्किक पठन कम हो गया है, तो प्रदर्शन में वृद्धि होगी। जब तक आप पदानुक्रम आईडी का उपयोग करने वाले की तुलना में तार्किक पठन को कम करते हैं, यह अच्छी खबर होगी।
लेकिन बीता हुआ समय के बजाय तार्किक पठन का संदर्भ क्यों लें?
सांख्यिकी समय चालू करें . का उपयोग करके दोनों प्रश्नों के लिए बीता हुआ समय की जाँच करना हमारे डेटा के छोटे सेट के लिए मिलीसेकंड के अंतर की एक छोटी संख्या को प्रकट करता है। साथ ही, आपके विकास सर्वर में भिन्न हार्डवेयर कॉन्फ़िगरेशन, SQL सर्वर सेटिंग्स और कार्यभार हो सकता है। यदि आपकी क्वेरी आपकी अपेक्षा के अनुरूप तेज़ प्रदर्शन कर रही है या नहीं, तो मिलीसेकंड से कम का बीता हुआ समय आपको धोखा दे सकता है।
आगे खोदना
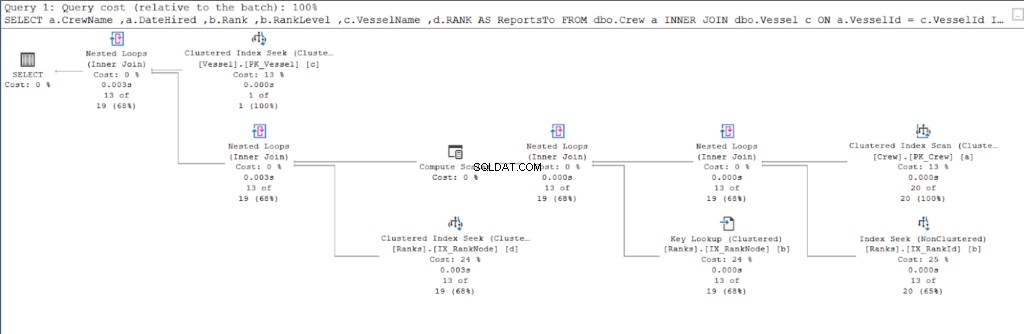
सांख्यिकी IO चालू करें "पर्दे के पीछे" होने वाली चीज़ों को प्रकट नहीं करता है। इस खंड में, हम निष्पादन योजना को देखकर पता लगाते हैं कि SQL सर्वर उन नंबरों के साथ क्यों आता है।
आइए पहली क्वेरी की निष्पादन योजना से शुरू करें।
अब, दूसरी क्वेरी की निष्पादन योजना देखें।
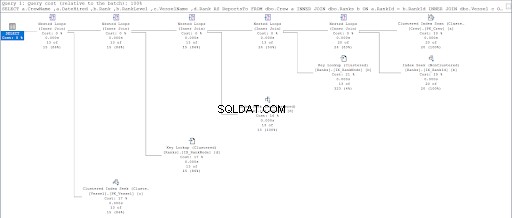
चित्र 11 और 12 की तुलना करते हुए, हम देखते हैं कि यदि आप पैरेंट/चाइल्ड दृष्टिकोण का उपयोग करते हैं तो SQL सर्वर को परिणाम सेट तैयार करने के लिए अतिरिक्त प्रयास की आवश्यकता होती है। कहां इस जटिलता के लिए खंड जिम्मेदार है।
हालाँकि, दोष टेबल डिज़ाइन का भी हो सकता है। हमने दोनों दृष्टिकोणों के लिए एक ही तालिका का उपयोग किया:रैंक टेबल। इसलिए, मैंने रैंक . की नकल करने की कोशिश की तालिका लेकिन प्रत्येक प्रक्रिया के लिए उपयुक्त विभिन्न संकुल अनुक्रमणिका का उपयोग करें।
नतीजतन, माता-पिता/बाल समकक्ष की तुलना में पदानुक्रम आईडी का उपयोग अभी भी कम तार्किक पढ़ता है। अंत में, हमने साबित कर दिया कि Microsoft इस पर सही दावा कर रहा था।
निष्कर्ष
यहाँ पदानुक्रम के लिए केंद्रीय अहा क्षण हैं:
- पदानुक्रम आईडी एक अंतर्निहित डेटा प्रकार है जिसे पेड़ों के अधिक अनुकूलित प्रतिनिधित्व के लिए डिज़ाइन किया गया है, जो कि पदानुक्रमित डेटा का सबसे सामान्य प्रकार है।
- पेड़ में प्रत्येक आइटम एक नोड है, और पदानुक्रम आईडी मान हेक्साडेसिमल या स्ट्रिंग प्रारूप में हो सकते हैं।
- पदानुक्रम आईडी संगठनात्मक संरचनाओं, परियोजना कार्यों, भौगोलिक डेटा, और इसी तरह के डेटा के लिए लागू है।
- श्रेणीबद्ध डेटा को ट्रैवर्स करने और उसमें हेर-फेर करने के तरीके हैं, जैसे GetAncestor (), GetDescendant ()। गेटलेवल (), GetReparentedValue (), और बहुत कुछ।
- श्रेणीबद्ध डेटा को क्वेरी करने का पारंपरिक तरीका एक नोड के प्रत्यक्ष वंशज प्राप्त करना या एक नोड के तहत उप-वृक्ष प्राप्त करना है।
- उप-वृक्षों को क्वेरी करने के लिए पदानुक्रम आईडी का उपयोग न केवल कोड के लिए आसान है। यह माता-पिता/बच्चे से भी बेहतर प्रदर्शन करता है।
माता-पिता/बच्चे का डिज़ाइन बिल्कुल भी बुरा नहीं है, और यह पोस्ट इसे कम करने के लिए नहीं है। हालांकि, विकल्पों का विस्तार करना और नए विचारों को पेश करना हमेशा एक डेवलपर के लिए एक बड़ा लाभ होता है।
आप हमारे द्वारा यहां पेश किए गए उदाहरणों को स्वयं आजमा सकते हैं। प्रभाव प्राप्त करें और देखें कि आप इसे अपने अगले प्रोजेक्ट के लिए कैसे लागू कर सकते हैं जिसमें पदानुक्रम शामिल हैं।
यदि आप पोस्ट और उसके विचारों को पसंद करते हैं, तो आप पसंदीदा सोशल मीडिया के लिए शेयरिंग बटन पर क्लिक करके इस शब्द का प्रसार कर सकते हैं।