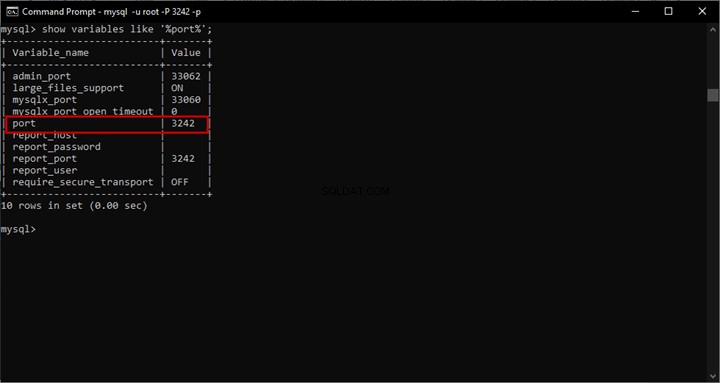
यह SQL सर्वर अर्थपूर्ण खोज को समर्पित सामग्री का दूसरा भाग है . पिछले लेख में, हमने मूल बातें खोजी थीं। अब, हम Windows फ़ाइल सिस्टम पर संग्रहीत दस्तावेज़ों की तुलना करने और SQL सर्वर में अर्थपूर्ण खोज के साथ तुलनात्मक विश्लेषण पर ध्यान केंद्रित करने जा रहे हैं।
नाम-आधारित दस्तावेज़ों का तुलनात्मक विश्लेषण करना
हम उनके मानक नामकरण के आधार पर दस्तावेजों का तुलनात्मक विश्लेषण करने जा रहे हैं। इस बिंदु पर, आइए कर्मचारियोंफाइलस्ट्रीम नमूना को क्वेरी करके एक त्वरित जांच करें। डेटाबेस जिसे हमने पहले सेट किया था:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
परिणाम हमें संग्रहीत दस्तावेज़ दिखाने चाहिए:
सिमेंटिक सर्च चेकलिस्ट
हमारे पास पहले से ही फ़ाइल तालिका का उपयोग करते हुए फ़ाइल सिस्टम पर डेटाबेस और दो नमूना एमएस वर्ड दस्तावेज़ हैं (यदि आवश्यक हो तो ज्ञान को ताज़ा करने के लिए आप भाग 1 का संदर्भ ले सकते हैं)। हालांकि, वह नहीं सिमेंटिक सर्च परिदृश्य के लिए हमारे दस्तावेज़ों को स्वचालित रूप से योग्य बनाते हैं।
सिमेंटिक सर्च को निम्नलिखित में से किसी एक तरीके से सक्षम किया जा सकता है:
- यदि आप पहले से ही पूर्ण-पाठ खोज सेट कर चुके हैं , आप सिमेंटिक खोज को एक ही चरण में सक्षम कर सकते हैं।
- आप सिमेंटिक सर्च को सीधे सेट कर सकते हैं, लेकिन इससे पहले आपको फुल-टेक्स्ट सर्च भी सेट करना होगा।
अर्थपूर्ण खोज सेटअप से पहले पूर्ण-पाठ खोज परीक्षण
यदि कोई पूर्ण-पाठ क्वेरी काम करती है, तो हमें केवल सिमेंटिक खोज को सक्षम करने की आवश्यकता है। इसे जांचने के लिए, वांछित तालिका के विरुद्ध एक पूर्ण-पाठ क्वेरी चलाएँ:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
आउटपुट:
इस प्रकार, हमें पहले पूर्ण-पाठ खोज आवश्यकताओं को पूरा करना होगा और फिर सिमेंटिक खोज को सक्षम करना होगा।
उपयोग के लिए अर्थपूर्ण खोज सक्षम करना
सिमेंटिक सर्च का उपयोग करने के लिए निम्न में से कम से कम दो बिंदु आवश्यक हैं:
- अद्वितीय अनुक्रमणिका
- एक पूर्ण-पाठ कैटलॉग
- एक पूर्ण-पाठ अनुक्रमणिका
अद्वितीय अनुक्रमणिका बनाने के लिए निम्न T-SQL स्क्रिप्ट निष्पादित करें:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
नव-निर्मित अद्वितीय अनुक्रमणिका के आधार पर एक पूर्ण-पाठ कैटलॉग बनाएँ। और फिर, एक पूर्ण-पाठ अनुक्रमणिका बनाएं जैसा कि नीचे दिखाया गया है:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
परिणाम:
अर्थपूर्ण खोज सेटअप के बाद पूर्ण-पाठ खोज परीक्षण
आइए कर्मचारी . शब्द खोजने के लिए वही पूर्ण-पाठ क्वेरी चलाएँ संग्रहीत दस्तावेज़ों में:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
आउटपुट:
जब हम इसे सिमेंटिक सर्च के लिए तैयार कर रहे हैं, तो फ़ाइल तालिका के विरुद्ध काम करने के लिए पूर्ण-पाठ प्रश्नों के लिए ठीक है।
अधिक MS Word दस्तावेज़ जोड़ें
हम कर्मचारी दस्तावेज़ स्टोर . पर जाते हैं फ़ाइल तालिका और क्लिक करें फ़ाइल तालिका निर्देशिका एक्सप्लोर करें :
सदफ अनुबंध कर्मचारी . नामक एक नया दस्तावेज़ बनाएं और संग्रहीत करें :
इसके बाद, नव-निर्मित दस्तावेज़ में निम्न पाठ जोड़ें। पहली पंक्ति दस्तावेज़ का शीर्षक होना चाहिए!
सदफ अनुबंध कर्मचारी (शीर्षक)
सदफ एक बहुत ही कुशल व्यापार विश्लेषक है जो संपर्क-आधारित कार्य करता है। वह व्यावसायिक आवश्यकताओं को संभालने और उन्हें डेवलपर्स के लिए काम करने के लिए तकनीकी विशिष्टताओं में बदलने में पूरी तरह से सक्षम है। वह एक बहुत ही अनुभवी व्यापार विश्लेषक हैं।
माइक स्थायी कर्मचारी called नामक एक अन्य दस्तावेज़ जोड़ें :
दस्तावेज़ को निम्न टेक्स्ट के साथ अपडेट करें:
माइक स्थायी कर्मचारी (दस्तावेज़ का शीर्षक)
माइक एक नया प्रोग्रामर है जिसकी विशेषज्ञता में वेब विकास शामिल है। वह एक त्वरित शिक्षार्थी है और किसी भी परियोजना पर काम करने के लिए खुश है। उसके पास समस्या को सुलझाने का मजबूत कौशल है लेकिन उसके पास व्यावसायिक ज्ञान कम है। समस्या को समझने और आवश्यकताओं को पूरा करने के लिए उसे अन्य डेवलपर्स या व्यापार विश्लेषकों से सहायता की आवश्यकता होती है।
जब वह छोटे प्रोजेक्ट पर काम करता है तो वह अच्छा होता है लेकिन अगर उसे कोई बड़ा या जटिल प्रोजेक्ट दिया जाता है तो वह संघर्ष करता है।
हमारे पास फाइल टेबल द्वारा प्रबंधित विंडोज फाइल सिस्टम पर चार दस्तावेज संग्रहीत हैं। इन दस्तावेज़ों का उपयोग सिमेंटिक सर्च (पूर्ण-पाठ खोज सहित) द्वारा किया जाना चाहिए।
महत्वपूर्ण:यद्यपि हमने अभी-अभी चार MS Word दस्तावेज़ों को एक नमूने के रूप में फ़ोल्डर में संग्रहीत किया है, आप सिमेंटिक खोज का उपयोग करने के महत्व की कल्पना कर सकते हैं जब ऐसे सैकड़ों दस्तावेज़ SQL सर्वर डेटाबेस द्वारा बनाए रखा जाता है, और आपको उन दस्तावेज़ों को क्वेरी करने की आवश्यकता होती है बहुमूल्य जानकारी प्राप्त करने के लिए।
दस्तावेजों का मानक नामकरण इस दृष्टिकोण के सफल कार्यान्वयन के लिए बहुत मायने रखता है।
दस्तावेजों की सरल गणना
हम इन दस्तावेज़ों की तुलना कर सकते हैं और सिमेंटिक सर्च का उपयोग करके उनके मानक नामकरण के आधार पर अंतर और समानता को परिभाषित कर सकते हैं। उदाहरण के लिए, एक साधारण क्वेरी हमें विंडोज फोल्डर में संग्रहीत दस्तावेजों की कुल संख्या बता सकती है:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

स्थायी बनाम अनुबंध-आधारित कर्मचारी तुलना
इस बार, हम अपने संगठन में स्थायी और अनुबंध-आधारित कर्मचारियों की संख्या की तुलना करने के लिए सिमेंटिक सर्च का उपयोग कर रहे हैं:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
आउटपुट:
आइए कीफ़्रेज़ देखने के लिए एक सरल (दस्तावेज़ नाम-आधारित) अर्थपूर्ण खोज क्वेरी चलाते हैं और इसका सापेक्ष स्कोर प्रत्येक दस्तावेज़ के लिए:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
आउटपुट:
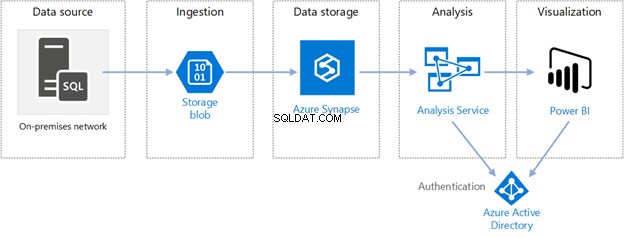
आइए दस्तावेज़ के नामों में अधिक विवरण जोड़ें। हम उनका नाम इस प्रकार रखेंगे:
- आसिफ स्थायी कर्मचारी - अनुभवी परियोजना प्रबंधक
- माइक परमानेंट एम्प्लॉई - फ्रेश प्रोग्रामर
- पीटर स्थायी कर्मचारी - नया परियोजना प्रबंधक
- सदफ अनुबंध कर्मचारी - अनुभवी व्यापार विश्लेषक
नए कर्मचारी (दस्तावेज़) ढूँढना
नए कर्मचारियों से संबंधित दस्तावेजों को उनके शीर्षक (मानक नामकरण) के आधार पर खोजें:
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
परिणाम:
अनुभवी कर्मचारी (दस्तावेज़) ढूँढना
मान लीजिए कि हम आगे की जटिल परियोजना के लिए अनुभवी कर्मचारियों के सभी विवरणों की शीघ्रता से समीक्षा करना चाहते हैं। निम्नलिखित अर्थपूर्ण खोज क्वेरी का प्रयोग करें:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
आउटपुट:
सभी प्रोजेक्ट मैनेजर (दस्तावेज़) ढूँढना
अंत में, यदि हम सभी परियोजना प्रबंधकों के दस्तावेज़ों को शीघ्रता से देखना चाहते हैं, तो हमें निम्नलिखित अर्थपूर्ण खोज क्वेरी की आवश्यकता होगी:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
परिणाम:
पूर्वाभ्यास को लागू करने के बाद, आप फ़ाइल तालिका का उपयोग करके असंरचित डेटा, जैसे MS Word दस्तावेज़, को Windows फ़ोल्डर में सफलतापूर्वक संग्रहीत कर सकते हैं।
नाम-आधारित विश्लेषण समीक्षा
अब तक, हमने सीखा है कि सिमेंटिक सर्च का उपयोग करके फ़ाइल तालिका में संग्रहीत दस्तावेज़ों का नाम-आधारित विश्लेषण कैसे किया जाता है। हालांकि, हमें निम्नलिखित शर्तों को पूरा करने की आवश्यकता है:
- मानक नामकरण होना चाहिए।
- नामों को विश्लेषण के लिए आवश्यक जानकारी प्रदान करनी चाहिए।
ये शर्तें नाम-आधारित विश्लेषण की सीमाएँ भी हैं। लेकिन इसका मतलब यह नहीं है कि हम इसके साथ बहुत कुछ नहीं कर सकते।
हमारा ध्यान नाम/स्तंभ-आधारित सिमेंटिक खोज दृष्टिकोण पर बना हुआ है।
दस्तावेजों के नाम कॉलम देखें
आइए हम नाम . सहित दस्तावेज़ तालिका के कुछ मुख्य स्तंभों को देखें कॉलम:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
आउटपुट:
SEMANTICKEYPHRASETABLE फ़ंक्शन को समझना
SQL सर्वर SEMANTICKEYPHRASETABLE . प्रदान करता है सिमेंटिक सर्च के साथ दस्तावेज़ का विश्लेषण करने के लिए कार्य करता है। वाक्य रचना इस प्रकार है:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
यह फ़ंक्शन हमें दस्तावेज़ से जुड़े प्रमुख वाक्यांश देता है। हम उनका उपयोग उनके नाम या सामग्री के आधार पर दस्तावेजों का विश्लेषण करने के लिए कर सकते हैं। हमारे मामले में, हमें न केवल इस फ़ंक्शन का उपयोग करने की आवश्यकता है, बल्कि यह भी समझना होगा कि इसका सही उपयोग कैसे किया जाए।
फ़ंक्शन को निम्न डेटा की आवश्यकता है:
- अर्थपूर्ण खोज विश्लेषण के लिए उपयोग की जाने वाली फ़ाइल तालिका का नाम।
- सिमेंटिक सर्च विश्लेषण के लिए उपयोग किए जाने वाले कॉलम का नाम।
फिर यह निम्न डेटा लौटाता है:
- Column_id - कॉलम नंबर
- दस्तावेज़_कुंजी - फ़ाइल तालिका दस्तावेज़ के लिए डिफ़ॉल्ट प्राथमिक कुंजी
- कीफ़्रेज़ - एक वाक्यांश है जिसे सिमेंटिक सर्च विश्लेषण के लिए अनुक्रमित करने का निर्णय लेता है। यह दस्तावेज़ के नाम और सामग्री दोनों पर लागू होता है, जिसके आधार पर हम किस कॉलम के लिए प्रमुख वाक्यांश देखना चाहते हैं
- स्कोर - किसी दस्तावेज़ से जुड़े एक प्रमुख वाक्यांश की ताकत को निर्धारित करता है, जैसे कि किसी दस्तावेज़ को उसके मुख्य वाक्यांश द्वारा सर्वोत्तम रूप से कैसे पहचाना जाता है। स्कोर 0.0 से 1.0 के बीच हो सकता है।
SEMANTICKEYPHRASETABLE फ़ंक्शन का उपयोग करके सभी दस्तावेज़ों का विश्लेषण करना
हम SEMANTICKEYPHRASETABLE . का उपयोग करते हैं फ़ाइल तालिका द्वारा प्रबंधित Windows फ़ोल्डर में संग्रहीत दस्तावेज़ों के नाम-आधारित विश्लेषण के लिए कार्य करता है।
निम्न T-SQL स्क्रिप्ट निष्पादित करें:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
आउटपुट:
हमारे पास सभी दस्तावेजों और उनके अंकों से जुड़े सभी प्रमुख वाक्यांशों की एक सूची है। column_id 3 शीर्ष पंक्ति में नाम है कॉलम। साथ ही, हमने इस कॉलम (नाम) की आपूर्ति करके फ़ंक्शन को भी बुलाया:
आप दस्तावेज़_कुंजी पा सकते हैं : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 निम्न स्क्रिप्ट चला रहा है (हालांकि यह स्पष्ट है कि यह दस्तावेज़ वही है जहां नाम में कुंजी वाक्यांश sadaf है। ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
आउटपुट:
कुंजी वाक्यांश सदफ सर्वश्रेष्ठ स्कोर . दिया गया है :1.0 ।
इस प्रकार, शब्दार्थ खोज विश्लेषण के लिए पर्याप्त जानकारी वाले मानक दस्तावेज़ के नामकरण के मामले में, हमारा मुख्य वाक्यांश सदफ़ उस विशेष दस्तावेज़ नाम के लिए सबसे अच्छा मिलान है।
SEMANTICKEYPHRASETABLE फ़ंक्शन का उपयोग करके विशिष्ट दस्तावेज़ का विश्लेषण करना
हम नाम . के आधार पर अपने सिमेंटिक खोज विश्लेषण को सीमित कर सकते हैं कॉलम। उदाहरण के लिए, हमें केवल नाम कॉलम- . देखने की जरूरत है किसी विशेष दस्तावेज़ के आधारित प्रमुख वाक्यांश। हम दस्तावेज़ कुंजी को SEMANTICKEYPHRASETABLE . में निर्दिष्ट कर सकते हैं समारोह।
सबसे पहले, हम उस दस्तावेज़ के लिए दस्तावेज़ कुंजी की पहचान करते हैं जहाँ हम सभी प्रमुख वाक्यांश देखना चाहते हैं। निम्न T-SQL स्क्रिप्ट चलाएँ:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
दस्तावेज़ कुंजी 0xFF6A92952500812FF013376870181CFA6D7C070220 है
अब, आइए इस दस्तावेज़ को उन सभी प्रमुख वाक्यांशों से संबंधित देखें जो दस्तावेज़ के नाम को परिभाषित कर सकते हैं:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
परिणाम:
मुख्य वाक्यांश कर्मचारी इस दस्तावेज़ में सर्वोच्च अंक प्राप्त करता है। हम देख सकते हैं कि कॉलम के सभी शब्द प्रमुख वाक्यांश हैं जो दस्तावेज़ के अर्थ को निर्धारित करते हैं।
SEMANTICSIMILARITYTABLE फंक्शन को समझना
यह फ़ंक्शन मुख्य वाक्यांशों के आधार पर एक दस्तावेज़ की अन्य सभी दस्तावेज़ों के साथ तुलना करने में हमारी सहायता करता है। इस फ़ंक्शन का सिंटैक्स इस प्रकार है:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
इसे अन्य दस्तावेज़ों से मेल खाने के लिए तालिका के नाम, कॉलम और दस्तावेज़ कुंजी की आवश्यकता होती है। उदाहरण के लिए, हम कह सकते हैं कि दो दस्तावेज़ समान हैं यदि उनके पास एक अच्छा कीफ़्रेज़ मिलान स्कोर है।
SEMANTICSIMILARITYTABLE फ़ंक्शन का उपयोग करके दस्तावेज़ों की तुलना करना
आइए SEMANTICSIMILARITYTABLE का उपयोग करके किसी दस्तावेज़ की तुलना अन्य दस्तावेज़ों से करें समारोह।
सभी प्रोजेक्ट मैनेजर के दस्तावेज़ों की तुलना करना
हमें परियोजना प्रबंधकों से संबंधित सभी दस्तावेजों को देखने की जरूरत है। उपरोक्त उदाहरणों से, हम जानते हैं कि दस्तावेज़ कुंजी निर्दिष्ट दस्तावेज़ के लिए 0xFF6A92952500812FF013376870181CFA6D7C070220 है . इसलिए, हम इस कुंजी का उपयोग परियोजना प्रबंधकों सहित अन्य मैचों को खोजने के लिए कर सकते हैं:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
आउटपुट:
सबसे निकट से संबंधित दस्तावेज़ है आसिफ स्थायी कर्मचारी - अनुभवी परियोजना प्रबंधक। docx <मजबूत>। यह समझ में आता है क्योंकि दोनों कर्मचारी स्थायी कर्मचारी हैं, और दोनों ही परियोजना प्रबंधक हैं।
अनुभवी व्यापार विश्लेषक के दस्तावेज़ों की तुलना करना
अब, हम अनुभवी व्यापार विश्लेषक . से संबंधित दस्तावेजों की तुलना करने जा रहे हैं s और सिमेंटिक सर्च का उपयोग करके निकटतम मिलान खोजें। हम दस्तावेज़ के नाम-आधारित विश्लेषण तक सीमित हैं:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
आउटपुट:
जैसा कि हम उपरोक्त परिणामों से देख सकते हैं, अनुभवी व्यापार विश्लेषक . से संबंधित दस्तावेज़ के लिए निकटतम मिलान अनुभवी परियोजना प्रबंधक . का दस्तावेज़ है क्योंकि वे दोनों अनुभवी हैं . फिर भी, 0.3 का स्कोर इंगित करता है कि इन दोनों दस्तावेज़ों के बीच बहुत कुछ समान नहीं है।
निष्कर्ष
बधाई हो! हमने विंडोज फोल्डर में दस्तावेजों को स्टोर करना और सिमेंटिक सर्च का उपयोग करके उनका विश्लेषण करना सफलतापूर्वक सीख लिया है। हमने व्यवहार में उपयोग करने के लिए कार्यों का भी पता लगाया। अब आप नए ज्ञान को लागू कर सकते हैं और निम्न अभ्यासों को आजमा सकते हैं
आगे की सामग्री के लिए बने रहें!