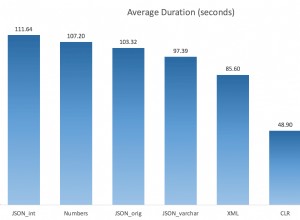
InnoDB में , पंक्तियों को प्राथमिक कुंजी क्रम में संग्रहीत किया जाता है। यदि आप LIMIT का उपयोग करते हैं बिना ORDER BY . के , आपको हमेशा सबसे कम प्राथमिक कुंजी मान वाली पंक्तियाँ मिलेंगी, भले ही आपने उन्हें यादृच्छिक क्रम में डाला हो।
create table foo (id int primary key, x char(1), y int) engine=InnoDB;
insert into foo values (5, 'A', 123);
insert into foo values (9, 'B', 234);
insert into foo values (2, 'C', 345);
insert into foo values (4, 'D', 456);
insert into foo values (1, 'E', 567);
select * from foo;
+----+------+------+
| id | x | y |
+----+------+------+
| 1 | E | 567 |
| 2 | C | 345 |
| 4 | D | 456 |
| 5 | A | 123 |
| 9 | B | 234 |
+----+------+------+
MyISAM में , पंक्तियाँ जहाँ भी फिट होती हैं उन्हें संग्रहीत किया जाता है। प्रारंभ में, इसका मतलब है कि पंक्तियों को डेटा फ़ाइल में जोड़ा जाता है, लेकिन जैसे ही आप पंक्तियों को हटाते हैं और नई सम्मिलित करते हैं, हटाए गए पंक्तियों द्वारा छोड़े गए अंतराल को नई पंक्तियों द्वारा पुन:उपयोग किया जाएगा।
create table bar (id int primary key, x char(1), y int) engine=MyISAM;
insert into bar values (1, 'A', 123);
insert into bar values (2, 'B', 234);
insert into bar values (3, 'C', 345);
insert into bar values (4, 'D', 456);
insert into bar values (5, 'E', 567);
select * from bar;
+----+------+------+
| id | x | y |
+----+------+------+
| 1 | A | 123 |
| 2 | B | 234 |
| 3 | C | 345 |
| 4 | D | 456 |
| 5 | E | 567 |
+----+------+------+
delete from bar where id between 3 and 4;
insert into bar values (6, 'F', 678);
insert into bar values (7, 'G', 789);
insert into bar values (8, 'H', 890);
select * from bar;
+----+------+------+
| id | x | y |
+----+------+------+
| 1 | A | 123 |
| 2 | B | 234 |
| 7 | G | 789 | <-- new row fills gap
| 6 | F | 678 | <-- new row fills gap
| 5 | E | 567 |
| 8 | H | 890 | <-- new row appends at end
+----+------+------+
यदि आप InnoDB का उपयोग करते हैं तो एक अन्य अपवाद मामला यह है कि यदि आप प्राथमिक अनुक्रमणिका के बजाय द्वितीयक अनुक्रमणिका से पंक्तियाँ प्राप्त कर रहे हैं। ऐसा तब होता है जब आप EXPLAIN आउटपुट में "इंडेक्स का उपयोग करना" नोट देखते हैं।
alter table foo add index (x);
select id, x from foo;
+----+------+
| id | x |
+----+------+
| 5 | A |
| 9 | B |
| 2 | C |
| 4 | D |
| 1 | E |
+----+------+
यदि आपके पास जुड़ने के साथ अधिक जटिल प्रश्न हैं, तो यह और भी जटिल हो जाता है, क्योंकि आपको पहली तालिका के डिफ़ॉल्ट क्रम से पंक्तियों को वापस मिल जाएगा (जहां "पहला" टेबल के क्रम को चुनने वाले ऑप्टिमाइज़र पर निर्भर है), फिर सम्मिलित तालिका से पंक्तियाँ पिछली तालिका से पंक्तियों के क्रम पर निर्भर होंगी।
select straight_join foo.*, bar.* from bar join foo on bar.x=foo.x;
+----+------+------+----+------+------+
| id | x | y | id | x | y |
+----+------+------+----+------+------+
| 1 | E | 567 | 5 | E | 567 |
| 5 | A | 123 | 1 | A | 123 |
| 9 | B | 234 | 2 | B | 234 |
+----+------+------+----+------+------+
select straight_join foo.*, bar.* from foo join bar on bar.x=foo.x;
+----+------+------+----+------+------+
| id | x | y | id | x | y |
+----+------+------+----+------+------+
| 5 | A | 123 | 1 | A | 123 |
| 9 | B | 234 | 2 | B | 234 |
| 1 | E | 567 | 5 | E | 567 |
+----+------+------+----+------+------+
लब्बोलुआब यह है कि स्पष्ट होना सबसे अच्छा है:जब आप LIMIT का उपयोग करते हैं , एक ORDER BY specify निर्दिष्ट करें .