क्या आप सोच रहे हैं कि Postgresql स्कीमा क्या हैं और वे क्यों महत्वपूर्ण हैं और आप अपने डेटाबेस कार्यान्वयन को अधिक मजबूत और रखरखाव योग्य बनाने के लिए स्कीमा का उपयोग कैसे कर सकते हैं? यह लेख Postgresql में स्कीमा की मूल बातें पेश करेगा और आपको दिखाएगा कि उन्हें कुछ बुनियादी उदाहरणों के साथ कैसे बनाया जाए। भविष्य के लेख वास्तविक अनुप्रयोगों के लिए स्कीमा को सुरक्षित और उपयोग करने के उदाहरणों में तल्लीन होंगे।
सबसे पहले, संभावित शब्दावली भ्रम को दूर करने के लिए, आइए समझते हैं कि Postgresql दुनिया में, "स्कीमा" शब्द शायद कुछ हद तक दुर्भाग्य से अतिभारित है। रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMS) के व्यापक संदर्भ में, शब्द "स्कीमा" को डेटाबेस के समग्र तार्किक या भौतिक डिज़ाइन को संदर्भित करने के लिए समझा जा सकता है, अर्थात, सभी तालिकाओं, स्तंभों, विचारों और अन्य वस्तुओं की परिभाषा जो डेटाबेस परिभाषा का गठन करते हैं। उस व्यापक संदर्भ में एक स्कीमा को एंटिटी-रिलेशनशिप (ईआर) डायग्राम या डेटा डेफिनिशन लैंग्वेज (डीडीएल) स्टेटमेंट की एक स्क्रिप्ट में व्यक्त किया जा सकता है जिसका उपयोग एप्लिकेशन डेटाबेस को इंस्टेंट करने के लिए किया जाता है।
Postgresql की दुनिया में, "स्कीमा" शब्द को "नेमस्पेस" के रूप में बेहतर ढंग से समझा जा सकता है। वास्तव में, Postgresql सिस्टम टेबल में, स्कीमा को "नाम स्थान" नामक तालिका कॉलम में दर्ज किया जाता है, जो कि, IMHO, अधिक सटीक शब्दावली है। एक व्यावहारिक मामले के रूप में, जब भी मैं Postgresql के संदर्भ में "स्कीमा" देखता हूं, तो मैं चुपचाप इसे "नाम स्थान" कहकर पुन:व्याख्या करता हूं।
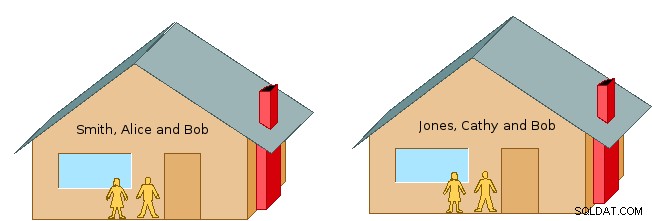
लेकिन आप पूछ सकते हैं:"नाम स्थान क्या है?" आम तौर पर, नाम स्थान नाम से जानकारी को व्यवस्थित करने और पहचानने का एक लचीला माध्यम है। उदाहरण के लिए, दो पड़ोसी परिवारों, स्मिथ, एलिस और बॉब, और जोन्स, बॉब और कैथी की कल्पना करें (cf. चित्र 1)। यदि हम केवल पहले नामों का उपयोग करते हैं, तो यह भ्रमित हो सकता है कि बॉब के बारे में बात करते समय हमारा मतलब किस व्यक्ति से था। लेकिन उपनाम नाम स्मिथ या जोन्स जोड़कर, हम विशिष्ट रूप से पहचानते हैं कि हमारा मतलब किस व्यक्ति से है।
अक्सर, नाम स्थान एक नेस्टेड पदानुक्रम में व्यवस्थित होते हैं। यह बड़ी मात्रा में जानकारी को बहुत बारीक संरचना में कुशल वर्गीकरण की अनुमति देता है, जैसे, उदाहरण के लिए इंटरनेट डोमेन नाम प्रणाली। शीर्ष स्तर पर, ".com", ".net", ".org", ".edu", और आदि व्यापक नाम रिक्त स्थान को परिभाषित करते हैं जिसमें विशिष्ट संस्थाओं के लिए पंजीकृत नाम होते हैं, उदाहरण के लिए, "severalnines.com" और "postgresql.org" विशिष्ट रूप से परिभाषित हैं। लेकिन उनमें से प्रत्येक के अंतर्गत "www", "मेल" और "ftp" जैसे कई सामान्य उप-डोमेन हैं, उदाहरण के लिए, जो अकेले डुप्लीकेट हैं, लेकिन संबंधित नाम रिक्त स्थान अद्वितीय हैं।
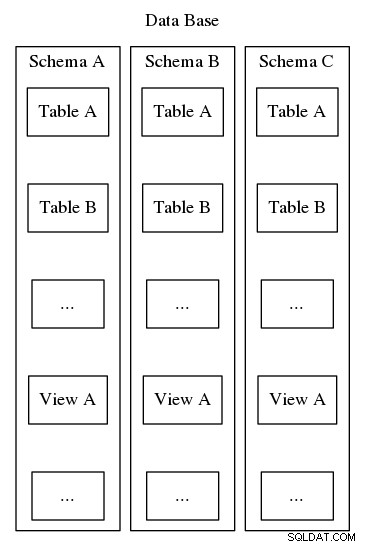
Postgresql स्कीमा व्यवस्थित करने और पहचानने के इसी उद्देश्य की पूर्ति करते हैं, हालांकि, ऊपर दिए गए दूसरे उदाहरण के विपरीत, Postgresql स्कीमा को पदानुक्रम में नेस्ट नहीं किया जा सकता है। जबकि एक डेटाबेस में कई स्कीमा हो सकते हैं, केवल एक ही स्तर होता है और इसलिए डेटाबेस के भीतर, स्कीमा नाम अद्वितीय होना चाहिए। साथ ही, प्रत्येक डेटाबेस में कम से कम एक स्कीमा शामिल होना चाहिए। जब भी कोई नया डेटाबेस त्वरित किया जाता है, तो "सार्वजनिक" नामक एक डिफ़ॉल्ट स्कीमा बनाया जाता है। एक स्कीमा की सामग्री में अन्य सभी डेटाबेस ऑब्जेक्ट शामिल होते हैं जैसे कि टेबल, दृश्य, संग्रहीत कार्यविधियाँ, ट्रिगर, और आदि। कल्पना करने के लिए, चित्र 2 देखें, जिसमें एक मैत्रियोशका गुड़िया जैसी नेस्टिंग को दर्शाया गया है जहां स्कीमा एक की संरचना में फिट होते हैं। Postgresql डेटाबेस।
डेटाबेस ऑब्जेक्ट्स को तार्किक समूहों में व्यवस्थित करने के अलावा उन्हें और अधिक प्रबंधनीय बनाने के अलावा, स्कीमा नाम टकराव से बचने के व्यावहारिक उद्देश्य को पूरा करते हैं। एक परिचालन प्रतिमान में प्रत्येक डेटाबेस उपयोगकर्ता के लिए एक स्कीमा को परिभाषित करना शामिल है ताकि कुछ हद तक अलगाव प्रदान किया जा सके, एक ऐसा स्थान जहां उपयोगकर्ता एक दूसरे के साथ हस्तक्षेप किए बिना अपनी स्वयं की तालिकाओं और विचारों को परिभाषित कर सकें। एक अन्य तरीका यह है कि सभी संबंधित घटकों को तार्किक रूप से एक साथ रखने के लिए अलग-अलग स्कीमा में तीसरे पक्ष के उपकरण या डेटा बेस एक्सटेंशन स्थापित करें। इस श्रृंखला में एक बाद का लेख मजबूत एप्लिकेशन डिज़ाइन के लिए एक उपन्यास दृष्टिकोण का विस्तार करेगा, स्कीमा को अप्रत्यक्ष के साधन के रूप में नियोजित करेगा ताकि डेटाबेस भौतिक डिज़ाइन के जोखिम को सीमित किया जा सके और इसके बजाय एक उपयोगकर्ता इंटरफ़ेस प्रस्तुत किया जा सके जो सिंथेटिक कुंजियों को हल करता है और दीर्घकालिक रखरखाव और कॉन्फ़िगरेशन प्रबंधन की सुविधा प्रदान करता है। जैसे-जैसे सिस्टम आवश्यकताएँ विकसित होती हैं।
चलिए कुछ कोड करते हैं!
आज श्वेतपत्र डाउनलोड करें क्लस्टर नियंत्रण के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, निगरानी करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंडेटाबेस में स्कीमा बनाने का सबसे सरल कमांड है
CREATE SCHEMA hollywood;इस कमांड के लिए डेटाबेस में विशेषाधिकार बनाने की आवश्यकता होती है, और नव-निर्मित स्कीमा "हॉलीवुड" कमांड को लागू करने वाले उपयोगकर्ता के स्वामित्व में होगा। एक अधिक जटिल आह्वान में एक अलग मालिक को निर्दिष्ट करने वाले वैकल्पिक तत्व शामिल हो सकते हैं, और यहां तक कि एक ही कमांड में स्कीमा के भीतर डेटा बेस ऑब्जेक्ट्स को तत्काल करने वाले डीडीएल स्टेटमेंट भी शामिल हो सकते हैं!
सामान्य प्रारूप है
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]जहां "उपयोगकर्ता नाम" वह है जो स्कीमा का मालिक होगा और "schema_element" कुछ डीडीएल आदेशों में से एक हो सकता है (विनिर्देशों के लिए पोस्टग्रेस्क्ल दस्तावेज़ देखें)। प्राधिकरण विकल्प का उपयोग करने के लिए सुपरयुसर विशेषाधिकारों की आवश्यकता होती है।
इसलिए, उदाहरण के लिए, "हॉलीवुड" नाम का एक स्कीमा बनाने के लिए जिसमें "फ़िल्म्स" नाम की एक तालिका है और एक कमांड में "विजेता" नाम का दृश्य है, आप ऐसा कर सकते हैं
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;अतिरिक्त डेटाबेस ऑब्जेक्ट बाद में सीधे बनाए जा सकते हैं, उदाहरण के लिए स्कीमा में एक अतिरिक्त तालिका जोड़ी जाएगी
CREATE TABLE hollywood.actors (name text, dob date, gender text);उपरोक्त उदाहरण में स्कीमा नाम के साथ तालिका नाम के उपसर्ग पर ध्यान दें। यह आवश्यक है क्योंकि डिफ़ॉल्ट रूप से, जो कि स्पष्ट स्कीमा विनिर्देश के बिना है, नए डेटाबेस ऑब्जेक्ट मौजूदा स्कीमा के भीतर बनाए जाते हैं, जिसे हम आगे कवर करेंगे।
याद करें कि ऊपर दिए गए प्रथम नाम स्थान उदाहरण में, हमारे पास बॉब नाम के दो व्यक्ति थे, और हमने वर्णन किया कि उपनाम को शामिल करके उन्हें कैसे अलग किया जाए या उन्हें अलग किया जाए। लेकिन स्मिथ और जोन्स के प्रत्येक घर में अलग-अलग, प्रत्येक परिवार "बॉब" को उस विशेष घर के साथ जाने वाले को संदर्भित करने के लिए समझता है। उदाहरण के लिए, प्रत्येक संबंधित घर के संदर्भ में, ऐलिस को अपने पति को बॉब जोन्स के रूप में संबोधित करने की आवश्यकता नहीं है, और कैथी को अपने पति को बॉब स्मिथ के रूप में संदर्भित करने की आवश्यकता नहीं है:वे प्रत्येक बस "बॉब" कह सकते हैं।
Postgresql वर्तमान स्कीमा उपरोक्त उदाहरण में घर की तरह है। वर्तमान स्कीमा में वस्तुओं को अयोग्य संदर्भित किया जा सकता है, लेकिन अन्य स्कीमाओं में समान-नामित वस्तुओं का संदर्भ देने के लिए ऊपर के रूप में स्कीमा नाम को उपसर्ग करके नाम की योग्यता की आवश्यकता होती है।
वर्तमान स्कीमा "search_path" कॉन्फ़िगरेशन पैरामीटर से लिया गया है। यह पैरामीटर स्कीमा नामों की अल्पविराम से अलग की गई सूची को संग्रहीत करता है और कमांड के साथ जांच की जा सकती है
SHOW search_path;या
. के साथ एक नए मान पर सेट करेंSET search_path TO schema [, schema, ...];सूची में पहला स्कीमा नाम "वर्तमान स्कीमा" है और यह वह जगह है जहां स्कीमा नाम योग्यता के बिना निर्दिष्ट किए जाने पर नए ऑब्जेक्ट बनाए जाते हैं।
स्कीमा नामों की अल्पविराम से अलग की गई सूची उस खोज क्रम को निर्धारित करने का काम भी करती है जिसके द्वारा सिस्टम मौजूदा अयोग्य नामित वस्तुओं का पता लगाता है। उदाहरण के लिए, स्मिथ और जोन्स पड़ोस में, केवल "बॉब" को संबोधित एक पैकेज डिलीवरी के लिए प्रत्येक घर में जाने की आवश्यकता होगी जब तक कि "बॉब" नाम का पहला निवासी न मिल जाए। ध्यान दें, यह इच्छित प्राप्तकर्ता नहीं हो सकता है। Postgresql के लिए भी यही तर्क लागू होता है। सिस्टम search_path के क्रम में स्कीमा के भीतर तालिकाओं, दृश्यों और अन्य वस्तुओं की खोज करता है, और फिर पहले पाया गया नाम मिलान ऑब्जेक्ट का उपयोग किया जाता है। स्कीमा-योग्य नामित ऑब्जेक्ट सीधे search_path के संदर्भ के बिना उपयोग किए जाते हैं।
डिफ़ॉल्ट कॉन्फ़िगरेशन में, search_path कॉन्फ़िगरेशन चर को क्वेरी करने से यह मान प्रकट होता है
SHOW search_path;
Search_path
--------------
"$user", publicसिस्टम ऊपर दिखाए गए पहले मान की व्याख्या वर्तमान लॉग इन उपयोगकर्ता नाम के रूप में करता है और पहले बताए गए उपयोग के मामले को समायोजित करता है जहां प्रत्येक उपयोगकर्ता को अन्य उपयोगकर्ताओं से अलग कार्य स्थान के लिए उपयोगकर्ता-नामित स्कीमा आवंटित किया जाता है। यदि ऐसा कोई उपयोगकर्ता-नामित स्कीमा नहीं बनाया गया है, तो उस प्रविष्टि को अनदेखा कर दिया जाता है और "सार्वजनिक" स्कीमा वर्तमान स्कीमा बन जाती है जहां नई वस्तुएं बनाई जाती हैं।
इस प्रकार, "हॉलीवुड.एक्टर्स" तालिका बनाने के हमारे पहले के उदाहरण पर वापस, यदि हमने स्कीमा नाम के साथ तालिका नाम को योग्य नहीं किया होता, तो तालिका सार्वजनिक स्कीमा में बनाई जाती। यदि हम एक विशिष्ट स्कीमा के भीतर सभी ऑब्जेक्ट बनाने का अनुमान लगाते हैं, तो search_path चर सेट करना सुविधाजनक हो सकता है जैसे कि
SET search_path TO hollywood,public;डेटाबेस ऑब्जेक्ट बनाने या एक्सेस करने के लिए अयोग्य नाम टाइप करने की शॉर्टहैंड की सुविधा।
एक सिस्टम सूचना फ़ंक्शन भी है जो वर्तमान स्कीमा को एक क्वेरी के साथ लौटाता है
select current_schema();स्पेलिंग को मोटा-मोटा करने के मामले में, स्कीमा का स्वामी नाम बदल सकता है, बशर्ते उपयोगकर्ता के पास डेटाबेस के लिए
के साथ विशेषाधिकार भी हों।ALTER SCHEMA old_name RENAME TO new_name;और अंत में, डेटाबेस से स्कीमा को हटाने के लिए, एक ड्रॉप कमांड है
DROP SCHEMA schema_name;यदि स्कीमा में कोई ऑब्जेक्ट है, तो DROP कमांड विफल हो जाएगा, इसलिए उन्हें पहले हटाया जाना चाहिए, या आप वैकल्पिक रूप से CASCADE विकल्प के साथ स्कीमा की सभी सामग्री को फिर से हटा सकते हैं
DROP SCHEMA schema_name CASCADE;ये मूलभूत बातें आपको स्कीमा को समझने में मदद करेंगी!