कुछ हफ़्ते पहले, मैंने लिखा था कि SQL सर्वर 2016 में एक नए नेटिव फ़ंक्शन के प्रदर्शन पर मुझे कितना आश्चर्य हुआ, STRING_SPLIT() :
- प्रदर्शन आश्चर्य और अनुमान :STRING_SPLIT()
पोस्ट प्रकाशित होने के बाद, मुझे इन सुझावों के साथ कुछ टिप्पणियां (सार्वजनिक और निजी तौर पर) मिलीं (या ऐसे प्रश्न जिन्हें मैंने सुझावों में बदल दिया):
- JSON दृष्टिकोण के लिए एक स्पष्ट आउटपुट डेटा प्रकार निर्दिष्ट करना, ताकि उस विधि को
nvarchar(max)के फ़ॉलबैक के कारण संभावित प्रदर्शन ओवरहेड से ग्रस्त न हो । - थोड़ा अलग दृष्टिकोण का परीक्षण, जहां वास्तव में डेटा के साथ कुछ किया जाता है - अर्थात्
SELECT INTO #temp। - दिखा रहा है कि अनुमानित पंक्तियों की संख्या मौजूदा विधियों की तुलना में कैसी है, विशेष रूप से विभाजन संचालन को नेस्ट करते समय।
मैंने कुछ लोगों को ऑफ़लाइन जवाब दिया, लेकिन सोचा कि यहां एक अनुवर्ती पोस्ट करना उचित होगा।
JSON के प्रति बेहतर होना
मूल JSON फ़ंक्शन इस तरह दिखता था, जिसमें आउटपुट डेटा प्रकार के लिए कोई विनिर्देश नहीं था:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); मैंने इसका नाम बदल दिया, और निम्नलिखित परिभाषाओं के साथ दो और बनाए:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); मैंने सोचा था कि इससे प्रदर्शन में काफी सुधार होगा, लेकिन अफसोस, ऐसा नहीं था। मैंने फिर से परीक्षण चलाए और परिणाम इस प्रकार थे:
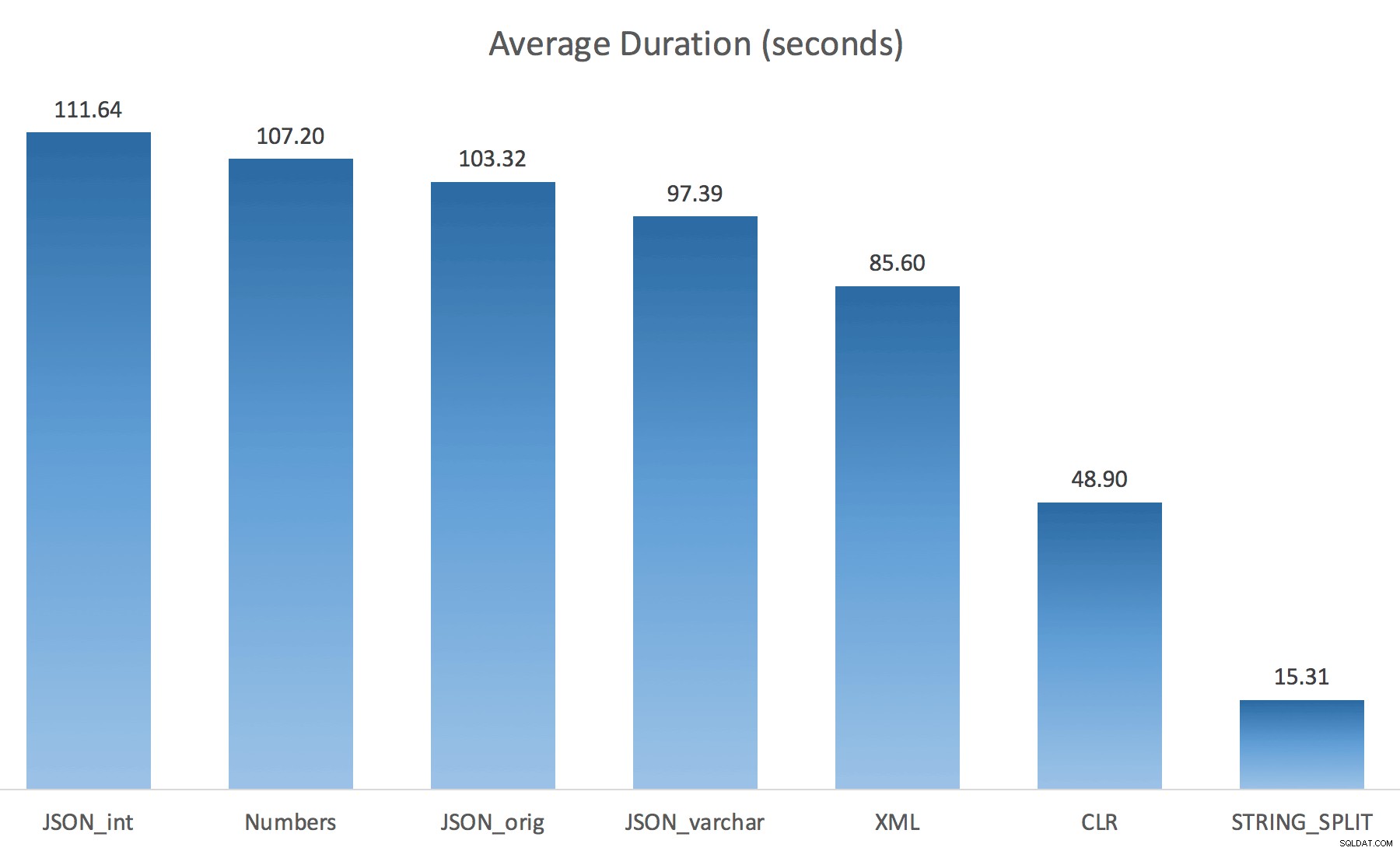
परीक्षण के एक यादृच्छिक उदाहरण के दौरान देखे गए प्रतीक्षा (उन लोगों के लिए फ़िल्टर्ड> 25):
| CLR | IO_COMPLETION | 1,595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6,294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4,307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6,110 |
| SOS_SCHEDULER_YIELD | 87 | |
| नंबर | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1,917 |
| IO_COMPLETION | 1,616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
प्रतीक्षित प्रतीक्षा> 25 (ध्यान दें कि STRING_SPLIT के लिए कोई प्रविष्टि नहीं है )
डिफ़ॉल्ट से varchar(100) . में बदलते समय प्रदर्शन में थोड़ा सुधार हुआ, लाभ नगण्य था, और int . में बदल रहा था वास्तव में इसे और खराब कर दिया। इसमें जोड़ें कि आपको संभवतः STRING_ESCAPE() add जोड़ना होगा कुछ परिदृश्यों में आने वाली स्ट्रिंग के लिए, बस उनके पास ऐसे वर्ण हैं जो JSON पार्सिंग को गड़बड़ कर देंगे। मेरा निष्कर्ष अभी भी है कि यह नई JSON कार्यक्षमता का उपयोग करने का एक साफ-सुथरा तरीका है, लेकिन ज्यादातर एक नवीनता उचित पैमाने के लिए अनुपयुक्त है।
आउटपुट को भौतिक बनाना
जोनाथन मैगनन ने मेरी पिछली पोस्ट पर यह सूक्ष्म अवलोकन किया:
STRING_SPLIT वास्तव में बहुत तेज़ है, हालांकि अस्थायी तालिका के साथ काम करते समय नरक के रूप में भी धीमा है (जब तक कि इसे भविष्य के निर्माण में ठीक नहीं किया जाता)।SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
SQL CLR समाधान (15x और अधिक!) की तुलना में धीमा होगा।
इसलिए, मैंने खोद लिया। मैंने कोड बनाया जो मेरे प्रत्येक कार्य को कॉल करेगा और परिणामों को #temp तालिका में डंप करेगा, और उन्हें समय देगा:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
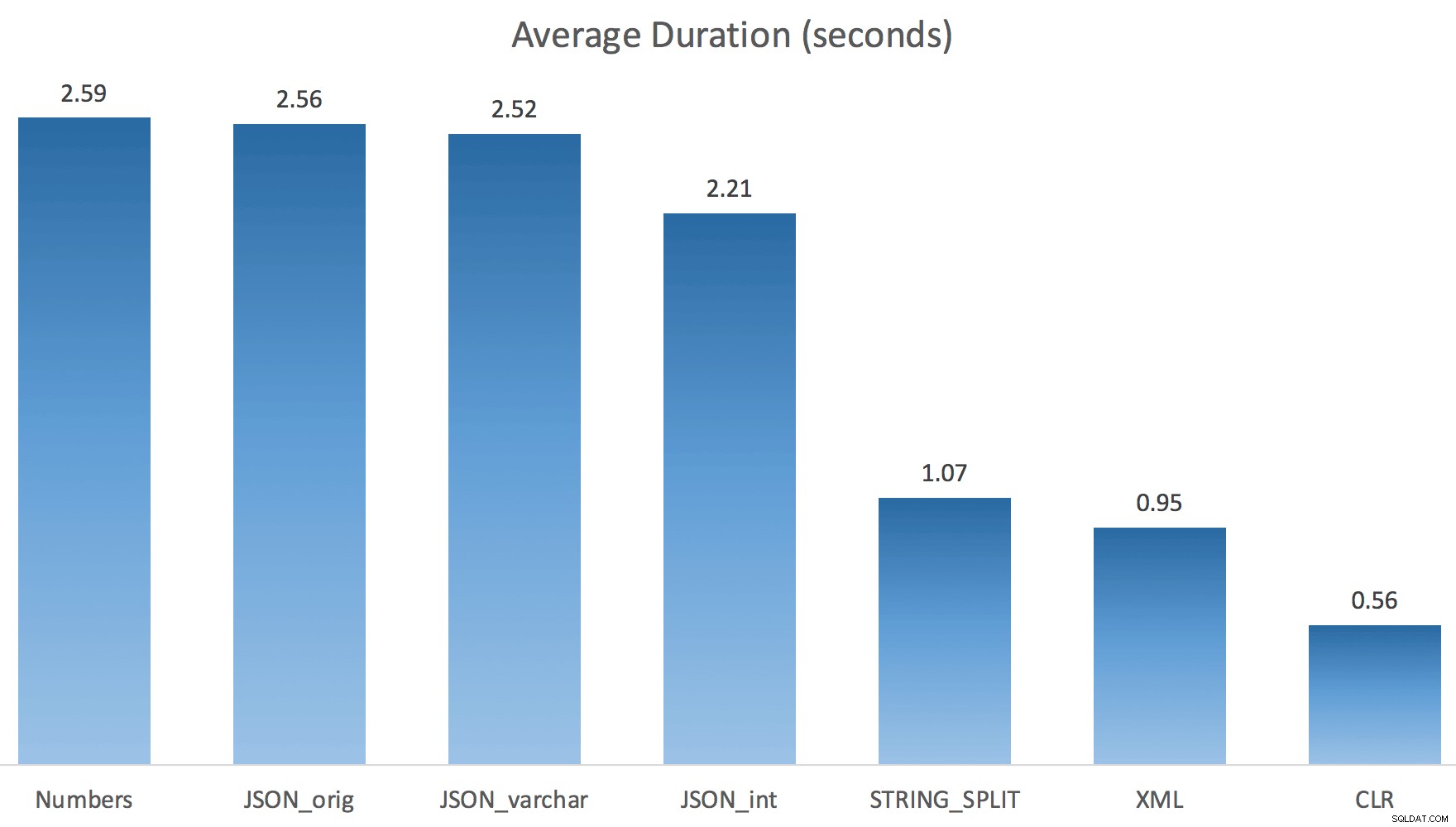
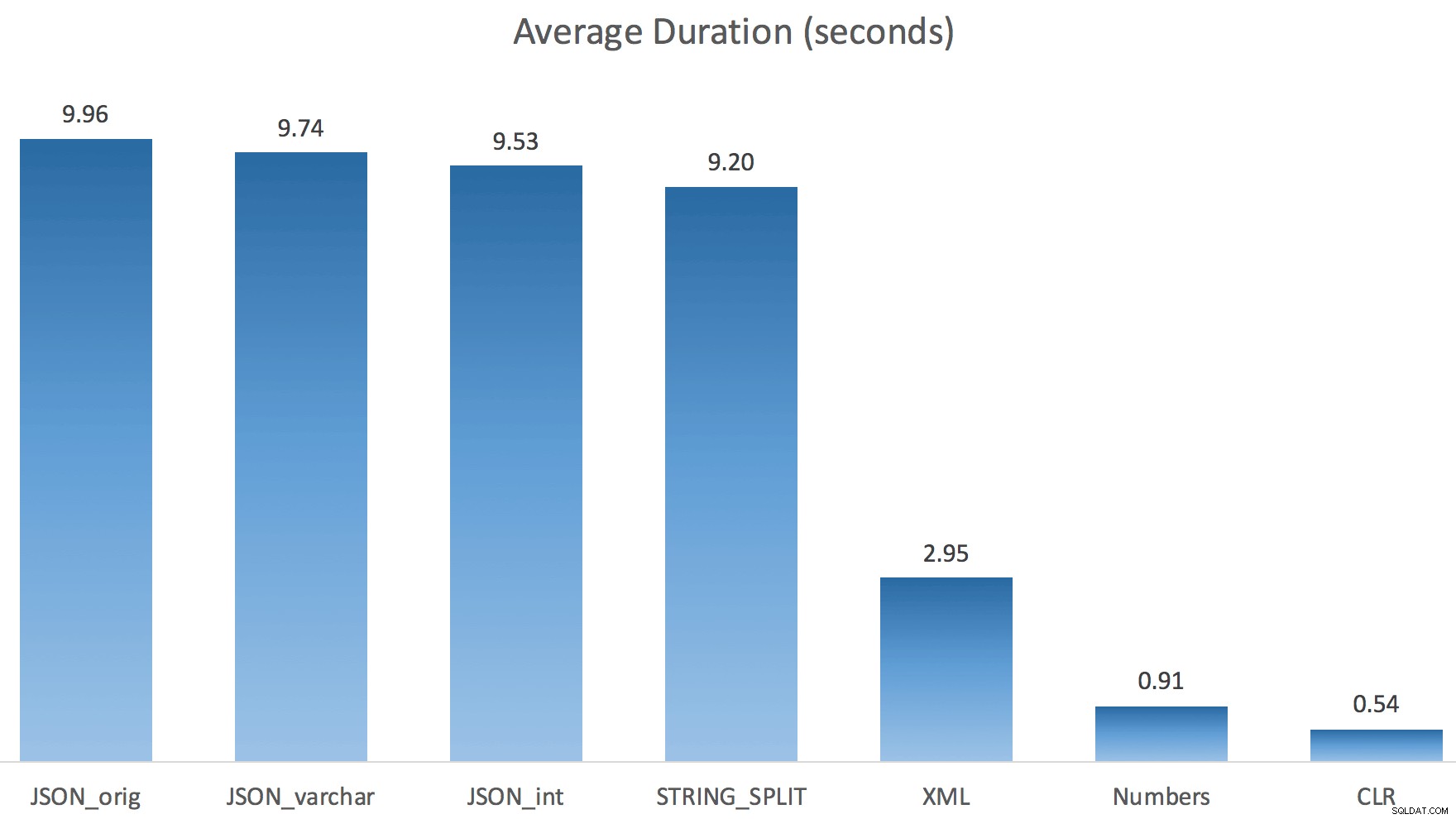
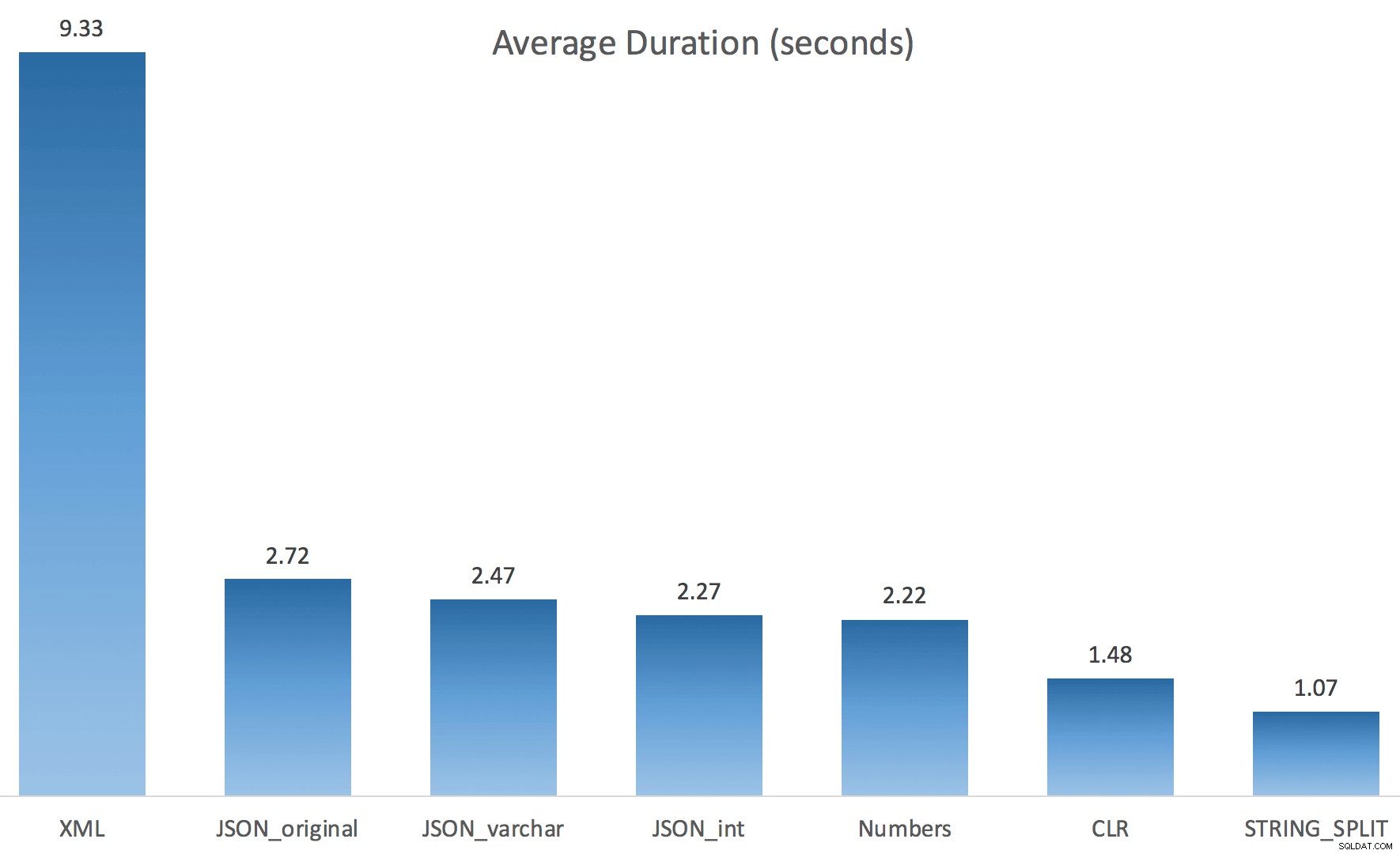
मैंने प्रत्येक परीक्षण को एक बार (100 बार लूप के बजाय) चलाया, क्योंकि मैं अपने सिस्टम पर I/O को पूरी तरह से थ्रैश नहीं करना चाहता था। फिर भी, तीन टेस्ट रन के औसत के बाद, जोनाथन बिल्कुल, 100% सही था। प्रत्येक विधि का उपयोग करके ~ 500,000 पंक्तियों के साथ #temp तालिका को पॉप्युलेट करने की अवधि यहां दी गई थी:
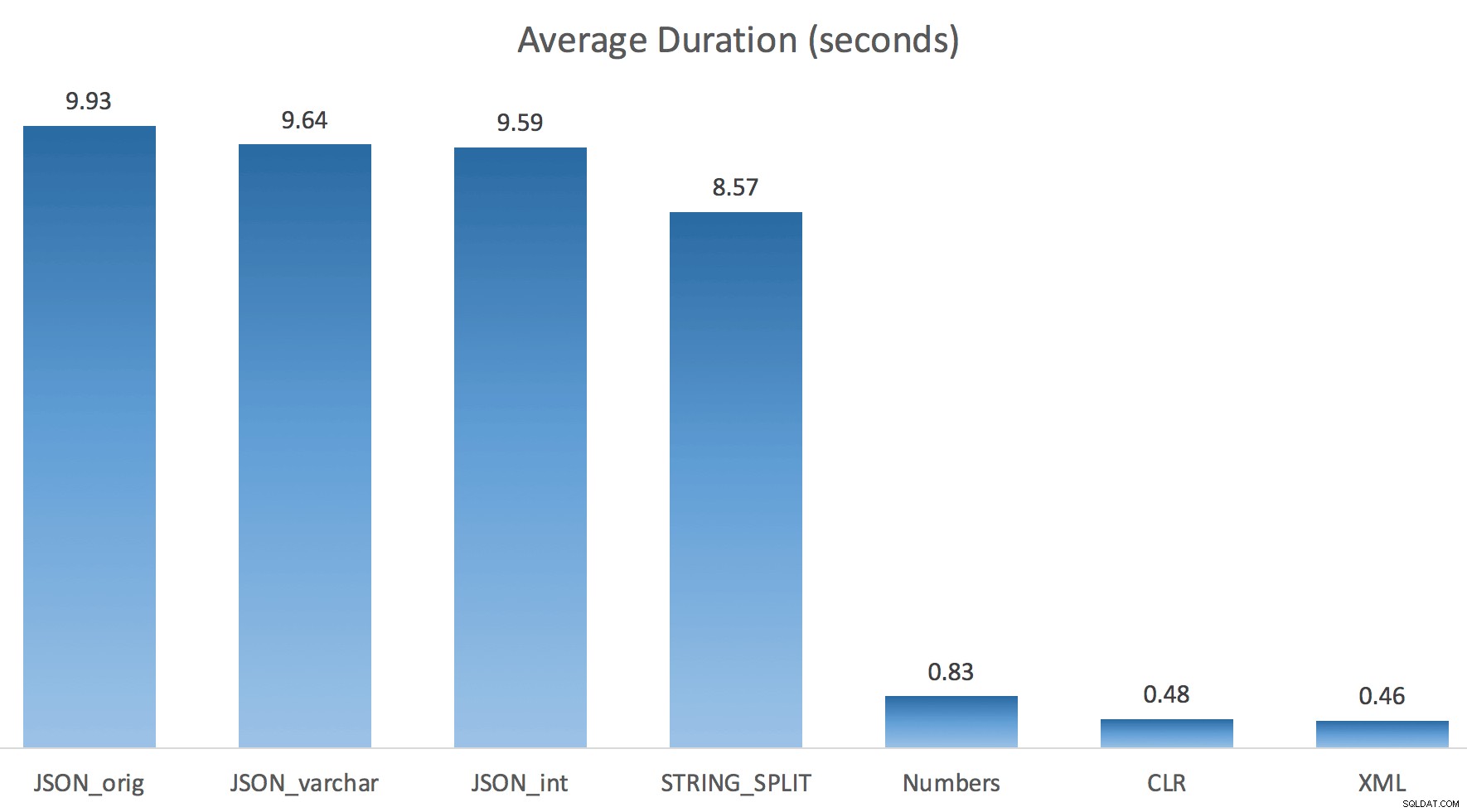
तो यहाँ, JSON और STRING_SPLIT विधियों में प्रत्येक में लगभग 10 सेकंड का समय लगा, जबकि Numbers तालिका, CLR और XML दृष्टिकोण में एक सेकंड से भी कम समय लगा। उलझन में, मैंने प्रतीक्षा की जांच की, और निश्चित रूप से, बाईं ओर चार विधियों ने महत्वपूर्ण LATCH_EX खर्च किया प्रतीक्षा (लगभग 25 सेकंड) अन्य तीन में नहीं देखी गई, और बोलने के लिए कोई अन्य महत्वपूर्ण प्रतीक्षा नहीं थी।
और चूंकि कुंडी की प्रतीक्षा कुल अवधि से अधिक थी, इसने मुझे एक सुराग दिया कि इसका समानांतरवाद से कोई लेना-देना नहीं है (इस विशेष मशीन में 4 कोर हैं)। इसलिए मैंने फिर से टेस्ट कोड जेनरेट किया, यह देखने के लिए कि समानांतरवाद के बिना क्या होगा, सिर्फ एक लाइन को बदलते हुए:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
अब STRING_SPLIT बहुत बेहतर प्रदर्शन किया (जैसा कि JSON विधियों ने किया था), लेकिन फिर भी CLR द्वारा लिए गए समय से कम से कम दोगुना:
इसलिए, समानांतरवाद शामिल होने पर इन नए तरीकों में एक शेष मुद्दा हो सकता है। यह कोई थ्रेड वितरण समस्या नहीं थी (मैंने इसकी जांच की), और सीएलआर का अनुमान वास्तव में खराब था (STRING_SPLIT के लिए 100x वास्तविक बनाम केवल 5x) ); मुझे लगता है कि धागे के बीच समन्वय समन्वय के साथ बस कुछ अंतर्निहित मुद्दा। अभी के लिए, MAXDOP 1 . का उपयोग करना उपयोगी हो सकता है यदि आप जानते हैं कि आप आउटपुट को नए पृष्ठों पर लिख रहे हैं।
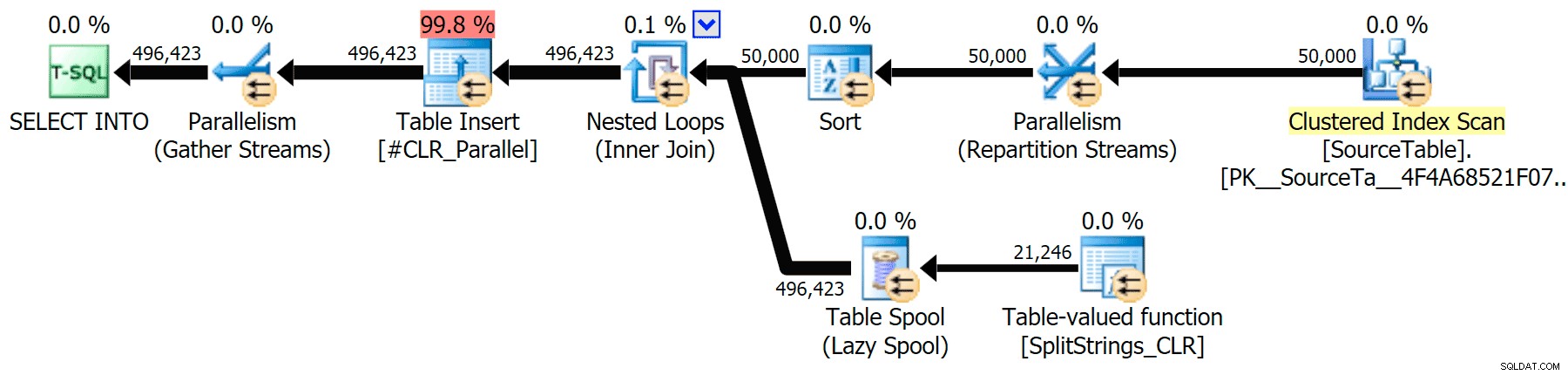
मैंने समानांतर और सीरियल निष्पादन दोनों के लिए सीएलआर दृष्टिकोण की तुलना मूल एक से करने वाली ग्राफिकल योजनाओं को शामिल किया है (मैंने एक क्वेरी विश्लेषण फ़ाइल भी अपलोड की है जिसे आप एसक्यूएल सेंट्री प्लान एक्सप्लोरर में खोल सकते हैं ताकि आप अपने आप को देख सकें):
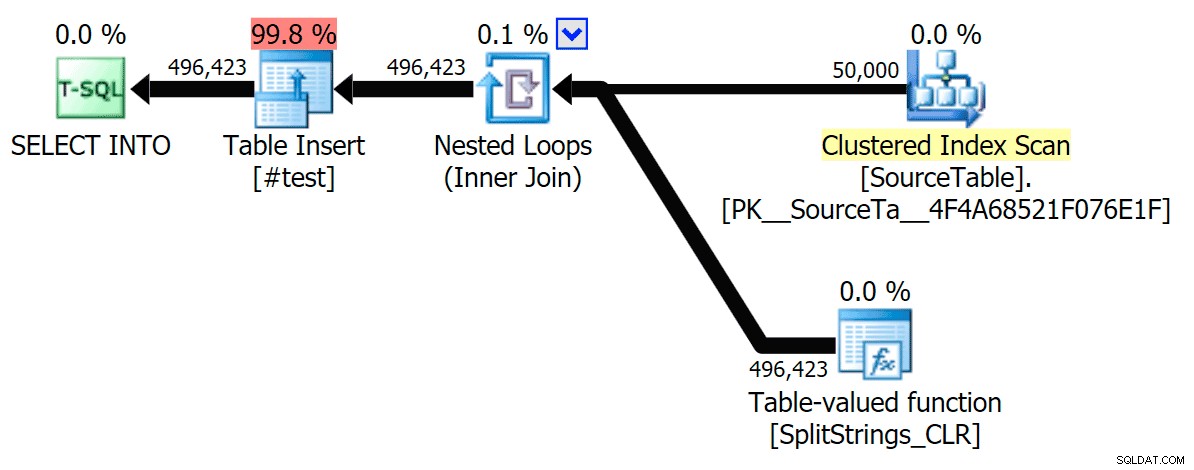
STRING_SPLIT
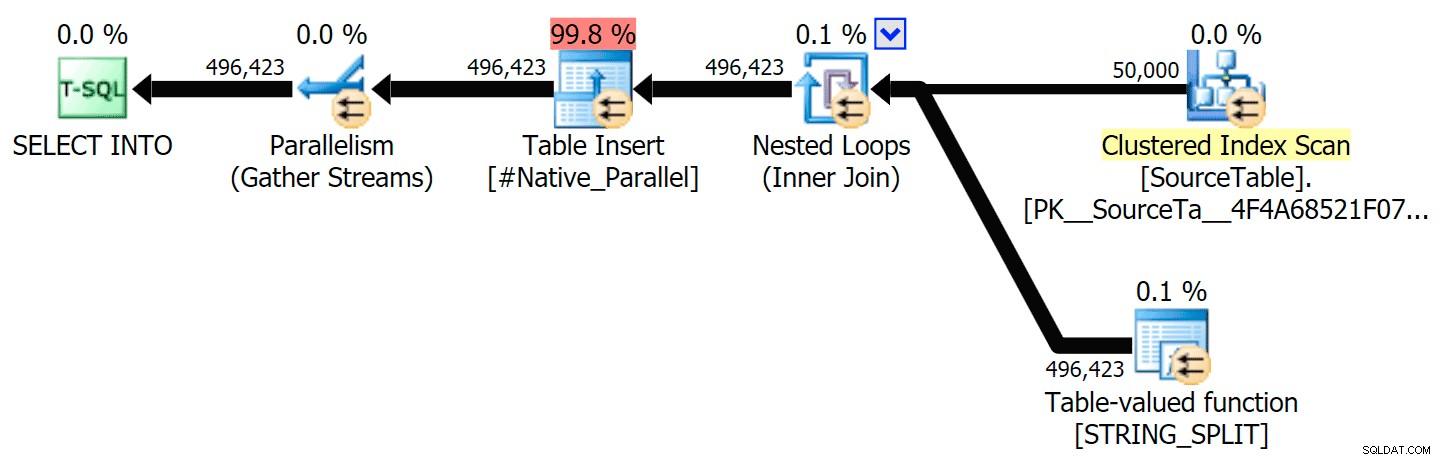
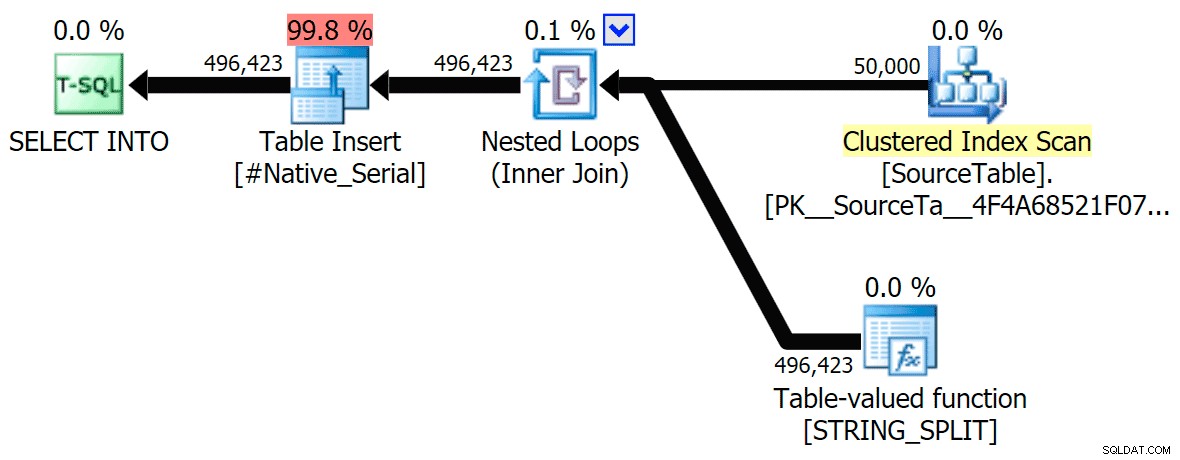
सीएलआर
सॉर्ट चेतावनी, एफवाईआई, कुछ भी चौंकाने वाला नहीं था, और स्पष्ट रूप से क्वेरी अवधि पर इसका कोई ठोस प्रभाव नहीं था:

- StringSplit.queryanalysis.zip (25kb)
गर्मियों के लिए स्पूल आउट
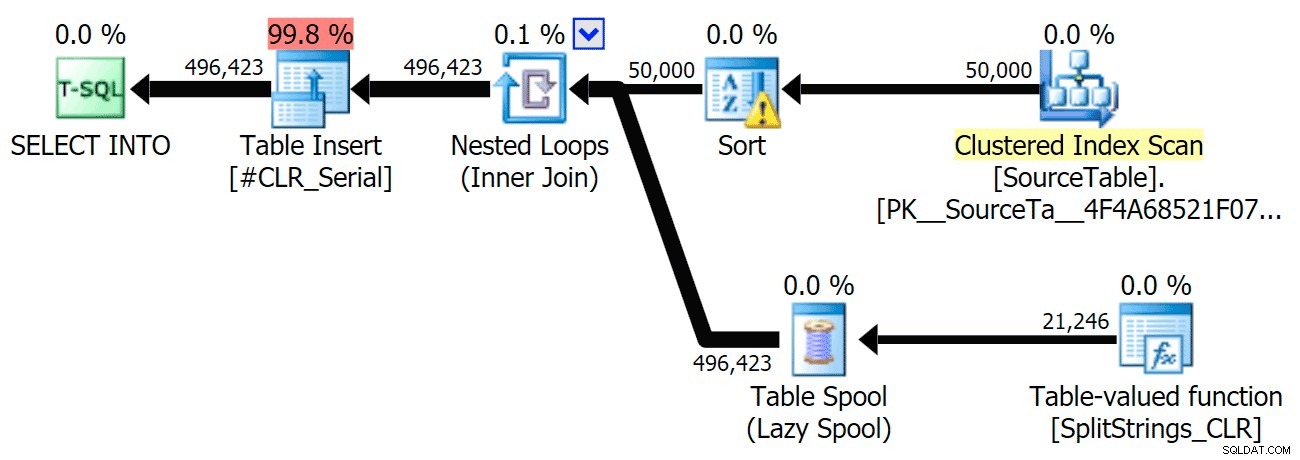
जब मैंने उन योजनाओं को थोड़ा करीब से देखा, तो मैंने देखा कि सीएलआर योजना में एक आलसी स्पूल है। यह सुनिश्चित करने के लिए पेश किया गया है कि डुप्लिकेट को एक साथ संसाधित किया जाता है (कम वास्तविक विभाजन करके काम को बचाने के लिए), लेकिन यह स्पूल सभी योजना आकारों में हमेशा संभव नहीं होता है, और यह उन लोगों को थोड़ा सा लाभ दे सकता है जो इसका उपयोग कर सकते हैं ( उदाहरण के लिए सीएलआर योजना), अनुमानों के आधार पर। स्पूल के बिना तुलना करने के लिए, मैंने ट्रेस फ्लैग 8690 को सक्षम किया, और परीक्षण फिर से चलाया। सबसे पहले, यहां स्पूल के बिना समानांतर सीएलआर योजना है:
और यहां TF 8690 सक्षम के साथ समानांतर चल रहे सभी प्रश्नों के लिए नई अवधियां दी गई हैं:
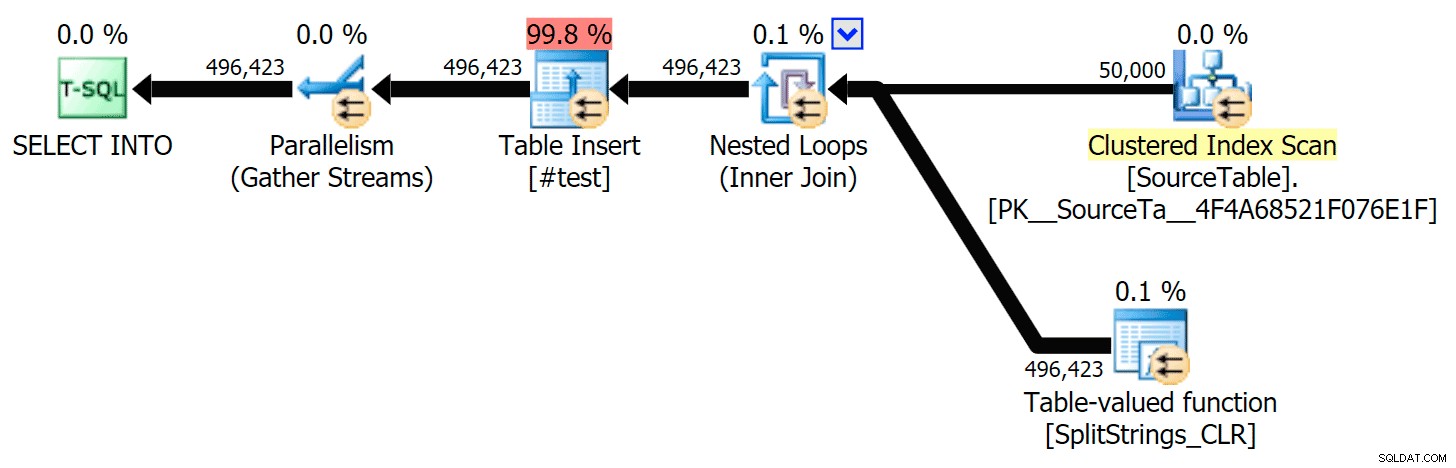
अब, यहाँ स्पूल के बिना सीरियल सीएलआर योजना है:
और यहां TF 8690 और MAXDOP 1 . दोनों का उपयोग करते हुए क्वेरी के लिए समय के परिणाम दिए गए थे :
(ध्यान दें कि, XML योजना के अलावा, अधिकांश अन्य ट्रेस फ़्लैग के साथ या उसके बिना बिल्कुल भी नहीं बदले हैं।)
अनुमानित पंक्तियों की तुलना करना
डैन होम्स ने निम्नलिखित प्रश्न पूछा:
दूसरे (या एकाधिक) स्प्लिट फ़ंक्शन में शामिल होने पर यह डेटा आकार का अनुमान कैसे लगाता है? नीचे दिया गया लिंक सीएलआर आधारित विभाजन कार्यान्वयन का एक लेख है। क्या 2016 डेटा अनुमानों के साथ 'बेहतर' काम करता है? (दुर्भाग्य से मेरे पास अभी तक RC स्थापित करने की क्षमता नहीं है)।https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and। एचटीएमएल
इसलिए, मैंने डैन की पोस्ट से कोड स्वाइप किया, इसे अपने कार्यों का उपयोग करने के लिए बदल दिया, और इसे प्लान एक्सप्लोरर के माध्यम से चलाया:
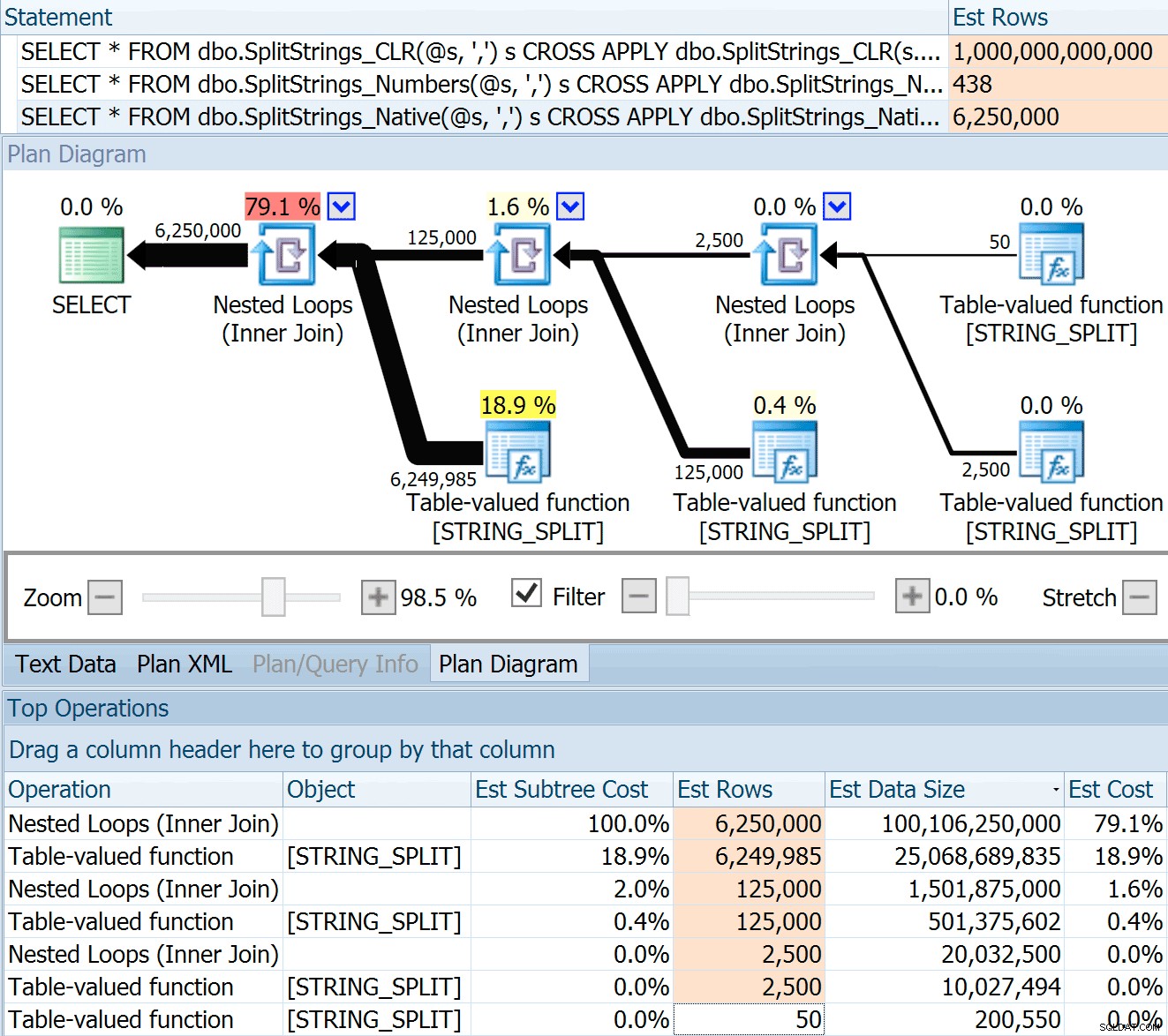
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING दृष्टिकोण निश्चित रूप से सीएलआर की तुलना में *बेहतर* अनुमानों के साथ आता है, लेकिन अभी भी पूरी तरह से खत्म हो गया है (इस मामले में, जब स्ट्रिंग खाली है, यह हमेशा मामला नहीं हो सकता है)। फ़ंक्शन में एक अंतर्निहित डिफ़ॉल्ट है जो अनुमान लगाता है कि आने वाली स्ट्रिंग में 50 तत्व होंगे, इसलिए जब आप उन्हें घोंसला बनाते हैं तो आपको 50 x 50 (2,500) मिलता है; यदि आप उन्हें फिर से घोंसला बनाते हैं, तो 50 x 2,500 (125,000); और फिर अंत में, 50 x 125,000 (6,250,000):
नोट:OPENJSON() ठीक उसी तरह व्यवहार करता है जैसे STRING_SPLIT - यह भी मानता है कि किसी दिए गए स्प्लिट ऑपरेशन से 50 पंक्तियां आ जाएंगी। मैं सोच रहा हूं कि 4137 (पूर्व-2014), 9471 और 9472 (2014+), और निश्चित रूप से 9481 जैसे ट्रेस झंडे के अलावा, इस तरह के कार्यों के लिए कार्डिनैलिटी को इंगित करने का एक तरीका उपयोगी हो सकता है ...
यह 6.25 मिलियन पंक्ति का अनुमान बहुत अच्छा नहीं है, लेकिन यह उस CLR दृष्टिकोण से बहुत बेहतर है जिसके बारे में डैन बात कर रहे थे, जिसका अनुमान एक ट्रिलियन ROWS है। , और मैंने डेटा आकार - 16 पेटाबाइट निर्धारित करने के लिए अल्पविरामों की संख्या खो दी है? एक्साबाइट्स?
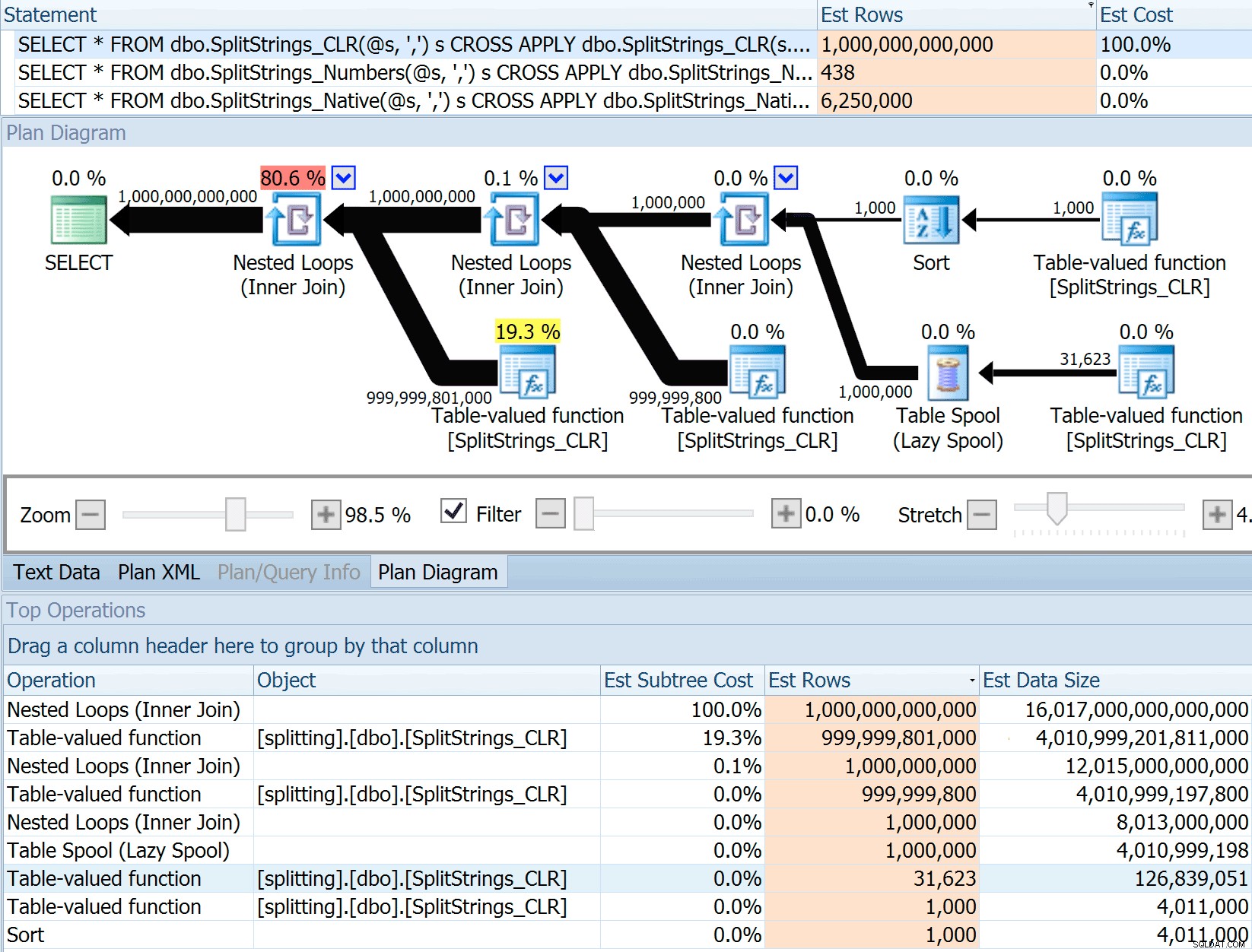
कुछ अन्य दृष्टिकोण स्पष्ट रूप से अनुमानों के संदर्भ में बेहतर प्रदर्शन करते हैं। संख्या तालिका, उदाहरण के लिए, अधिक उचित 438 पंक्तियों (SQL सर्वर 2016 RC2 में) का अनुमान है। यह नंबर कहां से आता है? खैर, तालिका में 8,000 पंक्तियाँ हैं, और यदि आपको याद है, तो फ़ंक्शन में समानता और असमानता दोनों विधेय हैं:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter तो, SQL सर्वर समानता फ़िल्टर के लिए तालिका में पंक्तियों की संख्या को 10% (अनुमान के रूप में) से गुणा करता है, फिर वर्गमूल असमानता फिल्टर के लिए 30% (फिर से, एक अनुमान)। वर्गमूल घातीय बैकऑफ़ के कारण होता है, जिसे पॉल व्हाइट यहां बताते हैं। यह हमें देता है:
8000 * 0.1 * एसक्यूआरटी (0.3) =438.178एक्सएमएल भिन्नता का अनुमान एक अरब पंक्तियों से थोड़ा अधिक था (एक टेबल स्पूल के 5.8 मिलियन बार निष्पादित होने का अनुमान है), लेकिन इसकी योजना यहां वर्णन करने की कोशिश करने के लिए बहुत जटिल थी। किसी भी मामले में, याद रखें कि अनुमान स्पष्ट रूप से पूरी कहानी नहीं बताते हैं - सिर्फ इसलिए कि किसी क्वेरी में अधिक सटीक अनुमान हैं इसका मतलब यह नहीं है कि यह बेहतर प्रदर्शन करेगा।
कुछ अन्य तरीके थे जिनसे मैं अनुमानों को थोड़ा बदल सकता था:अर्थात्, पुराने कार्डिनैलिटी अनुमान मॉडल (जो एक्सएमएल और नंबर टेबल विविधता दोनों को प्रभावित करता था) को मजबूर कर रहा था, और टीएफ 9471 और 9472 का उपयोग कर रहा था (जो केवल संख्या तालिका भिन्नता को प्रभावित करता था, क्योंकि वे दोनों कई विधेय के आसपास कार्डिनैलिटी को नियंत्रित करते हैं)। ये थे वे तरीके जिनसे मैं अनुमानों को थोड़ा सा बदल सकता था (या बहुत सारे , पुराने CE मॉडल पर वापस लौटने के मामले में):

पुराने सीई मॉडल ने परिमाण के क्रम से एक्सएमएल अनुमानों को नीचे लाया, लेकिन संख्या तालिका के लिए, इसे पूरी तरह से उड़ा दिया। विधेय झंडे ने नंबर तालिका के अनुमानों को बदल दिया, लेकिन वे परिवर्तन बहुत कम दिलचस्प हैं।
इनमें से किसी भी ट्रेस फ़्लैग का CLR, JSON, या STRING_SPLIT के अनुमानों पर कोई प्रभाव नहीं पड़ा विविधताएं।
निष्कर्ष
तो मैंने यहाँ क्या सीखा? एक पूरा गुच्छा, वास्तव में:
- समानांतरवाद कुछ मामलों में मदद कर सकता है, लेकिन जब यह मदद नहीं करता है, तो यह वास्तव में मदद नहीं करता। JSON विधियां समानांतरवाद के बिना ~5x तेज थीं, और
STRING_SPLITलगभग 10 गुना तेज था। - स्पूल ने वास्तव में इस मामले में सीएलआर दृष्टिकोण को बेहतर प्रदर्शन करने में मदद की, लेकिन टीएफ 8690 अन्य मामलों में प्रयोग करने के लिए उपयोगी हो सकता है जहां आप स्पूल देख रहे हैं और प्रदर्शन में सुधार करने की कोशिश कर रहे हैं। मुझे यकीन है कि ऐसी स्थितियां हैं जहां स्पूल को खत्म करना अंत में बेहतर होगा।
- स्पूल को हटाना वास्तव में एक्सएमएल दृष्टिकोण को नुकसान पहुंचाता है (लेकिन केवल इतना ही कि जब इसे सिंगल-थ्रेडेड होने के लिए मजबूर किया गया था)।
- सामान्य आंकड़ों, वितरण और ट्रेस फ़्लैग के साथ-साथ दृष्टिकोण के आधार पर अनुमानों के साथ बहुत सी मज़ेदार चीज़ें हो सकती हैं। ठीक है, मुझे लगता है कि मुझे यह पहले से ही पता था, लेकिन निश्चित रूप से यहाँ कुछ अच्छे, ठोस उदाहरण हैं।
उन लोगों को धन्यवाद जिन्होंने प्रश्न पूछे या मुझे अधिक जानकारी शामिल करने के लिए प्रेरित किया। और जैसा कि आपने शीर्षक से अनुमान लगाया होगा, मैं एक दूसरे प्रश्न को टीवीपी के बारे में एक दूसरे अनुवर्ती में संबोधित करता हूं:
- SQL सर्वर 2016 में
- STRING_SPLIT() :फॉलो-अप #2