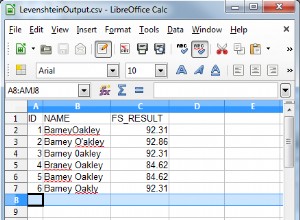
आपको MySQL के विचार को बदलना होगा कि एक शब्द क्या है।
सबसे पहले, डिफ़ॉल्ट न्यूनतम शब्द लंबाई 4 है। इसका मतलब है कि कोई भी खोज शब्द जिसमें केवल <4 अक्षरों के शब्द हों, कभी भी मेल नहीं खाएंगे, चाहे वह 'सी ++' या 'सीपीपी' हो। आप इसे ft_min_word_len config विकल्प, उदा। आपके my.cfg में:
[mysqld]
ft_min_word_len=3
(फिर MySQLd को रोकें/शुरू करें और पूर्ण टेक्स्ट इंडेक्स का पुनर्निर्माण करें।)
दूसरे, MySQL द्वारा '+' को एक अक्षर नहीं माना जाता है। आप इसे एक अक्षर बना सकते हैं, लेकिन इसका मतलब है कि आप 'fish+chips' स्ट्रिंग में 'fish' शब्द की खोज करने में सक्षम नहीं होंगे, इसलिए कुछ देखभाल की आवश्यकता है। और यह मामूली नहीं है:इसके लिए MySQL को पुन:संकलित करने या मौजूदा वर्ण सेट को हैक करने की आवश्यकता है। अनुभाग 11.8.6 दस्तावेज़ के।
हां, ऐसा कुछ एक सामान्य समाधान है:आप अपने 'वास्तविक' डेटा (बचने के बिना) को प्राथमिक, निश्चित तालिका में रख सकते हैं — आमतौर पर ACID अनुपालन के लिए InnoDB का उपयोग करते हुए। फिर एक सहायक MyISAM तालिका जोड़ी जा सकती है, जिसमें फुलटेक्स्ट सर्च बैट के लिए केवल उलझे हुए शब्द होते हैं। आप इस दृष्टिकोण का उपयोग करके स्टेमिंग का एक सीमित रूप भी कर सकते हैं।
एक अन्य संभावना उन खोजों का पता लगाना है जो MySQL नहीं कर सकता, जैसे कि केवल छोटे शब्दों या असामान्य वर्णों वाले, और केवल उन खोजों के लिए एक सरल-लेकिन-धीमी LIKE या REGEXP खोज पर वापस आते हैं। इस मामले में आप शायद ft_stopword_file एक खाली स्ट्रिंग के लिए, क्योंकि इसमें सब कुछ विशेष के रूप में भी लेना व्यावहारिक नहीं है।