आपका प्रश्न वास्तव में है सटीक कृपया, @RiggsFolly सुझावों का पालन करें और एक अच्छा प्रश्न कैसे पूछें, इस पर संदर्भ पढ़ें।
साथ ही, जैसा कि @DuduMarkovitz द्वारा सुझाया गया है, आपको समस्या को सरल बनाकर और अपने डेटा को साफ करके शुरू करना चाहिए। आपको आरंभ करने के लिए कुछ संसाधन:
- बेसिक टेक्स्ट प्रोसेसिंग ट्यूटोरियल मैट डेनी द्वारा
- R में स्ट्रिंग्स को संभालना और संसाधित करना गैस्टन सांचेज़ द्वारा
एक बार जब आप परिणामों से संतुष्ट हो जाते हैं, तो आप प्रत्येक Var1 . के लिए एक समूह की पहचान करने के लिए आगे बढ़ सकते हैं प्रविष्टि (इससे आपको समान प्रविष्टियों पर आगे के विश्लेषण/हेरफेर करने में मदद मिलेगी) यह कई अलग-अलग तरीकों से किया जा सकता है लेकिन जैसा कि @GordonLinoff द्वारा उल्लेख किया गया है, एक संभवतः लेवेनशेटिन दूरी है।
नोट :50K प्रविष्टियों के लिए, परिणाम 100% सटीक नहीं होगा क्योंकि यह हमेशा . नहीं होगा शर्तों को उपयुक्त समूह में वर्गीकृत करें लेकिन इससे मैन्युअल प्रयासों में काफी कमी आनी चाहिए।
R में, आप <का उपयोग करके ऐसा कर सकते हैं। कोड>एडिस्ट ()
अपने उदाहरण डेटा का उपयोग करना:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
इस छोटे से नमूने के लिए, आप 3 अलग-अलग समूहों (कम लेवेनस्टीन दूरी मानों के समूह) देख सकते हैं और उन्हें आसानी से मैन्युअल रूप से असाइन कर सकते हैं, लेकिन बड़े सेट के लिए, आपको क्लस्टरिंग एल्गोरिदम की आवश्यकता होगी।
मैंने आपको पहले ही टिप्पणियों में मेरी पिछला उत्तर
यह दिखा रहा है कि hclust() . का उपयोग करके इसे कैसे किया जाए और वार्ड की न्यूनतम भिन्नता विधि लेकिन मुझे लगता है कि यहां आप अन्य तकनीकों का उपयोग करना बेहतर होगा (आर में सबसे व्यापक रूप से उपयोग की जाने वाली कुछ विधियों के त्वरित अवलोकन के लिए विषय पर मेरा पसंदीदा संसाधन यह है विस्तृत उत्तर
)
एफ़िनिटी प्रोपेगेशन क्लस्टरिंग का उपयोग करते हुए एक उदाहरण यहां दिया गया है:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
आपको APResult ऑब्जेक्ट d_ap . में मिलेगा प्रत्येक क्लस्टर से जुड़े तत्व और इस मामले में क्लस्टर की इष्टतम संख्या:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
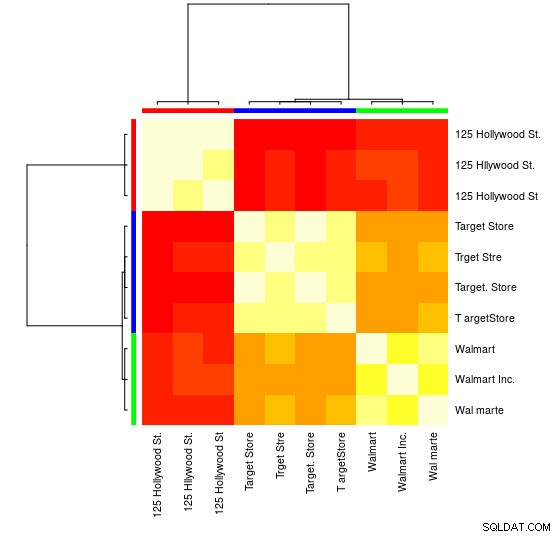
आप एक दृश्य प्रतिनिधित्व भी देख सकते हैं:
> heatmap(d_ap, margins = c(10, 10))
फिर, आप प्रत्येक समूह के लिए और जोड़तोड़ कर सकते हैं। उदाहरण के तौर पर, यहां मैं hunspell . का उपयोग करता हूं Var1 . से प्रत्येक अलग शब्द देखने के लिए वर्तनी की गलतियों के लिए एक en_US शब्दकोश में और प्रत्येक समूह . के भीतर खोजने का प्रयास करें , जो id वर्तनी की कोई त्रुटि नहीं है (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
जो देता है:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
नोट :यहां चूंकि हमने कोई टेक्स्ट प्रोसेसिंग नहीं की है, इसलिए परिणाम बहुत निर्णायक नहीं हैं, लेकिन आपको इसका अंदाजा हो गया है।
डेटा
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)