इस लेख का फोकस जॉइन का उपयोग करने पर होगा। हम इस बारे में थोड़ी बात करके शुरू करेंगे कि जॉइन कैसे होने जा रहे हैं और आपको डेटा में शामिल होने की आवश्यकता क्यों है। फिर हम उन जॉइन प्रकारों पर एक नज़र डालेंगे जो हमारे पास उपलब्ध हैं और उनका उपयोग कैसे करें।
मूल बातें शामिल हों
TSQL में जॉइन आमतौर पर FROM लाइन पर किए जाने वाले हैं।
इससे पहले कि हम किसी और चीज़ पर पहुँचें, असली बड़ा सवाल बन जाता है - "हमें जॉइन क्यों करना है, और हम वास्तव में अपने जॉइन कैसे करने जा रहे हैं?"
जैसा कि यह पता चला है, प्रत्येक डेटाबेस जिसके साथ हम कभी भी काम करते हैं, उसका डेटा कई तालिकाओं में विभाजित होने वाला है। इसके कई अलग-अलग कारण हैं:
- डेटा अखंडता बनाए रखना
- संग्रहीत स्थान सहेजना
- डेटा को तेज़ी से संपादित करना
- प्रश्नों को अधिक लचीला बनाना
इस प्रकार, आप जिस भी डेटाबेस के साथ काम करने जा रहे हैं, उसे वास्तव में समझ में आने के लिए उस डेटा को एक साथ जोड़ने की आवश्यकता होगी।
उदाहरण के लिए, आपके पास ऑर्डर और ग्राहकों के लिए अलग-अलग टेबल हैं। यह प्रश्न बन जाता है - "हम वास्तव में सभी डेटा को एक साथ कैसे जोड़ते हैं?" जॉइन ठीक यही करने जा रहे हैं।
जॉइन कैसे काम करता है
उस मामले की कल्पना करें, जब हमारे पास दो अलग-अलग टेबल हों और उन तालिकाओं को एक सीम बनाकर एक साथ लाया जा रहा हो।
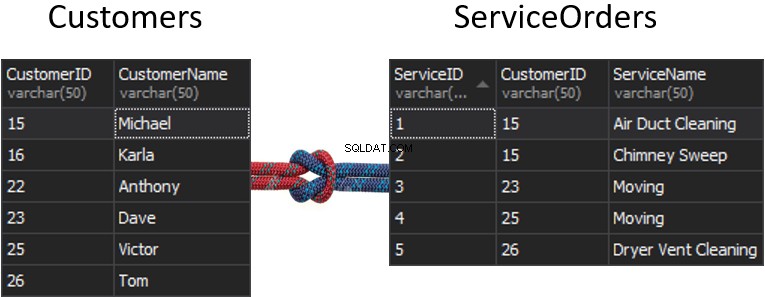
सीम के साथ क्या होने जा रहा है, अगर हमें प्रत्येक तालिका से एक कॉलम मिलता है जिसका उपयोग मिलान के लिए किया जा रहा है, और यह निर्धारित करने जा रहा है कि कौन सी पंक्तियां वापस की जा रही हैं या नहीं? उदाहरण के लिए, हमारे पास बाईं ओर ग्राहक हैं और दाईं ओर ServiceOrders हैं। यदि हम सभी ग्राहकों और उनके आदेशों को प्राप्त करना चाहते हैं, तो हमें इन दो तालिकाओं को एक साथ जोड़ना होगा। इसके लिए, हमें एक कॉलम चुनना होगा जो एक सीम के रूप में कार्य करेगा, और निश्चित रूप से, हम जिस कॉलम का उपयोग करने जा रहे हैं वह CustomerID है।
वैसे, CustomerID को प्राथमिक कुंजी . के रूप में जाना जाता है बाईं तालिका के लिए, जो विशिष्ट रूप से ग्राहक तालिका के भीतर प्रत्येक पंक्ति की पहचान करती है।
ServiceOrders तालिका में, हमारे पास CustomerID कॉलम भी है, जिसे विदेशी कुंजी के रूप में जाना जाता है . एक विदेशी कुंजी बस एक कॉलम है जिसे किसी अन्य तालिका को इंगित करने के लिए डिज़ाइन किया गया है। हमारे मामले में, यह वापस ग्राहक तालिका की ओर इशारा कर रहा है। इसलिए, इस तरह हम उस सीम को प्रदान करके उस सभी डेटा को एक साथ लाने जा रहे हैं।
इन तालिकाओं में, हमारे पास निम्नलिखित मिलान हैं:15 के लिए 2 आदेश और 23, 25, और 26 के लिए 1 आदेश। 16 और 22 छोड़ दिए गए हैं।
यहां ध्यान देने वाली एक बड़ी बात यह है कि हम कई तालिकाओं में शामिल हो सकते हैं . वास्तव में, किसी भी प्रकार की जानकारी प्राप्त करने के लिए कई तालिकाओं को एक साथ जोड़ना काफी सामान्य है। यदि आप सबसे सामान्य डेटाबेस पर एक नज़र डालते हैं, तो आपको केवल वह जानकारी प्राप्त करने के लिए चार, पाँच, छह और अधिक तालिकाओं को एक साथ जोड़ना पड़ सकता है। डेटाबेस डायग्राम का होना मददगार साबित होगा।
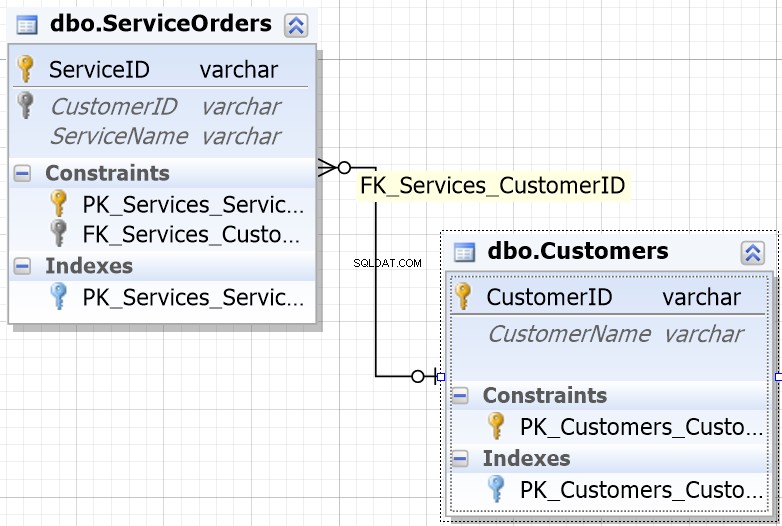
अधिकांश डेटाबेस वातावरण में आपकी मदद करने के लिए आप देखेंगे कि जॉइन करने के लिए डिज़ाइन किए गए कॉलम का एक ही नाम है।
सिंटैक्स में शामिल हों
SQL डेटाबेस क्वेरी भाषा (SQL-92) का तीसरा संशोधन JOIN सिंटैक्स को नियंत्रित करता है:
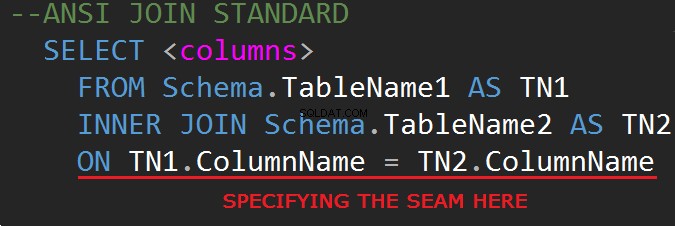
WHERE लाइन पर जॉइन करना संभव है:
एक संबंध में आमतौर पर एक तालिका के रूप में एक सरल चित्रमय व्याख्या होती है।
सर्वोत्तम अभ्यास और परंपराएं
- उपनाम तालिका नाम।
- स्तंभों के लिए दो भागों के नामकरण का प्रयोग करें
- प्रत्येक जॉइन को एक अलग लाइन पर रखें
- तालिकाओं को तार्किक क्रम में रखें
प्रकार में शामिल हों
SQL सर्वर निम्न प्रकार के जॉइन प्रदान करता है:
- इनर जॉइन
- बाहरी शामिल हों
- स्वयं शामिल हों
- क्रॉस जॉइन
विषय पर अधिक जानकारी के लिए, SQL सर्वर में जुड़ने के प्रकारों के बारे में इस लेख को बेझिझक देखें और जानें कि SQL पूर्ण की सहायता से इस तरह के प्रश्नों को लिखना कितना आसान है।
इनर जॉइन
पहले प्रकार के जॉइन जिन्हें हम निष्पादित करना चाहते हैं, वह है इनर जॉइन। आमतौर पर, लेखक इस प्रकार के SQL सर्वर जॉइन को नियमित या सरल जॉइन के रूप में संदर्भित करते हैं। वे सिर्फ INNER उपसर्ग को छोड़ देते हैं। इस प्रकार का जॉइन दो तालिकाओं को एक साथ जोड़ता है और केवल मेल खाने वाली दोनों तरफ से पंक्तियों को लौटाता है ।
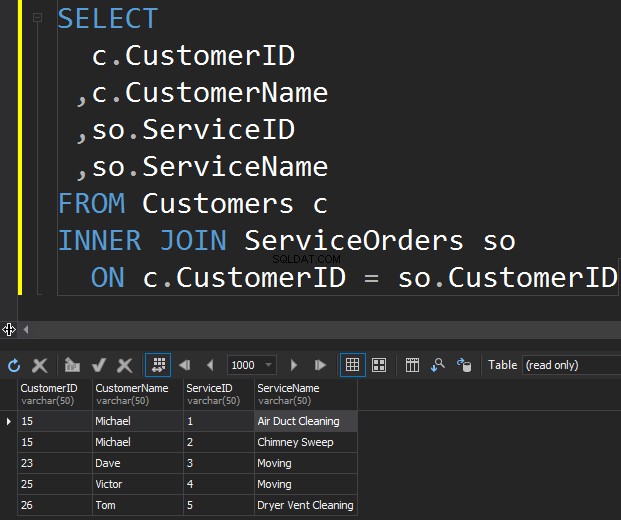
हम यहां क्लारा और एंथनी को नहीं देखते हैं क्योंकि उनका ग्राहक आईडी दोनों तालिकाओं में मेल नहीं खाता है। मैं इस तथ्य को भी उजागर करना चाहता हूं कि जॉइन ऑपरेशन ग्राहक को हर बार ऑर्डर से मेल खाने पर लौटाता है . माइकल के लिए दो ऑर्डर हैं और डेव, विक्टर और टॉम प्रत्येक के लिए एक ऑर्डर है।
सारांश:
- INNER JOIN केवल तभी पंक्तियाँ लौटाता है जब दोनों तालिकाओं में कम से कम एक पंक्ति JOIN शर्त से मेल खाती हो।
- INNER JOIN उन पंक्तियों को हटा देता है जो दूसरी तालिका की किसी पंक्ति से मेल नहीं खाती हैं
बाहरी शामिल हों
आउटर जॉइन अलग होते हैं क्योंकि वे मेल न खाने पर भी टेबल या व्यू से पंक्तियां लौटाते हैं। इस प्रकार का जॉइन उपयोगी है यदि आपको उन सभी ग्राहकों को पुनः प्राप्त करने की आवश्यकता है जिन्होंने कभी ऑर्डर नहीं दिया है। या, उदाहरण के लिए, यदि आप किसी ऐसे उत्पाद की तलाश में हैं जिसे कभी ऑर्डर नहीं किया गया है।
जिस तरह से हम अपने OUTER JOINs करते हैं, वह LEFT या RIGHT, या FULL को दर्शाता है।
निम्नलिखित खंडों में कोई अंतर नहीं है:
- बाएं बाहरी शामिल हों =बाएं शामिल हों
- राइट आउटर जॉइन =राइट जॉइन
- फुल आउटर जॉइन =फुल जॉइन
हालांकि, मैं पूरा खंड लिखने की सलाह दूंगा क्योंकि यह कोड को अधिक पठनीय बनाता है।
बाएं बाहरी जॉइन का उपयोग करना
बाएँ या दाएँ के बीच कोई अंतर नहीं है सिवाय इस तथ्य के कि हम केवल उस तालिका को इंगित करते हैं जिससे हम अतिरिक्त पंक्तियाँ प्राप्त करना चाहते हैं। निम्नलिखित उदाहरण में, हमने ग्राहकों और उनके आदेशों को सूचीबद्ध किया है। हम उन सभी ग्राहकों को प्राप्त करने के लिए LEFT का उपयोग करते हैं जिन्होंने कभी ऑर्डर नहीं दिया है। हम SQL सर्वर से हमें बाईं तालिका से अतिरिक्त पंक्तियाँ प्राप्त करने के लिए कहते हैं।
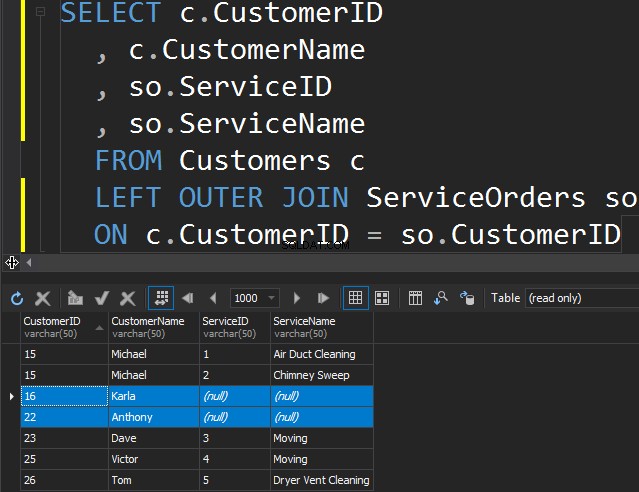
ध्यान दें कि कार्ला और एंथनी ने कोई ऑर्डर नहीं दिया है और परिणामस्वरूप, हमें सर्विसनाम और सर्विसआईडी के लिए NULL मान मिलते हैं। SQL सर्वर नहीं जानता कि वहां क्या रखा जाए, और यह NULLs रखता है।
दाएं बाहरी जॉइन का उपयोग करना
ServiceOrders तालिका से कम लोकप्रिय सेवा प्राप्त करने के लिए, हमें सही दिशा का उपयोग करने की आवश्यकता है।
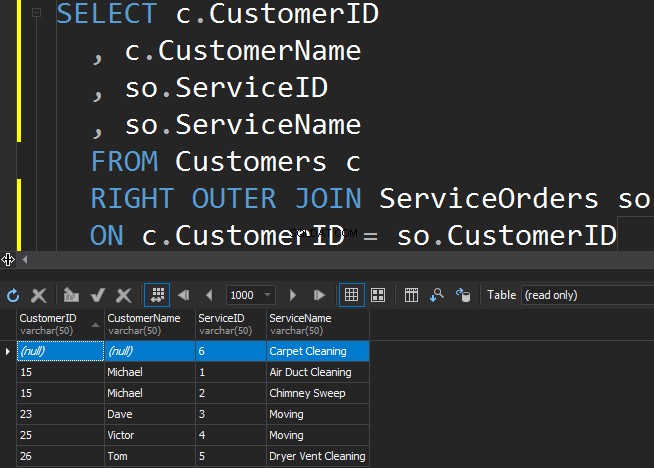
हम देखते हैं कि इस मामले में, SQL सर्वर ने दाएँ तालिका से अतिरिक्त पंक्तियाँ लौटा दीं, और कालीन सफाई सेवा का कभी भी आदेश नहीं दिया गया।
पूर्ण बाहरी जॉइन का उपयोग करना
इस प्रकार का जॉइन आपको दोनों तालिकाओं से गैर-मिलान वाली पंक्तियों को शामिल करके गैर-मिलान जानकारी प्राप्त करने की अनुमति देता है।
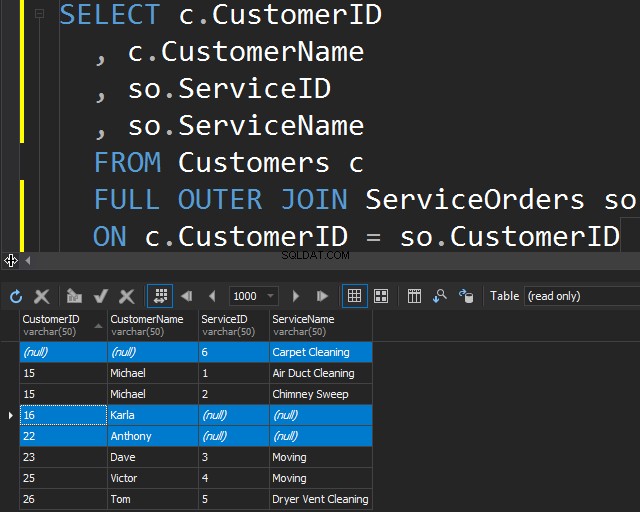
यह तब भी उपयोगी हो सकता है जब आपको डेटा क्लीनअप करने की आवश्यकता हो।
सारांश:
पूर्ण बाहरी शामिल हों
- दोनों तालिकाओं से पंक्तियों को लौटाता है, भले ही वे जॉइन स्टेटमेंट से मेल नहीं खाते हों
बाएँ या दाएँ
- FROM क्लॉज में तालिकाओं के क्रम को छोड़कर कोई अंतर नहीं
- गैर-मिलान वाली पंक्तियों को पुनः प्राप्त करने के लिए तालिका में दिशा बिंदु
स्वयं शामिल हों
अगले प्रकार के जॉइन जो हमारे पास हैं वह है सेल्फ जॉइन। यह शायद दूसरा सबसे कम सामान्य प्रकार का जॉइन है जिसे आप कभी भी निष्पादित करने जा रहे हैं। SELF JOIN तब होता है जब आप किसी टेबल से खुद जुड़ रहे होते हैं। सामान्यतया, यह खराब डिजाइन का संकेत है। एक ही तालिका को एक ही क्वेरी में दो बार उपयोग करने के लिए, तालिका को अलियास किया जाना चाहिए। उपनाम क्वेरी प्रोसेसर को यह पहचानने में मदद करता है कि कॉलम को दाईं या बाईं ओर से डेटा प्रस्तुत करना चाहिए या नहीं। इसके अतिरिक्त, आपको स्वयं को आगे बढ़ने वाली पंक्तियों को समाप्त करने की आवश्यकता है। यह आम तौर पर एक गैर-समान जुड़ाव के साथ किया जाता है।
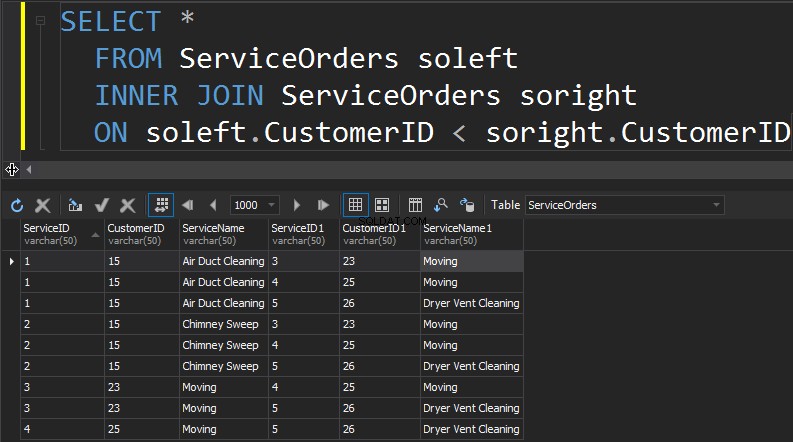
सारांश:
- टेबल को खुद से जोड़ता है
- आम तौर पर खराब डिजाइन और सामान्यीकरण का संकेत
- तालिकाओं का उपनाम होना चाहिए
- स्वयं से मेल खाने वाली पंक्तियों को फ़िल्टर करने की आवश्यकता है
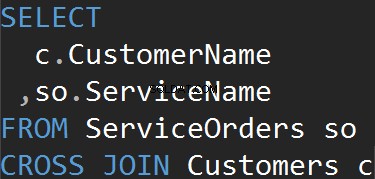
क्रॉस जॉइन
इस प्रकार के जॉइन में चालू . नहीं होता है बयान। प्रत्येक तालिका से प्रत्येक पंक्ति का मिलान होने वाला है। इसे कार्टेशियन उत्पाद के रूप में भी जाना जाता है (यदि क्रॉस जॉइन में WHERE क्लॉज नहीं है)। वास्तविक दुनिया के परिदृश्यों में आप शायद ही इस जॉइन प्रकार का उपयोग करेंगे, हालांकि, यह परीक्षण डेटा उत्पन्न करने का एक अच्छा तरीका है।
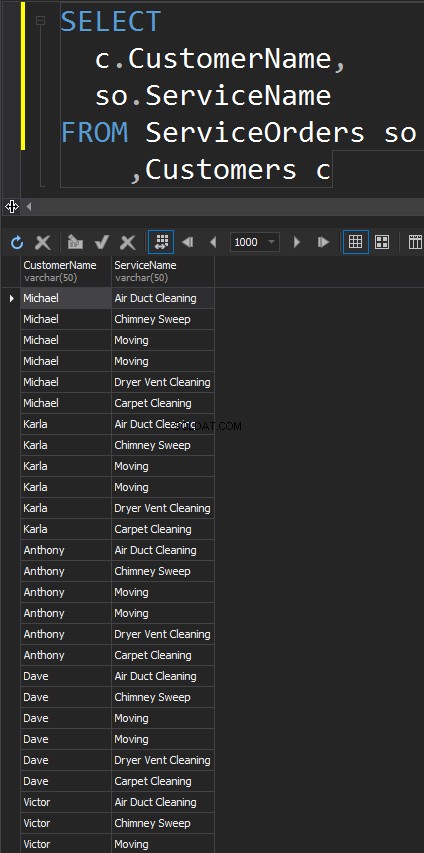
परिणाम एक डेटासेट है, जहां बाईं तालिका में पंक्तियों की संख्या को दाईं तालिका में पंक्तियों की संख्या से गुणा किया जाता है। आखिरकार, हम देखते हैं कि हर एक ग्राहक हर एक सेवा से मेल खाता है।
क्रॉस जॉइन क्लॉज का स्पष्ट रूप से उपयोग करने पर हमें वही परिणाम मिलता है।
सारांश:
- प्रत्येक तालिका से सभी पंक्तियां मेल खाती हैं
- कोई बयान नहीं
- परीक्षण डेटा उत्पन्न करने के लिए इस्तेमाल किया जा सकता है
एल्गोरिदम में शामिल हों
लेख के पहले भाग में, हमने तार्किक . पर चर्चा की है जॉइन ऑपरेटर्स SQL सर्वर क्वेरी पार्सिंग और बाइंडिंग के दौरान उपयोग करता है। वे हैं:
- इनर जॉइन
- बाहरी शामिल हों
- क्रॉस जॉइन
तार्किक संचालक वैचारिक होते हैं और वे भौतिक . से भिन्न होते हैं शामिल हों। अन्यथा, तार्किक जॉइन वास्तव में शामिल नहीं होते हैं विशेष तालिका कॉलम। एक तार्किक जॉइन कई भौतिक जॉइन के अनुरूप हो सकता है। SQL सर्वर ऑप्टिमाइज़ेशन के दौरान लॉजिकल जॉइन को फिजिकल जॉइन में बदल देता है। SQL सर्वर में निम्नलिखित भौतिक जॉइन ऑपरेटर हैं:
- नेस्टेड लूप
- मर्ज करें
- हैश
उपयोगकर्ता इस प्रकार के जॉइन नहीं लिखता या उपयोग नहीं करता है। वे SQL सर्वर इंजन का हिस्सा हैं और SQL सर्वर तार्किक जॉइन को लागू करने के लिए आंतरिक रूप से उनका उपयोग करता है। जब आप निष्पादन योजना की खोज करते हैं, तो आप नोट कर सकते हैं कि SQL सर्वर तार्किक JOIN ऑपरेटरों को तीन भौतिक ऑपरेटरों में से एक के साथ बदल देता है।
नेस्टेड लूप जॉइन
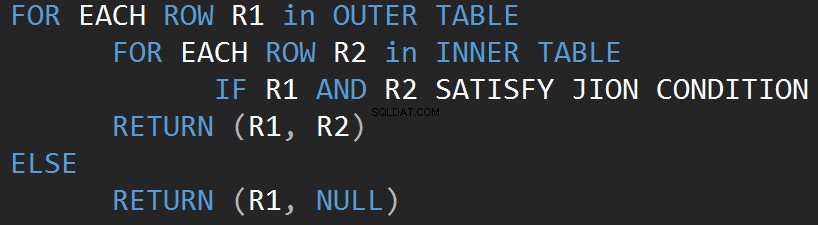
आइए सबसे सरल ऑपरेटर से शुरू करें, जो नेस्टेड लूप है। एल्गोरिथ्म एक तालिका (बाहरी तालिका) की प्रत्येक पंक्ति की तुलना दूसरी तालिका (आंतरिक तालिका) की प्रत्येक पंक्ति से करता है जो JOIN विधेय को पूरा करने वाली पंक्तियों की तलाश में है।
निम्नलिखित छद्म कोड इनर नेस्टेड जॉइन लूप एल्गोरिथम का वर्णन करता है:

निम्नलिखित छद्म कोड बाहरी नेस्टेड जॉइन लूप एल्गोरिथम का वर्णन करता है:
इनपुट का आकार सीधे एल्गोरिथम लागत को प्रभावित करता है। इनपुट बढ़ता है, लागत भी बढ़ती है। छोटे इनपुट के मामले में इस प्रकार का जॉइन एल्गोरिदम कुशल है। SQL सर्वर दोनों इनपुट में प्रत्येक पंक्ति के लिए JOIN विधेय का अनुमान लगाता है।
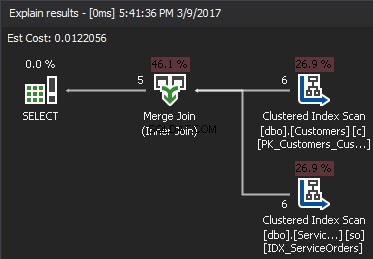
एक उदाहरण के रूप में निम्नलिखित प्रश्न पर विचार करें, जिससे ग्राहक और उनके आदेश प्राप्त होते हैं।
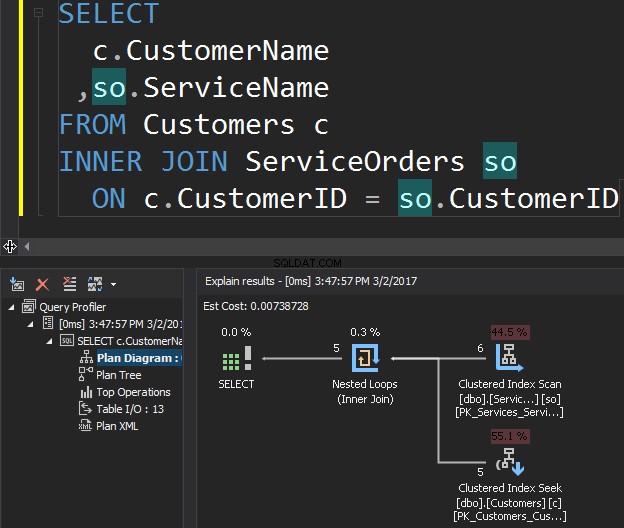
क्लस्टर्ड इंडेक्स स्कैन ऑपरेटर बाहरी इनपुट . है और क्लस्टर्ड इंडेक्स सीक आंतरिक इनपुट . है . नेस्टेड लूप ऑपरेटर वास्तव में मेल खाता है। ऑपरेटर बाहरी इनपुट में प्रत्येक रिकॉर्ड की तलाश करता है और आंतरिक इनपुट में मेल खाने वाली पंक्तियों को ढूंढता है। SQL सर्वर सभी प्रासंगिक रिकॉर्ड प्राप्त करने के लिए केवल एक बार क्लस्टर्ड इंडेक्स स्कैन ऑपरेशन (बाहरी इनपुट) निष्पादित करता है। क्लस्टर्ड इंडेक्स सीक बाहरी इनपुट से प्रत्येक रिकॉर्ड के लिए निष्पादित किया जाता है। इसकी पुष्टि करने के लिए, कर्सर को ऑपरेटर आइकन पर नेविगेट करें और टूलटिप की जांच करें।
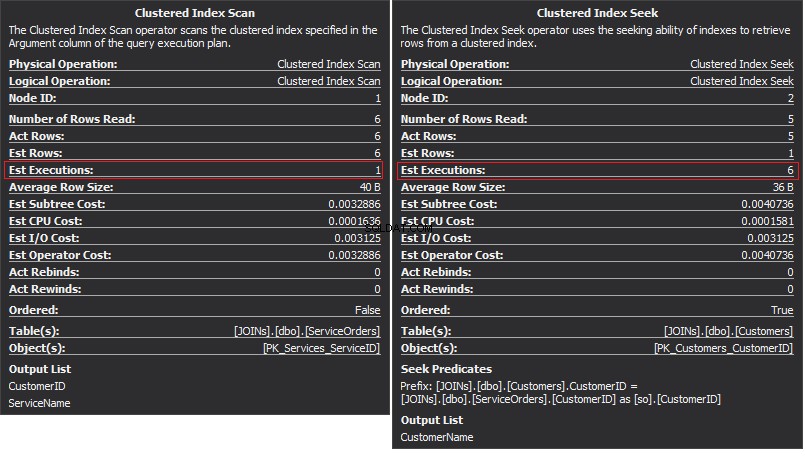
चलो जटिलता के बारे में बात करते हैं। मान लीजिए N बाहरी आउटपुट के लिए पंक्ति संख्या है। एम विक्रय आदेश . में कुल पंक्ति संख्या है टेबल। इस प्रकार, क्वेरी की जटिलता O(NLogM) . है जहां लॉगएम आंतरिक इनपुट में प्रत्येक तलाश की जटिलता है। ऑप्टिमाइज़र हर बार इस ऑपरेटर का चयन करेगा जब बाहरी इनपुट छोटा होगा और आंतरिक इनपुट में कॉलम में एक इंडेक्स होता है जो सीम के रूप में कार्य करता है। इसलिए, इस जॉइन प्रकार के लिए इंडेक्स और आंकड़े आवश्यक हैं, अन्यथा SQL सर्वर गलती से सोच सकता है कि इनपुट में से एक में इतनी पंक्तियां नहीं हैं। इंडेक्स सीक को 100K बार करने के बजाय एक टेबल स्कैन करना बेहतर है। खासकर जब आंतरिक इनपुट आकार 100K से अधिक हो।
सारांश:
नेस्टेड लूप्स
- जटिलता:हे(NlogM)
- आमतौर पर तब लागू होता है जब एक टेबल छोटा होता है
- बड़ी तालिका में एक अनुक्रमणिका होती है जो इसे शामिल होने की कुंजी का उपयोग करके खोजने की अनुमति देती है
मर्ज करें
कुछ डेवलपर्स हैश और मर्ज जॉइन को पूरी तरह से नहीं समझते हैं और अक्सर उन्हें खराब प्रदर्शन वाले प्रश्नों से जोड़ते हैं।
नेस्टेड लूप के विपरीत जो किसी भी जॉइन विधेय को स्वीकार करता है, मर्ज जॉइन के लिए कम से कम एक समान जॉइन की आवश्यकता होती है। साथ ही, दोनों इनपुट को जॉइन कीज़ पर सॉर्ट किया जाना चाहिए।
MERGE JOIN एल्गोरिथम के लिए छद्म कोड:
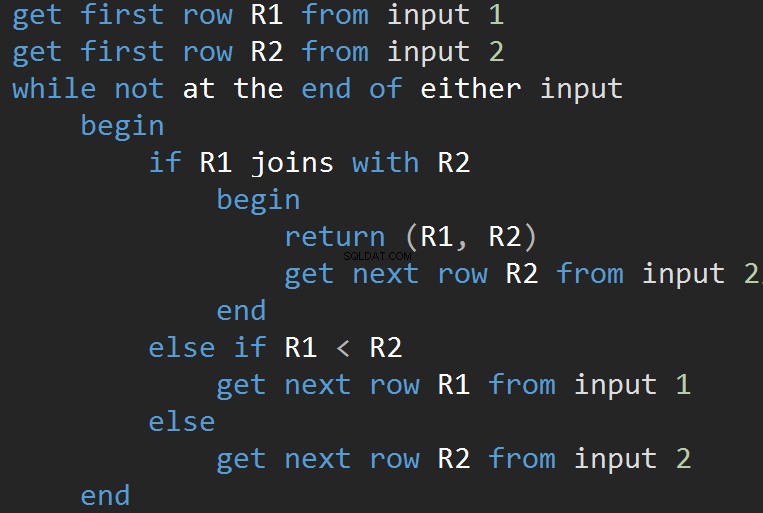
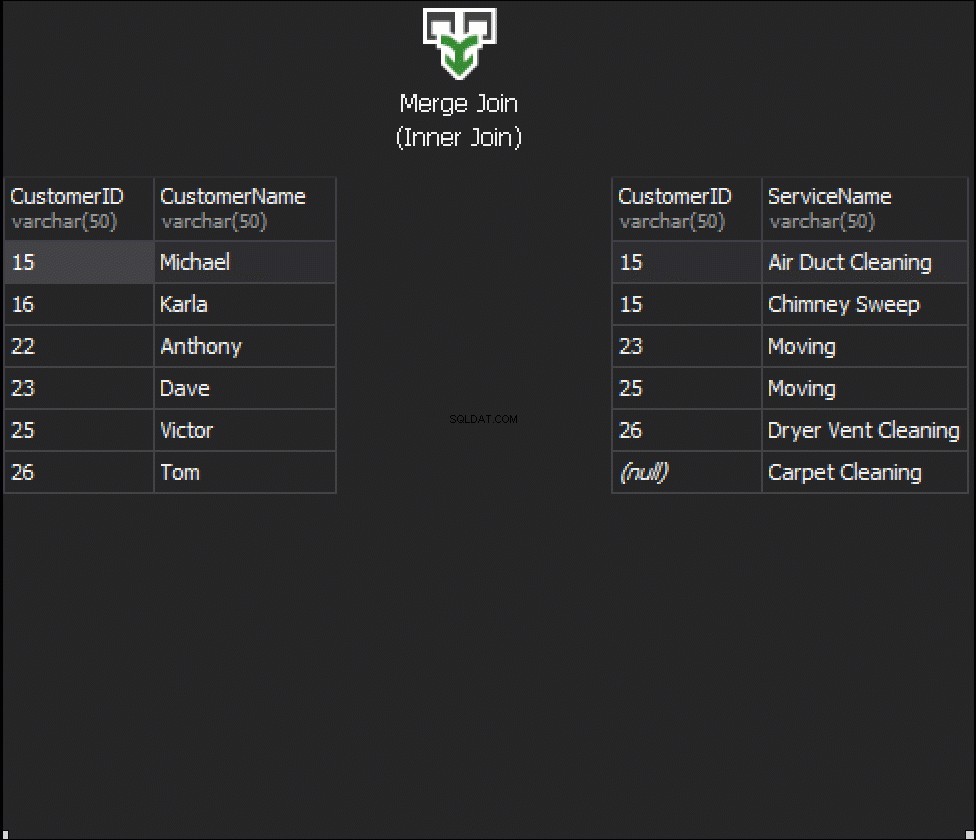
एल्गोरिथ्म दो क्रमबद्ध इनपुट की तुलना करता है। एक समय में एक पंक्ति। यदि दो पंक्तियों के बीच समानता है, तो एल्गोरिथ्म आउटपुट पंक्तियों में शामिल हो जाता है और जारी रहता है। यदि नहीं, तो एल्गोरिथ्म दो इनपुटों में से कम को छोड़ देता है और जारी रखता है। नेस्टेड लूप के विपरीत, यहां लागत इनपुट पंक्तियों की संख्या के योग के समानुपाती होती है। जटिलता के संदर्भ में - <मजबूत> ओ (एन + एम)। इसलिए, इस प्रकार के जॉइन अक्सर बड़े इनपुट के लिए बेहतर होते हैं।
निम्न एनिमेशन दर्शाता है कि MERGE JOIN एल्गोरिथम वास्तव में तालिका पंक्तियों में कैसे जुड़ता है।
सारांश
- जटिलता:ओ(एन+एम)
- दोनों इनपुट को जॉइन की पर सॉर्ट किया जाना चाहिए
- एक समानता ऑपरेटर का उपयोग किया जाता है
- बड़ी तालिकाओं के लिए उत्कृष्ट
हैश जॉइन
हैश जॉइन प्रयोग करने योग्य इंडेक्स के बिना बड़ी टेबल के लिए उपयुक्त है। पहले चरण पर – बिल्ड चरण एल्गोरिथ्म बाईं ओर के इनपुट पर एक इन-मेमोरी हैश इंडेक्स बनाता है। दूसरे चरण को जांच चरण . कहा जाता है . एल्गोरिथम राइट-साइड इनपुट के माध्यम से जाता है और बिल्ड चरण के दौरान बनाए गए इंडेक्स का उपयोग करके मैच ढूंढता है। अगर सच कहा जाए, तो यह अच्छा संकेत नहीं है जब ऑप्टिमाइज़र इस प्रकार के JOIN एल्गोरिथम को चुनता है।
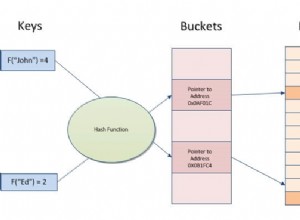
इस प्रकार के जॉइन में दो महत्वपूर्ण अवधारणाएं निहित हैं:हैश फ़ंक्शन और हैश टेबल।
एक हैश फ़ंक्शन कोई भी फ़ंक्शन है जिसका उपयोग चर आकार के डेटा को निश्चित आकार के डेटा में मैप करने के लिए किया जा सकता है।
एक हैश तालिका एक डेटा संरचना है जिसका उपयोग एक सहयोगी सरणी को लागू करने के लिए किया जाता है, एक संरचना जो मूल्यों के लिए कुंजियों को मैप कर सकती है। एक हैश तालिका एक हैश फ़ंक्शन का उपयोग किसी इंडेक्स को बाल्टी या स्लॉट की एक सरणी में गणना करने के लिए करती है, जिससे वांछित मान पाया जा सकता है।
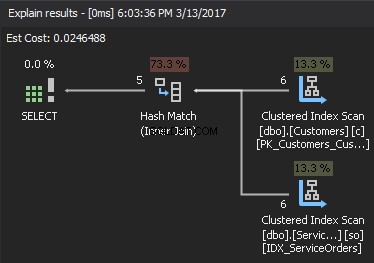
उपलब्ध आंकड़ों के आधार पर, SQL सर्वर बिल्ड इनपुट के रूप में सबसे छोटे इनपुट को चुनता है और इसका उपयोग मेमोरी में हैश टेबल बनाने के लिए करता है। यदि पर्याप्त मेमोरी नहीं है, तो SQL सर्वर TempDB में भौतिक डिस्क स्थान का उपयोग करता है। हैश तालिका बनने के बाद, SQL सर्वर जांच इनपुट (बड़ी तालिका) से डेटा प्राप्त करता है और हैश मिलान फ़ंक्शन का उपयोग करके हैश तालिका से इसकी तुलना करता है। परिणामस्वरूप, यह मिलान वाली पंक्तियों को लौटाता है।
यदि हम निष्पादन योजना को देखें, तो सही शीर्ष तत्व है बिल्ड इनपुट , और दायां निचला तत्व जांच इनपुट . है . यदि दोनों इनपुट बहुत बड़े हैं, तो लागत बहुत अधिक है।
जटिलता का अनुमान लगाने के लिए, निम्न मान लें:
ज<उप>सी - हैश तालिका निर्माण की जटिलता
ज<उप>एम - हैश मैच फंक्शन की जटिलता
एन - छोटी टेबल
एम - बड़ी टेबल
जे - गतिशील गणना और हैश फ़ंक्शन के निर्माण के लिए जटिलता जोड़
जटिलता होगी:O(N*hc + एम*एच<उप>एम + जे)
अनुकूलक मूल्य कार्डिनैलिटी निर्धारित करने के लिए आंकड़ों का उपयोग करता है। फिर यह गतिशील रूप से एक हैश फ़ंक्शन बनाता है जो डेटा को समान आकार के साथ कई बकेट में विभाजित करता है। हैश तालिका निर्माण प्रक्रिया की जटिलता का अनुमान लगाना अक्सर मुश्किल होता है, साथ ही गतिशील प्रकृति के कारण प्रत्येक हैश मैच की जटिलता का अनुमान लगाना मुश्किल होता है। निष्पादन योजना गलत अनुमान भी दिखा सकती है क्योंकि ऑप्टिमाइज़र निष्पादन समय के दौरान इन सभी गतिशील कार्यों को करता है। कुछ मामलों में, निष्पादन योजना दिखा सकती है कि नेस्टेड लूप हैश जॉइन की तुलना में अधिक महंगा है, लेकिन वास्तव में, गलत लागत अनुमान के कारण हैश जॉइन धीमी गति से निष्पादित होता है।
सारांश
- जटिलता:O(N*hc +एम*एच<उप>एम +जे)
- लास्ट-रिज़ॉर्ट जॉइन टाइप
- पंक्तियों से मिलान करने के लिए हैश तालिका और गतिशील हैश मिलान फ़ंक्शन का उपयोग करता है
उपयोगी उत्पाद:
SQL पूर्ण - अपने कोड को आसानी से लिखें, सुशोभित करें, पुन:सक्रिय करें और अपनी उत्पादकता बढ़ाएं।