पिछले साल, एंडी मॉलन ने int . से एक कॉलम को अपसाइज़ करने के बारे में ब्लॉग किया था करने के लिए bigint बिना डाउनटाइम के। (यह SQL सर्वर के आधुनिक संस्करणों में केवल मेटाडेटा-ऑपरेशन क्यों नहीं है, यह मेरे से परे है, लेकिन यह एक और पोस्ट है।)
आम तौर पर जब हम इस मुद्दे से निपटते हैं, तो वे विस्तृत और विशाल टेबल होते हैं (पंक्ति गणना और सरासर आकार दोनों में), और जिस कॉलम को हमें बदलने की आवश्यकता होती है वह क्लस्टरिंग कुंजी में एकमात्र/अग्रणी कॉलम होता है। आम तौर पर इसमें अन्य जटिलताएं भी शामिल होती हैं - इनबाउंड विदेशी कुंजी बाधाएं, बहुत सारे गैर-क्लस्टर इंडेक्स, और एक व्यस्त डेटाबेस जो लॉग गतिविधि के लिए अति संवेदनशील है (क्योंकि यह चेंज ट्रैकिंग, प्रतिकृति, उपलब्धता समूह, या तीनों में शामिल है। )
इस कारण से, हमें एंडी आउटलाइन जैसा दृष्टिकोण अपनाने की आवश्यकता है, जहां हम नई स्कीमा के साथ एक शैडो टेबल बनाते हैं, दोनों प्रतियों को सिंक में रखने के लिए ट्रिगर बनाते हैं, और फिर उस टीम की अपनी गति से बैच/बैकफिल तब तक करते हैं जब तक कि वे स्वैप करने के लिए तैयार न हों। कॉपी में असली डील के रूप में।
लेकिन मैं आलसी हूँ!
ऐसे कुछ मामले हैं जहां आप कॉलम को सीधे बदल सकते हैं, यदि आप डाउनटाइम/ब्लॉकिंग की एक छोटी सी खिड़की का खर्च उठा सकते हैं, और यह एक बहुत आसान ऑपरेशन बन जाता है। पिछले हफ्ते ऐसा एक मामला सामने आया, जिसमें 1TB से अधिक की तालिका थी, लेकिन केवल 100K पंक्तियाँ थीं। लगभग सभी डेटा ऑफ-रो (LOB) था, यदि आवश्यक हो तो वे डाउनटाइम की एक छोटी सी खिड़की का खर्च उठा सकते थे, और वे चेंज ट्रैकिंग को अक्षम करने और इसे फिर से कॉन्फ़िगर करने की योजना बना रहे थे। विश्वास है कि क्लस्टर किए गए पीके को फिर से बनाने के लिए एलओबी डेटा (ज्यादा) को छूना नहीं पड़ेगा, मैंने सुझाव दिया कि यह एक ऐसा मामला हो सकता है जहां हम सीधे बदलाव को लागू कर सकते हैं।
एक अलग परिदृश्य में (कोई इनबाउंड विदेशी कुंजी नहीं, कोई अतिरिक्त अनुक्रमणिका नहीं, लॉग रीडर के आधार पर कोई गतिविधि नहीं, और समवर्ती के बारे में कोई चिंता नहीं), मैंने कुछ परीक्षणों को एक शून्य में देखने के लिए फेंक दिया, इस परिवर्तन की अवधि के संदर्भ में क्या आवश्यकता होगी और लेन-देन लॉग पर प्रभाव। मुख्य प्रश्न जो मुझे नहीं पता था कि अग्रिम में कैसे उत्तर दिया जाए, "जब बड़ी मात्रा में गैर-कुंजी डेटा होते हैं तो टेबल को अपडेट करने की वृद्धिशील लागत क्या होती है?"
मैं यहां एक पोस्ट में बहुत कुछ पैक करने की कोशिश करने जा रहा हूं। मैंने बहुत सारे परीक्षण किए, और यह सभी प्रकार से संबंधित है, भले ही सभी परीक्षण परिदृश्य आप पर लागू न हों। कृपया मेरे साथ रहें।
टेबल
मैंने एक आधार रेखा सहित 6 तालिकाएँ बनाईं, जो केवल केवल . हैं कुंजी कॉलम था, एक तालिका जिसमें 4K इन-पंक्ति संग्रहीत थी, और फिर चार टेबल प्रत्येक में एक वर्चर (अधिकतम) कॉलम के साथ अलग-अलग मात्रा में स्ट्रिंग डेटा (4K, 16K, 64K, और 256K) के साथ पॉप्युलेट किया गया था।
CREATE TABLE dbo.withJustId
(
id int NOT NULL,
CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withoutLob
(
id int NOT NULL,
extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob004
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob016
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)),
CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob064
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)),
CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob256
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)),
CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id)
); मैंने प्रत्येक को 100,000 पंक्तियों से भर दिया:
INSERT dbo.withJustId (id) SELECT TOP (100000) id = ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
मैं स्वीकार करता हूं कि उपरोक्त अवास्तविक है; कितनी बार हमारे पास एक टेबल है जो सिर्फ एक पहचानकर्ता + एलओबी डेटा है? मैंने गैर-एलओबी डेटा पृष्ठों को थोड़ा और वास्तविक-विश्व पदार्थ देने के लिए इन अतिरिक्त चार स्तंभों के साथ परीक्षण फिर से चलाया:
fill1 char(320) NOT NULL DEFAULT ('x'),
count1 int NOT NULL DEFAULT (0),
count2 int NOT NULL DEFAULT (0),
dt datetime2 NOT NULL DEFAULT sysutcdatetime(), ये तालिकाएँ समग्र आकार के संदर्भ में केवल थोड़ी बड़ी हैं, लेकिन गैर-LOB डेटा की मात्रा में आनुपातिक वृद्धि (इस चार्ट में चित्रित नहीं) बड़ा लेकिन छिपा हुआ अंतर है:
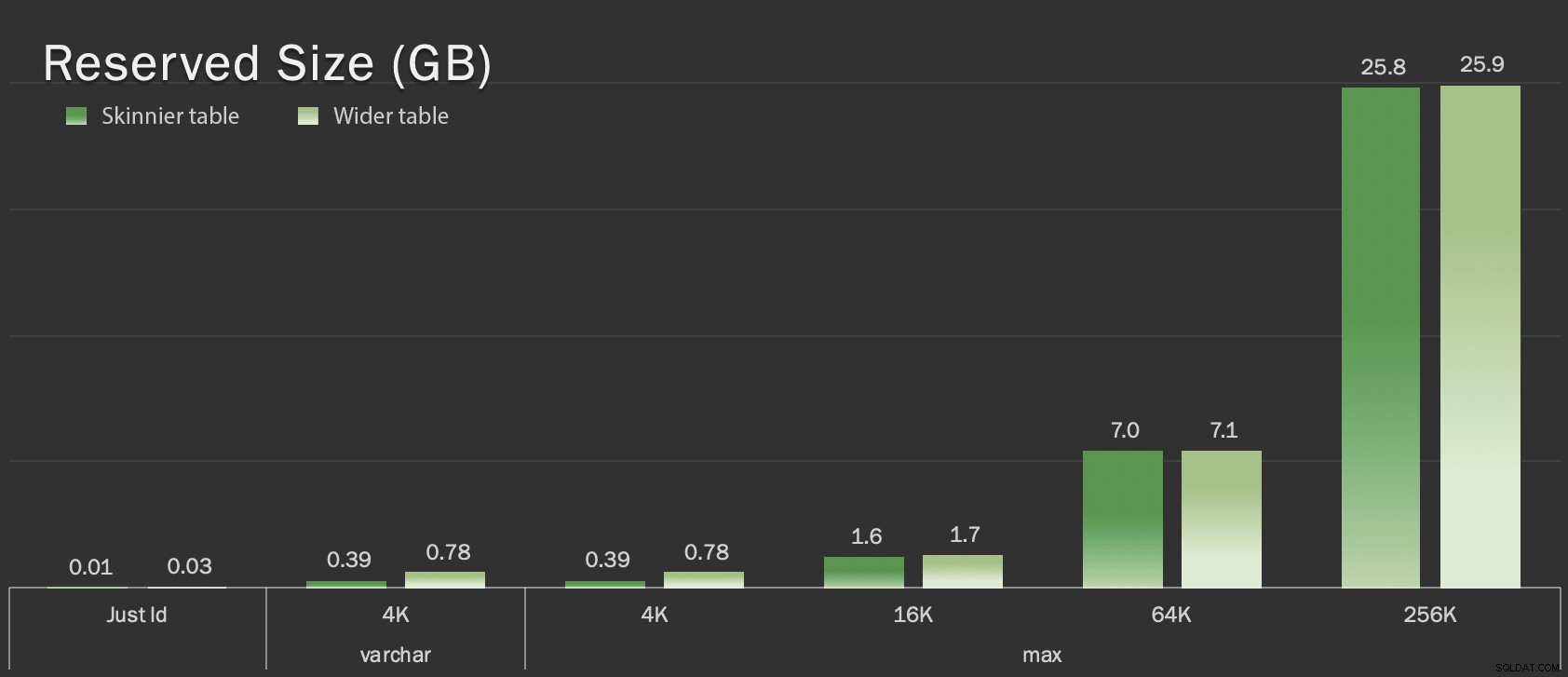 जीबी में टेबल का आरक्षित आकार
जीबी में टेबल का आरक्षित आकार
परीक्षा
फिर मैंने इनमें से प्रत्येक ऑपरेशन के लिए समयबद्ध और लॉग डेटा एकत्र किया (ONLINE = ON के साथ और बिना) ) तालिका के प्रत्येक रूपांतर के सामने:
ALTER TABLE dbo.<name> DROP CONSTRAINT pk_<name>; ALTER TABLE dbo.<name> ALTER COLUMN id bigint NOT NULL; -- WITH (ONLINE = ON); ALTER TABLE dbo.<name> ADD CONSTRAINT pk_<name> PRIMARY KEY CLUSTERED (id);
वास्तव में, मैंने इन सभी परीक्षणों को उत्पन्न करने के लिए गतिशील SQL का उपयोग किया, ताकि मैं प्रत्येक परीक्षण से पहले स्क्रिप्ट के साथ मैन्युअल रूप से फ़िदा न हो।
एक अन्य पोस्ट में, मैं उन परीक्षणों को उत्पन्न करने के लिए उपयोग किए जाने वाले गतिशील SQL को साझा करूंगा, और प्रत्येक चरण में समय एकत्र करूंगा।
तुलना के लिए, मैंने एंडी की विधि का भी परीक्षण किया (यद्यपि बिना बैचिंग के, और केवल तालिका के पतले संस्करण पर):
CREATE TABLE dbo.<name>_copy ( id bigint NOT NULL -- <, extradata column when relevant > CONSTRAINT pk_copy_<name> PRIMARY KEY CLUSTERED (id)); INSERT dbo.<name>_copy SELECT * FROM dbo.<name>; EXEC sys.sp_rename N'dbo.<name>', N'dbo.<name>_old', N'OBJECT'; EXEC sys.sp_rename N'dbo.<name>_copy', N'dbo.<name>', N'OBJECT';
मैंने यहां व्यापक तालिकाओं को छोड़ दिया; मैं बैच संचालन को कोडिंग और मापने की जटिलता का परिचय नहीं देना चाहता था। यहां स्पष्ट दर्द बिंदु यह है कि, कॉलम को जगह में बदलने के विपरीत, छाया विधि के साथ आपको उस एलओबी डेटा के प्रत्येक बाइट को कॉपी करना होगा। बैचिंग एकल लेनदेन में ऐसा करने की कोशिश के बड़े प्रभाव को कम कर सकता है, लेकिन उस सभी फेरबदल को अंततः डाउनस्ट्रीम में फिर से करना होगा। स्रोत पर बैचिंग पूरी तरह से नियंत्रित नहीं कर सकती है कि गंतव्य पर कितना नुकसान होगा।
परिणाम
पहले परिणाम जो मैं दिखाने जा रहा हूं, वे सभी 12 टेबल कॉन्फ़िगरेशन के लिए, इन-प्लेस परिवर्तनों के लिए औसत अवधि हैं, और ONLINE = ON के साथ और बिना :
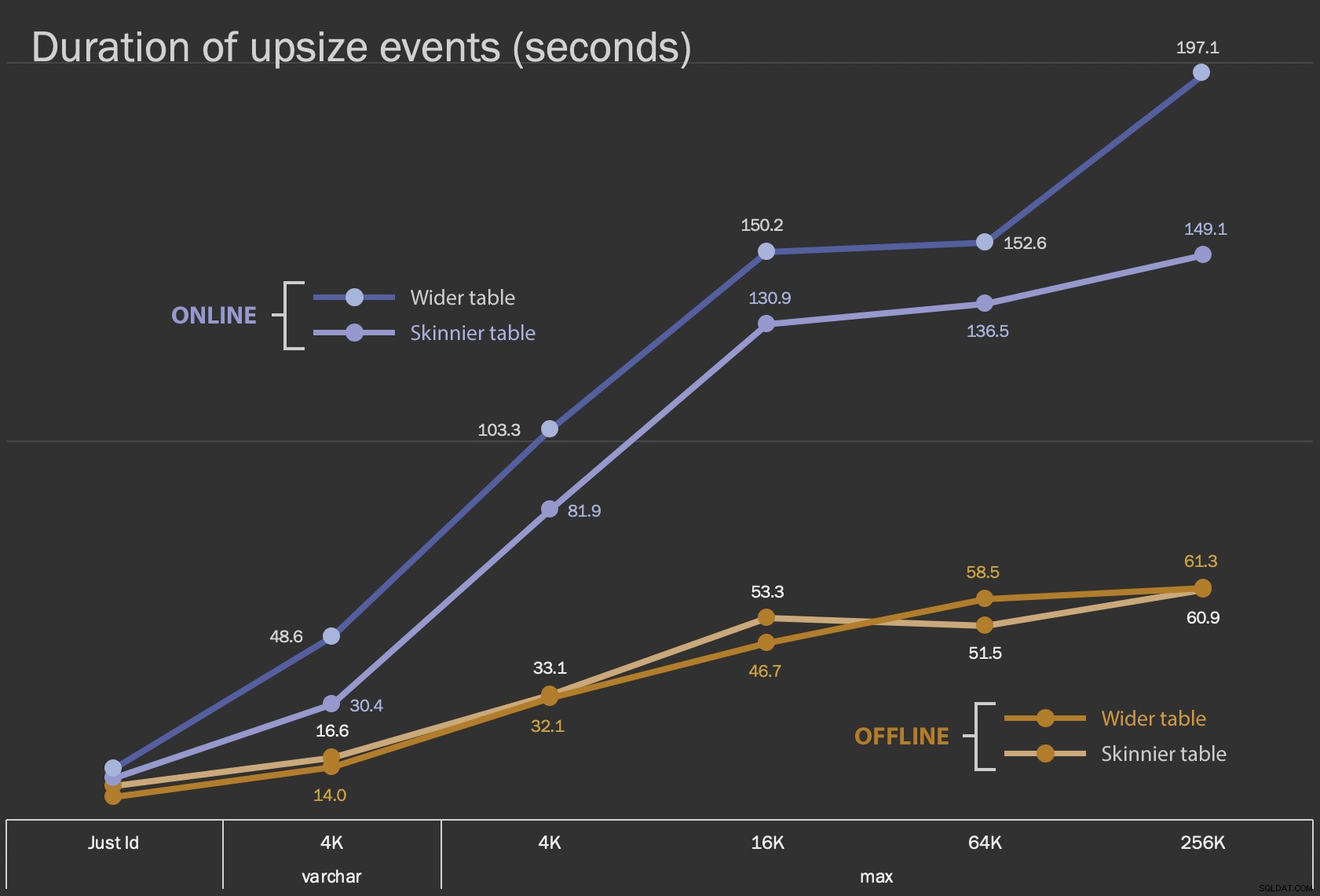 कॉलम को यथास्थान बदलने की अवधि, सेकंडों में
कॉलम को यथास्थान बदलने की अवधि, सेकंडों में
इसे ऑनलाइन ऑपरेशन के रूप में करने में अधिक समय लगता है (सबसे खराब स्थिति में 200 सेकंड), लेकिन यह उपयोगकर्ताओं को ब्लॉक नहीं करता है। यह आकार के साथ बढ़ता हुआ प्रतीत होता है, लेकिन काफी रैखिक रूप से नहीं। इस कार्रवाई को ऑफ़लाइन करने से अवरोधन होता है, लेकिन यह बहुत तेज़ होता है, और तालिका के बड़े होने के साथ-साथ बहुत अधिक नहीं बदलता है (यहां तक कि सबसे बड़े आकार में भी, यह लगभग एक मिनट में होता है)।
इन-प्लेस ऑपरेशंस की तुलना स्वैप और ड्रॉप ऑपरेशन से करना एक लाइन चार्ट का उपयोग करना मुश्किल है क्योंकि स्केल में भारी अंतर है। इसके बजाय मैं प्रत्येक तालिका कॉन्फ़िगरेशन से जुड़ी अवधि के लिए एक क्षैतिज बार चार्ट दिखाने जा रहा हूं। जब री-क्रिएट तेज होगा, तो मैं उस पंक्ति की पृष्ठभूमि को हरे रंग में रंग दूंगा; जब यह धीमा होता है (या ऑफ़लाइन और ऑनलाइन विधियों के बीच आता है), तो शायद मुझे इसकी आवश्यकता नहीं है, लेकिन मैं उस पंक्ति की पृष्ठभूमि को लाल रंग में रंग दूंगा।
| अवधि (सेकंड) | |||
|---|---|---|---|
| बस Id | ऑफ़लाइन बदलें | स्किनियर टेबल (10 MB) | 8.8 |
| व्यापक तालिका (30 एमबी) | 6.3 | ||
| ऑनलाइन बदलें | स्किनियर टेबल | 11.0 | |
| व्यापक तालिका | 13.6 | ||
| रीक्रिएट | स्किनियर टेबल | 3.4 | |
| varchar 4K | ऑफ़लाइन | स्किनियर टेबल (390 एमबी) | 16.6 |
| व्यापक तालिका (780 एमबी) | 14.0 | ||
| ऑनलाइन | स्किनियर टेबल | 30.4 | |
| व्यापक तालिका | 48.6 | ||
| रीक्रिएट | स्किनियर टेबल | 1,290.0 | |
| अधिकतम 4k | ऑफ़लाइन | स्किनियर टेबल (390 एमबी) | 33.1 |
| व्यापक तालिका (780 एमबी) | 32.1 | ||
| ऑनलाइन | स्किनियर टेबल | 81.9 | |
| व्यापक तालिका | 103.3 | ||
| रीक्रिएट | स्किनियर टेबल | 28.9 | |
| अधिकतम 16k | ऑफ़लाइन | स्किनियर टेबल (1.6 जीबी) | 53.3 |
| व्यापक तालिका (1.7 GB) | 46.7 | ||
| ऑनलाइन | स्किनियर टेबल | 130.9 | |
| व्यापक तालिका | 150.2 | ||
| रीक्रिएट | स्किनियर टेबल | 81.8 | |
| अधिकतम 64k | ऑफ़लाइन | स्किनियर टेबल (7.0 GB) | 51.5 |
| व्यापक तालिका (7.1 GB) | 58.5 | ||
| ऑनलाइन | स्किनियर टेबल | 136.5 | |
| व्यापक तालिका | 152.6 | ||
| रीक्रिएट | स्किनियर टेबल | 226.5 | |
| अधिकतम 256k | ऑफ़लाइन | स्किनियर टेबल (25.8 जीबी) | 60.9 |
| व्यापक तालिका (25.9 GB) | 61.3 | ||
| ऑनलाइन | स्किनियर टेबल | 149.1 | |
| व्यापक तालिका | 197.1 | ||
| रीक्रिएट | स्किनियर टेबल | 1,576.7 | |
यह एंडी की पद्धति पर एक अनुचित झटका है, क्योंकि - वास्तविक दुनिया में - आप एक शॉट में वह पूरा ऑपरेशन नहीं कर रहे होंगे। मैंने यहां संक्षिप्तता के लिए लेन-देन लॉग का उपयोग नहीं दिखाया, लेकिन साथ-साथ संचालन में बैचिंग के माध्यम से इसे नियंत्रित करना आसान होगा। जबकि उनके दृष्टिकोण के लिए और अधिक काम करने की आवश्यकता है, यह डाउनटाइम और/या अवरोधन के मामले में बहुत सुरक्षित है। लेकिन आप उन मामलों में देख सकते हैं जहां आपके पास बहुत सारे ऑफ-रो डेटा हैं और एक संक्षिप्त आउटेज बर्दाश्त कर सकते हैं, कि कॉलम को सीधे बदलना बहुत कम दर्दनाक है। "जगह में बदलने के लिए बहुत बड़ा" व्यक्तिपरक है और "बड़े" के अर्थ के आधार पर अलग-अलग परिणाम उत्पन्न कर सकता है। किसी दृष्टिकोण के लिए प्रतिबद्ध होने से पहले, उचित प्रतिलिपि के विरुद्ध परिवर्तन का परीक्षण करना समझ में आता है, क्योंकि इन-प्लेस ऑपरेशन एक स्वीकार्य व्यापार-बंद का प्रतिनिधित्व कर सकता है।
निष्कर्ष
मैंने इसे एंडी के साथ बहस करने के लिए नहीं लिखा था। मूल पोस्ट में दृष्टिकोण ध्वनि, 100% विश्वसनीय है, और हम इसे हर समय उपयोग करते हैं। जब पाशविक बल को सर्जिकल परिशुद्धता पर महत्व दिया जाता है, हालांकि, और विशेष रूप से यदि आप डाउनटाइम का एक टुकड़ा ले सकते हैं, तो कुछ टेबल आकृतियों के लिए सरल दृष्टिकोण में मूल्य हो सकता है।